CCNet: Criss-Cross Attention for Semantic Segmentation论文阅读
CCNet: Criss-Cross Attention for Semantic Segmentation
Abstract
上下文信息对于语义分割和目标检测任务都很重要,这里提出CCNet。对于每个像素,criss-cross attention模块能获得其交叉路径上所有像素的上下文信息,通过进一步的递归操作,每个像素最终可以捕获全图像的依赖关系。此外,提出类别一致损失使得criss-cross attention模块生成更具判别性的特征。CCNet有以下优点:(1)GPU显存友好,比non-local block少11倍显存消耗 (2)高计算效率,比non-local block少85% (3)最先进性能,Cityscapes可达81.9%
开源地址:https://github.com/speedinghzl/CCNet
这里推荐一篇很有意思的工作,通过注意力机制处理预测head关联多目标跟踪领域的检测和ReID特征:Rethinking the competition between detection and ReID in Multi-Object Tracking,该论文不但构思了一种简单有效的注意力机制,还巧妙地利用注意力机制来交叉关联两个任务,避免了检测和ReID的竞争,并联合提升了彼此分支的性能。
Introduction
FCN是固定的几何结构(卷积的网格效应),局部感受野只能提供短距离上下文信息。为了弥补FCN的缺点,deeplab系列提出多尺度空洞卷积结构的ASPP模块聚合上下文信息,PSPNet引入金字塔池化模块捕获上下文信息。然而,基于空洞卷积的方法从一些周围像素收集信息,不能准确产生稠密的上下文信息;基于池化的方法以非自适应的相同上下文提取策略处理所有像素,不能满足不同像素需要不同上下文依赖的要求。Non-local的空间和时间复杂度高,需要改进。
Related work
UNet,Deeplabv3+,MSCI,SPGNet,RefineNet,DFN采取encoder-decoder结构,融合低层次和高层次信息做出稠密预测。Scale-adaptive Convolutions(SAC)和Deformable Convolutional Network(DCN)改善标准卷积处理目标形变和各种尺寸目标…
Approach
1.Network Architecture
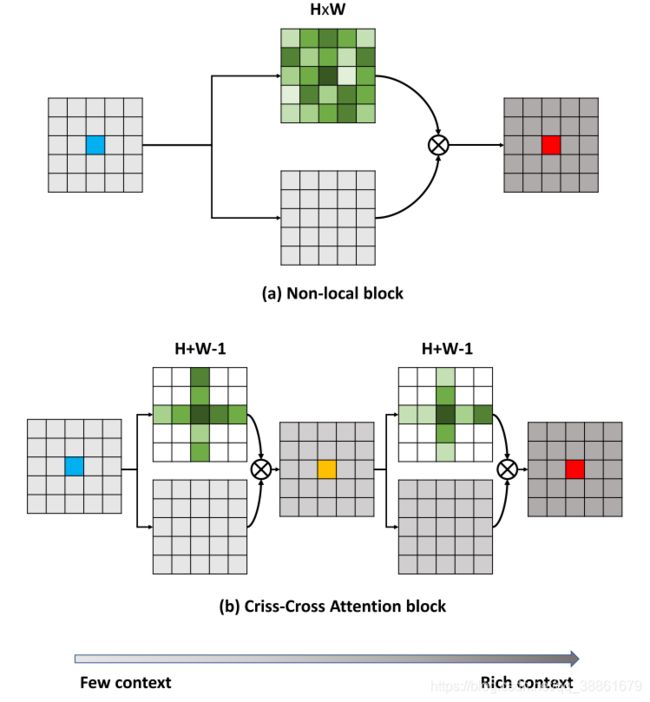
上图是Non-local block和Criss-Cross Attention block结构的简化示意图,Non-local block通过计算任意两个位置之间的交互直接捕获远距离依赖,而不用局限于相邻点,但是由于每个位置对应的向量(共 H × W H\times W H×W个)都要和 H × W H\times W H×W个向量相乘,带来的计算量偏大;而Criss-Cross Attention block一次只用考虑"十字交叉"的同行同列的向量,即每个位置对应的向量( H × W H\times W H×W个)都要和 ( H + W − 1 ) (H+W-1) (H+W−1)个向量相乘,这样捕获的是一个位置和”十字交叉“路径上其他位置的依赖,但是将输出结构果再次送入Criss-Cross Attention block即可获得一个位置与全局位置的依赖,进一步的理解可以看下文的Criss-cross Attention模块细节。
Backbone是全卷积网络,移去最后两个下采样操作,并且随后的卷积层都采取空洞卷积(带空洞卷积的FCN),输出特征图 X X X为输入图像的1/8。 X X X通过卷积层降低通道维度输出 H H H, H H H送入criss-cross attention模块聚合每个像素交叉路径上的上下文信息得到 H ′ H' H′, H ′ H' H′再次送入criss-cross attention模块输出 H ′ ′ H'' H′′,则 H ′ ′ H'' H′′的每个像素聚合了所有像素的信息。两个criss-cross attention模块共享参数,取名为recurrent Criss-Cross Attention(RCCA)模块。然后, H ′ ′ H'' H′′和特征 X X X进行concat,接着是一个或几个带BN的卷积层和激活层用于特征融合,最后融合的特征送入分割层预测最终的分割结果。
2.Criss-cross Attention
考虑一个局部特征图 H ∈ R C × W × H H\in \mathbb{R}^{C\times W\times H} H∈RC×W×H,首先通过两个 1 × 1 1\times1 1×1卷积生成两个特征图 Q Q Q和 K K K, { Q , K } ∈ R C ′ × W × H \{Q,K\} \in{\mathbb{R}^{C'\times W\times H}} {Q,K}∈RC′×W×H, C ′ C' C′是比 C C C小的通道数,形状为 C ′ × H × W C'\times H\times W C′×H×W的三维特征图可以很容易reshape成二维的 C ′ × ( H × W ) C'\times (H \times W) C′×(H×W)的矩阵。通过Affinity操作生成注意力图 A A A,对于特征图 Q Q Q的每一个位置 u u u,拉出一条维度为 C ′ C' C′的向量 Q u ∈ R C ′ Q_u\in \mathbb{R}^{C'} Qu∈RC′。同时,从特征图 K K K拉出同属于 u u u位置的同行或同列的 ( H + W − 1 ) (H+W-1) (H+W−1)条( H + W H+W H+W会包括 u u u位置两次)维度均为 C ’ C’ C’的向量集 Ω u ∈ R ( H + W − 1 ) × C ′ \Omega_{u}\in\mathbb{R}^{(H+W-1)\times C'} Ωu∈R(H+W−1)×C′, Ω i , u ∈ R C ′ \Omega_{i,u}\in\mathbb{R}^{C'} Ωi,u∈RC′是 Ω u \Omega_{u} Ωu的第 i i i个元素(向量),则Affinity操作可用公式表达如下: d i , u = Q u Ω i , u T d_{i,u}=Q_u\Omega_{i,u}^T di,u=QuΩi,uT d i , u ∈ D d_{i,u}\in D di,u∈D是特征 Q u Q_u Qu和 Ω i , u \Omega_{i,u} Ωi,u之间的关联度, i = [ 1 , . . . , H + W − 1 ] i=[1,...,H+W-1] i=[1,...,H+W−1],且 D ∈ R ( H + W − 1 ) × ( W × H ) D\in \mathbb{R}^{(H+W-1)\times (W\times H)} D∈R(H+W−1)×(W×H),然后对 D D D在通道维度上添加softmax层,输出注意力图A
输入特征图H通过另外一个 1 × 1 1\times1 1×1卷积生成特征图 V ∈ R C × W × H V \in{\mathbb{R}^{C\times W\times H}} V∈RC×W×H,对于特征图 V V V的每一个位置 u u u,同理拉出维度为 C C C的向量 V u ∈ R C V_u\in \mathbb{R}^{C} Vu∈RC和向量集 Φ u ∈ R ( H + W − 1 ) × C \Phi_u \in \mathbb{R}^{(H+W-1)\times C} Φu∈R(H+W−1)×C,然后给出聚合(Aggregation)操作的公式如下: H u ′ = ∑ i = 1 H + W − 1 A i , u Φ i , u + H u H_u'=\sum_{i=1}^{H+W-1}A_{i,u}\Phi_{i,u}+H_u Hu′=i=1∑H+W−1Ai,uΦi,u+Hu
其中, H u ′ H_u' Hu′是 H ′ ∈ R C × W × H H' \in \mathbb{R}^{C\times W \times H} H′∈RC×W×H中位置 u u u的特征向量, A i , u A_{i,u} Ai,u是注意力图A中位置 u u u对应的第 i i i个数值。最后是以残差的形式输出 H ′ H' H′,增强了像素级的表达能力,并聚合了全局上下文信息,提升了语义分割的性能。
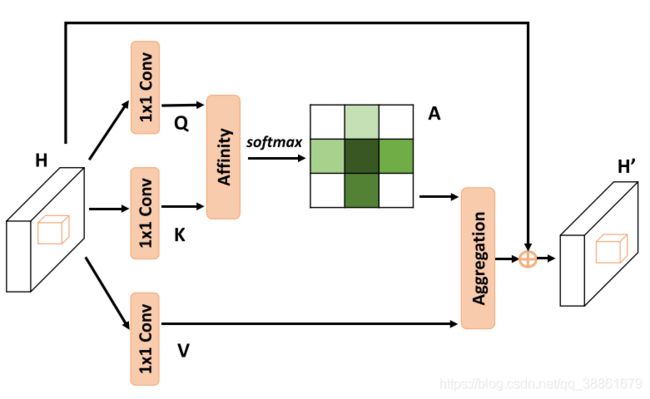
Recurrent Criss-Cross Attention(RCCA)模块包含两个Criss-Cross Attention模块,且是共享参数的,RCCA可获得一个位置与全局位置的依赖,能够获得稠密丰富的下文信息。
3.Learning Category Consistent Features
对于语义分割任务,同一类像素应该有相似的特征,不同类像素应该有差别大的特征,这被称作类别一致性。论文认为,RCCA模块聚合的特征可能会存在过度平滑的问题,这是图神经网络的常见问题,因此除了使用交叉熵损失 l s e g l_{seg} lseg监督外,还提出了类别一致损失。RCCA模块输出后接 1 × 1 1\times1 1×1卷积降低特征图通道数(这里设置16),在这个低通道数特征图 M M M上添加类别一致性损失。假定 C C C是mini-batch images里存在的类别数, N c N_c Nc是属于类别 c ∈ C c\in C c∈C的有效元素数目, h i ∈ H h_i \in H hi∈H是特征图M空间位置 i i i对应的特征向量( i i i是属于类别 c c c的,是 N c N_c Nc中的一个元素), u c u_c uc是类别 c c c的平均特征向量(聚类中心), φ v a r ( h i , u c ) \varphi_{var}(h_i,u_c) φvar(hi,uc)计算两者之间的距离进行惩罚,希望同类别像素对应的特征向量具有相似性,靠近该类聚类中心最好; u c a u_{c_a} uca和 u c b u_{c_b} ucb是两个不同类别的聚类中心(特征向量), φ d i s ( u c a , u c b ) \varphi_{dis}(u_{c_a},u_{c_b}) φdis(uca,ucb)计算两个类别中心之间的距离进行惩罚,两两类别计算,希望不同类别像素的聚类中心越远越好。 l r e g l_{reg} lreg是聚类中心向量的正则项损失,最终损失是所有损失的加权和: l = l s e g + α l v a r + β l d i s + γ l r e g l=l_{seg}+\alpha l_{var}+\beta l_{dis}+\gamma l_{reg} l=lseg+αlvar+βldis+γlreg其中,设置 δ v = 0.5 , δ d = 1.5 , α = β = 1. γ = 0.001 \delta_v=0.5,\delta_d=1.5,\alpha=\beta=1.\gamma=0.001 δv=0.5,δd=1.5,α=β=1.γ=0.001。总之,类别一致损失是从特征上,希望同类别像素特征具有相似性,不同类相似特征具有差异性。损失具体公式如下:
