Lesson 17.2 经典数据集(1):入门数据集,以及读数据时哪些可能的坑
一 数据
数据是一切机器学习项目的根基。当我们想建立一个项目时,首先考虑的第一个问题就是:数据从哪里来?如果你是带着项目在学习这段课程,那你可能已经从导师或公司团队那里拿到了相应的数据,那对你来说最难的部分可能是如何将你的数据放入卷积网络,你可以直接学习《一、2 使用自己的数据/图片创造数据集》。但如果你没有现成的数据在手,你就需要使用深度学习框架中配置好的数据集。对初学者、尤其是只了解深度视觉、不太了解传统视觉方法的人们来说,自己收集和创造数据基本是不太可能的,因此使用现成的数据集是成本更低廉的方法。不过,调用内置数据集可不是一件容易的事。现在,让我们来看看调用经典数据集中的那些问题。
1 认识经典数据
在入门级课程时,我们都会学习MNIST和Fashion-MNIST这两个数据集,他们都是灰度图像的数据集,并且都有10个标签类别,每个标签类别分别对应了图像上的物品/数字是什么。
这两个数据集代表了最传统、最简单的图像预测问题中所使用的数据,他们足以应对图像领域最前沿的任何分类模型,例如残差网络。当我们的学习越来越深入,我们自然会渴望使用更有挑战性的数据集,例如我们之前已经介绍过的ImageNet,或者许多人可能都听说过的COCO、CIFAR等数据集。然而,即便是对前沿模型掌握熟练的初学者,也无法轻易将Fashion-MINST数据集上的操作推广至其他数据集。
例如,在PyTorch中,如果可能的话,我们都会从torchvision.datasets模块下调用图像数据集。在Lesson 11中,我们使用以下代码成功调用了Fashion-MNIST数据集。你可以试着将这段代码中使用的类更换为其他数据集,就会开始无穷无尽的报错之旅。
import torchvision
import torchvision.transforms as transforms
mnist = torchvision.datasets.FashionMNIST(root='...\FashionMNIST'
,train=False
,download=True
,transform=transforms.ToTensor())
不同于传统机器学习中广泛使用的表格数据,图像数据集在格式、标签、内容上的丰富程度异常地高,大部分图像数据集无法用同一个API调用,这就是说许多情况下我们不能使用同样的代码加载不同的数据集。同样,图像数据集可能会存在文件太大、占用内存太多、普通用户无法调用的问题。例如,ImageNet是一个巨大的数据集,我们能够获取到的开源部分比原始数据集小很多,然而这个开源的ImageNet子集的大小也有155G。大部分经典图像数据集的大小都超过10个G,大大超出大部分个人电脑的运存。另外,CNN对于图像数据也有一些要求,例如,被识别对象往往需要在图像中心,图像要清晰、要具体,不能容纳太复杂的信息,还需要被标上具体的标签,因此图像数据集的生产成本往往很高。现在我们能够接触到的大部分图像或视频数据集,都是研究机构或商业机构出于研究目的自制的数据集,大部分都有版权限制和使用限制。几乎所有数据集都被要求只能使用于学术场景,许多数据集需要注册、申请才能够使用,许多数据集甚至完全不开源。这又进一步缩小了我们可以调用的图像数据集的范围。即便存在这些重重困难,PyTorch还是将许多数据集归纳在torchvision模块的datasets模块下,试图使用相似的API对其进行调用,但每个API上复杂的参数和参数的说明又让许多初学者望而却步。可见,初学者即便知道一些经典图像数据集的名称,也无法轻易实现对数据集的调用。
为了解决这个问题,我对PyTorch中内置的数据集进行了梳理,并将调用这些数据集所需的基础知识都包含在这一节当中,尽可能地赋予大家自由调用数据集的能力。遗憾的是,考虑到课时限制与学习效率,我们无法在课程中对所有类都进行讲解,因此要想灵活使用图像数据集,英文阅读能力/谷歌翻译插件是必不可少的,否则你将会陷入无边无际的报错当中。幸运的是,我们还是可以一定程度上将数据集进行归类讲解。只要认识了这些数据的名称,并知道去哪里获取他们,我们就可以一定程度上实现对他们的调用。我们先来认识一下这些数据集吧。
1.1 入门数据:MNIST、其他数字与字母识别
第一部分要介绍的是最适合用于教学和实验、几乎对所有的电脑都无负担的MNIST一族。MNIST一族是数字和字母识别的最基本的数据集,这些数据几乎全都是小尺寸图像的简单识别,可以被轻松放入任意神经网络中进行训练。具体如下:
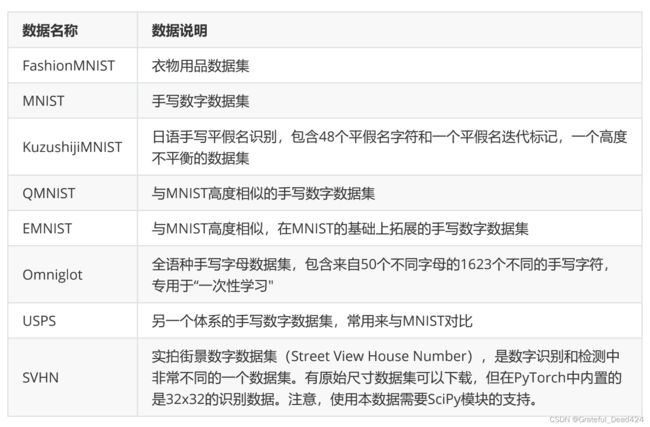

在PyTorch中,提供了三个与MNIST数据集相对比的数据集,分别是用于一次性学习的字母识别数据集Omniglot,另一个体系的手写数字数据集USPS,以及SVHN实拍街景数字数据集。这几个数据集与MNIST的区别如下图。
这些数据集都很简单,那什么时候使用他们呢?在深度视觉的研究中,我们很少专门就MNIST进行研究,但我们在这些简单识别数据集上设置了其他值得研究的问题。比如,在我们撰写论文或检验自己的架构时,MNIST一族是很好的基准线——他们尺寸很小,容易训练,很简单却又没有那么“简单”。一流的架构往往能够在MNIST数据集上取得99%以上的高分,而发表论文时,MNIST数据集的结果低于97%是不能接受的。单一机器学习算法能够在Fashion-MNIST数据集上取得的分数基本都在90%左右,而一流的深度学习架构至少需要达到95%以上的水准。再比如,我们常常使用平假名识别的数据集来研究深度学习中的样本不平衡问题,我们还使用Omniglot数据集来研究人脸识别(主要是个体识别 identity recognition)中常见的“一次性学习”问题(one-shot learning)。我们来重点讲讲这个“一次性学习”的问题。


在人脸识别中,我们有两种识别策略:
第一种策略是以人名为标签进行多分类,在训练样本中包含大量的同一个人的照片,测试集中也包含这个人的照片,看CNN能否正确预测出这个人的名字;而第二种策略则是一种二分类策略,在训练样本中给与算法两张照片,通过计算距离或计算某种相似性,来判断两张照片是否是同一个人,输出的标签为“是/否相似或一致”,在这种策略中,测试集的样本也是两张照片,并且测试集的样本不需要出现在训练集中。
如果基于第一种策略来执行人脸识别,则机场、火车站的人脸识别算法必须把全国人民的人脸数据都学习一遍才可能进行正确的判断。而在第二种策略中,算法只需要采集身份证/护照上的照片信息,再把它与摄像头中拍摄到的影像进行对比,就可以进行人脸识别了。这种“看图A,判断图B上的人是否与图A上的人是同一人”的学习方法,就叫做一次性学习,因为对于单一样本,算法仅仅见过一张图A而已。不难想象,实际落地的人脸识别项目都是基于一次性学习完成的。Omniglot数据集就是专门训练一次性学习的数据集。从上图可以看出,Omniglot数据集中的字母/符号对我们而言是完全陌生的,因此我们并无法判断出算法是否执行了正确的“识别”结果。而再Omniglot数据集上,算法是通过学习图像与图像之间的相似性来判断两个符号是否是一致的符号,至于这个符号是什么,代表什么含义,对Omniglot数据集来说并无意义。
字母和数字识别的数据集的尺寸都较小,因此PyTorch对以上每个数据集都提供了下载接口,因此我们无需自行下载数据,就可以使用torchvision.datasets.xxxx的方式来对他们进行调用。在网速没有太大问题的情况下,只要将download设置为True,并确定VPN是关闭状态,就可以顺利下载。注意,下载之后最好将download参数设置为False,否则只要调用目录写错,就会重新进行下载,费时也费流量。在课程中,我已给大家下载好以下三个文件(其中Fashion-MNIST是之前就下载过的),大家可以将文件放置到自己的目录下,将root修改为文件夹所在目录后来进行运行。我的根目录如下所示:
你可以查看相应的文件夹,你会发现FashionMNIST中的文件是gz文件加压后的pt文件,omniglot-py的文件是zip文件解压后的png图片,SVHN中是matlab生成的mat文件,但这些文件都可以统一使用torchvision.datasets来读取。
基于这个目录,我们来运行以下代码:
#在频繁调用数据的过程中,可能出现环境问题,导致jupyter整个崩溃刷新
#为解决/避免该问题,对环境进行了部分修改
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torchvision
import torchvision.transforms as transforms
fmnist = torchvision.datasets.FashionMNIST(root ='/Users/zhucan/Desktop/cv数据集' #写到文件夹
,train = True #根据类的不同,参数可能发生变化
,download = False #未下载则设置为True
,transform = transforms.ToTensor())
svhn = torchvision.datasets.SVHN(root ='/Users/zhucan/Desktop/cv数据集/SVHN' #写到文件
,split ="train" #"test","val"
,download = False
,transform = transforms.ToTensor())
omnist = torchvision.datasets.Omniglot(root ='/Users/zhucan/Desktop/cv数据集' #写到文件夹
,background = True
,download = False
,transform = transforms.ToTensor())
#如返回结果所示,除了样本量之外什么都无法看见
omnist
#Dataset Omniglot
# Number of datapoints: 19280
# Root location: /Users/zhucan/Desktop/cv数据集/omniglot-py
# StandardTransform
#Transform: ToTensor()
fmnist
#Dataset FashionMNIST
# Number of datapoints: 60000
# Root location: /Users/zhucan/Desktop/cv数据集
# Split: Train
# StandardTransform
#Transform: ToTensor()
svhn
#Dataset SVHN
# Number of datapoints: 73257
# Root location: /Users/zhucan/Desktop/cv数据集/SVHN
# Split: train
# StandardTransform
#Transform: ToTensor()
fmnist.data
#tensor([[[0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# ...,
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0]],
#
# [[0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# ...,
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0],
# [0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)
fmnist.targets
#tensor([9, 0, 0, ..., 3, 0, 5])
#之前我们使用.data的方式查看特征,.target的方式查看标签,但如下所示,不同的数据集并不共享调用的API
#这其实可以理解,当面临的任务不同时,每个数据集的标签排布方式和意义也都不同,因此不太可能使用相同的API进行调用
for i in [fmnist,svhn,omnist]:
print(i.data.shape)
#torch.Size([60000, 28, 28])
#(73257, 3, 32, 32)
#AttributeError: 'Omniglot' object has no attribute 'data'
for i in [fmnist,svhn,omnist]:
print(i.targets.shape)
#torch.Size([60000])
#AttributeError: 'SVHN' object has no attribute 'targets'
#如果你想查看每个数据集都可以调用哪些属性,必须要进入到数据集的源码进行查看
#如果不想读源码,也可以直接使用下面的方式进行简单的调用
#索引的方式调用单个样本
omnist[0][0].shape
#torch.Size([1, 105, 105])
len(omnist) #查看样本量
#19280
#报错概率最低的查看方式
for i in [fmnist,svhn,omnist]:
for x,y in i:
print(x.shape,y)
break
#torch.Size([1, 28, 28]) 9
#torch.Size([3, 32, 32]) 1
#torch.Size([1, 105, 105]) 0
#可视化
#实际上,在读图时如果不加ToTensor的预处理,很可能直接读出PIL文件
#PIL可以直接可视化
fmnist = torchvision.datasets.FashionMNIST(root ='/Users/zhucan/Desktop/cv数据集'
,train =True #根据类的不同,参数可能发生变化
,download =False #未下载则设置为True
# ,transform = transforms.ToTensor()
)
fmnist[0]
#(, 9)
fmnist[0][0] #尺寸较小,难以看清
![]()
#同时,当数据集很大时,我们希望最好只读取一遍,所以一般还是会加上ToTensor
#此时我们就需要自己编写可视化的函数
#使用numpy和matplotlib将图像可视化
import matplotlib.pyplot as plt
import numpy as np
import random
#让每个数据集随机显示5张图像
def plotsample(data):
fig, axs = plt.subplots(1,5,figsize=(10,10)) #建立子图
for i in range(5):
num = random.randint(0,len(data)-1) #首先选取随机数,随机选取五次
#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据
#而展示图像用的imshow函数最常见的输入格式也是3通道
npimg = torchvision.utils.make_grid(data[num][0]).numpy()
nplabel = data[num][1] #提取标签
#将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取
axs[i].imshow(np.transpose(npimg, (1, 2, 0)))
axs[i].set_title(nplabel) #给每个子图加上标签
axs[i].axis("off") #消除每个子图的坐标轴
#可以自行修改plotsample函数,为可视化实现更高的自由度
plotsample(omnist)

plotsample(svhn)

plotsample(fmnist)

根据类的不同,参数train可能变化为split,还可能增加一些其他的参数,具体可以参考datasets页面。MNIST一组的数据几乎都可以被用于最简单的识别项目,是测试架构的最佳数据。在提出新架构或新方法时,学者们总是会在MNIST或Fashion-MNIST数据集上进行测试,并将在这些数据上拿到高分(>95%)作为新架构有效的证明之一。
1.2 竞赛数据:ImageNet、COCO、VOC、LSUN
除了数字和字母识别之外,最为人熟悉并令人瞩目的就是各大竞赛的主力数据了。之前在讲解大规模视觉挑战赛ILSVRC的时候,我们介绍过ImageNet数据集,和ImageNet数据一样,竞赛数据往往诞生于顶尖大学、顶尖科研机构或大型互联网公司的人工智能实验室,属于推动整个深度学习向前发展的数据集,因此这些数据集通常数据量巨大、涵盖类别广泛、标签异常丰富、可以被用于各类图像任务,并且每年会更新迭代、且在相关竞赛停止或关闭之后会下架数据集。作为计算机视觉的学习者,你可以没有用过这些数据,但你必须知道他们的名字和基本信息,如果你是计算机视觉工程师,那在你的每个项目上线之前,你都需要使用这些数据来进行测试。让我们来看看这些数据集:

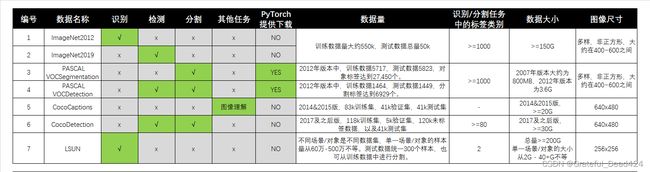
各个数据集的样图如下所示:




这一类数据集最大的特点就是数据量多、原图尺寸很大,因此整个数据集所占用的存储空间也会更大。最小的VOC数据集也在3.6个G左右,其他都在20G以上。PyTorch只提供了VOC的下载通道,但这个下载通道极不稳定,因此我还是推荐大家提前下载好之后将数据放入根目录中进行读取。
竞赛数据都是来自于各个机构和大学的研究,因此其风格和调用流程不可能一致,使用每个数据都需要进行一定的探索、还必须具备一定的英文阅读/谷歌翻译能力/Github使用/Python脚本编程能力。在我们的课程中,我给大家准备了2012年的ImageNet数据集、VOC以及LSUN数据集中较小的2类数据(见课程资料),并且准备了可以运行来下载LSUN其他类别数据的Python脚本和readme文档。其中VOC适用于分割和检测任务,ImageNet和LSUN适用于分类任务。我的根目录如下所示: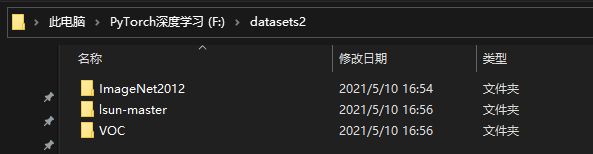
如果你并不知道如何使用Python脚本文件,可以参考下面的代码。图中正在下载LSUN户外教堂类别,注意,执行此代码时VPN必须处于关闭状态。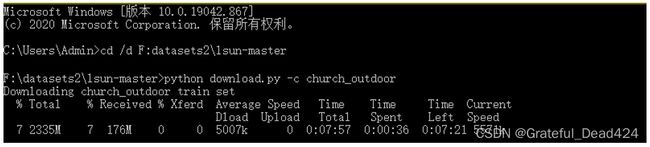
值得一提的是,LSUN竞赛现已关闭,因此测试集已无法下载,但训练集和验证集还是可以下载。LSUN各个类别的数据集大小如下所示。在课程中,我给大家下载了户外教堂以及教室两个类别,可以用于分类。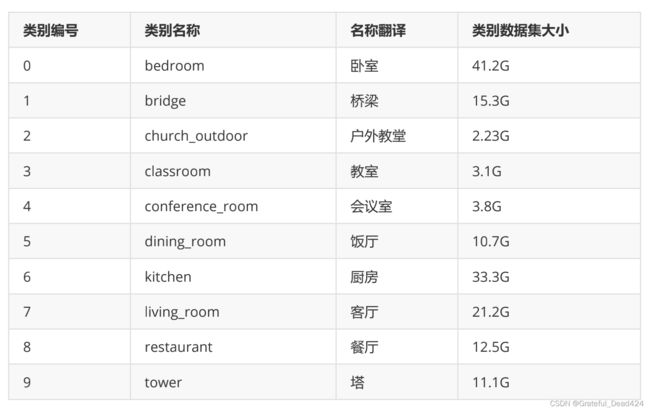
LSUN数据集下载后是压缩文件,解压后是LMBD(Lightning Memory-Mapped Database)数据库的文件。在深度学习中,有许多大型图像数据集都是储存为LMBD文件,因为框架Caffe和TensorFlow在早期使用了大量储存为LMBD格式的数据集。从LMBD数据库中读取数据的代码并不复杂,但需要较多数据库和LMBD相关的基础知识,我在后续为大家提供了相关代码。幸运的是,LSUN的LMBD文件可以直接通过pytorch中datasets下的类来直接调用,具体代码如下:
#导入一个类别
data_train = torchvision.datasets.LSUN(root="/Users/zhucan/Desktop/lsun-master/data"
,classes=["church_outdoor_train"] #标签类别
,transform = transforms.ToTensor()
)
data_train
#Dataset LSUN
# Number of datapoints: 126227
# Root location: /Users/zhucan/Desktop/lsun-master/data
# Classes: ['church_outdoor_train']
# StandardTransform
#Transform: ToTensor()
data_val = torchvision.datasets.LSUN(root="/Users/zhucan/Desktop/lsun-master/data"
,classes=["church_outdoor_val"]
,transform = transforms.ToTensor())
data_val
#Dataset LSUN
# Number of datapoints: 300
# Root location: /Users/zhucan/Desktop/lsun-master/data
# Classes: ['church_outdoor_val']
# StandardTransform
#Transform: ToTensor()
data_train[0][0].shape
#torch.Size([3, 392, 256])
data_train[3][0] #不用transforms

plotsample(data_val)

for x, y in data_val:
print(x.shape)
print(y)
#torch.Size([3, 256, 341])
#0
#torch.Size([3, 341, 256])
#0
#torch.Size([3, 358, 256])
#0
#...
#torch.Size([3, 256, 383])
#0
#torch.Size([3, 256, 256])
#0
#只导入一个类别时,该类别是没有标签的
check_ = 0
for x,y in data_val:
check_+=y
check_
#0
#想要进行训练,至少得导入两个类别,进行二分类
data_train = torchvision.datasets.LSUN(root=r"/Users/zhucan/Desktop/lsun-master/data"
,classes=["church_outdoor_train","classroom_train"]
,transform = transforms.ToTensor())
data_train
#Dataset LSUN
# Number of datapoints: 294330
# Root location: /Users/zhucan/Desktop/lsun-master/data
# Classes: ['church_outdoor_train', 'classroom_train']
# StandardTransform
#Transform: ToTensor()
data_val = torchvision.datasets.LSUN(root=r"/Users/zhucan/Desktop/lsun-master/data"
,classes=["church_outdoor_val","classroom_val"]
,transform = transforms.ToTensor())
data_val
#Dataset LSUN
# Number of datapoints: 600
# Root location: /Users/zhucan/Desktop/lsun-master/data
# Classes: ['church_outdoor_val', 'classroom_val']
# StandardTransform
#Transform: ToTensor()
data_val[298]
#(tensor([[[0.1804, 0.1843, 0.1804, ..., 0.4902, 0.4863, 0.4863],
# [0.1922, 0.1961, 0.1961, ..., 0.4902, 0.4902, 0.4863],
# [0.1608, 0.1686, 0.1765, ..., 0.4941, 0.4902, 0.4902],
# ...,
# [0.1137, 0.1686, 0.1882, ..., 0.1804, 0.1765, 0.1804],
# [0.1294, 0.1804, 0.1922, ..., 0.1686, 0.1725, 0.1765],
# [0.1255, 0.1725, 0.1765, ..., 0.1882, 0.1843, 0.1804]],
#
# [[0.1451, 0.1490, 0.1451, ..., 0.8863, 0.8824, 0.8824],
# [0.1569, 0.1608, 0.1608, ..., 0.8863, 0.8863, 0.8824],
# [0.1255, 0.1333, 0.1412, ..., 0.8902, 0.8863, 0.8863],
# ...,
# [0.1882, 0.2431, 0.2549, ..., 0.2863, 0.2824, 0.2863],
# [0.1961, 0.2471, 0.2588, ..., 0.2902, 0.2941, 0.2980],
# [0.1922, 0.2392, 0.2431, ..., 0.3098, 0.3059, 0.3020]]]),
# 0)
data_val[500]
#(tensor([[[0.4471, 0.4196, 0.4196, ..., 0.0627, 0.0392, 0.0314],
# [0.3882, 0.3843, 0.4039, ..., 0.0588, 0.0863, 0.1020],
# [0.4157, 0.3843, 0.3725, ..., 0.1647, 0.1922, 0.2078],
# ...,
# [0.4078, 0.3961, 0.4235, ..., 0.2392, 0.2235, 0.2667],
# [0.3961, 0.3922, 0.4275, ..., 0.2549, 0.2588, 0.2549],
# [0.3922, 0.3922, 0.4314, ..., 0.2431, 0.2784, 0.2549]],
#
# [[0.2588, 0.2353, 0.2353, ..., 0.0549, 0.0314, 0.0235],
# [0.1490, 0.1451, 0.1725, ..., 0.0510, 0.0784, 0.0941],
# [0.0941, 0.0784, 0.0706, ..., 0.1569, 0.1843, 0.2000],
# ...,
# [0.2824, 0.2706, 0.2980, ..., 0.1843, 0.1686, 0.2118],
# [0.2706, 0.2667, 0.2941, ..., 0.2000, 0.2039, 0.2000],
# [0.2667, 0.2667, 0.2980, ..., 0.1882, 0.2235, 0.2000]]]),
# 1)
#此时标签会自动标注为0和1
#循环代码别在data_train上运行,时间会爆炸
for x,y in data_val:
print(y)
#break
#每个类别的验证集的大小都是300,因此两个类别就是共600个样本
check_ = 0
for x,y in data_val:
check_+=y
check_
#300
很遗憾的是,ImageNet数据集并不能使用pytorch中的datasets下的类来直接调用(能够被pytorch直接调用的都是tar.gz格式文件,或tar.gz解压后的文件),而VOC不能作为识别数据被使用,因此希望调用竞赛数据来完成分类任务则需要更多的技巧。在《一、2 使用自己的数据/图片创造数据集》中,我们将使用ImageNet和LSUN数据集来说明,如何将压缩文件/数据库文件中的图片导出为四维tensor。同时,VOC数据集的导入(识别和检测数据的导入)会在本课下半部分、讲解具体识别和检测任务的时候说明。
事实上,如果没有GPU计算资源的话,我不推荐大家使用ImageNet。虽然比起LSUN和VOC,
ImageNet含有更丰富的数据,只要我们有足够的硬盘空间,我们都可以下载或导入它,但在没有较大GPU支持的情况下,我们很难对这个数据进行适当的训练(proper training)。在没有GPU时,个人电脑的显存大多只有4G,在有GPU的情况下,显存可以达到8G或16G,但这和150G、200G的数据集比起来都不算什么。要训练ImageNet,我们必须使用非常小的batch_size,但batch_size过小又会延长训练完成一个epochs的时间。如果训练一个ImageNet需要20个小时,那我们就基本没有任何“学习体验”可言了。因此,如果我们要使用ImageNet数据集,我强烈建议大家使用Colab等线上平台的大型GPU。
1.3 景物、人脸、通用、其他
如果入门数据太简单,竞赛数据又太大该怎么办呢?难道就没有尺寸适中,又非常适合初学者练习和试验的数据集吗?当然有。除了竞赛数据和入门数据,我们还有不少通用的数据集,比如: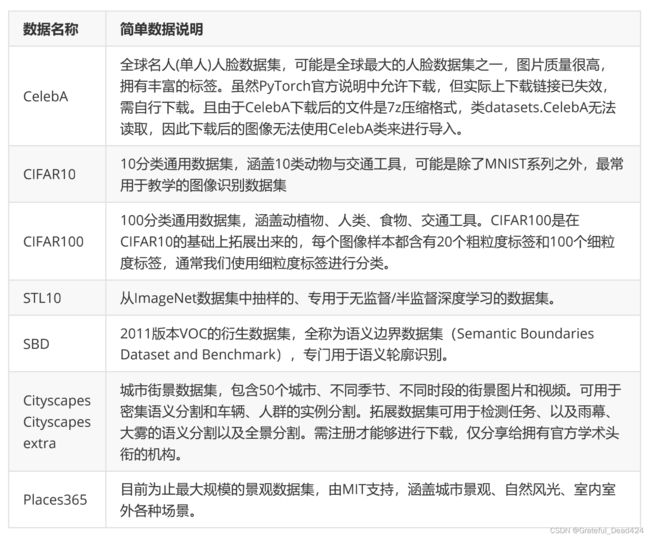
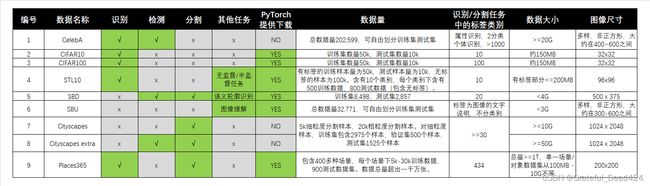
部分数据集的样例如下所示:
【CelebA】
【CIFAR10 & CIFAR100】

【STL-10】

【Cityscapes】

【Place365】
在课程中,我准备了celebA、CIFAR、sbu、sbd四种数据,在图像识别中我们比较常用的是CIFAR。以CIFAR为例,我们来调用一下这个数据集。我的根目录如下:
CIFAR文件夹内部为解压状态:
#import torch, torchvision
#import torchvision.transforms as transforms
#import matplotlib.pyplot as plt
#import numpy as np
#CIFAR10
#注意我的根目录到了哪一层
data = torchvision.datasets.CIFAR10(root = "/Users/zhucan/Desktop/cifar"
,train=True
,download=False
,transform = transforms.ToTensor()
)
#非常规整而且完整的数据集
#几乎就是彩图版MNIST
data[0][0].shape
#torch.Size([3, 32, 32])
for x,y in data:
print(x,y)
break
#tensor([[[0.2314, 0.1686, 0.1961, ..., 0.6196, 0.5961, 0.5804],
# [0.0627, 0.0000, 0.0706, ..., 0.4824, 0.4667, 0.4784],
# [0.0980, 0.0627, 0.1922, ..., 0.4627, 0.4706, 0.4275],
# ...,
# [0.8157, 0.7882, 0.7765, ..., 0.6275, 0.2196, 0.2078],
# [0.7059, 0.6784, 0.7294, ..., 0.7216, 0.3804, 0.3255],
# [0.6941, 0.6588, 0.7020, ..., 0.8471, 0.5922, 0.4824]],
#
# [[0.2431, 0.1804, 0.1882, ..., 0.5176, 0.4902, 0.4863],
# [0.0784, 0.0000, 0.0314, ..., 0.3451, 0.3255, 0.3412],
# [0.0941, 0.0275, 0.1059, ..., 0.3294, 0.3294, 0.2863],
# ...,
# [0.6667, 0.6000, 0.6314, ..., 0.5216, 0.1216, 0.1333],
# [0.5451, 0.4824, 0.5647, ..., 0.5804, 0.2431, 0.2078],
# [0.5647, 0.5059, 0.5569, ..., 0.7216, 0.4627, 0.3608]],
#
# [[0.2471, 0.1765, 0.1686, ..., 0.4235, 0.4000, 0.4039],
# [0.0784, 0.0000, 0.0000, ..., 0.2157, 0.1961, 0.2235],
# [0.0824, 0.0000, 0.0314, ..., 0.1961, 0.1961, 0.1647],
# ...,
# [0.3765, 0.1333, 0.1020, ..., 0.2745, 0.0275, 0.0784],
# [0.3765, 0.1647, 0.1176, ..., 0.3686, 0.1333, 0.1333],
# [0.4549, 0.3686, 0.3412, ..., 0.5490, 0.3294, 0.2824]]]) 6
data.data.shape
#(50000, 32, 32, 3)
data.classes
#['airplane',
# 'automobile',
# 'bird',
# 'cat',
# 'deer',
# 'dog',
# 'frog',
# 'horse',
# 'ship',
# 'truck']
np.unique(data.targets)
#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
data_test = torchvision.datasets.CIFAR10(root = "/Users/zhucan/Desktop/cifar"
,train=False
,download=False
,transform = transforms.ToTensor())
data_test
#Dataset CIFAR10
# Number of datapoints: 10000
# Root location: F:\datasets3\cifar
# Split: Test
# StandardTransform
#Transform: ToTensor()
plotsample(data)

#CIFAR100
data100 = torchvision.datasets.CIFAR100(root = "/Users/zhucan/Desktop/cifar"
,train=True
,download=False
,transform = transforms.ToTensor())
data100
#Dataset CIFAR100
# Number of datapoints: 50000
# Root location: F:\datasets3\cifar
# Split: Train
# StandardTransform
#Transform: ToTensor()
data100.classes
#['apple',
# 'aquarium_fish',
# 'baby',
# 'bear',
#
# 'willow_tree',
# 'wolf',
# 'woman',
# 'worm']
np.unique(data100.targets)
#array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
# 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
# 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50,
# 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67,
# 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84,
# 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99])
plotsample(data100)

SBU和SBD数据也可以使用torchvision.datasets进行读取,大家可以尝试自己读读看。不过注意他们都不能被用于图像识别任务。
对于学习资料中没有提供的数据文件,我们可以去哪里找呢?首先,我并不推荐使用pytorch当中自带的download功能,考虑到图像数据集的尺寸都不小,并且pytorch官方的下载功能通常速度较慢(实际上,我消耗了3天时间才将只有3G的SBU数据集下载下来),还十分容易出现超时的问题。因此,能够不使用download参数就不使用download参数。
如下图所示,对于PyTorch中带有的数据集,我们可以从数据说明中找到这个数据集的官方网站或原始地址。进入该原始地址后,我们大部分时候都可以找到数据的下载渠道。当然,通过原始地址下载的数据很有可能不能使用torchvision.datasets来进行读取,但我们也不妨一试。当你下载好的数据无法被读取时,可以尝试更换目录、解压下载文件等方式,或许可以被读取成功。
在dataset、dataset2、dataset3和dataset4四个文件夹中,分别存在不同的便于下载的数据集。这些数据集都很巨大,你必须下载和使用的数据都在dataset4中,其他文件夹中的内容你可以按需下载。在下一节中,我们将仔细来说明如何读取已经存在的、下载好的数据文件。无论数据文件是什么格式,我们都能够采用一定的方法将其处理成四维张量格式,从而让数据能够被输入卷积神经网络当中。