ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
ESimCSE:用于无监督句子嵌入对比学习的增强样本构建方法
Xing Wu 1,2,3 , Chaochen Gao 1,2 ∗ , Liangjun Zang 1 , Jizhong Han 1 , Zhongyuan Wang 3 , Songlin Hu 1,2 1 Institute of Information Engineering, Chinese Academy of Sciences, Beijing, China 2 School of Cyber Security, University of Chinese Academy of Sciences, Beijing, China 3 Kuaishou Technology, Beijing, China { gaochaochen,zangliangjun,hanjizhong,husonglin } @iie.ac.cn { wuxing,wangzhongyuan } @kuaishou.com
摘要
对比学习因其在无监督句中的嵌入而备受关注。当前最先进的无监督方法是无监督simcse(unsup simcse)。Unsup SimCSE将dropout作为一种最小的数据扩充方法,并将相同的输入语句传递给经过预训练的Transformer编码器(打开dropout)两次,以获得两个相应的嵌入,以构建正对。
由于在Transformer中使用位置嵌入,句子的长度信息通常会被编码到句子嵌入中,因此Unpsimcse中的每个正对实际上包含相同的长度信息。
因此,用这些正对训练的unsup SimCSE可能是有偏见的,这会倾向于认为相同或相似长度的句子在语义上更相似。通过统计观察,我们发现unsup SimCSE确实存在这样的问题。为了缓解这种情况,我们使用一个简单的重复操作来修改输入句子,然后将输入句子和修改后的句子分别传递给预先训练好的Transformer编码器,以获得正对。
此外,我们从计算机视觉社区中汲取灵感,引入动量对比,在不进行额外计算的情况下扩大了负对的数量。
将所提出的两种修改分别应用于正和负对,构建了一种新的句子嵌入方法,称为增强型unsp-SimCSE(ESimCSE)。
我们通过语义文本相似性(STS)任务,在几个基准数据集上评估了所提出的ESimCSE。实验结果表明,ESimCSE的平均Spearman相关系数为2.02%,优于最先进的unsup SimCSE。
1引言
以BERT为代表的大规模预训练语言模型(devlin et al.,2018;Liu et al.,2019)通过微调方法使许多下游监督任务受益。然而,当直接应用伯特的原生句子嵌入用于语义相似性任务而没有标记数据时,性能几乎不令人满意(高等人,2021;Yun等人,2021)。最近,研究人员提出使用对比学习来学习更好的无监督句子嵌入。对比学习的目的是学习有效的句子嵌入,其假设是有效的句子嵌入应该使相似的句子更接近,而将不同的句子推开。它通常使用各种数据增强方法为每个句子随机生成不同的视图,并假设一个句子在语义上比任何其他句子更类似于其增强的对应句子。目前最先进的方法是unsup SimCSE(高等人,2021),它产生了最先进的无监督句子嵌入,并与先前监督的同行进行标准杆数。Unsup SimCSE隐含地假设dropout是一种最小的数据扩充方法。具体来说,unsup SimCSE将N个句子组成一批,并使用两个独立抽样的dropout口罩将每个句子两次馈送给预先训练过的BERT。那么,来自同一个句子的嵌入构成“正对”,而来自两个不同句子的嵌入构成“负对”。
使用dropout作为一种最小的数据扩充方法简单有效,但存在一个弱点。预训练语言模型建立在Transformer块上,通过位置嵌入对句子的长度信息进行编码。
因此,来自同一个句子的正对将包含相同的长度信息,而来自两个不同句子的负对通常包含不同的长度信息。因此,正对和负对所包含的长度信息不同,这可以作为区分它们的特征。具体来说,由于这种差异,用这些对训练的语义相似度模型可能会有偏差,这可能认为长度相同或相似的两个句子在语义上更相似。
为了证实长度差异的影响,我们使用(Gao等人,2021)发布的unsup SimCSE BERT base模型评估了标准语义文本相似度(STS)任务。我们根据句子对的长度差异对STS任务数据集进行分组,并分别使用spearman关联计算相应的语义相似度。如表1所示,随着长度差的增加,unsup SimCSE的性能变得更差。unsup SimCSE在长度相近的句子中的表现(≤ 3) 远远超过长度差异较大(>3)的句子的表现。
为了缓解这个问题,我们提出了一种简单而有效的增强方法来取消对SimCSE的更新。对于每个正对,我们希望在不改变语义的情况下改变句子的长度。现有的改变句子长度的方法通常使用随机插入和随机删除。然而,在句子中插入随机选择的单词可能会引入额外的噪音,这可能会扭曲句子的意思;从句子中删除关键词也会极大地改变其语义。
因此,我们提出了一种更安全的方法,称为“单词重复”,它随机复制句子中的一些单词。例如,如表2所示,原来的句子是“我喜欢这个苹果,因为它看起来很新鲜,我觉得它应该很好吃。”随机插入可能会产生“我不喜欢这个苹果,因为它看起来太不新鲜了,我觉得它应该很好吃。”,随机删除可能会产生“我喜欢这个苹果,因为它看起来如此,我认为它应该如此。”。两者都偏离了原句的意思。
相反,“单词重复”的方法可能会得到“我喜欢这个苹果,因为它看起来很新鲜,而且我觉得它应该很好吃。”,或者“我喜欢这个苹果,因为它看起来很新鲜,我觉得它应该很好吃。”两者都很好地保留了原句的意思。
除了上述对正对结构的优化之外,我们还进一步探讨了如何优化负对的结构。由于对比学习是在正对和负对之间进行的,从理论上讲,更多的负对可以导致更好的对之间的比较(Chen等人,2020)。因此,一个潜在的优化方向是利用更多的负对,鼓励模型朝着更精细的学习方向发展。然而,根据(高等人,2021),较大的批量大小并不总是更好的选择。
例如,如图2所示,对于unpsimcse-bert-base模型,最佳批大小为64,其他批大小设置将降低性能。因此,我们倾向于找出如何更有效地扩展负对。
在计算机视觉领域,为了缓解GPU在扩展批量时的内存限制,一种可行的方法是引入动量对比(He et al.,2020),这也适用于自然语言理解(Fang et al.,2020)。动量contrast允许我们重用前一个小批次的编码嵌入,通过维护队列来扩展负对:队列总是将当前小批次的句子嵌入排队,同时将“最旧”的句子嵌入排队。
由于排队的句子嵌入来自之前的小批量,我们通过取其参数的移动平均值来保持MomentumUpdate模型,并使用动量模型生成排队的句子嵌入。请注意,使用动量编码器时,我们会关闭dropout,这可以缩小训练和预测之间的差距。
上述两种优化分别用于构建正和负对。我们最终将二者结合到unsup SimCSE中,这被称为增强型SimCSE(ESimCSE)。我们在图1中展示了ESimCSE的示意图。该ESimCSE在语义文本相似性(STS)任务和7个STS-B测试集上进行了评估。实验结果表明,与以前最先进的unsup SimCSE相比,ESimCSE可以显著提高不同模型设置下的相似性度量性能。具体而言,ESimCSE的斯皮尔曼相关性比unsup SimCSE的平均增幅分别为:伯特基+2.02%、伯特大+0.90%、罗伯塔基+0.87%、罗伯塔大+0.55%。
我们的贡献可以总结如下:•我们观察到unsup SimCSE用两个长度相同的句子构建每个正对,这可能会影响学习过程。
我们提出了一种简单但有效的“单词重复”方法来缓解这个问题。
•我们建议使用动量对比法来增加损失计算中涉及的负对的数量,这将鼓励模型进行更精细的学习。
•我们在多个基准数据集上进行了广泛的实验,即w.r.t语义文本相似性任务。实验结果很好地表明,两种优化方法都对unsup SimCSE带来了实质性的改进。
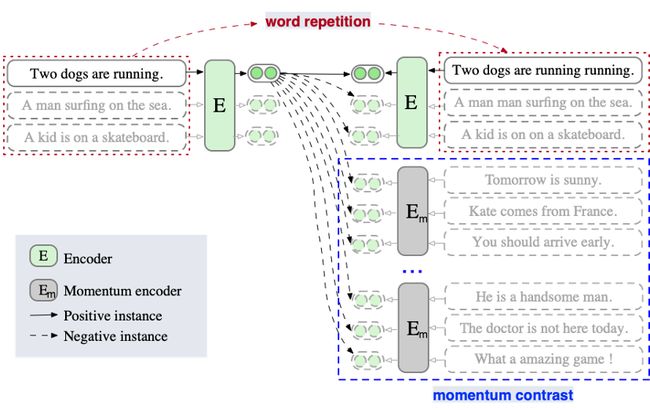
图1:ESimCSE方法的示意图。与unsup SimCSE不同,ESimCSE在批处理上执行单词重复操作,以便在不改变句子语义的情况下改变正对的长度。在预测正对时,这种机制削弱了对模型的相同长度提示。此外,ESimCSE还将之前几个小批次的模型输出保持在一个队列中,称为动量对比度,它可以扩展损失计算中涉及的负对。这一机制使得在对比学习中对配对进行更充分的比较。
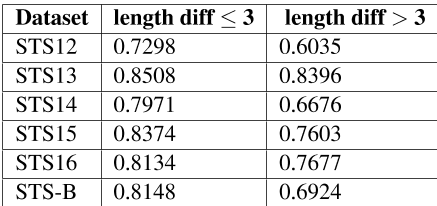
表1:长度差异为的句子对的斯皮尔曼相关性≤ 3和>3。
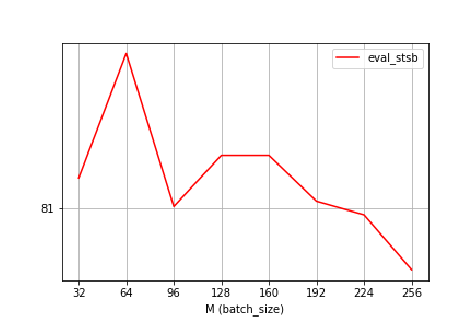
图2:unsup simcsebert base模型批量大小变化时STS-B开发集的性能趋势。
2背景:Unsup SimCSE
给定一组成对句子,其中![]() 和
和![]() 在语义上相关,将被视为正对。unpsimcse的核心思想是使用相同的句子来构建正对,即x+i=x i。请注意,在transformer中,在完全连接的层和注意力概率上放置了一个dropout遮罩。因此,关键是通过应用不同的dropout掩码z i和z+i,将相同的输入x i两次输入编码器,并输出两个独立的句子嵌入,以构建如下的正对:
在语义上相关,将被视为正对。unpsimcse的核心思想是使用相同的句子来构建正对,即x+i=x i。请注意,在transformer中,在完全连接的层和注意力概率上放置了一个dropout遮罩。因此,关键是通过应用不同的dropout掩码z i和z+i,将相同的输入x i两次输入编码器,并输出两个独立的句子嵌入,以构建如下的正对:
![]()
在批次大小为N的小批次中,每个句子的h i和h+i,对比学习目标w.r.t x i的公式如下:,
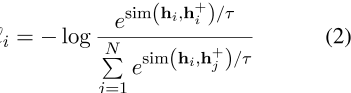
其中τ是温度超参数,![]() 是相似性度量,通常是余弦相似性函数,如下所示,
是相似性度量,通常是余弦相似性函数,如下所示,
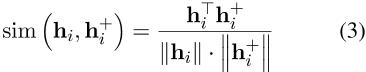
。

表2:改变句子长度的不同方法示例。相似性分数由官方发布的“unsup simcse bert base uncased”模型预测。
3提议的ESimCSE:增强的unsup SimCSE
在这一部分中,我们首先介绍单词重复法来构建更好的正对。然后我们引入动量对比法来展开负对。
3.1单词重复单词重复机制随机复制句子中的一些单词/子单词。这里我们以子词重复为例。给定一个句子s,经过子词标记器处理后,我们得到一个子词序列x=![]() ,N是序列的长度。
,N是序列的长度。
我们将重复标记的数量定义为
![]()
,其中dup rate是最大重复率,这是一个超参数。然后,dup len是上面定义的集合中的一个随机抽样数,它将在扩展序列长度时引入更多分集。在确定dup len后,我们使用均匀分布从序列中随机选择需要重复的dup len子字,其组成dup集合如下,
![]()
例如,如果第1个子字在dup集合中,则序列x变为
![]()
。
与unsup SimCSE不同,E-SimCSE将x传递给预先训练的伯特两次,E-SimCSE独立地传递x和![]() 。
。
3.2动量对比
动量对比允许我们通过保持一个固定大小的队列来重用前面小批量中的编码语句嵌入。具体来说,队列中的嵌入会逐渐被替换。当当前小批量的输出语句嵌入被排队时,如果队列已满,则删除队列中“最早”的语句嵌入。注意,我们使用动量更新编码器对排队的句子嵌入进行编码。形式上,将编码器的参数表示为θe,将动量更新编码器的参数表示为θm,我们按照以下方式更新θmin,
![]()
,其中![]() 是动量系数参数。
是动量系数参数。
注意,只有参数θe通过反向传播更新。这里我们引入θm来生成队列的句子嵌入,因为动量更新可以使θm比θe更平滑地进化。因此,虽然队列中的嵌入由不同的编码器编码(在训练期间的不同“步骤”),但这些编码器之间的差异可以很小。
在队列中嵌入句子后,ESimCSE的损失函数进一步修改如下,
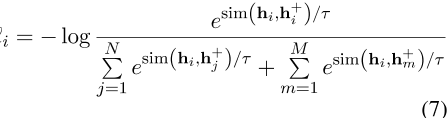
其中![]() 表示嵌入动量更新队列中的句子,M表示队列的大小。
表示嵌入动量更新队列中的句子,M表示队列的大小。

表3:标准语义文本相似性(STS)任务的数据统计。
4实验
4.1评估设置
在unsup SimCSE之后,我们使用从英文维基百科中随机抽取的100万句句子进行训练1。然后,我们在7个标准语义文本相似性(STS)任务上进行了实验。
详细统计数据如表3所示。sts12sts16数据集没有训练或开发集,因此我们评估STS-B开发集上的模型,以搜索更好的超参数设置。SentEval toolkit 2用于评估。对于比较的基线unsup SimCSE,我们下载正式发布的模型checkpoints 3,并在开发/测试模式下使用建议的超参数再现评估结果。实验在Nvidia 3090 GPU上进行。
语义文本相似性任务语义文本相似性度量任意两个句子的语义相似性。STS 2012-2016(Agirre et al.,2012、2013、2014、2015、2016)和STS-B(Cer et al.,2017)是广泛使用的语义文本相似性基准数据集,它们通过相应句子嵌入的余弦相似性来衡量两个句子的语义相似性。
在推导出测试集中所有对的语义相似性之后,我们遵循unsup SimCSE,使用斯皮尔曼相关来测量预测相似性等级与基本事实之间的相关性。对于一组大小n,n个原始分数X i,Y i被转换为其相应的秩![]() ,
,![]() ,然后斯皮尔曼相关性定义如下
,然后斯皮尔曼相关性定义如下
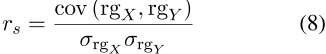
,其中![]() 是秩变量的协方差,
是秩变量的协方差,![]() 和
和![]() 是秩变量的标准偏差。斯皮尔曼相关性的值介于-1和1之间,当预测的相似性等级和基本事实相似时,该值将很高。
是秩变量的标准偏差。斯皮尔曼相关性的值介于-1和1之间,当预测的相似性等级和基本事实相似时,该值将很高。
4.2训练详情
我们从使用基本版本和大型版本的预先训练的BERT(uncased)或RoBERTa(cased)检查点开始,并在[CLS]表示上添加一个MLP层,以实现句子嵌入。我们基于Huggingface的transformers包4实现了ESimCSE。我们使用Adam优化器对模型进行一个历元的训练,该优化器的批量大小=64,超参数温度![]() ,如式(3)所示。ESimCSE BERT base模型的学习率设置为3e-5,其他模型的学习率设置为1e-5。基本型号的dropout率
,如式(3)所示。ESimCSE BERT base模型的学习率设置为3e-5,其他模型的学习率设置为1e-5。基本型号的dropout率![]() ,p=0。15个大型号。对于动量对比,我们根据经验选择相对较大的动量λ=0.995。此外,我们在STS-B开发集上每隔125个训练步骤对模型进行一次评估,并为测试集的最终评估保留最佳检查点。我们使用子单词重复而不是单词重复,这将在研究部分进一步讨论。
,p=0。15个大型号。对于动量对比,我们根据经验选择相对较大的动量λ=0.995。此外,我们在STS-B开发集上每隔125个训练步骤对模型进行一次评估,并为测试集的最终评估保留最佳检查点。我们使用子单词重复而不是单词重复,这将在研究部分进一步讨论。
4.3主要结果
表4显示了在STS-B开发集上获得的最佳结果。我们强调了使用与bold相同的预训练编码器的型号中数量最多的型号。♣ 表示官方发布的模型的评估结果(Gao等人,2021)。可以看出,我们提出的esimcse在伯特基础上的表现优于unsup SimCSE,分别为+2.40%、+2.19%、+1.19%和+0.26%。
通过在开发集上对建议的esimcse和unsup SimCSE进行比较,我们初步了解了建议的esimcse的优越性。然后,我们进一步评估测试集上相应的检查点。表5显示了7个STS测试集的评估结果。可以看出,与之前最先进的unsup SimCSE相比,ESimCSE在基本模型的不同设置下显著改进了语义-文本相似度的度量。具体而言,我们提出的ESimCSE在BERT基础上的表现优于UnpsiMCSE,分别为+2.02%、+0.90%、+0.87%和+0.55%。
我们还探讨了当只使用单词重复或动量对比时,它能给unsup SimCSE带来多大的改进。如表6和表7所示,无论是单词重复还是动量对比都可以显著改善unpsimcse。
这意味着所提出的增强正对和负对的方法都是有效的。
更好的是,这两个修改可以叠加(ESimCSE)以获得进一步的改进。
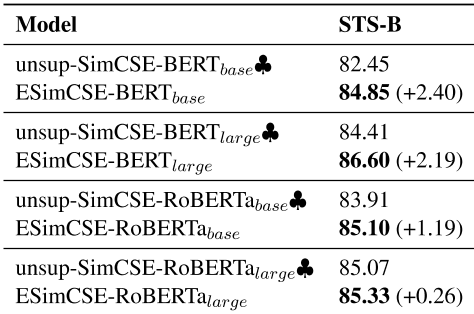
表4:基于Spearman相关性的语义-文本相似性(STS)发展集的句子嵌入性能,以BERT-base、BERT-large、RoBERTa-base、RoBERTa-large为基础模型。♣ : 官方发布的模型结果(Gao等人,2021)。
5消融研究
本节研究不同的dropout率、重复率、句子长度扩展方法和动量对比队列大小如何影响ESimCSE的性能。我们一次只更改一个超参数。所有结果均使用我们的ESimCSE BERT base模型,并在STS-B开发集上进行了评估。
5.1 Dropout率的影响
Dropout是unsup SimCSE模型的关键因素,因此不同的Dropout率p对模型的性能至关重要。根据(Gao等人,2021),unsup simcsebert base的最佳dropout率为p=0。1.考虑到ESimCSE还引入了单词重复和动量对比机制,我们重新研究了不同辍学对其性能的影响。我们对三种典型的dropout率进行了实验,结果如表8所示。具体来说,当dropout为0.1时,它在STS-B开发集上实现了最佳性能。当dropout增加到0.15时,性能接近0.1,没有显著下降。即使dropout达到0.2,成绩也下降了近1%,但仍优于unsup SimCSE。
实验结果显示,就dropout率而言,所提出的ESimCSE优于unsup SimCSE的稳健性。
5.2重复率的影响
在提出的ESimCSE中,单词重复可以使正对的长度差异多样化,从而带来改善。直觉上,很少的重复对长度差异的多样性影响有限,而很多重复会扭曲句子的语义,使正对不够牢固。为了定量研究重复率对模型性能的影响,我们将重复率参数dup rate从0.08缓慢增加到0.36,每次增加0.04。如表9所示,当dup率=0时。32,ESimCSE BERT base实现最佳性能,较大或较小的dup速率将导致性能下降,这与我们的直觉一致。虽然存在小的波动,但提议的ESimCSE的大多数结果仍然超过了UnpsiMCSE-bert-base的最佳结果。
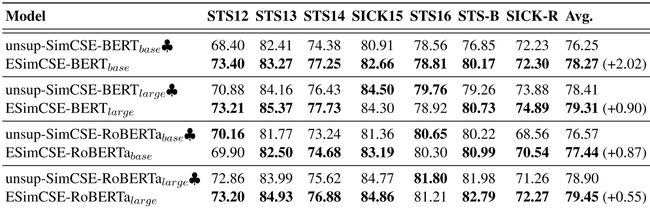
表5:以BERT-base、BERT-large、RoBERTa-base、RoBERTa-large为基础模型,根据Spearman相关性,在7个语义-文本相似性(STS)测试集上的句子嵌入性能。♣ : 官方发布的模型结果(Gao等人,2021)。。
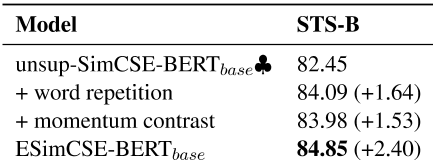
表6:单词重复或动量对比带来的对STS-B发展集的改善。
5.3句子长度延伸法的效果
除了子词重复,我们还探索了其他三种增加句子长度的方法:单词重复、插入停止词和插入[MASK](Devlin等人,2018)。单词重复的实现类似于子单词重复,只是重复操作发生在标记化之前。例如,给定一个单词“微生物学”,单词重复将产生“微生物学微生物学”,而子单词重复将产生“微生物生物学”或“微生物生物学”。插入停止字是另一种字级扩展方法。插入位置的选择与单词重复的方法相同,只是所选单词不再重复,而是插入一个随机停止词。
插入[MASK]与此类似,在所选单词后插入[MASK]标记。它类似于BERT的训练前输入。我们可以将[MASK]视为动态上下文兼容的单词占位符。如表10所示,子词重复的性能最好,词重复也能带来很好的改善,这表明更细粒度的重复可以更好地缓解正对长度差异带来的偏差。插入[MASK]也可以带来小的改善,但插入停止词会略微降低效果。
5.4队列大小对动量对比度的影响
动量对比度队列的大小决定了损失计算中涉及的负对的数量。在不考虑时间成本和GPU内存限制的情况下,较大的队列大小能否带来更好的性能?我们将BERT基作为ESimCSE的基本模型,并用队列大小等于批量大小的不同倍数进行实验。实验结果如表11所示。当队列大小为批处理大小的2.5倍时,可以达到最佳结果。队列大小越小或越大,影响越小。这很直观,因为动量对比度的引入鼓励更多的负对参与损失计算,从而可以更充分地比较正对。但队列太大也会降低效益。我们猜测这是因为动量对比度中的负对是由训练期间过去的“步骤”生成的,更大的队列将使用与当前编码器模型截然不同的更过时编码器模型的输出。
因此,这将降低损失计算的可靠性。

表7:单词重复或动量对比给unsup SimCSE带来的7个STS测试集的改进。

表8:根据斯皮尔曼的相关性,不同dropout概率对STS-B发展集的影响。
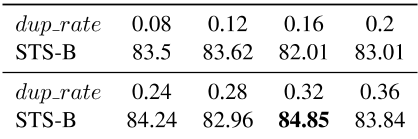
表9:根据斯皮尔曼的相关性,重复频率对STS-B发展集的影响。

表10:根据斯皮尔曼的相关性,句子长度扩展方法对STS-B发展集的影响。
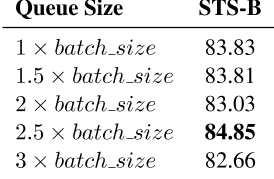
表11:根据斯皮尔曼相关性,动量对比度队列大小对STS-B开发集的影响。
6相关工作
无监督句子表征学习已被广泛研究。(Socher等人,2011年;Hill等人,2016年;Le和Mikolov,2014年)建议根据每个句子的内部结构学习句子表征。(Kiros等人,2015年;Logeswaran和Lee,2018年)根据分布假设预测给定句子的周围句子。(Pagliardini et al.,2017)提出Sent2Vec,这是一种简单的无监督模型,允许使用单词向量和n-gram嵌入组合句子嵌入。
近来,对比学习在非监督句型学习中得到了探索,并成为一种很有发展前途的趋势(张等人,2020;吴等人,2020;Mon等人,2021;高等人,2021;Yin等人,2021)。这些基于对比学习的句子嵌入方法通常基于这样一个假设,即良好的语义表示应该能够使相似的句子更接近,而将不同的句子推开。
因此,这些方法使用各种数据增强方法为每个句子随机生成两个不同的视图,并设计一个有效的损失函数,使它们在语义表示空间中更接近。在这些对比方法中,与我们的工作最相关的是unsup ConSERT和unsup SimSCE。ConSERT探索了各种有效的数据扩充策略(例如,对抗性攻击、标记洗牌、切断、dropout),以产生不同的对比学习观点,并分析其对无监督句子表征迁移的影响。Unsup-SimSCE,当前最先进的无监督方法仅使用标准dropout作为最小数据扩充,并使用独立采样的dropout掩码将相同的句子两次馈送到预训练的模型,以生成两个不同的句子嵌入,作为正对。Unsup SimSCE很简单,但工作得出奇的好,与以前监督的同行标准杆数相当。
然而,我们发现,unsup-SimCSE用两个相同长度的句子构建每个正对,这可能会误导句子嵌入的学习。因此,我们提出了一种简单而有效的方法来缓解这种情况。我们还建议使用动量对比法来增加损失计算中涉及的负对的数量,这鼓励模型朝着更精细的学习方向发展。
7.结论和今后的工作
在本文中,我们提出了为unsup SimCSE构造正和负对的优化方法,并将其与unsup SimCSE相结合,称为ESimCSE。通过大量实验,提出的ESimCSE与unsup SimCSE相比,在标准语义文本相似性任务上取得了显著的改进。
正如unsup SimCSE对待所有负对一样重要。一些负对与正对有很大不同,而另一些则相对接近正对。这种区别将有助于嵌入检索任务,但不会反映在unsup SimCSE的目标函数中。
因此,在未来,我们将重点设计一个更精细的目标函数,以改善不同负对之间的区分。
参考文献
Eneko Agirre, Carmen Banea, Claire Cardie, Daniel Cer, Mona Diab, Aitor Gonzalez-Agirre, Weiwei Guo, Inigo Lopez-Gazpio, Montse Maritxalar, Rada Mihalcea, et al. 2015. Semeval-2015 task 2: semantic textual similarity, english, spanish and pilot on interpretability. In Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015) , pages 252–263.
Eneko Agirre, Carmen Banea, Claire Cardie, Daniel Cer, Mona Diab, Aitor Gonzalez-Agirre, Weiwei Guo, Rada Mihalcea, German Rigau, and Janyce Wiebe. 2014. Semeval-2014 task 10: Multilingual semantic textual similarity. In Proceedings of the 8th international workshop on semantic evaluation (SemEval 2014) , pages 81–91.
Eneko Agirre, Carmen Banea, Daniel Cer, Mona Diab, Aitor Gonzalez Agirre, Rada Mihalcea, german Rigau Claramunt, and Janyce Wiebe. 2016. Semeval-2016 task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. In SemEval-2016. 10th International Workshop on semantic Evaluation; 2016 Jun 16-17; San Diego, CA. Stroudsburg (PA): ACL; 2016. p. 497-511. ACL (association for Computational Linguistics).
Eneko Agirre, Daniel Cer, Mona Diab, and Aitor Gonzalez-Agirre. 2012. Semeval-2012 task 6: A pilot on semantic textual similarity. In * SEM 2012: The First Joint Conference on Lexical and computational Semantics–Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012) , pages 385– 393.
Eneko Agirre, Daniel Cer, Mona Diab, Aitor gonzalezagirre, and Weiwei Guo. 2013. * sem 2013 shared task: Semantic textual similarity. In Second joint conference on lexical and computational semantics (* SEM), volume 1: proceedings of the Main conference and the shared task: semantic textual similarity , pages 32–43.
Daniel Cer, Mona Diab, Eneko Agirre, Inigo lopezgazpio, and Lucia Specia. 2017. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv preprint arXiv:1708.00055 .
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. In international conference on machine learning , pages 1597–1607. PMLR.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 .
Hongchao Fang, Sicheng Wang, Meng Zhou, Jiayuan Ding, and Pengtao Xie. 2020. Cert: Contrastive
self-supervised learning for language understanding. arXiv preprint arXiv:2005.12766 .
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. Simcse: Simple contrastive learning of sentence embeddings. arXiv preprint arXiv:2104.08821 .
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. 2020. Momentum contrast for unsupervised visual representation learning. In proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition , pages 9729–9738. Felix Hill, Kyunghyun Cho, and Anna Korhonen. 2016. Learning distributed representations of sentences from unlabelled data. arXiv preprint arXiv:1602.03483 .
Ryan Kiros, Yukun Zhu, Russ R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Skip-thought vectors. In Advances in neural information processing systems , pages 3294–3302.
Quoc Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. In international conference on machine learning , pages 1188– 1196. PMLR.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 .
Lajanugen Logeswaran and Honglak Lee. 2018. An efficient framework for learning sentence representations. arXiv preprint arXiv:1803.02893 .
Yu Meng, Chenyan Xiong, Payal Bajaj, Saurabh tiwary, Paul Bennett, Jiawei Han, and Xia Song. 2021. Coco-lm: Correcting and contrasting text sequences for language model pretraining. arXiv preprint arXiv:2102.08473 .
Matteo Pagliardini, Prakhar Gupta, and Martin Jaggi. 2017. Unsupervised learning of sentence embeddings using compositional n-gram features. arXiv preprint arXiv:1703.02507 .
Richard Socher, Eric Huang, Jeffrey Pennin, christopher D Manning, and Andrew Ng. 2011. Dynamic pooling and unfolding recursive autoencoders for paraphrase detection. Advances in neural information processing systems , 24.
Zhuofeng Wu, Sinong Wang, Jiatao Gu, Madian Khabsa, Fei Sun, and Hao Ma. 2020. Clear: contrastive learning for sentence representation. arXiv preprint arXiv:2012.15466 .
Yuanmeng Yan, Rumei Li, Sirui Wang, Fuzheng Zhang, Wei Wu, and Weiran Xu. 2021. consert: A contrastive framework for self-supervised sentence representation transfer. arXiv preprint arXiv:2105.11741 .
Yan Zhang, Ruidan He, Zuozhu Liu, Kwan Hui Lim, and Lidong Bing. 2020. An unsupervised sentence embedding method by mutual information maximization. arXiv preprint arXiv:2009.12061 .