知识图谱-知识体系与知识融合-实体消歧
目录
1 实体消歧定义
2 基于聚类的实体消歧
3 基于实体链接的语义消歧
4 其他实体链接任务
5 实体链接常用数据集
6 实体链接面临的挑战
1 实体消歧定义
1. 命名实体的歧义指的是一个实体指称项可对应到多个真实世界实体;
2. 确定一个实体指称项所指向的真实世界实体,这就是命名实体消歧;

3. 对于一段自然语言文本,“迈克尔·乔丹教授昨天访问了CMU”。要从自然语言文本中抽取信息构成知识图谱,处理流程如下:
命名实体识别:
[迈克尔·乔丹]/PER教授昨天访问了[CMU]/ORG
关系抽取:
(迈克尔·乔丹,visit, CMU)
抽取出三元组并不能直接构造知识图谱,因为我们不知道迈克尔·乔丹到底是哪个迈克尔·乔丹,CMU到底指的是哪个机构。因此,需要利用实体链接技术;
4.自然语言任务的歧义性:同一表达不同意义
普通的歧义:
一词多义
打水,打电话,打毛衣,打哈欠,打拍子
拍子坏了,打拍子
看电影,看病
炒菜,炒外汇,炒鱿鱼
Bank:银行,河岸
Plant:植物,工厂
一义多词
计算机,电脑
WordNet
同义词词林
5. 词义排歧 vs 实体消歧
相同点:都在解决语言中的词汇歧义问题;
不同点: 普通词及其义项通常是比较固定的;
实体词的义项数目要比普通词多很多;
实体词消歧的场景比普通词消歧要丰富;
实体词消歧可用的特征比普通词要多;
6.实体消歧方法分类
基于无监督聚类的实体消歧;
所有实体指称项按其指向的目标实体进行聚类;
每一个实体指称项对应到一个单独的类别;
基于实体链接的实体消歧
将实体指称项与目标实体列表中对应实体进行链接,实现消歧。
2 基于聚类的实体消歧
1. 基本思路
指向相同实体的实体指称项有相似的上下文
核心问题:选取何种特征对指称项进行表示
词袋模型
语义特征
社会化网络
维基百科的知识
多源异构语义知识融合
2. 词袋模型
利用实体指称项上下文中的词来构造向量
利用向量空间模型来计算两个实体指称项的相似度,进行聚类
3. 语义特征
词袋模型,没有考虑词的语义信息
方法:利用SVD分解挖掘词的语义信息
利用词袋和浅层语义特征,共同表示指称项,利用余弦相似度来计算两个指称项的相似度
4. 社会化网络
不同的人具有不同的社会关系
例子:
MJ(BasketBall): Pippen, Buckley, Ewing, Kobe...
MJ(Machine Learning): Liang, Mackey, Wauthier...
在网页实体消歧时,利用MJ, Pippen, Buckley, Ewing, Kobe等社会化关联信息所表现出来的网页链接特征,对网页进行聚类,从而实现对网页内的人名聚类消歧
5. Wikipedia
Wikipedia中相关实体具有超链接关系,比如姚明的页面中有指向休斯顿火箭队的超链接
这种链接关系反映条目之间的语义相关度
计算公式:
![]()
|A|, |B|, 表示文章A与文章B中的超链接个数(去掉文章中重复的超链接),也就是与实体a紧密相关的实体;
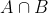 表示在文章A与文章B中都存在的超链接个数,也就是与实体a和b都相关的实体;
表示在文章A与文章B中都存在的超链接个数,也就是与实体a和b都相关的实体;
|W|表示Wikipedia中所有的实体个数;
如果sr(a, b)=1,表明a和b相关;
如果sr(a, b) 接近0,表明a和b无关;
用实体上下文的维基条目对于实体进行向量表示;
利用维基条目之间的相关度计算指称项之间的相似度(解决数据稀疏问题)
6. 多元异构知识
仅仅考虑Wikipedia一种知识源,覆盖度有限
知识源中存在大量的多源异构知识
挖掘和集成多源异构知识可以提高实体消歧的性能;
Wikipedia
用于捕捉概念之间的语义关联
WordNet
用于捕捉词语之间的语言学关联
Web网页库
用于捕捉命名实体之间的社会化关联
网页中的超链接
社交网络中的社交关系
关注、评论、转发等
挖掘和集成不同知识源中的结构化语义知识的第一个关键问题是如何使用知识表示模型来统一表示这些语义知识:
在WordNet中,语义知识被表示为Word Sense 和Word Sense之间的词汇化语义关系(同义、反义、部分等关系,语言学关联);
在Wikipedia中,语义知识被表示为概念之间的语义关联;
多源异构知识的表示框架:结构化语义关联图(简称语义图):
每个节点代表一个独立的概念;
节点之间的边代表概念之间的语义关系;
边的权重代表语义关系的强度:
◼ 可以是三类语义关联的加权
◼ 也可以取最大
语义图的构建
概念抽取
◼ WordNet概念:首先切分词,然后使用词在WordNet中的最常见词义作为其语义
◼ 对命名实体:利用命名实体识别系统进行识别
◼ Wikipedia概念:首先识别出Wikipedia概念的指称项,然后将其映射到对应概念上
等同概念识别
概念抽取的一个难点是同一个概念在不同知识源中表示不同。例如,Wikipedia中的Most Valuable Player概念和WordNet中的词义(mostvaluable player, MVP)表示的是同一个概念;
如果两个概念共享同一个字面表现形式,则认为两个概念是等同概念;
概念链接
对每一对节点表示的概念关系进行识别,判断两个概念之间是否存在语义关系;
多源异构结构化知识挖掘:语义图中的知识以两种方式存在
语义图的节点:代表了结构化语义知识。例如:一个节点建模了所有与该节点所表示的实体显式相关的实体的语义
语义图的边:代表了显式语义知识。例如:NBA和Basketball的关联以及NBA和MVP的关联
语义图的路径:代表了隐式语义知识。(隐式语义关联)(如果一个节点的邻居节点与另一个节点存在语义关联,则这个节点也与另一个节点存在语义关联)
7. 评测
WePS: Web People Search Evaluation
任务:
Web环境中的人名消歧,即给定一个包含某个歧义人名的网页集合,按照网页中人名指称项所指向的人物概念来对网页进行聚类,以及抽取一个网页中关于某个人的特定属性来辅助进行人名消歧
评测方法:
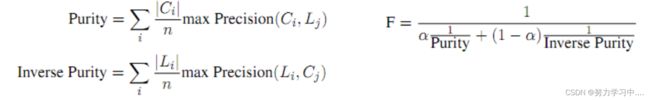
纯净度(purity):评价的聚类结果中每个类别中指称项的平均准确率;
倒纯净度(inverse purity):评价的聚类结果中每个类别中指称项的平均召回率
WePS1是SEMEVAL2007的子任务;
WePS2是WWW的一个workshop;
WePS数据到来自于网络。对每一个歧义人名,WePS数据集提供其在搜索引擎中的前N个结果,每个结果包括以下信息 :在原来搜索引擎中的排序、URL、Snippet和标题等
3 基于实体链接的语义消歧
1. 实体链接任务:给定实体指称项和它所在的文本,将其链接到给定知识库中的相应实体上;
2. 实体链接输入:
目标实体知识库:目前最常用的是Wikipedia,在其他一些任务中可能是特定领域的知识库,比如说社交媒体中的Yelp,电影领域的IMDB等;
待消歧实体指称项及其上下文信息;
实体链接输出:文本中实体指称项映射到的知识库中的实体;
3. 实体链接主要步骤
候选实体的发现
给定实体指称项,链接系统根据知识、规则等信息找到实体指称项的候选实体;
候选实体的链接
系统根据指称项和候选实体之间的相似度等特征,选择实体指称项的目标实体;
无链接实体(NIL)的聚类

候选实体发现:
Wikipedia消歧页面(维基百科中用于消除“一词多义”所引起的歧义的页面);
Wikipedia重定向页面:人们在输入该名称进入条目时,系统能够自动导航到重定向页面
内部指定的另一相关页面中,从而实现相关页面可以以多个名称进行访问
利用上下文(缩略语问题):在实体指称项文本中,缩略语的全称出现过,利用人工规则抽取实体候选
计算实体指称项和候选实体的相似度,选择相似度最大的候选实体(利用先验知识做初始排序,局部实体链接,协同实体链接)
3. 候选实体的发现 - 利用先验知识做初始排序 - 利用指称项指向实体的概率
利用指称项指向实体的概率作为先验知识对候选实体进行粗筛选是非常必要的;
指称项指向实体的概率

4. 候选实体的发现 - 局部实体链接
传统特征的方法( 2016-2017年之前 ):
BOW模型 (Honnibal TAC 2009, Bikel TAC 2009)
加入实体流行度等特征(Han ACL 2011)
加入候选实体的类别特征(Bunescu et al., EACL 2006)
表示学习的方法( 2017-至今):如何获得实体和实体指称项上下文的分布式表示
实体表示比较复杂:从不同粒度来表示实体;可能会利用实体的类别(Entity Type)信息;可能会利用Wikipedia中实体与实体共现关系。
卷积神经网络模型(Francis-Landau et al., NAACL 2016)
利用预训练实体向量表示实体(Ganea and Hofmann, EMNLP 2017)
5. 局部实体链接 - 传统特征 - BOW模型
将实体指称项上下文文本与候选实体上下文文本表示成词袋子向量形式,通过计算向量间的夹角确定指称项与候选实体相似度,系统选择相似度最大的候选实体进行链接
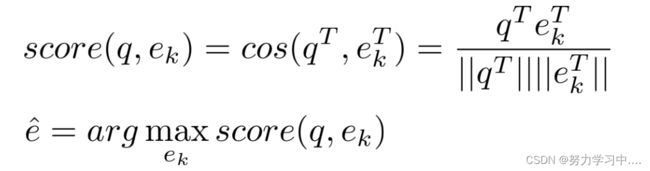
6. 局部实体链接 - 传统特征 - 在局部链接中考虑实体流行度等特征
词袋模型问题:仅仅是计算实体指称项与候选实体的相似度,忽略了候选实体的背景知识与先验信息,如实体本身的流行度、实体与指称项的关系等
方法:
考虑实体的背景知识,将实体的背景知识融入到实体链接的过程,实体的背景知识和先验信息主要有:
实体流行度:实体e在知识库中的概率P(e);
名称的知识:指称项s指向实体e的概率P(s|e);
上下文知识:实体e出现在特定上下文环境c的概率P(c|e);
7. 局部实体链接 - 传统特征 - 类别特征
动机:
候选实体的文本内容可能太短,会导致相似度计算的不准确;
加入指称项文本中的词与候选实体类别的共现特征
方法:
训练SVM分类器对候选实体进行选择;
训练数据由Wikipedia中的超级链接获得
所采用的特征
文本相似度
指称项文本中词与候选实体类别的共现信息
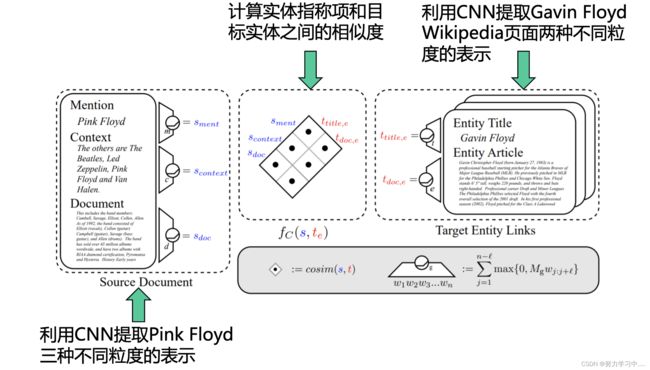
8. 局部实体链接 - 表示学习 - 卷积神经网络模型
问题:
之前的方法对目标实体和实体指称项表示都是启发式的,如词袋模型, tf-idf等。这些启发式算法很难调整,而且它们很难捕获更细粒度的语义信息和结构信息;
指称项的多粒度表示:词、句子、篇章
方法:
利用卷积网络分别得到实体指称项的表示;实体指称项上下文表示;实体指称项所在篇章的表示 。
利用卷积神经网络得到目标实体标题表示;目标实体篇章表示;
计算实体指称项的三个表示和目标实体的两个表示两两之间的相似度,得到六维相似度向量。这个向量包含了不同粒度的相似度信息。将这个向量与传统特征拼接,通过logistic回归得到最终相似度得分。
9. 局部实体链接 - 表示学习 - 利用预训练实体向量表示实体
动机:
是否可以像预训练的词向量一样,提前将实体向量训练好,这样在训练和测试过程中就可以很方便地通过查表法得到实体表示;
上下文中不同词对于消歧具有不同的重要性;
现有的局部实体链接方法将上下文中的词同等对待;
例子:
12月20日,清华大学正式宣布聘请计算机科学机器学习领域顶级学者Michael I. Jordan为访问教授。
上下文中的“计算机”、“机器学习”、“教授”对消歧实体指称项“Michael I. Jordan”有帮助,而“聘请”和“访问”等词对消歧实体用处不大。
方法:
利用word2vec方法训练实体向量;
利用注意力机制实现自动去除上下文中的停用词;
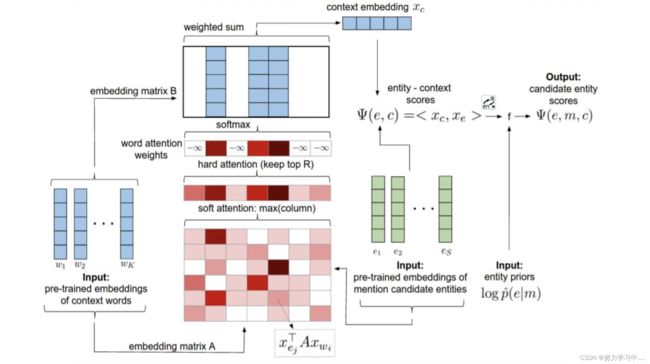
论文:Ganea O E, Hofmann T. Deep joint entity disambiguation with local neural attention. EMNLP 2017
10. 候选实体的发现 - 协同实体链接
不仅要实体指称项与目标实体的语义相似度,还要考虑目标实体之间的全局语义相似度;
协同实体链接是在局部实体链接之上,增加了一个全局项(协同策略),来综合考虑目标实体之间一致性
全局项计算方法:
基于图的方法 (Han et al., SIGIR 2011)
基于条件随机场的方法 (Ganea et al., EMNLP 2017)
基于Pair-Linking的方法 (Phan et al., CIKIM 2017)
4 其他实体链接任务
1. 跨语言实体链接:跨语言实体链接中要利用到不同语言知识库之间的对应关系,但很多语言Wikipedia并不完备,例如北梭托语只有4000个Wikipedia页面;
跨语言候选实体生成很难;
跨语言文本相似度计算很难:神经网络跨语言实体链接需要解决实体指称项描述语言词向量和英文词向量的位于不同语义空间的问题;
2. 实体列表中的实体链接
输入是网页实体列表,没有列表周围的文本来帮助实体指称项排歧
协同实体链接利用同一文档中的实体是语义相关的性质来帮助链接,而实体列表中的实体应该是拥有同一类型的实体,是语义相似而不是语义相关;
基于”列表中的实体指称项应该拥有同一种类型”的假设,候选实体要满足:
这个候选实体的先验概率较高;
这个候选实体的类型与同一个列表中其他列表项的对应实体的类型一致(语义相似);
建模语义相似的方法:
基于类型层次结构的相似性;
实体上下文分布相似性;
利用最大间隔方法自动学习特征的权值,为每个候选实体定义链接质量;
利用迭代替换算法对实体列表中所有相对应的实体进行联合优化;
3. 社交数据中的实体链接
社交媒体的特点(以Tweet为例)
用户多,每个月的活跃用户超过3亿3千万人
数目大,每天Tweet的数量超过5亿条, 主题从生活到突发的新闻
Tweet文本的特点:
字数限制,每条tweet不超过140个字,文本短
噪音大,非正式的缩写,写作方式口语化,打字错误
实时性强,tweet内容中包含了很多新发生的事件和新产生的实体
5 实体链接常用数据集
1. AIDA(AIDA CoNLL-YAGO ):由马普研究所公开的数据集,是目前最大的手工标注实体链接数据集。它是基于CoNLL 2013 实体识别数据集上标注的,题材是路透社新闻;
2. WNED :自动构建的数据 ,数据规模很大 。 WNED-CWEB 是 从ClueWeb中自动构建的,WNED-WIKI是从Wikipedia中自动构建的。由于是自动构建的数据,所以数据中噪音比较大,可信度较低
3.

4. TAC KBP数据集 2009-2018:TAC (Text Analysis Conference) KBP(Knowledge Base Population)是国际上知名的实体链接评测,由美国国防高级研究计划局(DARPA)资助。数据来源是新闻和论坛,是手工标注的数据集。
TAC-KBP (2009-2013):Entity Linking
任务:将文本中的实体指称项链接到Wikipedia中的真实概念,达到消歧的目的;
TAC-KBP (2014-Present):Entity Discovery and Linking
任务:识别出文本中的实体指称项,并将文本中的实体指称项链接到Wikipedia中的真实概念,达到消歧的目的。
◼ 2014年-2017年,实体指称项类别只有5类 ,人名,地点名,组织机构名,地缘政治实体,设施名。
◼ 2018年,将实体指称项的类别扩充至 7309种,这7309中类别是Yago中的实体类别的一部分
6 实体链接面临的挑战
1. 缩写与别名的难点:在候选生成的时候如何将别名与缩写的实体引入;
2. 常识知识;
如何定义常识知识
如何大规模地动态地获取常识知识
如何表示常识知识
如何将常识知识融入实体链接
3. 无链接实体指称项预测(NIL问题)
现有工作中无链接实体指称项识别和聚类算法都是启发式的,都比较简单;
学界忽视这个问题,实体链接论文中主要部分关注于候选实体链接这一步骤,不考虑NIL问题;
NIL问题本身就很困难,很难提出有效的特征来解决;
NIL问题很难和候选实体链接端到端的解决
4. 其他领域和多模态的实体链接
现在实体链接数据集大部分都是基于新闻语料构建的,其他领域内语料规模和数量都远远不够;
现在实体链接只是利用单模态(文本的信息),多模态实体链接缺乏研究;
参考: 国科大-知识图谱课件