【20210723】【机器/深度学习】“基于特征工程完成对贷款数据集Lending Club的预处理” 学习笔记
学习链接:https://work.datafountain.cn/forum?id=79&type=2&source=1
相关知识点:
数据预处理
特征工程
特征工程基本流程
python 相关库函数(pandas, numpy 等)
一、背景
在机器学习领域,有这样一句话:“数据和特征决定了机器学习算法的上限,而模型和算法只是不断逼近这个上限而已”。特征工程是从原始数据集转变为适合于模型且质量较高的训练数据的过程,其中对数据的处理涉及了统计学和专业领域的知识。
特征工程是机器学习中非常重要的一部分,“更多的数据胜过聪明的算法,而更好的数据胜过更多的数据”,所以特征工程环节十分关键!特征工程主要包括特征提取和特征选择。

二、具体步骤
第一步:导入所需数值计算库、读取原始数据集
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv(''./datasets/loan2.csv'')
print(data.head(n)) # 查看 data 前 n 行,为空则默认为 5第二步:特征提取和处理
特征提取和处理是将原始特征转换为一组具有明显物理意义或统计意义的特征,也就是说将机器学习算法识别不了的数据转变为可识别的数据特征的过程。特别地,提取到的特征能够增强模型的可解释性。
本文主要介绍下面几方面的特征提取和处理方法:数值特征、类别特征、时间特征、特征交叉。
2.1 数值特征
常用的对数值特征提取和处理的方法有:缩放、对数变换、数值离散化、分箱等。
1. 缩放:是一种用来统一特征取值范围的方法,常用的缩放方法有:Z-Score标准化、最大最小归一化等。
# Z-Score标准化
# 首先计算均值、再计算方差,再带入正态分布标准化公式即可。
stDf = data['loan_amnt'].to_frame()
loan_mean = stDf['loan_amnt'].mean() # 计算均值
loan_std = stDf['loan_amnt'].std() # 计算标准差
sfDf['loan_amnt_sf'] = (stDf['loan_amnt'] - loan_mean ) / loan_std # z-score标准化,也可以用sklearn库中的StandardScaler()方法计算2. 对数变换:可以对数值较大的范围进行压缩,对数值较小的范围进行扩展,可以很好的应对长尾分布现象,使数据分布更接近正态分布。
3. 数值离散化:当原始特征的数值作用不大时,可以采用某种临界点等方法将原始特征转化为二值特征。
# 二值化
# 用字典映射 —— dataframe.map(dic)
termDf = data['term'].to_frame()
term_dic = {' 36 months': 0,
' 60 months': 1} # 映射关系(存成字典)
termDf['term_binary'] = termDf['term'].map(term_dic) # 二值化4. 分箱:当数值跨越的数量级范围较大时,可以把数值按一定的顺序划分为几部分,常用的方法有:固定宽度分箱、分位数分箱、卡方分箱、聚类分箱等。
# 简单分箱
# 以 annual_inc(贷款人的年收入)为例,0~2w、2w~6w、6w 以上分别定义为低收入人群、中等收入人群、高收入人群。
binsDf = data['annual_inc'].to_frame()
set_bins = [0.0, 20000.0, 60000.0, binsDf.max()+1] # 设置箱体取值范围
set_labels = ['low', 'mid', 'high'] # 设置箱体标签
binsDf['annual_inc_bins'] = pd.cut(binsDf['annual_inc'], bins=set_bins, labels=set_labels) # 分箱三、知识点
1. 数据规范化(归一化)
是数据挖掘的一项基础工作,由于不同评价指标、不同数据集有不同的量纲,为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理,将数据按照比例进行缩放。提高了数据可比性,削弱了数据可解释性。
(1)最大最小归一化:也称离散标准化,是对原始数据的线性变换,将数据映射到 [0, 1] 之间,处理公式为:
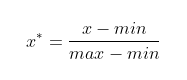
(2)z-score标准化(零-均值规范化):也称标准差标准化,经处理后的数据均值为0,标准差为1,处理公式为:
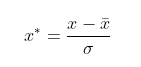
(参考:Z-Score数据标准化)
(参考:数据规范化(归一化)、及Z-score标准化)
2. 分箱库函数 pandas.cut() —— 对连续型的数值进行分箱操作
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates='raise')
# 【参数解释】
# x:一维数组
# bins:整数,标量序列或者间隔索引
# (1)如果bins=n,则表示将x中的数值分成等宽的n份;
# (2) 如果是标量序列,那么序列中的数值表示用来分档的分界值;
# (3)如果是间隔索引,“bins”的间隔索引必须不重叠。
#
# right:布尔值,默认为True,表示包含最右侧的数值,当bins是间隔索引时,将忽略此参数。
#
# labels:数值或布尔值,可选,指定分箱的标签
# (1)如果是数组,长度要与分箱个数一致;
# (2)如果是False,则仅返回分箱的整数指示符,即x中的数据在第几个箱子里
# (3)当bins是间隔索引时,将忽略此参数。
#
# retbins:是否显示分箱的分界值,默认为False。
#
# include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,表示不包含区间左边。
#
# duplicates:如果分箱临界值不唯一,则引发ValueError或丢弃非唯一。
(参考:数据分箱之pd.cut())