Learning to Segment Every Thing算法笔记
论文:Learning to Segment Every Thing
链接:https://arxiv.org/abs/1711.10370
Instance segmentation算法几乎都是fully supervised training,监督学习就要求数据中的object都有instance mask标注,但是由于这种标注代价较大,因此难以将这类算法延伸至数千个object类的instance segmentation。而这篇文章要做的恰恰就是large-scale instance segmentation. 要怎么实现呢?容易想到和instance mask标注类似的bounding box标注,bounding box标注的数据在各种object detection算法中应用较为成熟,相比之下标注代价较低,而且已标注的数据较为丰富,于是: Is it possible to train high quality instance segmentation models without complete instance segmentation annotations for all categories?基于这个想法,这篇文章就提出了一种partially supervised instance segmentation task并且采用 transfer learning method 实现。具体而言就是采用混合的数据集,其中一小部分是instance mask标注的(比如COCO数据集,80 classes),其余都是采用bounding box标注(比如Visual Genome数据集,3000 classes),算法以这两种数据作为输入,通过在Mask RCNN中引入transfer learning method,将模型输出的bounding box信息transfer成instance mask,换句话说就是学习一个函数映射(transfer function),将bounding box信息映射成instance mask,从而达到segment instances of all object categories的目的,如Figure1所示。

前面提到作者是采用transfer learning方法来实现partially supervised instance segmentation,而transfer learning是基于Mask RCNN框架的。那么为什么选用Mask R-CNN?Mask R-CNN is well-suited to our task because it decomposes the instance segmentation problem into the subtasks of bounding box object detection and mask prediction. 这也就和本文的两种类型数据集对应上了。
因此作者设计了一个 parameterized weight transfer function that is trained to predict a category’s instance segmentation parameters as a function of its bounding box detection parameters. The weight transfer function can be trained end-to-end in Mask R-CNN using classes with mask annotations as supervision. 简而言之就是通过训练Mask R-CNN网络得到weight transfer function,这个weight transfer function可以用来基于bounding box detection parameters预测instance segmentation parameters,这样就达到了基于混合数据集的instance segmentation。可以看出在作者设计的这种partially supervised training方案中,并不是直接训练网络得到instance segmentation parameters。在测试的时候就可以利用训练得到的weight transfer function去预测输入图像中每个类别的instance segmentation parameter,即便输入图像是那些在训练时候没有instance mask标注的数据。
Figure2是本文算法的细节。首先数据集方面主要包含两种,A:classes with box & mask data;B:classes with only box data。这里严格讲A数据集只有mask标注,但是因为根据mask标注信息可以较容易得到其bounding box的标注信息,所以默认数据集A也包含bounding box标注信息。
关于Figure2中的mask head,主要有两种类型,一种是采用FCN head,也就是用一个全卷积网络去预测M*M的mask;另一种是MLP head,也就是用几个全连接层去预测M*M的mask。在Mask RCNN中,FCN head的效果更好。作者在文中说到这两种类型的mask head其实是可以互补的:The MLP mask predictor may better capture the ‘gist’ of an object while the FCN mask predictor may better capture the details (such as the object boundary). 简而言之就是MLP偏向获取全局信息,毕竟全连接层可以融合特征;FCN偏向获取局部信息,卷积的特性如此。后面的实验结果中有相关实验对比。

weight transfer function的公式如下。这里c指的是一个指定的类,Wcseg表示class-specific mask weights(也就是前面说的mask parameters),Wcdet表示class-specific object detection weights(也就是前面说的bounding box parameters)。T()函数后面会提到,主要是全连接层来实现。
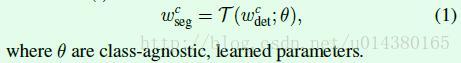
Figure2中的box head包含两部分,详细描述见下面截图:

接下来介绍训练时候的一些细节:
As shown in Figure 2, we train the bounding box head using the standard box detection losses on all classes in A∪B, but only train the mask head and the weight transfer function T() using a mask loss on the classes in A. Given these losses, we explore two different training procedures: stage-wise training and end-to-end training.
Stage-wise training. As Mask R-CNN can be seen as augmenting Faster R-CNN with a mask head, a possible training strategy is to separate the training procedure into detection training (first stage) and segmentation training (second stage). In the first stage, we train a Faster R-CNN using only the bounding box annotations of the classes in A∪B, and then in the second stage the additional mask head is trained while keeping the convolutional features and the bounding box head fixed. 这样的话detection weight在第二阶段训练的时候就不需要更新。
End-to-end joint training. In principle, one can directly train with back propagation using the box losses on classes in A∪B and the mask loss on classes in A. However, this may cause a discrepancy in the class-specific detection weights wcdet between set A and B, since only wcdet for c∈A will receive gradients from the mask loss through the weight transfer function T(). 可以看出直接训练的话,c∈A的detection weight wcdet 能接收到mask loss通过weight transfer函数回传的梯度,这样就相当于c∈A的detection weight wcdet既有mask loss的梯度,又有原来bounding box loss的梯度,而我们是希望属于A和B数据集的wcdet都可以接收到相同支路的梯度。怎么解决呢?可以看下面这个截图。简而言之就是在回传mask loss的梯度时,只传给weight transfer function用于预测mask weight,而不传给bounding box weight。

实验结果:
一些实验细节:Each minibatch has 16 images 512 RoIs-per-images, and the network is trained for 90k iterations on 8 GPUs. 主网络采用ResNet-50-FPN or ResNet-101-FPN。minibatch大小为16,其中每张图包含512个ROI。
Table1是关于本文算法中各个细节设计上的对比实验。其中voc表示PASCAL VOC数据集中的20类,non-voc表示从COCO数据集中去除PASCAL VOC的20类后剩下的60个类。强调下B是只含有bounding box标注的数据集,A是包含instance segmentation标注的数据集。class-agnostic是一个baseline算法,具体而言是带有一个class-agnostic FCN mask prediction head 的Mask RCNN,在这个算法中all the categories share the same learned segmentation parameters(no weight transfer function is involved)。fully supervised(oracle)表示完全采用监督算法做的instance segmentation。下面各表中数字加黑的行是本文算法采用的方法。(a)是对比weight transfer function的不同输入对结果的影响。transfer w/ cls+box是本文的算法。(b)是关于weight transfer function的不同形式的实验结果对比,前面提到过weight transfer function可以采用全连接层来实现,通过对比可以看出不同数量的全连接层和不同类型的激活函数对最后结果的影响并不大。(c)是关于不同类型的mask branch的对比,尤其是验证MLP mask branch的有效性。其中第四行的transfer+MLP就是两种不同的Mask head融合的效果,因为transfer中已经包含了FCN作为Mask head。(d)是两种不同训练方式:stage-wise(‘sw’)和end-to-end(‘e2e’)的对比,可以看出end-to-end的训练方式更加有效,而且在end-to-end的训练方式中stop gradient也比较重要。
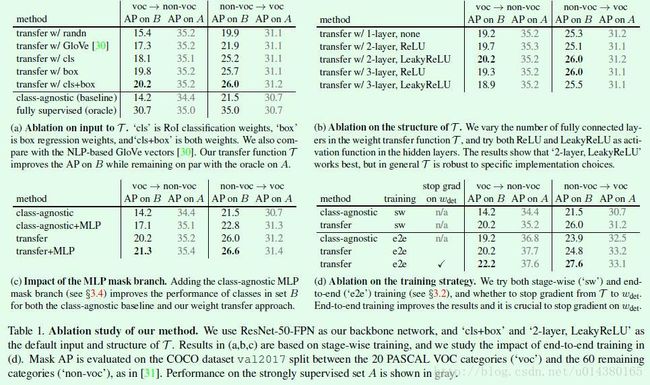
Table2是关于本文算法和其他算法的对比。

关于训练和验证数据集的具体划分以及更多实验结果可以参看原文。