【数据库】北邮国际学院大二下期末复习
期末背诵
1
Data: facts and statistics collected together for reference or analysis.
数据:收集起来供参考或分析的事实和统计数字。
Database: a shared collection of logically related data (and a description of this data), designed to meet the information needs of an organization.
数据库:逻辑上相关的数据(以及数据的描述)的共享集合,旨在满足组织的信息需求。
DBMS (Database Management Systems): A software system which enables users to define, create, maintain, and control access to the database.
DBMS(数据库管理系统):一种软件系统,它使用户能够定义、创建、维护和控制对数据库的访问。
Data model: A data model is a graphical description of the components of database.
数据模型:数据模型是对数据库组件的图形化描述。
Schema: The description of the database is the database schema
模式:数据库的描述是数据库模式
Relation model:
Relational model: In the relational model, all data is logically structured within relations.
关系模型:在关系模型中,所有数据都是在关系中逻辑结构化的。
Relation: A relation is a table with columns and rows.(table)
Attribute: An attribute is a named column of a relation. (column)
Tuple: A tuple is row of a relation.(row)
Cardinality: the number of tuples in a relation.即行数
Degree: the number of attributes in a relation.即列数
Domain: the set of allowable values for one or more attributes.
关系:关系是一个包含列和行的表。
元组:元组是一个关系的行。
属性:属性是关系的命名列。
基数:中元组的数量关系。即行数
学位:属性的数量关系。即列数
域:一个或多个属性的允许值集。
Key:
Candidate Key: A set of attributes that uniquely identifies a tuple within a relation.
Primary Key: Candidate key selected to identify tuples uniquely within relation.
Foreign Key: Attribute, or set of attributes, within one relation that matches candidate key of some (possibly same) relation.
Composite Key: A candidate key that consists of two or more attributes.
候选键:唯一标识关系中的元组的一组属性。
主键:选择的用于在关系中唯一标识元组的候选键。
外键:一个关系中与某个(可能相同)关系的候选键匹配的属性或属性集。
Entity Integrity: In a base relation, no attribute of a primary key can be null.
Referential Integrity: If foreign key exists in a relation, either foreign key value must match a candidate key value of some tuple in its home relation or foreign key value must be null.
实体完整性:在基本关系中,主键的任何属性都不能为空。
引用完整性:如果一个关系中存在外键,则外键值必须匹配其主关系中的某个元组的某个候选键值,或者外键值必须为空。
E-R model: E-R modelling is a high-level conceptual modelling technique for DB applications
E-R模型:E-R建模是一种用于数据库应用的高级概念建模技术
Entity: a distinct object in the organization that is to be represented in the database.
实体:组织中要在数据库中表示的一个不同的对象。
Relationship: an association between entities.
联系:实体之间的关联。
A relational schema outlines the database relationships and construction in a relational database program. It could be displayed graphically or written within the Structured Query Language (SQL) used to construct tables in a relational database.
关系模式概括了关系数据库程序中的数据库关系和构造。它可以图形化显示,也可以使用结构化查询语言(SQL)编写,这种语言用于在关系数据库中构造表。
Relational Algebra: Relational algebra is formal language associated with the relational model.
关系代数:关系代数是与关系模型相关联的形式语言。
2
Database Design Methodology四步
– Gather requirements收集需求
– Conceptual database design数据库概念设计
– Logical database design逻辑数据库设计
– Physical database design物理数据库设计
3
1NF: a table in first normal is simply one that has no multi-values (repeating) fields.
2NF: A relation that is in first normal form and every non-candidate-key attribute is fully functionally dependent on any candidate key.
3NF: A relation that is in first and second normal form and in which no non-candidate-key attribute is transitively dependent on any candidate key.
BCNF: every determinant is a candidate key.
4NF:in Boyce-Codd Normal Form and contains no nontrivial multi-valued dependencies.
1NF:第一个普通表就是没有多值(重复)字段的表。
2NF:一种第一范式的关系,每个非候选键属性在功能上完全依赖于任何候选键。
3NF:一种第一和第二范式的关系,在这种关系中,没有任何非候选键属性在传递上依赖于任何候选键。
BCNF:关系在BCNF中当且仅当每个行列式都是一个候选键。
4NF:定义为Boyce-Codd范式的关系,不包含非平凡的多值依赖关系。
Functional dependency: Functional dependency describes relationship between attributes.
函数依赖:函数依赖描述属性之间的关系。
Full Functional Dependency: Determinants should have the minimal number of attributes necessary to maintain the functional dependency with the attribute(s) on the right hand-side.
完整的函数依赖性:行列式应该有最少数量的必要属性来维护函数依赖性,右边的属性。
Partial functional dependency: A functional dependency A−> B is a partial dependency if there is some attribute that can be removed from A and the dependency still holds.
部分函数依赖:函数依赖A−> B;如果有一些属性可以从A中删除,并且依赖项仍然存在,那么B就是部分依赖项。
Transitive Dependency: A, B, and C are attributes of a relation such that if A −> B and B −> C, then C is transitively dependent on A via B.
传递相关性:A、B和C是一个关系的属性,如果A−> B和B−> B,那么C通过B依赖于A。
Multi-valued Dependency (MVD): Dependency between attributes (for example, A, B, and C) in a relation, such that for each value of A there is a set of values for B and a set of values for C. However, the set of values for B and C are independent of each other.
多值依赖(MVD):属性之间的依赖关系(例如,A, B, C)在一个关系,这样对于每个值都有一组值B和C。然而,一组值的集合值B和C是相互独立的。
Transaction: Action, or series of actions, carried out by user or application, which reads or updates contents of database.
事务:用户或应用程序执行的读取或更新数据库内容的操作或一系列操作。
ACID
Atomicity: ‘All or nothing’ property
Consistency: Must transform database from one valid state to another.
Isolation: Partial effects of incomplete transactions should not be visible to other transactions.
Durability: Effects of a committed transaction are permanent and must not be lost because of later failure.
原子性:“全做或者全不做”属性
一致性:必须将数据库从一种有效状态转换为另一种有效状态。
隔离:未完成事务的部分影响不应对其他事务可见。
持久性:已提交事务的影响是永久的,不能因为以后的失败而丢失。
Concurrency problems: In order to run transactions concurrently we interleave their operations.
并发性问题:为了并发地运行事务,我们交错处理它们的操作。
Lost Update Problem: Successfully completed update is overridden by another user.
Uncommitted Dependency Problem: Occurs when one transaction can see intermediate results of another transaction before it has committed.
Inconsistent analysis problem: Occurs when a transaction reads several values from the database but a second transaction updates some of them during the execution of the first.
丢失更新问题:成功完成的更新被另一个用户覆盖。
未提交依赖关系问题:当一个事务在提交之前可以看到另一个事务的中间结果时发生。
不一致的分析问题:当一个事务从数据库中读取几个值,但第二个事务在执行第一个事务时更新其中一些值时发生。
2PL: Every transaction must lock an item (read or write) before accessing it. Once a lock has been released, no new items can be locked.
2PL:每个事务在访问一个项目(读或写)之前必须锁定它。一旦锁定被释放,就不能再锁定新的项目。
Deadlock: A deadlock occurs when two (or more) transactions are each waiting for locks held by the other to be released.
死锁:当两个(或多个)事务都在等待另一个事务持有的锁被释放时,就会发生死锁。
Timeout: locks only last a system-defined period of time: the lock will be eliminated after such period.
Deadlock prevention: the DBMS looks ahead to see if a transaction would cause a deadlock and never allows a deadlock to occur.
超时:锁只持续系统定义的一段时间:在这段时间后锁将被消除。
死锁预防:DBMS会提前查看一个事务是否会导致死锁,并且永远不会允许死锁发生。
4
Three-tier client architecture: Three-tier includes: The user interface layer, which runs on the end-user’s computer (the client). The business logic and data processing layer. This middle tier runs on a server and is often called the application server. A DBMS, which stores the data required by the middle tier. This tier may run on a separate server called the database server.
三层客户机体系结构:三层包括:用户界面层,它运行在最终用户的计算机(客户机)上。业务逻辑和数据处理层。这个中间层运行在服务器上,通常称为应用服务器。Distributed Database: A logically interrelated collection of shared data (and a description of this data), physically spread over a computer network.
分布式数据库:逻辑上相互关联的共享数据(和数据的描述)的集合,物理上分布在计算机网络上。
Distributed processing: centralized database that can be accessed over a computer network.
分布式处理:可以通过计算机网络访问的集中式数据库。
Distributed DBMS:Software system that permits the management of the distributed database and makes the distribution transparent to users.
分布式数据库管理系统:允许对分布式数据库进行管理并使分布对用户透明的软件系统。
DBMS,它存储中间层所需要的数据。这一层可以在称为数据库服务器的单独服务器上运行。
XML: A meta-language (a language for describing other languages) that enables designers to create their own customized tags to provide functionality not available with HTML.
XML:一种元语言(用于描述其他语言的语言),它允许设计人员创建自己的定制标记,以提供HTML无法提供的功能。
DTDs(Document Type Definitions ): Defines the valid syntax of an XML document.
XCD (XML Schema): XML schema is the definition (both in terms of its organization and its data types) of a specific XML structure.
DTDs(文档类型定义):定义XML文档的有效语法。
XCD (XML模式):XML模式是特定XML结构的定义(就其组织和数据类型而言)。
Data mining: The process of extracting valid, previously unknown, comprehensible, and actionable information from large databases and using it to make crucial business decisions.
数据挖掘:从大型数据库中提取有效的、以前未知的、可理解的和可操作的信息,并将其用于做出关键的业务决策的过程。
NoSQL: alternative, non-traditional DB technology to be used in large scale environments where (ACID) transactions are not a priority.
NoSQL:可选的、非传统的数据库技术,用于不优先考虑(ACID)事务的大规模环境。
基础知识
数据:数据就是数据库中存储的基本数据,比如学生的学号、学生的班级
数据库:存放数据的仓库
数据库管理系统:数据库软件,如MySQL、Oracle
数据库系统:数据库+数据库管理系统+应用程序+数据库管理员(大佬)
实体:客观存在的对象,比如一个学生,一位老师
属性:实体的特性,比如学生的学号、姓名、院系
键:可唯一标识实体的属性集。比如学号是学生的键,一个学号唯一标识一名学生。学号和课程号是成绩的键,因为学号和课程号唯一标识一门课程的成绩
实体型:对实体的描述,比如学生(学号,姓名,院系)
实体集:实体的集合
联系(relationship):实体集之间的关系。一名学生对应一个寝室(一对一),一个院系对应多名学生(一对多),多位教师对应多名学生(多对多)
关系(relation):若干元组的集合,说白了就是指数据库表
关系模式:对关系的描述称为关系模式,最后会详细描述
关系模型:若干关系的集合,也就是一个数据库
属性(关系):相对于前面的属性的意义,这里特指数据库表中的某列
元组:一条数据库记录
分量:元组中某一属性值
域:一组具有相同数据类型的值的集合,是属性的取值范围,比如性别属性的域就是{男,女},学生学历属性的域就是{学士、硕士、博士、院士}
候选键:可唯一标识某一元组的属性组,属性组中各个属性缺一不可。【t_student】(学号,姓名,学院),姓名可能会重复,所以其中学号可以唯一标识一条记录,学号就是t_student的候选键。那么假设姓名不会重复,那么候选键就有学号和姓名两个。 又比如【t_grade】(学号,课程,成绩),其中一个学生可以有多条成绩记录,所以需要学号和课程号组合才可以唯一标识一条数据库记录,所以学号、课程号就是t_student的一个候选键。
超键:只要一个属性组可以唯一标识一个元组,那么就说这个属性组是超键 【t_student】(学号,姓名,学院),姓名可能会重复,所以(学号)是一个超键同时也是候选键,(学号,姓名)可唯一标识一个元组,所以其也是超键,但不是候选键,因为少了姓名也可以唯一标识。
主属性:候选键中的属性称为主属性。【t_student】(学号,姓名,学院),学号就是主属性
非主属性:不是主属性就是非主属性呗。【t_student】(学号,姓名,学院),姓名、学院就是非主属性
全键:极端情况下表的所有属性组成该表的候选键,则称为全键
主键/主码:primary key,一个表可能有多个,往往选中一个作为主键
外键/外码:foreign key,假设表A的某个属性attr是另一表B中的主键,且A和B有某种联系,则称attr是外键
参照表:外键所在的表
被参照表:外键所引用(foreign key references)的表
数据完整性:数据完整性就是指数据的正确性和相容性(符合逻辑),又分为实体完整性、参照完整性、用户自定义完整性
实体完整性:主键唯一且不为空
参照完整性:不允许引用不存在的实体。参照表插入某条记录,这条记录的外键在被参照表中必须存在
用户自定义完整性:由用户自定义的数据约束。比如性别只能用男、女表示,人的年龄在0-120之间。常见的用户自定义完整性有NOT NULL,UNIQUE,CHECK等
内模式:对数据库的物理存储结构和存储方式的描述,是数据库在数据库内部的存储方式。拿MySQL来讲,每建一个表,都会在文件系统上生成一个或多个文件,这些文件存储了数据、表信息、索引信息,这就称为内模式
模式:对内模式的抽象,即数据库
外模式:对模式的抽象,即用户直接使用的应用程序
外模式-模式映像:保证数据的逻辑独立性。当模式改变时(增加表,增加表的结构),可以保证外模式不变
模式-内模式映像:保证数据的物理独立性。当内模式改变时(比如MySQL切换了存储引擎),可以保证模式不变,从而外模式也不会变。
关系模式
关系模式是对关系的描述(有哪些属性,各个属性之间的依赖关系如何),模式的一个具体值称为模式的一个实例。模式反应是数据的结构及其联系,是型,是相对稳定的,实例反应的是关系某一时刻的状态,是值,是相对变动的。
想要查看t_student的关系模式?DESC t_student
想要查看t_student的关系实例?SELECT * FROM student
另外,关系模式有约定的数学表示,R(U,D,DOM,F),R指关系名,U指一组属性,D指域,DOM指属性到域的映射,F就是指数据依赖。举个栗子,假设一个学生表t_student,拥有属性学号,姓名,性别,学院,其数学表示如图。

数据库复习
第一周
1.1
- Database
- Data: facts and statistics collected together for reference or analysis (Oxford dictionary)
- Database: a shared collection of logically related data (and a description of this data), designed to meet the information needs of an organization.
- Entity: a distinct object in the organization that is to be represented in the database.
- Attribute: a property that describes some aspect of the object that we wish to record.
- Relationship: an association between entities.
- Database Management Systems (DBMS)
- A software system that enables users to define, create, maintain, and control access to the database.
- (Database) application program: a computer program that interacts with database by issuing an appropriate request (SQL statement) to the DBMS.
- Schema vs Data
- The description of the database is the database schema.
比如ER model is an example of schema
- Data is the actual information stored in the database.
- The three-level ANSI-SPARC architecture
External level, conceptual level, internal level
- Advantages and disadvantages of DBMS
- Advantage of DBMSs
• Control of data redundancy• Data consistency
• More information from the same amount of data• Sharing of data
• Improved data integrity• Improved security• Enforcement of standards
• Economy of scale• Balance conflicting requirements
• Improved data accessibility and responsiveness• Increased productivity
• Improved maintenance through data independence• Increased concurrency
• Improved backup and recovery services
- Disadvantages of DBMSs
• Complexity• Size• Cost of DBMS
• Additional hardware costs• Cost of conversion
• Performance• Higher impact of a failure
1.2
- Relational model
- In the relational model, all data is logically structured within relations (tables).
- Each relation is made up of attributes(columns) of data.
- Each tuple (row) contains one value per attribute.
- 专业名词
- Relation: A relation is a table with columns and rows.
- Attribute: An attribute is a named column of a relation.
- Domain: the set of allowable values for one or more attributes.
- Tuple: A tuple is row of a relation.
- Degree: the number of attributes in a relation.即列数
- Cardinality: the number of tuples in a relation.即行数
- Relational database: A collection of normalized relations with distinct relation names.
- Creating relations (tables) in SQL
Create Table Branch(branchNo, street, city, postcode)
- Relational keys
- Candidate Key
定义A set of attributes that uniquely identifies a tuple within a relation.
性质Uniqueness : In each tuple, candidate key uniquely identify that tuple.
Irreducibility: No proper subset of the candidate key has the uniqueness property.
- Primary Key
Candidate key selected to identify tuples uniquely within relation.
- Foreign Key
Attribute, or set of attributes, within one relation that matches candidate key of some (possibly same) relation.
- Composite Key
A candidate key that consists of two or more attributes.
- Integrity constraints
- Entity Integrity
In a base relation, no attribute of a primary key can be null.
- Referential Integrity
If foreign key exists in a relation, either foreign key value must match a candidate key value of some tuple in its home relation or foreign key value must be null.
- Relational Algebra
定义Relational algebra is formal language associated with the relational model.
- 注意projection会去除重复,所以有的时候先projection会出错,即先selection再projection更普适,比如:
![]()
- union会消除重复
- Division: v除以w即找出A中能对应B中的全部数的数(即既对应B中的1又对应B中的2的数)
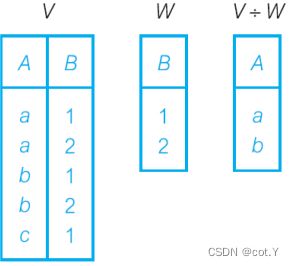
一般当题目里出现all xx 看了/买了/做了.. all xx的字眼时,用division,例如:
Identify all clients who have viewed all properties with three rooms.
结果为:

1.3
- Data model
A data model is a graphical description of the components of database.
- Entity-relationship (E-R) modelling
- E-R modelling is a high-level conceptual modelling technique for DB applications
- Main concepts (building blocks)
– Entity
– Attributes
– Relationship
- Relationship
Relationship describes a linkage between two entities and is represented by an arc between them.
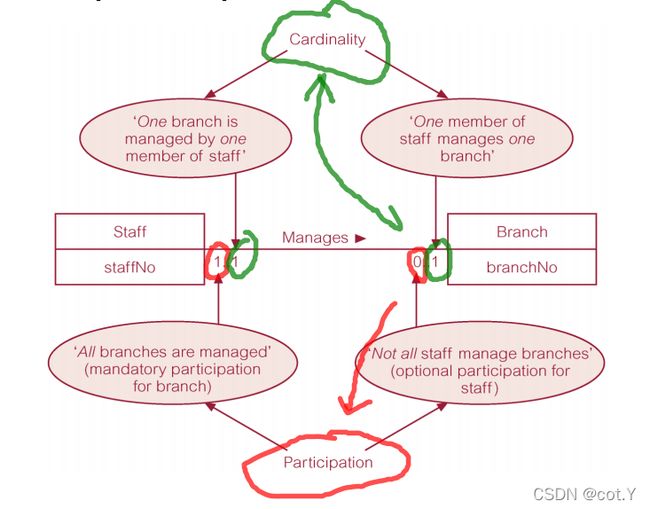
- Structural Constraints
- Main type of constraint on relationships is called multiplicity.
- Multiplicity - number (or range) of possible occurrences of an entity type that may relate to a single occurrence of an associated entity type through a particular relationship(?)
- The most common degree for relationships is binary. Binary relationships are generally referred to as being:
– one-to-one (1:1)
– one-to-many (1:*)
– many-to-many (*:*)
- Multiplicity is made up of two types of restrictions on relationships: cardinality and participation.
Cardinality– Describes maximum number of possible relationship occurrences for an entity participating in a given relationship type.
Participation– Determines whether all or only some entity occurrences participate in a relationship.
即两个entity的relationship之间标的数字的意义为,一个对方能xx(或被xx)的自己的最小到最大个个数

- Relationship Types
- Degree of a Relationship
– Number of participating entities in a relationship.
- Relationship of degree
Binary, ternary, Quaternary
2.1
- Specialization / Generalization
- Superclass/subclass relationship is one-to-one (1:.
- Not all members of a superclass need be a member of a subclass.
- Specialization
– Process of maximizing differences between members of an entity by identifying their distinguishing characteristics.
- Generalization
– Process of minimizing differences between entities by identifying their common characteristics.
- 当考虑一个问题要不要用superclass/subclass关系时,看各个类有没有自己的独特attributes。因为subclass一般都是有跟superclass一样的属性,但也有自己新的独特的属性才需要。所有subclass里的属性都是独特属性,superclass里的属性是subclass共有的
- Constraints on Specialization / Generalization
- Participation constraint
– Determines whether every member in superclass must participate as a member of a subclass.
– May be mandatory or optional.
即看superclass的member是不是必须是subclass里的某一个,若是,则为mandatory,若不是,即还可以为除了subclass里提到的之外的属性时,则为optional
- Disjoint constraint
– Describes relationship between members of the subclasses and indicates whether member of a superclass can be a member of one, or more than one, subclass.
– May be disjoint or nondisjoint.
即若superclass里的member只能为subclass里的某一个时,用or (disjoint), 若可以同时为subclass里的好几个,则用and (nondisjoint)
2.2
- Mapping ER model concepts to relations
- 1: *
把1的pk作为fk放到多里
- 1:1
随便放哪个里都可以,尽量使null值最少
- 1:* recursive
follow the rules for participation as described above for a 1:m relationship. An additional column for the foreign key, is created for the entity at the “many ” side of the relationship.(?)
- *:*
新建一个relation,把原先两个relation的pk放到新的relation里作为pk
- Ternary relationship
新创建一个relation,将三个relation里的PK都放进去作为fk
- Multi-valued attributes
新建一个relation,把多值attribute作为原relation的fk,作为新建的relation的pk(?)
- Superclass/subclass relationship types
- Mandatory and : 单个relation
- Optional and : 两个relation;superclass一个relation,所有的subclass共用一个relation
- Mandatory or : 多个;每个combined superclass/subclass一个relation
- Optional or : 多个; superclass一个relation,每个subclass一个relation
2.3
- SQL
- SQL is a transform-oriented language with 2major components:
– A DDL for defining database structure.
– A DML for retrieving and updating data.
- It is non-procedural
- it is essentially free-format.
- DDL - create table and drop table
DML - insert, delete, update, select
2.4
Database Design Methodology
• Main phases
– Gather requirements
– Conceptual database design
– Logical database design
– Physical database design
第三周
3.1
- normalization的两种作用:
Use normalization as a bottom-up technique to create set of relations.
Use normalization as a validation technique to check structure of relations.
- Update anomalies
Relations that contain redundant information may have problems called update anomalies:有三种:
Insertion anomalies:需要插入没有pk的一行信息时会出错
Deletion anomalies: 删除带有某个信息的一行时使得那一行的其他唯一的数据丢失
Modification anomalies: 修改某个参数时需要修改包含它的很多行
- Decomposition
为处理有更新异常的表格的解决方法;有两个性质:
Lossless-join property: ensures that any instance of the original relation can be identified from corresponding instances in the smaller relations.
Dependency preservation property: ensures that a constraint on the original relation can be maintained by enforcing some constraint on each of the smaller relations.
- Functional Dependencies
- Functional dependency describes relationship between attributes.
- B is functionally dependent on A (denoted A——>B),(or A functionally determines B), if each value of A in R is associated with exactly one value of B in R.
- The determinant of a functional dependency refers to the attribute or group of attributes on the left-hand side of the arrow.
- Full functional dependency
Determinants should have the minimal number of attributes necessary to maintain the functional
dependency with the attribute(s) on the right hand-side.
if A and B are attributes of a relation, B is fully functionally dependent on A, if B is functionally
dependent on A, but not on any proper subset of A.
即箭头左边的attributes全部为必要的不可再删最小组合,即B不可与A的真子集也形成这个关系
- Partial functional dependency
A functional dependency A -> B is a partial dependency if there is some attribute that can be removed from A and the dependency still holds.
- fd的characteristics
There is a one-to-one relationship between the attribute(s) on the left-hand side (determinant) and those on the right-hand side of a functional dependency.
- Transitive Dependencies
A, B, and C are attributes of a relation such that if A → B and B → C, then C is transitively dependent on A via B
- 1NF——>2NF
- Identify the functional dependencies in the relation.
- Identify the primary key for the 1NF relation.
- If partial dependencies on primary key exist, remove the partially dependent attributes from the relation by placing the attributes in a new relation along with a copy of their determinant.
把partial dependency移出来分别取一个relation名字后以各自的determinant做主键,B作attributes.
- 2NF
A relation that is in first normal form and every non-candidate-key attribute is fully functionally dependent on any candidate key.
- 3NF
A relation that is in first and second normal form and in which no non-candidate-key attribute is transitively dependent on any candidate key.
即2NF里没有partial fd, 3NF里没有transitive fd
- 2NF——>3NF
- Identify functional dependencies
- Identify the primary key in the 2NF relation
- If transitive dependencies exist, remove the transitively dependent attributes from the relation by placing the attributes in a new relation along with a copy of their determinant.
例如A->b,c,d 而其中c->d
则改写成: A->b,c c->d
3.2
- Boyce–Codd Normal Form (BCNF)
- 定义:A relation is in BCNF if and only if every determinant is a candidate key.
- Every relation in BCNF is also in 3NF. However, a relation in 3NF is not necessarily in BCNF
- The potential to violate BCNF may occur in a relation that:
– contains two (or more) composite candidate keys;
– the candidate keys overlap, that is have at least one attribute in common.(?)
- 将relation分解为BCNF时,对于不符合BCNF的fd:
-Pick any R’ with A->B that violates BCNF
-Decompose R’ into R1(A, B) and R2(A, rest)(?)
- A set of functional dependencies {AB → C, C → B} cannot be represented by a BCNF schema
- MVD
- Although BCNF removes anomalies due to functional dependencies, another type of dependency called a multi-valued dependency (MVD) can also cause data redundancy.
- Possible existence of multi-valued dependencies in a relation is due to 1NF and can result in data redundancy.
- 定义:Dependency between attributes (for example, A, B, and C) in a relation, such that for each value of A there is a set of values for B and a set of values for C. However, the set of values for B and C are independent of each other.
- trivial or nontrivial MVD
MVD可以被分为trivial的和nontrivial的:
- Trivial:
若满足a)B is a subset of A 或者 b)A并上B = R.
则称MVD A −>> B in relation R 是trivial的
- Nontrivial:
若以上a),b)两点都不满足,则称为nontrivial
- 4NF
Defined as a relation that is in Boyce-Codd Normal Form and contains no nontrivial multi-valued dependencies.
即4NF满足两个条件,一是in BCNF, 即所有的determinant都是candidate key;二是不包含nontrivial MVD, 即不存在既不满足B是A的子集,又不满足A并上B等于R的A—>>B.(也就是说所有的A—>>B要么满足a,要么满足b,或者都满足)
- Decomposition Properties
- Lossless: Data should not be lost or created when splitting relations up
- Dependency preservation: It is desirable that FDs are preserved when splitting relations up
- Normalization to 3NF is always lossless and dependency preserving
- Normalization to BCNF is lossless, but may not preserve all dependencies
3.3
Transaction
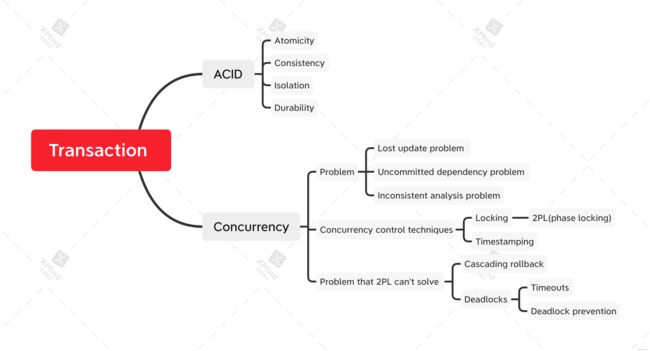
- 定义:Action, or series of actions, carried out by user or application, which reads or updates contents of database.
- Four basic properties of a transaction(ACID):
Atomicity: ‘All or nothing’ property
Consistency: Must transform database from one valid state to another.
Isolation: Partial effects of incomplete transactions should not be visible to other transactions.
Durability: Effects of a committed transaction are permanent and must not be lost because of later failure.
- Concurrency problems
This leads to several problems: (All arise because isolation is broken)
- Lost updates problem:
Successfully completed update is overridden by another user.

- Uncommitted dependency problem
Occurs when one transaction can see intermediate results of another transaction before it has committed.
Failure to commit causes a rollback, but other transactions are unaware of the rollback.

- Inconsistent analysis problem
Occurs when a transaction reads several values from the database but a second transaction updates some of them during the execution of the first.
Sometimes referred to as dirty read or unrepeatable read.

- Concurrency control
process of managing simultaneous operations on the database without having them interfere with one another.
- Schedule(?)
- Schedule: A schedule is a sequence of the operations by a set of concurrent transactions that preserves the order of the operations in each of the individual transactions.
- serial schedule: A serial schedule is a Schedule where operations of each transaction are executed consecutively without any interleaved operations from other transactions.
Serial schedules are guaranteed to avoid interference and keep the database consistent.
No guarantee that results of all serial executions of a given set of transactions will be identical.
即不能保证给定一组事务的所有串行执行的结果都是相同的
- Nonserial Schedule: Schedule where operations from set of concurrent transactions are interleaved.
- Serialisability
- serialisability identifies those executions of transactions guaranteed to ensure consistency.(?)
即将来自一组并发事务的操作交织在一起的时间安排
- Objective of serialisability is to find nonserial schedules that allow transactions to execute concurrently without interfering with one another.即serialisability的目标是找到允许事务并发执行而不相互干扰的nonserial schedule
- In other words, The objective of serialisability is to find nonserial schedules that are equivalent to some serial schedule. Such a schedule is called serialisable.
即如果nonserial schedule = serial schedule,则称该nonserial schedule 是serialisable schedule
- Conflict Serialisability
- 对两个 transactions,若at least one is a write and they use the same resource,则称这Two transactions have a conflict
- A schedule is conflict serialisable if transactions in the schedule have a conflict but the schedule is still serializable.
- Concurrency Control Techniques
- Two basic concurrency control techniques: Locking and Timestamping
- These two both are conservative approaches: delay transactions in case they conflict with other transactions.
- Locking
- Two types of lock: shared lock(read-lock); exclusive lock(write-lock)
- Basic rules:
Read-lock allows several transactions simultaneously to read a resource (but no transactions can change it at the same time).
Write-lock allows one transaction exclusive access to write to a resource. No other transaction can read this resource at the same time.
- Locks are released on commit/rollback
- A transaction may not acquire a lock on any resource that is write-locked by another transaction
- A transaction may not acquire a write-lock on a resource that is locked by another transaction
- If the requested lock is not available, transaction waits.
- Two-Phase Locking (2PL)
- All locking operations precede unlock operation in the transaction.
- Principle: Once a lock has been released, no new items can be locked.
- Two phases for transaction:
Growing phase - acquires all locks but cannot release any locks.
Shrinking phase - releases locks but cannot acquire any new locks.
- 2PL cannot solve: Cascading rollback, Deadlocks
A.Cascading Rollback:
定义: a transaction (T1) causes a failure and a rollback must be performed. Other transactions dependent on T1's actions must also be rollbacked, thus causing a cascading effect.
How to prevent the cascading rollback with 2PL?: Postpone the release of all locks until end of the transaction.
B.Deadlock
A deadlock occurs when two (or more) transactions are each waiting for locks held by the other to be released.
Only one way to break deadlock: abort one or more of the transactions.
General techniques for handling deadlock: • Timeouts.• Deadlock prevention.
- Timestamping
- 定义A unique identifier created by DBMS that indicates relative starting time of a transaction.
- No locks so no deadlock.
- There are also timestamps for data items: read-timestamp and write-timestamp
- Database recovery:
定义Process of restoring database to a correct state in the event of a failure.
有两种:Logs and checkpoints
- Log file
Contains information about all updates to database: Transaction records and Checkpoint records.
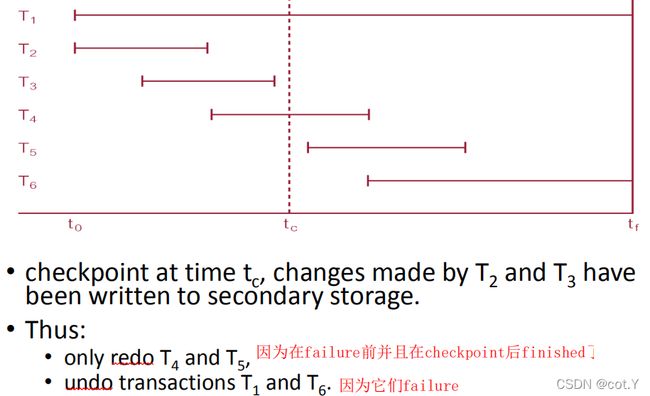
- Checkpointing
即在checkpoint点之前commit的事务已经写入到第二存储,不作变化;在checkpoint后,failure之前commit的事务要redo;在checkpoint之后且在failure的时候仍未commit的事务要undo.
3.4
- Database architectures
- 两个elements:
Client: the machine running the user interface of the applications.
Database server: the machine that runs the DBMS and contains the database.
- Categories:
A.Personal databases
B.Two-tier databases
Computers (client) connected over wired or wireless local area network (LAN)
The database itself and the DBMS are stored on a central device called the database server, which is also connected to the network.
即在二级数据库中,client的主要任务是user interface和main business, data processing logic, database server的主要任务是database access
C.Multi-tier databases.
对于三级数据库,client的任务是user interface, application server的任务是business logic和data processing logic, database server的任务是database access
- Distributed Database
- Distributed Database
A logically interrelated collection of shared data (and a description of this data), physically spread over a computer network.
- Distributed DBMS
Software system that permits the management of the distributed database and makes the distribution transparent to users.
- Distributed DBMS与Distributed Processing的区别
- Distributed processing
centralized database that can be accessed over a computer network

- Distributed DBMS (DDBMS)
Single logical database that is split into fragments, and these fragments are distributed over a computer network
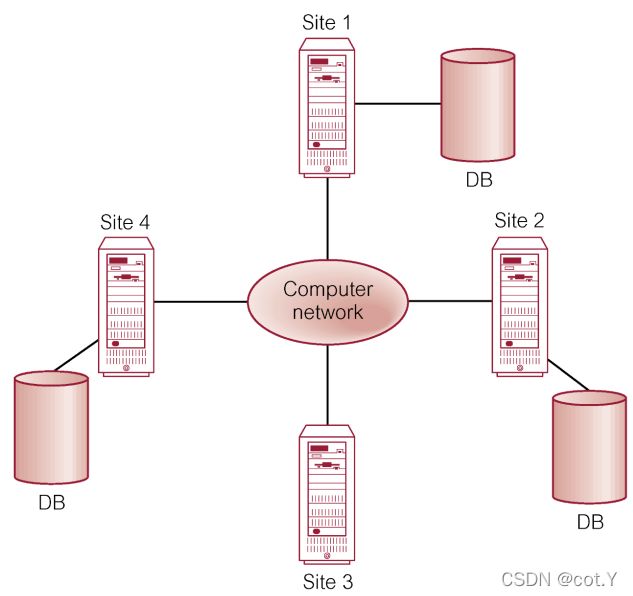
即区别在于,distributed processing只有一个中央的database,而distributed DBMS有分散的多个database
- DDBMS(distributed DBMS)的分类
- Homogeneous DDBMS
All sites use same DBMS product.
- Heterogeneous DDBMS
Sites may run different DBMS products, with possibly different underlying data models.
Solution: Gateways
- Distributed Database Design – key issues
- Fragmentation
- Allocation
- Replication
- Fragmentation
- Correctness of fragmentation
Completeness; Reconstruction; Disjointness
- Types of Fragmentation
- Horizontal Fragmentation
Consists of a subset of the tuples of a relation. Defined using the Selection operation of relational algebra: ![]()
- Vertical Fragmentation
Consists of a subset of attributes of a relation.
Defined using the Projection operation of relational algebra:![]()
- Mixed Fragmentation
Defined using Selection and Projection operations of relational algebra:
![]() 或
或![]()
- Transparency
Hiding DDBMS complexity, is called transparency
Using distributed database should feel like a centralized database.分为:
Distribution Transparency
Transaction Transparency
Performance Transparency
DBMS Transparency
- Distributed Query Processor (DQP)
- Advantages and disadvantages of DDBMSs
- Advantages of DDBMSs
• Reflects organizational structure
• Improved shareability and local autonomy
• Improved availability
• Improved reliability
• Improved performance
• Economics
• Modular growth
- Disadvantages of DDBMSs
• Complexity
• Cost
• Security
• Integrity control more difficult
• Lack of standards
• Lack of experience
• Database design more complex
4.1
XML
A meta-language (a language for describing other languages) that enables designers to create their own customized tags to provide functionality not available with HTML.
Also streaming format
XML has a document format similar to HTML
XML - Element
First element must be a root element, which can contain other (sub)elements.
XML elements are case sensitive
An element can be empty, in which case it can be abbreviated to
XML - Attributes
Attributes are name-value pairs that contain descriptive information about an element.
XML – Other Sections
XML declaration: optional at start of XML document.E.g.,
Entity references: serve various purposes, such as shortcuts to often repeated text or to distinguish reserved characters from content.(?) E.g., < is the same as <
Comments: enclosed in tags,E.g.,
XML – Ordering
elements are ordered
attributes are unordered.
XML is a markup specification language
“Well-Formed” XML
Single root element
Matched tags, proper nesting
Unique attributes within elements
Document Type Definitions (DTDs)
Defines the valid syntax of an XML document.
DTDs – Element Type Declarations
Options for repetition are:
* zero or more occurrences for an element;
+ one or more occurrences for an element;
? zero occurrences or (exactly) one occurrence for an element.
Name with no qualifying punctuation must occur exactly once.(?)
Commas between element names indicate they must occur in succession; if commas omitted, elements can occur in any order.
#PCDATA: parsable character data, declares the base element
DTDs – Attribute List Declarations
Some types:
• CDATA: character data, containing any text.
• whether an attribute must occur (#REQUIRED) or not (#IMPLIED),
• ID: used to identify individual elements in document (ID is an element name).
• IDREF/IDREFS: must correspond to value of ID attribute(s) for some element
in document.
• List of names: values that attribute can hold
• ID allows unique key to be associated with an element.
• IDREF allows an element to refer to another element with the designated key.
• IDREFS allows an element to refer to multiple elements.
例如: •
•
(In DTD, do not have data type)(?)
XML Schema (XSD)
XML schema is the definition (both in terms of its organization and its data types) of a specific XML structure.
• Like DTDs, can specify elements, attributes, nesting, ordering, occurrences
• Also data types, keys, (typed) pointers, and more.
Schema is an XML document, and so can be edited and processed by same tools that read the XML it describes.
Specifies that an attribute/element value (or set of values) must be a key within the containing element in an instance document.
Specifies that an attribute or element value (or set of values) correspond to those of the specified key or unique element.
Occurrences: Specifies the min/max number of occurrences
XML Schema – Simple Types
Elements that do not contain other elements or attributes are of type simpleType.
(?)Attributes must be defined last:
XML Schema – Complex Types
• Elements that contain other elements are of type complexType.
Cardinality
• Cardinality of an element can be represented using attributes minOccurs and maxOccurs.
To represent an optional element, set minOccurs to 0; to indicate there is no maximum number of occurrences, set maxOccurs to “unbounded”.
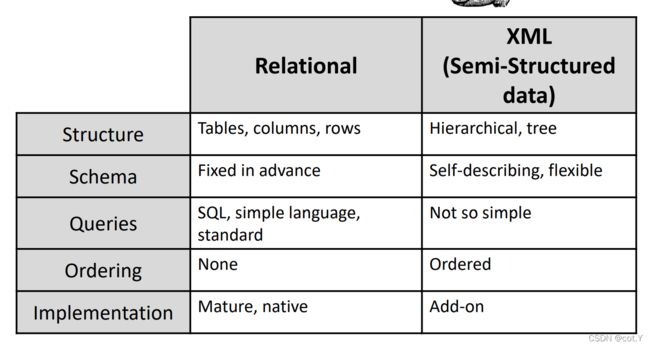
Relational Model versus XML:
Relational model for structured data, XML for semi-structured data
Relational model is none-ordering, XML is ordered
4.2
Data Warehousing Concepts:
A subject-oriented, integrated, time-variant, and non-volatile collection of data in support of management’s decision-making process (Inmon, 1993).
Integrated Data
The data warehouse integrates
• corporate application-oriented data
• from different source systems
OLTP and OLAP
• OLTP: OnLine Transaction Processing
Transactional
o provide source data to data warehouses
OLAP: OnLine Analytical Processing
Analytical
Main types of access tools:
• Online Analytical Processing (OLAP)
• Data mining.
Online Analytical Processing (OLAP)
Original definition - The dynamic synthesis, analysis, and consolidation of large volumes of multi-dimensional data, Codd (1993).
Common key features:
• multi-dimensional views of data• support for complex calculations• time intelligence
How to represent multi-dimensional data
• relational table,
• matrix
• data cube
Dimensional Hierarchy
A dimensional hierarchy defines mappings from a set of lower-level concepts to higher level concepts
The analytical operations that can be performed on data cubes include:
• Roll-up• Drill-down• Slice and Dice• Pivot
4.3

Data mining: The process of extracting valid, previously unknown, comprehensible, and actionable information from large databases and using it to make crucial business decisions.
Characteristics:
Data Mining Operations:
Four main operations include:
• Predictive modeling• Database segmentation• Link analysis• Deviation detection
XML is a semi-sturcture xx
And NoSQl is another
还有一些练习题
Block 1
1.Which of below represents "data"?
2.A relational model contains:
a. A set of tables
b. Unorganised data
c. Operations using non-SQL language.
d. None of the above
3.A primary key is which of the following?
a. Any attribute
b. An attribute that uniquely identifies each column of a relation.
c. Set of attribute(s) that uniquely identifies each row of a relation.
d. None of the above
4.A relation has which of the following properties?
a. Each row may not be unique.
b. Each relation has a unique name.
c. Attributes can have same names within a relation.
d. The order of columns is significant.
5.Which of the following statement about relational algebra operations is CORRECT?
a. The result of a relational algebra operation may be a relation or a data.
b. Selection gives a horizontal subset of a relation.
c. Relation R has 5 tuples and relation S has 10 tuples. The result relation of R X S (cartesian product) has 15 tuples.
d. None of the above
6.For DreamHome Rental Database, private owner Tina Murphy wants to know the viewing comments on all of her properties for rent. Which of the following statements gives the correct result?

ANSWER: cacbbb
Block 2
1.In an Enhanced Entity-Relationship Model, the relationship between a superclass and its subclass is:
a. 1:m relationship
b. 1:1 relationship Correct
c. m:m relationship
d. None of the above
2.Which of the following statements about EER is correct?
a. Generalization is the process of maximizing the differences between members of an entity by identifying their distinguishing features.
b. Specialization is the process of maximizing the differences between members of an entity by identifying their distinguishing features.
c. A subclass is an entity that includes one or more distinct subgroupings of its occurrences.
d. None of the above
3.Consider the library database. Apart from the fact that book copies can be loaned to borrowers, a new fact is introduced that the library has a number of book copies that are no longer suitable for loaning out. These books can be sold for a fraction of the original cost. However, not all library book copies are eventually sold as many are considered too damaged to sell on, or are simply lost or stolen. Each book copy that is suitable for sale has a price and the date that the copy is no longer to be loaned out.
How would you model this requirement in a EER model?
a. One entity for book copy that can be loaned, one entity for book copy that can be sold, one entity for book copy that cannot be sold.
b. One superclass for book copy, one subclass for book copy that can be loaned, one subclass for book copy that can be sold, one subclass for book copy that cannot be sold.
c. One entity for book copy, with attributes indicating different kinds of book copies.
d. None of the above.
4.Which is the subset of SQL commands used to manipulate Database structures, including tables?
a. Data Definition Language(DDL)
b. Data Manipulation Language(DML)
c. Both of the above
d. None of the above
5.Which operator in SQL performs pattern matching?
a. EXISTS operator
b. BETWEEN operator
c. LIKE operator
d. None of the above
6.What operator in SQL tests column for the absence of data?
a. NOT EXISTS operator
b. IS NULL operator
c. NOT operator
d. None of the above
7.In SQL, which command is used to SELECT only one copy of each set of duplicable rows?
a. SELECT DISTINCT
b. SELECT UNIQUE
c. SELECT DIFFERENT
d. None of the above
8.Which of the following aggregate functions include NULL values?
a. MAX
b. COUNT
c. AVG
d. COUNT(*)
9.Table Employee has 10 records. It has a NON-NULL SALARY column which is also UNIQUE.
The SQL statement:
SELECT COUNT(*) FROM Employee
WHERE SALARY > ANY (SELECT SALARY FROM EMPLOYEE);
returns what?
a. 10
b. 9
c. 0
d. None of the above
10.Which of the following SQL commands can be used to add data to a database table?
a. ADD
b. UPDATE
c. APPEND
d. INSERT
answer : bbbac badbd
1.2

1.3-exercise1

1.3-exercise2

1.3-exercise3

1.3-exercise

2.1

2.3

3.1
3.3
