深度学习目标分割概述
目录
- 1 图像分割的定义
- 2 任务类型
-
- 2.1 任务描述
- 2.2 任务类型
- 3 常用的开源数据集
-
- 3.1 VOC数据集
- 3.2 城市风光Cityscapes数据集
- 4 评价指标
-
- 4.1 像素精度
- 4.2 平均像素精度
- 4.3 平均交并比
- 5 总结
1 图像分割的定义
计算机视觉旨在识别和理解图像中的内容,包含三大基本任务:图像分类(图a)、目标检测(图b)和图像分割,其中图像分割又可分为:语义分割(图c)和实例分割(图d)。
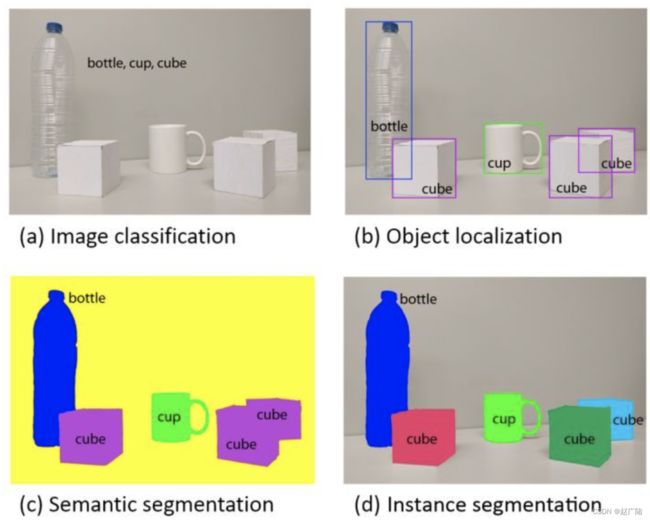
这三个任务对图像的理解逐步深入。假设给定一张输入图像,
-
图像分类旨在判断该图像所属类别。
-
目标检测是在图像分类的基础上,进一步判断图像中的目标具体在图像的什么位置,通常是以外包矩形(bounding box)的形式表示。
-
图像分割是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标。但是,语义分割不区分属于相同类别的不同实例。如上图所示,当图像中有多个cube时,语义分割会将所有立方体整体的所有像素预测为“cube”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一个cube、哪些像素属于第二个cube……。
-
定义:在计算机视觉领域,图像分割(Object Segmentation)指的是将数字图像细分为多个图像子区域(像素的集合)的过程,并且同一个子区域内的特征具有一定相似性,不同子区域的特征呈现较为明显的差异。

图像分割的目标就是为图像中的每个像素分类。应用领域非常的广泛:自动驾驶、医疗影像,图像美化、三维重建等等。
- 自动驾驶(Autonomous vehicles):汽车需要安装必要的感知系统以了解它们的环境,这样自动驾驶汽车才能够安全地驶入现有的道路

- 医疗影像诊断(Medical image diagnostics):机器在分析能力上比放射科医生更强,而且可以大大减少诊断所需时间。
图像分割是一个非常困难的问题,尤其是在深度学习之前。深度学习使得图像分割的准确率提高了很多,接下来主要围绕深度学习方法给大家介绍图像分割的内容。
2 任务类型
2.1 任务描述
简单来说,我们的目标是输入一个RGB彩色图片(height×width×3)或者一个灰度图(height×width×1),然后输出一个包含各个像素类别标签的分割图(height×width×1)。如下图所示:
与我们处理分类值的方式类似,预测目标可以采用one-hot编码,即为每一个可能的类创建一个输出通道。通过取每个像素点在各个channel的argmax可以得到最终的预测分割图,(如下图所示):

比如:person的编码为:10000,而Grass的编码为:00100
当将预测结果叠加到单个channel时,称这为一个掩膜mask,它可以给出一张图像中某个特定类的所在区域:

2.2 任务类型
目前的图像分割任务主要有两类: 语义分割和实例分割
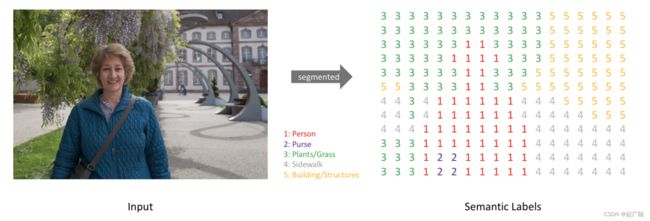
我们以下图为例,来介绍这两种分割方式:

- 语义分割就是把图像中每个像素赋予一个类别标签,如下图我们将图像中的像素分类为人,羊,狗,草地即可。

- 实例分割,相对于语义分割来讲,不仅要区分不同类别的像素,还需要需要对同一类别的不同个体进行区分。如下图所示,不仅需要进行类别的划分,还要将各个个体划分出来:羊1,羊2,羊3,羊4,羊5等。

目前图像分割的任务主要集中在语义分割,而目前的难点也在于“语义”,表达某一语义的同一物体并不总是以相同的形象出现,如包含不同的颜色、纹理等,这对精确分割带来了很大的挑战。而且以目前的模型表现来看,在准确率上还有很大的提升空间。而实例分割的思路主要是目标检测+语义分割,即用目标检测方法将图像中的不同实例框出,再用语义分割方法在不同检测结果内进行逐像素标记。
3 常用的开源数据集
图像分割常用的数据集是PASCAL VOC,城市风光数据集,coco数据集等。
3.1 VOC数据集
VOC数据集共有20类数据,目录结构如下图所示:

这个在目标检测概述一节中已经给大家介绍过,接下来我们主要介绍目标分割相关的内容:
- JPEGImages中存放图片文件
- imagesets中的segmentation中记录了用于分割的图像信息
- SegmentationClass中是语义分割的标注信息
- SegmentationObject中是实例分割的标注信息
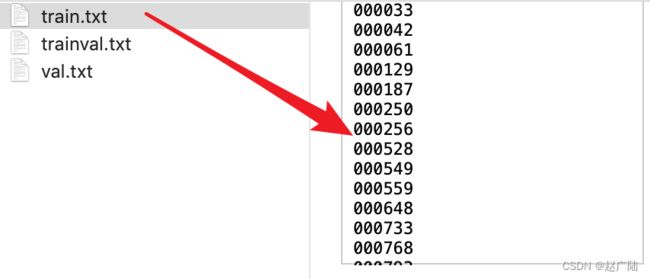
VOC中的图片并不是所有都用于分割,用于分割比赛的图片实例都记录在txt文件中,如下图所示:

相关的图像记录在相应的文本文件中,如训练集数据记录在train.txt文件中,其中内容如下:
那我们就可以使用这些数据进行图像分割模型的训练。图像的标注效果如下图所示:
原图像002378.jpg的语义分割和实例分割的标注结果如上所示,背景是黑色的,不同类别的像素标注为不同的颜色。可以看出,语义分割只标注了像素的类别,而实例分割不仅标注了类别,还对同一类别的不同个体进行了区分。
在写程序的时候就利用 train.txt 对图片进行挑选,因为不是所有的图片都有分割真实值,获取图片及其对应的真实值,对网络进行训练即可。
3.2 城市风光Cityscapes数据集
Cityscapes是由奔驰于2015年推出的,提供无人驾驶环境下的图像分割数据集。它包含50个城市不同场景、不同背景、不同季节的街景,提供了5000张在城市环境中驾驶场景的高质量像素级注释图像(其中 2975 for train,500 for val,1525 for test)。
Cityscapes是目前公认的自动驾驶领域内最具权威性和专业性的图像语义分割评测集之一,其关注真实场景下的城区道路环境理解,任务难度更高且更贴近于自动驾驶等热门需求。接下来我们看下数据的内容,数据集的文件目录结构如下图所示:
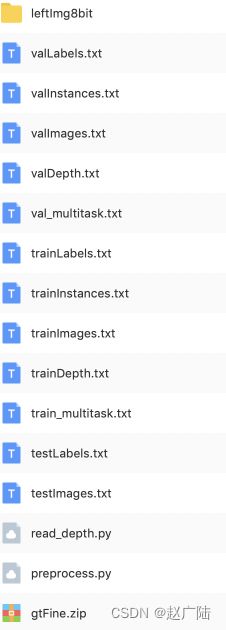
其中txt文件中保存了相关样本图片的路径和文件名,便于查找相应的数据,我们主要使用数据是leftImg8bit和gtFine中的内容,如下所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kH5pbP6o-1646528416919)(笔记图片/image-20201008173056349.png)]](http://img.e-com-net.com/image/info8/a2ea730fca0e42dda568c3d2a4e96102.jpg)
- leftImg8bit文件夹有三个子目录:test, train以及val,分别为测试集,训练集以及验证集图片。这三个子目录的图片又以城市为单元来存放,如下图所示:

这里解释下leftImg8bit的含义,因为cityscapes实际上来源于双摄像头拍摄的立体视频序列,所以这里的leftImg就是来自于左摄像头的图片,而8bit意味着该图片集都为RGB每个分量为8bit的图片。
- gtFine是样本图片对应的标注信息,gtFine下面也是分为train, test以及val,然后它们的子目录也是以城市为单位来放置图片。这些都是和leftImg8bit的一一对应。 不同的是,在城市子目录下面,每张样本图片对应有6个标注文件,如下所示:

精细标注数据集里面每张图片只对应四张标注文件:xxx_gtFine_color.png, xxx_gtFine_instanceIds.png, xxx_gtFine_labelsIds.png以及xxx_gtFine_polygons.json。 xxx_color.png是标注的可视化图片,真正对训练有用的是后面三个文件。xxx_instanceIds.png是用来做实例分割训练用的,而xxx_labelsIds.png是语义分割训练需要的。而最后一个文件xxx_polygons.json主要记录了每个多边形标注框上的点集坐标。
该数据集的标注效果可视化如下所示:
4 评价指标
图像分割中通常使用许多标准来衡量算法的精度。这些标准通常是像素精度及IoU的变种,以下我们将会介绍常用的几种逐像素标记的精度标准。
为了便于解释,假设如下:共有k+1个类(从L0到Lk,其中包含一个背景类),pij表示本属于类ii但被预测为类jj的像素。即pii表示预测正确的像素。
4.1 像素精度
Pixel Accuracy(PA,像素精度):这是最简单的度量,为预测正确的像素占总像素的比例。
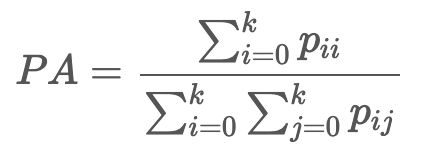
对于样本不均衡的情况,例如医学图像分割中,背景与标记样本之间的比例往往严重失衡。因此并不适合使用这种方法进行度量。
4.2 平均像素精度
Mean Pixel Accuracy(MPA,平均像素精度):是PA的一种简单提升,计算每个类内被正确分类像素数的比例,之后求所有类的平均。

4.3 平均交并比
Mean Intersection over Union(MIoU,平均交并比):为语义分割的标准度量,其计算两个集合的交集和并集之比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。交集为预测正确的像素数(intersection),并集为预测或真实值为ii类的和减去预测正确的像素,在每个类上计算IoU,之后求平均即可。

那么,如何理解这里的公式呢?如下图所示,红色圆代表真实值,黄色圆代表预测值。橙色部分红色圆与黄色圆的交集,即预测正确的部分,红色部分表示假负(真实值为该类预测错误)的部分,黄色表示假正(预测值为i类,真实值为其他)的部分。
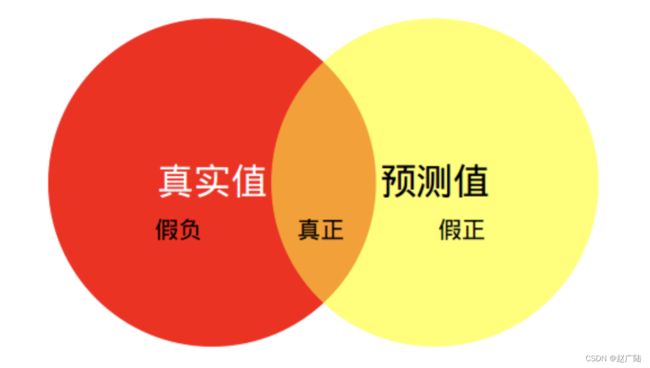
MIoU计算的是计算A与B的交集(橙色部分)与A与B的并集(红色+橙色+黄色)之间的比例,在理想状态下A与B重合,两者比例为1 。
在以上所有的度量标准中,MIoU由于其简洁、代表性强而成为最常用的度量标准,大多数研究人员都使用该标准报告其结果。PA对于样本不均衡的情况不适用。
5 总结
- 图像分割的定义
图像分割(Object Segmentation)指的是将数字图像细分为多个图像子区域(像素的集合)的过程,并且同一个子区域内的特征具有一定相似性,不同子区域的特征呈现较为明显的差异。
- 图像分割的任务类型
图像分割的任务就是给图像中的每一个像素点进行分类
语义分割和实例分割
- 图像分割的常见数据集
Voc 数据集,城市风光数据集,coco数据集等
- 图像分割的评估指标
像素精度(PA),平均像素精度(mPA)和 平均交并比(mIOU)
最常用的是MIOU