SSD算法理论
SSD算法
SSD(Single Shot MultiBox Detector)是one-stage目标检测方法,one-stage算法就是目标检测和分类是同时完成的,其主要思路是利用CNN提取特征后,均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,物体分类与预测框的回归同时进行,整个过程只需要一步,所以其优势是速度快。
SSD网络模型
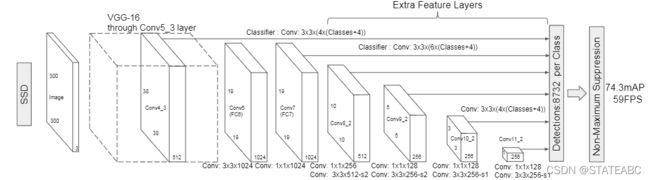
输入图像shape为300x300x3(将图像输入网络之前会进行缩放);
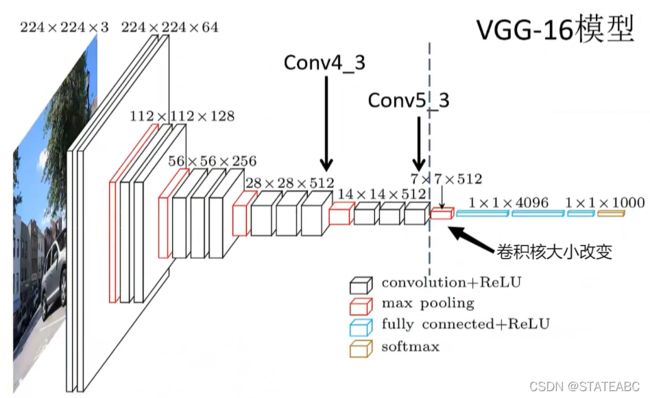
将图像输入到VGG16的backbone中,贯穿Conv5_3(即虚线前的网络结构):
1、conv1,经过两次3x3卷积网络,输出的特征层为64,输出为(300,300,64),再2X2最大池化,该最大池化步长为2,输出net为(150,150,64)。
2、conv2,经过两次3x3卷积网络,输出的特征层为128,输出net为(150,150,128),再2X2最大池化,该最大池化步长为2,输出net为(75,75,128)。
3、conv3,经过三次3x3卷积网络,输出的特征层为256,输出net为(75,75,256),再2X2最大池化,该最大池化步长为2,输出net为(38,38,256)。
4、conv4,经过三次3x3卷积网络,输出的特征层为512,输出net为(38,38,512),再2X2最大池化,该最大池化步长为2,输出net为(19,19,512)。
5、conv5,经过三次3x3卷积网络,输出的特征层为512,输出net为(19,19,512),再3X3最大池化,该最大池化步长为1,输出net为(19,19,512)。
利用卷积代替全连接层,进行了一次3x3卷积网络和一次1x1卷积网络,分别为fc6和fc7,输出的通道数为1024,因此输出的net为(19,19,1024);
通过在backbone后添加一系列的卷积层得到其他的预测特征层:
Conv8,经过一次1x1卷积网络,调整通道数,一次步长为2的3x3卷积网络,输出的通道数为512,因此输出的net为(10,10,512)。
Conv9,经过一次1x1卷积网络,调整通道数,一次步长为2的3x3卷积网络,输出的通道数为256,因此输出的net为(5,5,256)。
Conv10,经过一次1x1卷积网络,调整通道数,一次padding为valid的3x3卷积网络,输出的通道数为256,因此输出的net为(3,3,256)。
Conv11,经过一次1x1卷积网络,调整通道数,一次padding为valid的3x3卷积网络,输出的特征层为256,因此输出的net为(1,1,256)。
然后将:
conv4的第三次卷积的特征;
fc7卷积的特征;
conv6的第二次卷积的特征;
conv7的第二次卷积的特征;
conv8的第二次卷积的特征;
conv9的第二次卷积的特征。
作为预测特征层,进行不同大小的目标检测,要进行两个操作:
- 一次num_anchors x 4的卷积,用于预测该特征层上 每一个网格点上 每一个先验框的变化情况。
- 一次num_anchors x num_classes的卷积,用于预测该特征层上 每一个网格点上 每一个预测对应的种类。
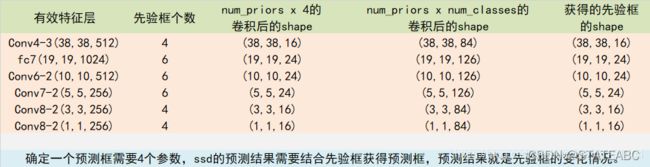
先验框虽然可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此还需要调整,ssd利用num_anchors x 4的卷积的结果对先验框进行调整。
num_anchors x 4中的num_anchors表示了这个网格点所包含的先验框数量,其中的4表示了x_offset、y_offset、h和w的调整情况。
x_offset与y_offset代表了真实框距离先验框中心的xy轴偏移情况。
h和w代表了真实框的宽与高相对于先验框的变化情况。
SSD解码过程可以分为两部分:
将每个网格的中心点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心;
利用h和w调整先验框获得预测框的宽和高。
最后对每一个预测框进行得分排序与非极大抑制筛选,获得最终的预测结果。
参考文献:
SSD算法理论
睿智的目标检测23——Pytorch搭建SSD目标检测平台