联邦学习概念及应用
联邦学习
0,联邦学习概念
联邦学习是使得多方在不共享本地数据的前提下,进行多方协同训练的机器学习方式。因此,他在实现功能的同时,能够很好的保护数据隐私。目前联邦学习支持的算法:SecureBoost,线性回归,逻辑回归,神经网络算法等。
1,特点
数据绝对掌握:每一个参与方数据都不离开本地,模型信息在各参与方之间以加密的形式传输,且保证不能由模型推测出原始数据;
参与方不稳定:不同参与方在计算能力、通信稳定性方面存在差异,导致联邦学习相对于分布式机器学习存在不稳定情况;
通信代价高:参与方不稳定造成通信代价高;
数据非独立同分布:不同参与方数据分布不同;
负载不均衡:参与方在数据量级上存在差异,但联邦学习中无法实现负载均衡。
2,分类
我们用数据集(I,X,Y)表示训练样本,按照样本和特征的分布情况,可以将联邦学习分为:
横向联邦学习(Horizontal Federated Learning,HFL),适用于特征信息重叠较多的场景,通过提升样本数量达到训练模型效果的提升。比如两个异地的银行之间就可以构建横向联邦学习模型。

纵向联邦学习(Vertical Federated Learning,VFL),适用于参与双方样本重叠较多时的场景,通过丰富样本特征维度,实现机器学习模型的优化。比如银行和商业公司之间可以构建纵向联邦学习模型。
联邦迁移学习(Federated Transfer Learning,FTL),样本和特征重叠都较少时,需要进行数据迁移。
3,架构设计
3.1,横向联邦模型
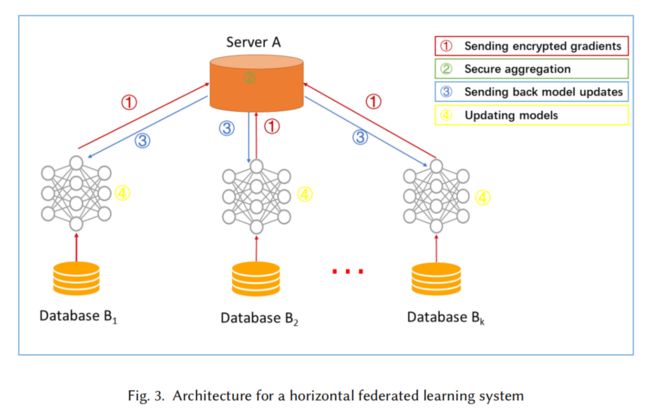
训练步骤:
Step 1: participants locally compute training gradients, mask a selection of gradients withencryption [51], differential privacy [58] or secret sharing [9] techniques, and send maskedresults to server;
Step 2: Server performs secure aggregation without learning information about any participant;
Step 3: Server send back the aggregated results to participants;
Step 4: Participants update their respective model with the decrypted gradients.
说明:
-
定义client是诚实的,server是诚实且好奇的。
-
最终的训练模型共享。
3.2,纵向联邦模型
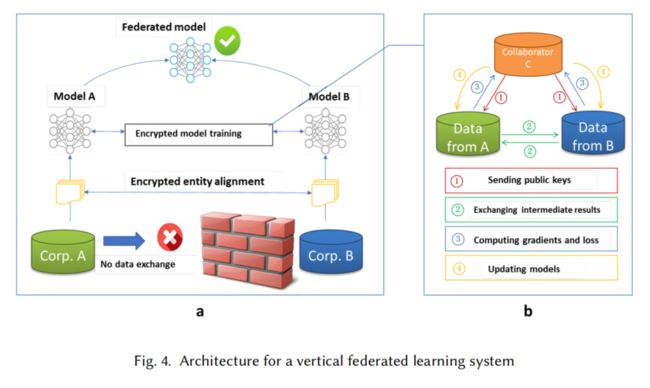
训练步骤:
part1:Encrypted entity alignment,即隐私求交(PSI);
part2:Encrypted model training.
Step 1: collaborator C creates encryption pairs, send public key to A and B;
Step 2: A and B encrypt and exchange the intermediate results for gradient and loss calculations;
Step 3: A and B computes encrypted gradients and adds additional mask, respectively,and B also computes encrypted loss; A and B send encrypted values to C;
Step 4: C decrypts and send the decrypted gradients and loss back to A and B; A and B unmask the gradients, update the model parameters accordingly.
说明:
- 定义client是诚实且好奇的,collaborator C是诚实的;
- 预测阶段,各参与方协作输出结果。
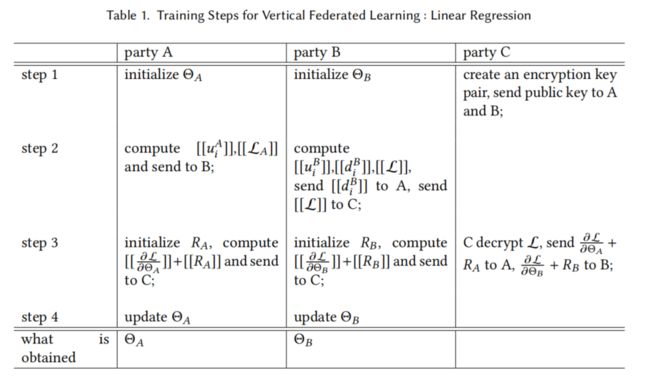
3.3,纵向联邦线性回归案例
背景:A,B双方利用纵向联邦算法共同训练线性回归模型,B方拥有标签y为active party,A为passive party。
理论推导:
定义:全局损失函数如(5),θ表示模型参数,λ表示惩罚系数;(6)式表示加密后用u表示的损失函数;然后我们将(6)展开,分别用 [ [ L A ] ] [[L_A]] [[LA]], [ [ L B ] ] [[L_B]] [[LB]] [ [ L A B ] ] [[L_{AB}]] [[LAB]]表示A方,B方的损失,以及含有AB双方的损失,得到(7)式;再然后我们将含有AB双方模型的那一项令为[[d]],由此求得双方各自的梯度得到(8)(9).

tips:线性回归模型中,我们通常使用梯度下降法不断迭代梯度值直到模型收敛找到最小损失。因此,对于训练来讲,双方都需要梯度数据。
训练过程如下:
第一步:A,B初始化参数,C生成密钥对,并分发公钥;
第二步:A计算模型A和损失A并发给B;B收到后便可以计算损失并发送给C,d发送给A,以及模型B;
第三步:A生成随机数RA,计算[[梯度A+RA]]发送给C;B生成随机数RB,计算[[梯度B+RB]]发送给C;C解密并返回;
第四步:AB分别减去各自的随机数便得到共同训练的全局梯度,然后各自更新模型。
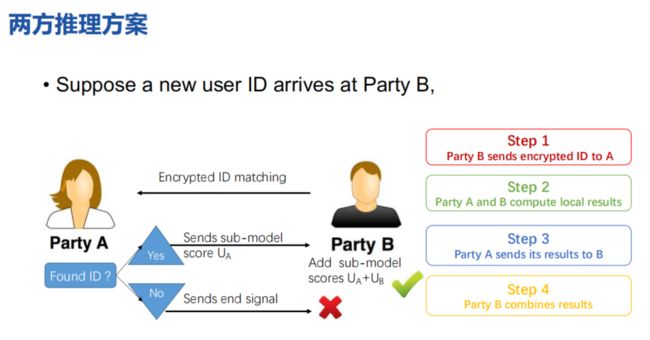
预测过程如下:
通过协调方C输入用户特征,AB分别计算结果并发送给C,C将结果相加即得到最终结果。

思考:上面的协作者C仅仅是分发公钥以及判断收敛的作用。可以不要呢?
纵向线性回归的两方方案:



4,研究方向
- 解决通信效率问题
针对横向联邦,google提出了FedAvg联邦平均算法,但有研究发现,其通信效率与模型收敛速度成反比;
- 中间数据安全问题
引入同态加密,但也增加了计算代价;
半同态加密技术对中间结果加密,存在解密过程,仅对私钥持有者单向隐私保护。
梯度数据可能存在反向推理风险,采用差分隐私技术,通过添加噪声,不仅造成收敛速度变慢,模型精度也会有损失;
隐私求交问题(纵向联邦样本对齐过程),虽然能过保护非交集内数据,但交集内数据存在泄露风险;
- 健壮性问题
联邦学习本质是分布式机器学习,也存在着拜占庭将军问题。
5,参考链接
Federated Machine Learning Concept and Applications
联邦学习白皮书V2.0
https://www.fedai.org/research/conferences/ccf-tf-talk-no-14-chinese-version-only/
Advances and Open Problems in Federated Learning
Advances and Open Problems in Federated Learning-中文版