知识 :卷积神经网络性能优化
转自:AI蜗牛车、极市平台
作者丨黎明灰烬
来源|https://zhuanlan.zhihu.com/p/80361782
引言
卷积(Convolution)是神经网络的核心计算之一,它在计算机视觉方面的突破性进展引领了深度学习的热潮。卷积的变种丰富,计算复杂,神经网络运行时大部分时间都耗费在计算卷积,网络模型的发展在不断增加网络的深度,因此优化卷积计算就显得尤为重要。
随着技术的发展,研究人员提出了多种优化算法,包括 Im2col、Winograd 等等。本文首先定义卷积神经网络的概念,继而简要介绍几种常见的优化方法,并讨论作者在该领域的一些经验。
大部分时间都耗费在计算卷积链接:
https://arxiv.org/abs/1807.11164
Im2col 链接:
https://www.mathworks.com/help/images/ref/im2col.html
Winograd 链接:
https://www.intel.ai/winograd/#gs.avmb0n
卷积神经网络的概念
卷积神经网络(Convolution Neural Networks, CNN)的概念拓展自信号处理领域的卷积。信号处理的卷积定义为
 (1)
(1)
由于对称性![]() 卷积计算在直觉上不易理解,其可视化后如图一所示。图中红色滑块在移动过程中与蓝色方块的积绘制成的三角图案即为卷积结果 (∗)() 在各点上的取值。
卷积计算在直觉上不易理解,其可视化后如图一所示。图中红色滑块在移动过程中与蓝色方块的积绘制成的三角图案即为卷积结果 (∗)() 在各点上的取值。
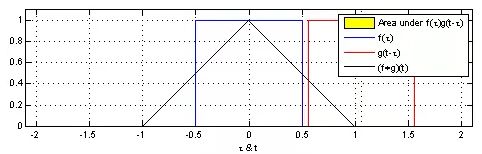
图一:信号处理中的卷积
信号处理中的卷积链接:
https://jackwish.net/convolution-neural-networks-optimization.html
公式1的离散形式为 :
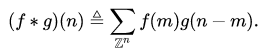 (2)
(2)
将该卷积拓展到二维空间即可得到神经网络中的卷积,可简写为:
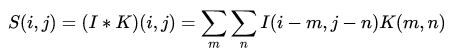 (3)
(3)
其中 为卷积输出, 为卷积输入, 为卷积核。该计算的动态可视化可以参考 conv_arithmetic,这里不再介绍。
conv_arithmetic 链接:
https://github.com/vdumoulin/conv_arithmetic
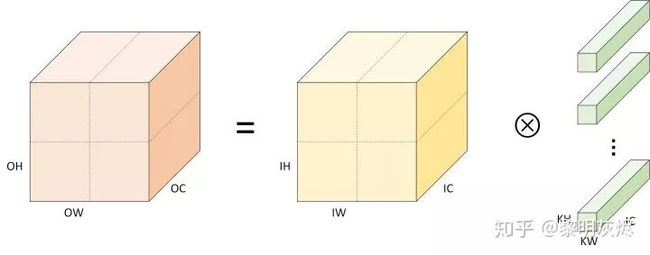
当应用到计算机视觉中处理图片时,图片的通道(Channel)可以对二维卷积简单堆叠,即:
(4)
其中 c 是输入的通道。这便是在三维张量中应用二维卷积的计算。
很多时候,公式描述显得不是很直观,图二是堆叠的二维卷积的可视化。其中,与输入、输出、卷积核相关的标记带有前缀 I、O、K。此外,本文图例对输出、输入、卷积核三者的着色一般为:橙色、黄色、绿色。
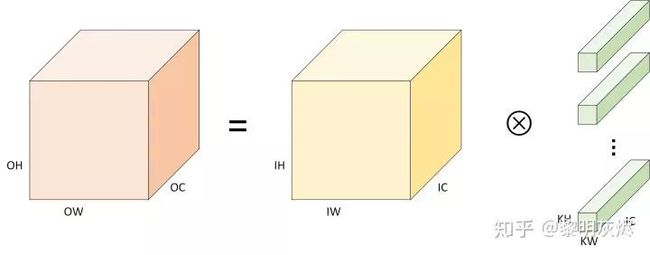
图二:卷积计算定义
当中张量的内存布局为 NHWC 时,卷积计算相应的伪代码如下。其中外三层循环遍历输出 C 的每个数据点,对于每个输出数据都需要经由内三层循环累加求和得到(点积)。
for (int oh = 0; oh < OH; oh++) {
for (int ow = 0; ow < OW; ow++) {
for (int oc = 0; oc < OC; oc++) {
C[oh][ow][oc] = 0;
for (int kh = 0; kh < KH, kh++){
for (int kw = 0; kw < KW, kw++){
for (int ic = 0; ic < IC, ic++){
C[oh][ow][oc] += A[oh+kh][ow+kw][ic] * B[kh][kw][ic];
}
}
}
}
}
}和矩阵乘的优化方法类似,我们也可针对该计算进行向量化、并行化、循环展开的基本的优化操作。卷积的问题在于其 和 一般不超过 5 ,这不容易向量化,而计算特征又有输入在空间维度存在数据复用。该计算的复杂性导致产生了几种优化方法,下面我们介绍几种。
和矩阵乘的优化方法链接:
https://jackwish.net/gemm-optimization.html
Im2col 优化算法
作为早期的深度学习框架,Caffe 中卷积的实现采用的是基于 im2col 的方法,至今仍是卷积重要的优化方法之一。
Im2col 是计算机视觉领域中将图片转换成矩阵的矩阵列(column)的计算过程。从上一节的介绍中可以看到,二维卷积的计算比较复杂不易优化,因此在深度学习框架发展的早期,Caffe 使用 Im2col 方法将三维张量转换为二维矩阵,从而充分利用已经优化好的 GEMM 库来为各个平台加速卷积计算。最后,再将矩阵乘得到的二维矩阵结果使用 Col2im 将转换为三维矩阵输出。
Caffe 链接:
http://caffe.berkeleyvision.org/
Caffe 使用 Im2col 方法将三维张量转换为二维矩阵链接:
https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo
算法过程
除非特别说明,本文默认采用的内存布局形式为 NHWC 。其他的内存布局和具体的转换后的矩阵形状或许略有差异,但不影响算法本身的描述。
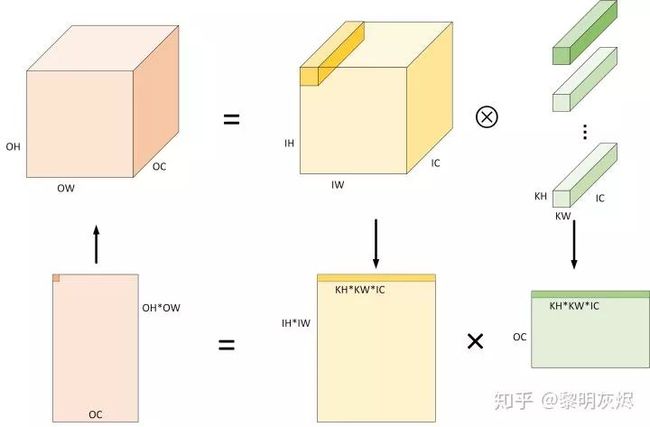
图三:Im2col 算法计算卷积的过程
图三是使用 Im2col 算法计算卷积的过程示例,具体的过程包括(简单起见忽略 Padding 的情况,即认为 =,=:
将输入由 ×× 根据卷积的计算特性展开成 (×)×(××) 形状的二维矩阵。显然,转换后使用的内存空间相比原始输入多约 ∗−1 倍。
权重的形状一般为 ××× 四维张量,可以将其直接作为形状为 ()×(××)) 的二维矩阵处理。
对于准备好的两个二维矩阵,将 (××) 作为累加求和的维度,运行矩阵乘可以得到输出矩阵 (×)×()。这一过程可以直接使用各种优化过的 BLAS(Basic Linear Algebra Subprograms)库来完成。
输出矩阵 (×)×() 在内存布局视角即为预期的输出张量 ×× 。
Im2col 计算卷积使用 GEMM 的代价是额外的内存开销。这是因为原始卷积计算中,卷积核在输入上滑动以计算输出时,相邻的输出计算在空间上复用了一定的输入输出。而用 Im2col 将三维张量展开成二维矩阵时,这些原本可以复用的数据平坦地分布到矩阵中,将输入数据复制了 ∗−1 份。
当卷积核尺寸 × 是 1×1 时,上述步骤中的 和 可以消去,即输入转换后形状为 (×)×(),卷积核形状为 ()×(),卷积计算退化为矩阵乘。注意观察,对于这种情况,Im2col 过程实际上并没有改变输入的形状,因此矩阵乘操作可以直接在原始输入上运行,从而省去内存组织的过程(即上述步骤中的 1、2、4 步)。
内存布局与卷积性能
神经网络中卷积的内存布局主要有 NCHW 和 NHWC 两种,不同的内存布局会影响计算运行时访问存储器的模式,特别是在运行矩阵乘时。本小节分析采用 Im2col 优化算法时计算性能性能和内存布局的关系。
特别是在运行矩阵乘时链接:
https://jackwish.net/gemm-optimization.html
在完成 Im2col 转换后,得到用于运行矩阵乘的输入矩阵和卷积核矩阵。对计算过程施加矩阵计算中常用的数据划分、向量化等优化方法(相关定义请参考通用矩阵乘(GEMM)优化算法)。下面着重分析在这种场景下,不同内存布局对性能的影响。
通用矩阵乘(GEMM)优化算法链接:
https://jackwish.net/gemm-optimization.html
首先考虑 NCHW 内存布局,将 NCHW 内存布局的卷积对应到矩阵乘 = 时, 是卷积核(filter), 是输入(input),各个矩阵的维度如图四所示。图中的 ,, 用于标记矩阵乘,即![]() ,同时标记出它们和卷积计算中各个维度的关系。
,同时标记出它们和卷积计算中各个维度的关系。
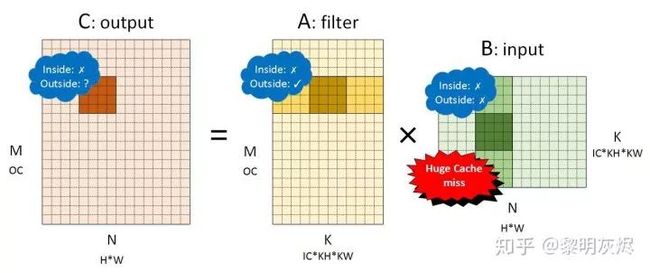
图四:NCHW 内存布局卷积转换成的矩阵乘
对该矩阵施行划分后,我们详细分析局部性的表现,并标记在图四中。其中 Inside 表示 4×4 小块矩阵乘内部的局部性,Outside 表示在削减维度方向小块之间的局部性。
对输出而言,小块内访存局部性较差,这是因为每次向量化加载会加载四个元素,每次加载都会发生缓存缺失(Cache miss)。外部表现取决于全局计算方向——行优先则局部性较好,列优先则较差。输出的行为不是这里的讨论终点,毕竟它没有访存复用。
对卷积核而言,小块内访存局部性较差,这和输出类似。当小块加载发生缓存缺失时,处理器会一次性加载一个缓存行(Cache line),这使得后续的若干个小块访存都能缓存命中(Cache hit),直到该缓存行全部命中后进入下一个缓存行的范围。因此小块外部局部性较好。
对输入而言,小块内访存局部性表现同样不好。然而不同于卷积核,小块中因缓存缺失加载到缓存中的缓存行数据只会被使用一次,因为这种内存布局中下一个小块的地址范围一般超出了一个缓存行。因此输入的几乎每次内存加载都会发生高速缓存缺失——Cache 没有起到加速的作用,每次访存都需要到内存取数据。
因此,用 Im2col 处理卷积计算时,NCHW 布局对内存很不友好。
图五是与之相对的 NHWC 内存布局的示例。值得注意的是,NHWC 和 NCHW 中 、 矩阵所代表的张量发生了调换——=×(调换一下只是不想多画一张图)。具体的拆分方式仍然一样,也正是上一小节中描述的步骤所构建的矩阵。
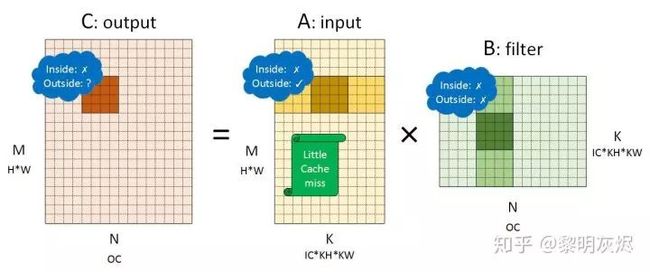
图五:NHWC 内存布局卷积转换成的矩阵乘
类似地,分析三个张量的访存表现可知:
对输出而言,NHWC 和 NCHW 表现一样。
对输入而言,小方块的内部局部性表现不是很好,因为几次向量加载都会发生缓存不命中;而外部局部性表现则较好,因为在削减维度滑动使用的内存是连续的。这种表现和 NCHW 中卷积核的表现一样,整体来看都是对高速缓存比较友好的内存布局。
对卷积核而言,NHWC 的情况和 NCHW 中输入的情况类似,小块内和小块外的局部性都较差。
两种内存布局中的卷积核缓存表现并不是问题,因为卷积核在运行期间保持不变,可以在模型加载阶段转换卷积核的内存布局,使其在小块外的内存对缓存友好(例如将 (××)×() 的布局转换为 ()×(×× )。这里值得说明的是一般框架或引擎的运行都至少可分为两个阶段:准备阶段和运行阶段。一些模型的预处理工作可以放在准备阶段完成,例如重新排布卷积核的内存布局这种在运行阶段保持不变的数据。
因此,当使用 Im2col 方法计算时,整体的访存表现取决于输入的情况,即 NHWC 的内存布局要比 NCHW 内存布局更加友好。我们在实践过程中的一个实验表明,对于一个 1×1 卷积核的卷积,当采用类似的优化方法时,从 NCHW 转换为 NHWC 可以将高速缓存缺失率从约 50% 降低到 2% 左右。这种程度的提高可以大幅改进软件的运行性能(这里特指不使用特别设计过的矩阵乘优化方法)。
空间组合优化算法
Im2col 是一种比较朴素的卷积优化算法,在没有精心处理的情况下会带来较大的内存开销。空间组合(Spatial pack)是一种类似矩阵乘中重组内存的优化算法。
矩阵乘中重组内存链接:
https://github.com/flame/how-to-optimize-gemm/wiki#packing-into-contiguous-memory
图六:空间组合优化算法对计算的划分
空间组合优化算法是一种基于分治法(Divide and Conquer)的方法——它基于空间特性将卷积计算划分为若干份,分别处理。图六所示是在空间上将输出、输入划分为四份。
划分后,一个大的卷积计算被拆分为若干个小的卷积计算。虽然在划分的过程中计算总量不变,但计算小矩阵时访存局部性更好,可以借由计算机存储层次结构获得性能提升。这通过图七中的步骤来完成。该步骤和上节中 Im2col 重组内存的过程类似:
在 H 和 W 维度划分,将形状为 ××× 的输入张量拆分为 ℎ∗ 个(两个方向分别拆分 ℎ 和 次)形状为 ×/ℎ×/× 的张量,分别将这些小的张量组织为连续内存;
将得到的 ℎ∗ 个输入张量分别和卷积核做二维卷积操作,即可得到 ℎ∗ 个形状为 ×/ℎ×/× 的输出张量;
将这些输出张量重组内存布局得到最终形状为 ××× 的输出。
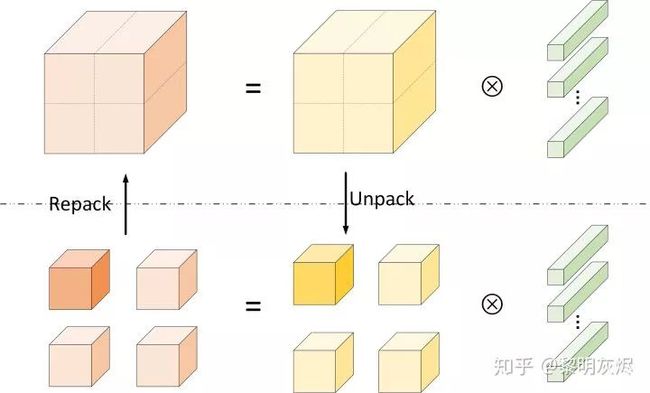
图七:空间组合计算的步骤
值得注意的是,方便起见,上文的描述中忽略了 Padding 的问题。实际在步骤 1 中将输入张量划分为若干个小张量时,除了将划分的小块中原始数据拷贝外,还需要将相邻的小张量的边界数据拷贝。具体而言,如图八所示,空间拆分得到的小张量的形状实际上是:
×(/ℎ+2(−1))×(/+(−1))×.(5)
这里的 2(−1) 和 2(−1) 遵循 Padding 规则。规则为![]() 时,它们可以忽略;规则为 SAME 时,位于源张量边界的一边 Padding 补
时,它们可以忽略;规则为 SAME 时,位于源张量边界的一边 Padding 补![]() ,不在源张量边界的 Padding 则使用邻居张量的值。只要考虑一下卷积的计算原理,这是显而易见的。
,不在源张量边界的 Padding 则使用邻居张量的值。只要考虑一下卷积的计算原理,这是显而易见的。

图八:空间组合算法的划分细节
上面的三个示例图都是拆分为 4 份的情况,实际应用中可以拆为很多份。例如可以拆成小张量边长为 4 或者 8 ,从而方便编译器向量化计算操作。随着拆分出的张量越小,其局部性也越高,负面作用是消耗的额外内存也越多。这些额外内存是由于 Padding 引入的。当拆分为 ℎ∗h∗w份时,拆分后 Padding 消耗的内存为:
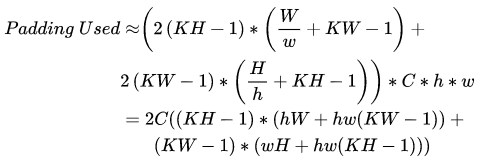
可以看到,随着拆分的粒度越小,额外消耗的内存越大。值得注意的是,当拆分到最细粒度时,即将在形状为 ××× 的输出的空间上拆分∗ 份时,空间组合退化为 Im2col 方法。此时在一个元素上的卷积即为矩阵乘计算一个输出元素时的点积。
只做空间划分时,划分与卷积核无关。而如果在输出的通道维度划分,卷积核也可做相应的拆分。通道维度的划分相当于固定空间划分后简单的堆叠,不会对影响内存消耗,但会影响局部性。对于不同规模的卷积,寻找合适的划分方法不是一件容易的事情。正如计算机领域的许多问题一样,该问题也是可以自动化的,例如 AutoTVM 可以在这种情况下寻找较优的划分方法。
AutoTVM 链接:
https://arxiv.org/abs/1805.08166
Winograd 优化算法
前两节介绍的两种算法,Im2col 在将三维张量组织成矩阵后调用 GEMM 计算库,这些计算库很大程度上使用一些基于访存局部性的优化;空间组合优化则本身就是利用局部性优化的方法。本小节介绍的 Winograd 优化算法则是矩阵乘优化方法中 Coppersmith–Winograd 算法的一种应用,是基于算法分析的方法。
这部分公式过多,排版不便,有兴趣的话可以参考原文或其他相关文献。
参考原文链接:
https://jackwish.net/convolution-neural-networks-optimization.html
间接卷积优化算法
Marat Dukhan 在 QNNPACK(Quantized Neural Network PACKage)中推出了间接卷积算法(The Indirect Convolution Algorithm),似乎到目前为止(2019 年中)依然是所有已公开方法中最快的。最近作者发表了相关的文章来介绍其中的主要思想。
虽然该算法在 QNNPACK 中的实现主要用于量化神经网络(业界的其他量化优化方案都比较传统 TensorFlow Lite 使用 Im2col 优化算法、腾讯出品的 NCNN使用 Winograd 优化算法;OpenAI 出品的 Tengine 使用 Im2col 优化算法),但其是一种同样的优化算法设计。
本文写作时设计文章尚未公开,而理解该算法设计很多细节内容,最好能结合代码理解。我的 QNNPACK fork 包含一个 explained 分支,其中对增加了对部分代码的注释,可作参考。
QNNPACK 链接:
https://github.com/pytorch/QNNPACK
TensorFlow Lite 使用 Im2col 优化算法链接:
https://github.com/tensorflow/tensorflow/blob/v2.0.0-beta1/tensorflow/lite/kernels/internal/optimized/integer_ops/conv.h
NCNN使用 Winograd 优化算法链接:
https://github.com/Tencent/ncnn/blob/20190611/src/layer/arm/convolution_3x3_int8.h
Tengine 使用 Im2col 优化算法链接:
https://github.com/OAID/Tengine/blob/v1.3.2/executor/operator/arm64/conv/conv_2d_fast.cpp
我的 QNNPACK fork 链接:
https://github.com/jackwish/qnnpack
计算工作流
间接卷积算法的有效工作以来一个关键的前提——网络连续运行时,输入张量的内存地址保持不变。这一特性其实比较容易满足,即使地址真的需要变化,也可以将其拷贝到固定的内存区域中。
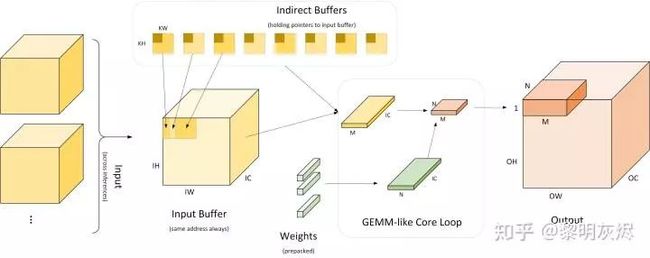
图九:间接卷积算法工作流
图九是间接卷积算法工作流的详细过程。最左侧部分表示多个输入使用相同的输入缓冲区(Input Buffer)。间接卷积算法会在该输入缓冲区基础上构建如图十的「间接缓冲区」(Indirect Buffer),而间接缓冲区是间接卷积算法的核心。如图中右侧,在网络运行时,每次计算出 × 规模的输出,其中 为将 × 视作一维后的向量化规模。一般 × 为 4×4、8×8 或 4×8 。在计算 × 规模大小的输出时,经由间接缓冲区取出对应使用的输入,并取出权重,计算出结果。计算过程等价于计算 × 和 × 矩阵乘。
在实现中,软件的执行过程分为两部分:
准备阶段:加载模型,配置输入缓冲区;重排权重,使其内存布局适用于后续计算;
运行阶段:对于每个输入,运行 ⌈∗/⌉∗⌈/⌉次核心循环,每次使用 GEMM 方法计算出 × 大小的输出。
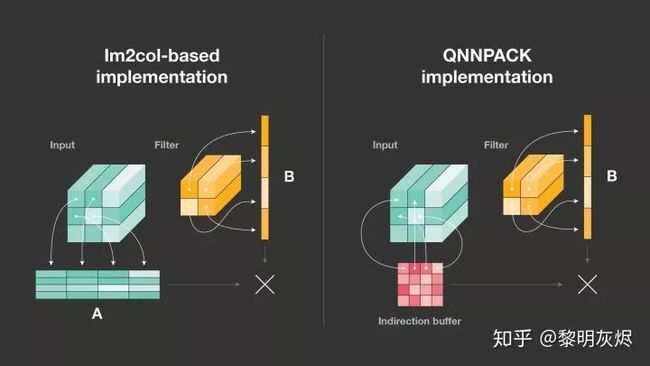
图十:间接缓冲区
如相关章节的讨论,Im2col 优化算法存在两个问题,第一是占用大量的额外内存,第二是需要对输入进行额外的数据拷贝。这两点如何才能解决呢?间接卷积算法给出的答案是间接缓冲区(Indirect Buffer),如图十右半所示。
图十是常规的 Im2col 优化算法和间接卷积优化算法的对比。正如相关小节介绍的那样,Im2col 优化算法首先将输入拷贝到一个矩阵中,如图十中 Input 的相关箭头,然后执行矩阵乘操作。间接卷积优化算法使用的间接缓冲区中存储的其实是指向输入的指针(这也是间接卷积优化算法要求输入内存地址固定的原因),在运行时根据这些指针即可模拟出类似于 Im2col 的矩阵计算过程。
间接缓冲区布局
间接缓冲区可以理解为是一组卷积核大小的缓冲区,共有 × 个,每个缓冲区大小为 ×——每个缓冲区对应着某个输出要使用的输入的地址。每计算一个空间位置的输出,使用一个间接缓冲区;空间位置相同而通道不同的输出使用相同的间接缓冲区,缓冲区中的每个指针用于索引输入中 个元素。在计算时,随着输出的移动,选用不同的间接缓冲区,即可得到相应的输入地址。无需再根据输出目标的坐标计算要使用的输入的地址,这等同于预先计算地址。
图十一绘制了当 × 为 4 、 和 均为 3 时,间接缓冲区的实际使用方法与计算过程。图中命名为局部间接缓冲区意指目前考虑的是计算 × 时核心计算的过程。
当计算 × 大小的输出时,使用的输入为卷积核在对应输入位置上滑动 步所覆盖的趋于,即规模 ()×(+2(−1))× 的输入。在间接卷积算法中,这些输入内存由 M个间接缓冲区中的指针索引,共有 ×× 个。图十一中标识出了输入空间位置左上角输入和相应的输入缓冲区的对应关系。可以看到,这里的 A、B、C、D 四个输入缓冲区,相邻的两个缓冲区所指向的地址区域有 (−)/ ,这里即为 2/3 ,各个缓冲区中指针的坐标也已标明。
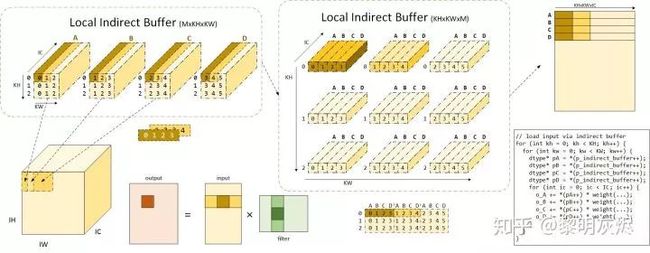
图十一:间接缓冲区详解
图中将平面缓冲区绘制成三维形式(增加 IC 维度),意在说明间接缓冲区的每个指针可索引 IC 个输入元素,而每个间接缓冲区索引的内容即为与权重对应的输入内存区域。
进一步地,左上角的输入缓冲区排列方式并不是最终的排布方法,实际上这些指针会被处理成图十一中部间接缓冲区的形式。将左上每个缓冲区中的指针打散,即可得到 × 指针,将 A、B、C、D 四个缓冲区的不同空间位置的指针收集到一起,即可得到图中上部分的缓冲区排列方式 ××。可以看到, A、B、C、D 四个缓冲区内部相同空间位置的指针被组织到了一起。图中中上部分是可视化的效果,中下部分则是间接缓冲区的真正组织方式。图中褐色和深黄色的着色对应着相同的输入内存或指针。值得注意的是,图例中 Stride 为 1,当 Stride 不为 1 时,重新组织后 A、B、C、D 相同空间的坐标(对应于在输入的坐标)不一定是连续的,相邻的空间位置横向坐标相差 大小。
使用间接缓冲区计算
我们已经知道了间接缓冲区的组织形式,以及其指针对应于输入内存的地址趋于,现在来研究在计算过程中如何使用这些缓冲区。
和上一小节一样,本小节的讨论大体都在计算 × 规模的输出,而这些输出要使用 个 × 大小的输入,其中有数据重用。现在回顾一下 Im2col 的算法(如图十一中下左部分),当向量化运行计算时,对于 × 的矩阵乘计算,每次取出 × 规模的输入和 × 规模的权重,对该块运行矩阵乘即可得到相应的部分和结果。其中 是向量化计算在 K维度上的步进因子。
而卷积之所以可以使用 Im2col 优化算法,本质原因在于其拆解后忽略内存复用后的计算过程等价于矩阵乘。而间接缓冲区使得可以通过指针模拟出对输入的访存。在实际运行计算 × 输出的计算核(micro kernel)时,会有 个指针扫描输入。个指针每次从图十一中下部分的间接缓冲区结构中取出 个地址,即对应于输入 × 的内存,如图中右上角的布局。在这里的步进中,仍是以 × 形式运行,其中 在 维度上运动。当这部分输入扫描完毕后,这 个指针从间接缓冲区中取出相应的指针,继续下一次对 × 输入内存的遍历,每次计算出 1/(∗) 的输出部分和。当这个过程运行 × 次后,即得到了 × 的输出。图十一右下角的伪代码对应了这一过程。由于间接缓冲区已经被组织成了特定的形状,因此每次更新 个指针时,只需要从间接缓冲区指针(图中伪代码里的 p_indirect_buffer)中获取。
这个过程的逻辑不易理解,这里再做一点补充说明。当上述的 个指针不断运动扫描内存时,实际上是在扫描三维输入 Im2col 之后的矩阵。而输入缓冲区的特定是它将对二维矩阵的扫描转化为了对三维张量的扫描。对输入的扫描过程即是对图十一中上部分可视化的输入的扫描,联系左上和左下对应的输入关系,不难发现它每次扫描输入中 × 块内存。值得注意的是,这里的 × 由 个 1× 张量组成,它们之间 维度的间距为 。
这样一来,只要运行该计算核心 ⌈∗/⌉∗⌈/⌉ 次,即可得到全部输出。
间接卷积优化算法解决了卷积计算的三个问题,第一是空间向量化问题,第二是地址计算复杂问题,第三是内存拷贝问题。一般计算卷积时都需要对输入补零(对于 × 不是 1×1 的情况),这个过程传统的方法都会发生内存拷贝。而间接卷积优化算法中的间接缓冲区可以通过间接指针巧妙地解决这一问题。在构造间接缓冲区时额外创建一块 1× 的内存缓冲区,其中填入零值,对于空间中需要补零的位置,将相应的间接指针指向该缓冲区,那么后续计算时即相当于已经补零。例如图十一中 A 的左上角对应于输入空间位置 (0,0) 的,当需要补零时该位置一定要为零值,此时只要修改间接缓冲区的地址即可。
讨论、总结与展望
至此,本文探讨了一些已经发表或开源的卷积神经网络的优化方法。这些优化方法或多或少地推动了深度学习技术在云端或移动端的应用,帮助了我们的日常生活。例如,最近上海人民乃至全中国人们头疼的垃圾分类问题,也可以利用深度学习方法来帮助人们了解如何分类。
利用深度学习方法来帮助人们了解如何分类链接:
https://news.mydrivers.com/1/633/633858.htm
从本文的集中优化方法中可以看到,卷积神经网络的优化算法依然可以囊括在基于算法分析的方法和基于软件优化的方法。实际上,在现代计算机系统中,基于软件优化的方法,特别是基于计算机存储层次结构的优化显得更为重要,因为其方法更容易挖掘和应用。另一方面也是因为现代计算机新增的专用指令已经可以抹除不同计算的耗时差异。在这种场景下,基于算法分析的方法要和基于软件优化的方法结合或许能取得更优的优化效果。
最后,本文讨论的优化方法都是通用的方法,而随着神经网络处理器(如寒武纪 MLU、Google TPU)的发展,以及其他通用计算处理器的拓展(如点积相关的指令:Nvidia GPU DP4A、Intel AVX-512 VNNI、ARM SDOT/UDOT ),深度学习的优化或许还值得继续投入资源。
寒武纪 MLU 链接:
https://www.jiqizhixin.com/articles/2019-06-20-12
Nvidia GPU DP4A 链接:
https://devblogs.nvidia.com/mixed-precision-programming-cuda-8/
Intel AVX-512 VNN 链接:
https://devblogs.nvidia.com/mixed-precision-programming-cuda-8/
本文写作过程中参考了以下(包括但不限于)资料:
QNNPACK
( 链接:https://github.com/pytorch/QNNPACK )
Convolution in Caffe
( 链接:https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo )
TensorFlow
Wikipedia
Fast Algorithms for Convolutional Neural Networks
( 链接:https://github.com/Tencent/ncnn )
NCNN
( 链接:https://github.com/OAID/Tengine )
Tengine
( 链接:https://jackwish.net/neural-network-quantization-introduction-chn.html )
神经网络量化简介
( 链接:https://jackwish.net/neural-network-quantization-introduction-chn.html )
通用矩阵乘(GEMM)优化算法
( 链接:https://jackwish.net/gemm-optimization.html )
The Indirect Convolution Algorithm
「完」
转自:AI蜗牛车、极市平台
作者丨黎明灰烬
来源|https://zhuanlan.zhihu.com/p/80361782
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。
