torchtext 中文语料加载
torchtext 中文语料加载
- 前言
- 数据集准备
- torchtext流程
- Field
- TabularDataset
- BucketIterator
前言
因为研究生方向选的是自然语言处理,准备提前接触下相关技术内容。在pytorch学习中发现有个torchtext库,说是用来文本处理,就接触一下。
发现目前网上资料都有点过时了(毕竟这东西出了这么久,总有版本更新)。所以自己另开一个帖子记录以下内容。
……
数据集准备
数据集就选了个常用的网上数据集,关于携程酒店评论。基本就如图所示:

label代表评论标签,1为正面情绪,0为负面情绪。
review代表评论内容。
数据集可以在网上搜搜,到处都是。我这里放一个下载链接。
数据集下载地址
不过如果使用我这个数据集,在后续分词时会报错,因为里面有一行内容为空。删去之后才能正常进行运作。

就这里,非常阴险得空了一条数据。
torchtext流程
简单来说, torchtext主要有三个部分。Field, TabularDataset,BucketIterator(或者是 Iterator,不过我还没试)。这部分先粗略介绍一下大致作用。
Field在我看来就是定义一个接收要求,或者说是处理条件。用于处理文本数据。
TabularDataset就是接受的数据集,就是pytorch中Dataset翻版,不过里面定义了一些文本处理操作,然后存储数据。相比自定义的Dataset而言,TabularDataset里一些预定义功能省去我们nlp中文本处理时间,但有些时候不如Dataset灵活。
BucketIterator就是pytorch中DataLoader翻版,可以进行批次训练。
如上而言,基本使用过程就是先定义Field规则,然后定义TabularDataset存放数据,TabularDataset中使用Field规则。最后将TabularDataset放入定义的
BucketIterator中进行批次训练。
下文将逐步详细介绍。
Field
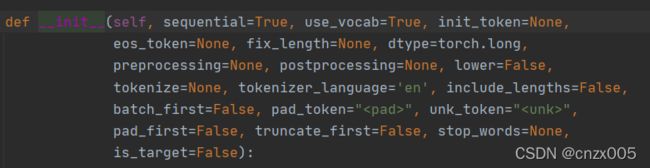
Field主要参数如图,在中文语料加载中基本只用到 sequential,use_vocab,fix_length, tokenize, stop_words五个属性(我感觉)。
sequential表示是否展示成序列,用在要分词的语料内容上。
use_vocab表示是否使用词典对象,用在要分词的语料内容上。后续将对应词转化为词向量需要。
fix_length表示句子长度,用在要分词的语料内容上。在nlp中,如果输入的是句子,必须确保每个句子维度相同,过长截取,过短补充(pad_token负责充当补充符)
tokenize表示分词函数,用在要分词的语料内容上。可以自定义,也可以用自带的。
stop_words表示停用词,用在要分词的语料内容上。
首先定义分词函数,我这里采用自定义分词函数,北大的pkuseg。
import pkuseg
seg = pkuseg.pkuseg()
# 定义分词函数
def tokenizer(text):
return seg.cut(text)
然后定义Field
from torchtext.legacy.data import Field
TEXT = Field(sequential=True, tokenize=tokenizer, fix_length=385)
LABEL = Field(sequential=False, use_vocab=False)
Field要求每一种需要的属性,都必须定义Field,本文中我们需要评论内容和标签,所以定义两个Field。
TEXT代表评论内容,需要分词以及序列化。fix_length是统计数据中大部分句子长度得来的,这里不仔细描述。
而LABEL 作为标签,自然无需序列化和词典使用。
需要注意的是,我之前看过许多torchtext描述的代码,对于Field的导入方式都已经过时。在最新版中,必须用 from torchtext.legacy.data import Field 来导入。
后续的TabularDataset,BucketIterator也是一样。
这部分整体代码如下:
import pandas as pd
from torchtext.legacy.data import Field
import pkuseg
import torch
# 使用种子
torch.manual_seed(114514)
# 读取数据
df = pd.read_csv('../data/drink/train.csv')
seg = pkuseg.pkuseg()
# 定义分词函数
def tokenizer(text):
return seg.cut(text)
TEXT = Field(sequential=True, tokenize=tokenizer, fix_length=385)
LABEL = Field(sequential=False, use_vocab=False)
读取的数据为train.csv是因为后续训练需要划分训练集与验证集,所以我从原数据集抽了一些评论,分成train.csv(训练集)与valid.csv(测试集)。
TabularDataset
from torchtext.legacy.data import TabularDataset
train_field = [('label', LABEL), ('content', TEXT)]
train, val = TabularDataset.splits(
path='../data/drink', train='train.csv',
validation='valid.csv', format='csv',
fields=train_field, skip_header=True)
这部分还是比较简单,首先定义TabularDataset,加载训练集与验证集。
path代表数据的路径。
train,validation代表训练集与验证集的文件名。splits可以直接通过TabularDataset构造训练集,验证集与测试集。不过本文中并没有测试集。
format代表文件格式。支持csv,tsv,json格式。
skip_header代表读取数据时是否跳过表头。
fields代表文字处理形式,需用到前文所定义的Field。
train_field = [('label', LABEL), ('content', TEXT)]
如上文,左边为装入TabularDataset后的属性名,右边为处理Field格式。
则 label 对应数据集的 label ,而 content 对应数据集中 review
该顺序必须与数据集中一致。同时数量也不能缺失。
如果不想将对应属性装载如TabularDataset,右侧Field改为None。如下图所示:
test_field = [('label', None), ('content', TEXT)]
因为在测试集中并不需要label标签,改为None后TabularDataset便不会加载。
TabularDataset构造完成后,需要将其中的词语转化成词向量。一般使用预训练词向量glove,当然也可以使用自己训练的词向量,比如用word2vec。
TEXT.build_vocab(train, min_freq=3, vectors='glove.6B.50d')
min_freq表示最短词频,低于其的词语不会进行训练。
glove.6B.50d是预训练词向量,没有的话,系统会自动下载。
这一块的整体代码如下:
import pandas as pd
from torchtext.legacy.data import Field, TabularDataset
import pkuseg
import torch
# 使用种子
torch.manual_seed(114514)
# 读取数据
df = pd.read_csv('../data/drink/train.csv')
seg = pkuseg.pkuseg()
# 定义分词函数
def tokenizer(text):
return seg.cut(text)
TEXT = Field(sequential=True, tokenize=tokenizer, fix_length=385)
LABEL = Field(sequential=False, use_vocab=False)
# 因为测试集不要label,所以在field中令label列传入None
# 因为训练集要label,所以在field中令label列传入
test_field = [('label', None), ('content', TEXT)]
train_field = [('label', LABEL), ('content', TEXT)]
train, val = TabularDataset.splits(
path='../data/drink', train='train.csv',
validation='valid.csv', format='csv',
fields=train_field, skip_header=True)
TEXT.build_vocab(train, min_freq=3, vectors='glove.6B.50d')
BucketIterator
Bucketiterator是torchtext最强大的功能之一。Bucketiterator和Iterator的区别是,Bucketlterator尽可能的把长度相似的句子放在一个batch里面。
而且Bucketiterator会自动将输入序列进行shuffle并做bucket,不过,需要告诉Bucketiterator想在哪个数据属性上做bucket。
from torchtext.legacy.data import BucketIterator
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_batch_size = 64
val_batch_size = 64
train_iter, val_iter = BucketIterator.splits(
(train, val),
batch_sizes=(train_batch_size, val_batch_size),
device=device,
sort_key=lambda x: len(x.content),
sort_within_batch=False,
repeat=False
)
运行完毕后我们可以看看内容结构和我们想象的差不多

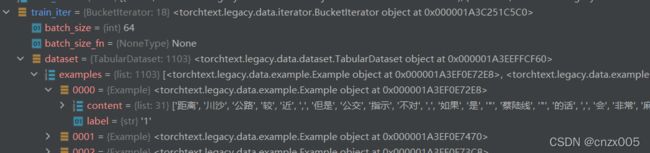
使用debug看到,所需的内容都被装载进去了。
这样就成功将中文语料加载入torchtext 中,之后就可以加入模型训练,跟一般pytorch训练没有什么差别。
总体而言,torchtext 还是满便利的,把一些分词,构建词序表等操作简化,还是值得一试的。