模式识别系列(五)对偶支撑向量机和核向量机
目录
- 1.对偶支撑向量机
-
- 1.1对偶问题
-
- 1.1.1线性规划对偶问题
- 1.1.2拉格朗日对偶问题
- 1.2概念提出
- 1.3公式推导
- 1.4对偶支撑向量机求解
- 2.核向量机
-
- 2.1问题提出
- 2.2核函数和核矩阵
- 2.3核向量机
1.对偶支撑向量机
1.1对偶问题
1.1.1线性规划对偶问题
在提出对偶支撑向量机之前,先得有对偶的概念。对偶就是对同一个问题,从不同的角度描述。举一个简单的例子,当周长一定,面积最大的矩形是正方形,而当面积一定,周长最小的矩形是正方形,这就是两个对偶的表述。再举一个例子,一个工厂可以选择出租设备或者生产产品,如果站在他的角度,那自然生产的利益要最大化,而站在租用设备的人的角度,他所付出的钱希望是最少的,从两边看对偶问题就是把一个最大值问题变成了最小值问题,因此线性规划中的对偶问题有如下标准型:
min w = y b max z = c x y A ≥ c A x ≤ b y ≥ 0 x ≥ 0 \begin{aligned} &\begin{array}{ccc} \min w=y b & & \max z & =c x \\ y A \geq c & & A x & \leq b \\ y \geq 0 & & x \geq 0 \end{array}\\ \end{aligned} minw=ybyA≥cy≥0maxzAxx≥0=cx≤b
这两个问题就互为对偶问题。对偶问题满足弱对偶性,即上式中的前者大于等于后者,就好像高个中挑个矮的,要比矮个中挑个高的来的高。
1.1.2拉格朗日对偶问题
拉格朗日对偶问题就是对拉格朗日函数进行对偶所形成的问题。首先,我们有一个目标函数的标准型:
min f ( x ) s.t. c i ( x ) ≤ 0 , i = 1 , 2 , ⋯ , k h j ( x ) = 0 , j = 1 , 2 , ⋯ , l \begin{array}{lc} \min & f(x) \\ \text { s.t. } & c_{i}(x) \leq 0, \quad i=1,2, \cdots, k \\ & h_{j}(x)=0, \quad j=1,2, \cdots, l \end{array} min s.t. f(x)ci(x)≤0,i=1,2,⋯,khj(x)=0,j=1,2,⋯,l
那么我们就可以通过拉格朗日函数的方式将约束放进函数里
L ( x , α , β ) = f ( x ) + ∑ i = 1 k α i c i ( x ) + ∑ j = 1 l β j h j ( x ) , a i ≥ 0 L(x, \alpha, \beta)=f(x)+\sum_{i=1}^{k} \alpha_{i} c_{i}(x)+\sum_{j=1}^{l} \beta_{j} h_{j}(x), a_i\geq0 L(x,α,β)=f(x)+i=1∑kαici(x)+j=1∑lβjhj(x),ai≥0
随后我们令拉格朗日函数最大化
θ P ( x ) = max α , β ; α i ≥ 0 L ( x , α , β ) \theta_P(x)=\max _{\alpha, \beta ; \alpha_{i} \geq 0} L(x, \alpha, \beta) θP(x)=α,β;αi≥0maxL(x,α,β)
假如有违反约束的值出现,比如 c i ( x ) > 0 c_{i}(x)>0 ci(x)>0 或者 h j ( x ) ≠ 0 h_{j}(x) \neq 0 hj(x)=0,由于 α \alpha α和 β \beta β是我们可以手动选择的,那么我们就可以选择一个趋向 + ∞ +\infty +∞的 α \alpha α,让上面的函数最大值是无穷,也就是没有最大值。而相反,当自变量 x x x满足约束条件, θ p ( x ) \theta_p(x) θp(x)取极大值时, α \alpha α只能是0,而 β \beta β对于函数值没有影响,最后的结果就是
θ P ( x ) = max α , β ; α i ≥ 0 [ f ( x ) + ∑ i = 1 k α i c i ( x ) + ∑ j = 1 l β j h j ( x ) ] = f ( x ) \theta_{P}(x)=\max _{\alpha, \beta ; \alpha_{i} \geq 0}\left[f(x)+\sum_{i=1}^{k} \alpha_{i} c_{i}(x)+\sum_{j=1}^{l} \beta_{j} h_{j}(x)\right]=f(x) θP(x)=α,β;αi≥0max[f(x)+i=1∑kαici(x)+j=1∑lβjhj(x)]=f(x)
由此一来,原问题就变成了
p ∗ = min x max α , β ; α i ≥ 0 L ( x , α , β ) p^* = \underset{x}{\min}\underset{\alpha, \beta ; \alpha_{i} \geq 0}{\max} L(x, \alpha, \beta) p∗=xminα,β;αi≥0maxL(x,α,β)
再从另外一个角度出发,由于 max α , β ; α i ≥ 0 L ( x , α , β ) = f ( x ) \underset{\alpha, \beta ; \alpha_{i} \geq 0} {\max}L(x, \alpha, \beta) = f(x) α,β;αi≥0maxL(x,α,β)=f(x)那么自然而然 f ( x ) ≥ L ( x , α , β ) f(x)\geq L(x,\alpha,\beta) f(x)≥L(x,α,β)是成立的,因而
min f ( x ) ≥ min x L ( X , α , β ) = d \min f(x) \geq \underset{x}{\min} L(X,\alpha, \beta) = d minf(x)≥xminL(X,α,β)=d
显然:
min x L ( x , α , β ) ≤ L ( x , α , β ) ≤ max α , β ; α i ≥ 0 L ( x , α , β ) \underset{x}{\min} L(x,\alpha,\beta) \leq L(x,\alpha,\beta) \leq \underset{\alpha, \beta ; \alpha_{i} \geq 0}{\max} L(x, \alpha, \beta) xminL(x,α,β)≤L(x,α,β)≤α,β;αi≥0maxL(x,α,β)
那么现在就可以考虑这样一个问题,令 d ∗ = max d d^* = \max d d∗=maxd,即:
d ∗ = max α , β ; α i ≥ 0 min x L ( x , α , β ) d^* = \underset{\alpha, \beta ; \alpha_{i} \geq 0}{\max}\underset{x}{\min} L(x,\alpha,\beta) d∗=α,β;αi≥0maxxminL(x,α,β)
从形式上 p ∗ p^* p∗和 d ∗ d^* d∗正好形成对偶,而且满足弱对偶性,即 d ∗ ≤ q ∗ d^* \leq q^* d∗≤q∗。究其原因,就在于 d d d和 q q q的变量是不一致的, d d d的变量是 α \alpha α和 β \beta β,给出了原函数的一个下界,而 q q q的变量是 x x x, q ∗ q^* q∗求的是原函数的最小值,而我们知道,一个函数的下界是小于函数最小值的,但我们可以通过求下确界,也就是求 d ∗ d^* d∗,来逼近函数的最小值,这就是拉格朗日对偶法的基本思想。如果原函数是一个凸函数,那么 d ∗ d^* d∗= p ∗ p^* p∗是成立的,这就是强对偶性。
本篇的内容是对偶SVM,我们花了这么多篇幅来解释拉格朗日对偶,原因就在于此:当原问题 p ∗ p^* p∗不那么好求的时候,我们可以用对偶的 d ∗ d^* d∗来求解,达到一个近似逼近的效果。
1.2概念提出
首先我们来温习一下标准SVM的目标函数:
min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w T ⋅ x i + b ) ≥ 1 , i = 1 , 2 , … , N \begin{aligned} &\quad\quad\min _{w, b} \frac{1}{2}\|w\|^2\\\\ \text { s.t. }\quad &y_{i}\left(w^T \cdot x_{i}+b\right) \geq 1, i=1,2, \ldots, N \\ \end{aligned} s.t. w,bmin21∥w∥2yi(wT⋅xi+b)≥1,i=1,2,…,N
那么求解的变量就有 d + 1 d+1 d+1个维度,在实际中,如果我们要拟合非线性的多项式,那么势必要对原始输入变量进行升维,比如将 ( x 1 , x 2 ) (x1,x2) (x1,x2)变成 ( x 1 , x 2 , x 1 x 2 , x 1 2 , x 2 2 ) (x1,x2,x1x2,x1^2,x2^2) (x1,x2,x1x2,x12,x22),诸如此类。这还仅仅是二元二次,还有更高次的变换,这样很可能特征向量的维度就很高了,优化的困难无疑变大了。因此我们可以用上节提到的拉格朗日乘子法,改写目标函数:
min w , b max α i ≥ 0 1 2 ∥ w ∥ 2 − ∑ i = 1 N α i ( y i w T ⋅ x i + y i b ) + ∑ i = 1 N α i \min _{w, b} \max _{\alpha_i \geq 0} \frac{1}{2}\|w\|^2 - \sum_{i=1}^N\alpha_i(y_{i}w^T \cdot x_{i}+y_{i}b) + \sum_{i=1}^N \alpha_i w,bminαi≥0max21∥w∥2−i=1∑Nαi(yiwT⋅xi+yib)+i=1∑Nαi
通过对偶拉格朗日,将目标函数改为:
max α i ≥ 0 min w , b 1 2 ∥ w ∥ 2 − ∑ i = 1 N α i ( y i w T ⋅ x i + y i b ) + ∑ i = 1 N α i \max _{\alpha_i \geq 0}\min _{w, b} \frac{1}{2}\|w\|^2 - \sum_{i=1}^N\alpha_i(y_{i}w^T \cdot x_{i}+y_{i}b) + \sum_{i=1}^N \alpha_i αi≥0maxw,bmin21∥w∥2−i=1∑Nαi(yiwT⋅xi+yib)+i=1∑Nαi
通过下界去逼近,此时这个目标函数就变成了了 α i \alpha_i αi的函数,而 α i \alpha_i αi就和维度一点关系都没有了,只和样本数量有关,这就转移了优化的难点。
1.3公式推导
在上节我们给出了对偶向量机的拉格朗日对偶函数,那么这个函数怎么优化呢?首先我们看里面,是一个无约束的函数吧,那么是不是可以求极值点呢?,分别对 w w w和 b b b求偏导,得到以下结果:
∂ L ∂ b = − ∑ i = 1 N α i y i ∂ L ∂ w = w − ∑ i = 1 N α i y i x i \begin{aligned} &\frac{\partial L}{\partial b} = - \sum_{i=1}^N \alpha_i y_i \\ &\frac{\partial L}{\partial w} = w - \sum_{i=1}^N\alpha_i y_ix_i \end{aligned} ∂b∂L=−i=1∑Nαiyi∂w∂L=w−i=1∑Nαiyixi
上面两个偏导都只有一个极值点,那么我们就可以令 ∑ i = 1 N α i y i = 0 \sum_{i=1}^N \alpha_i y_i = 0 ∑i=1Nαiyi=0, w = ∑ i = 1 N α i y i x i w = \sum_{i=1}^N\alpha_i y_ix_i w=∑i=1Nαiyixi,此时目标函数就变成了 α i \alpha_i αi的单变量函数,即:
max α i ≥ 0 ; ∑ i = 1 N α i y i = 0 ; w = ∑ i = 1 N α i y i x i 1 2 ∥ ∑ i = 1 N α i y i x i ∥ 2 + ∑ i = 1 N α i \max _{\alpha_i \geq 0;\sum_{i=1}^N \alpha_i y_i = 0;w = \sum_{i=1}^N\alpha_i y_ix_i}\ \frac{1}{2}\|\sum_{i=1}^N\alpha_i y_ix_i\|^2 + \sum_{i=1}^N \alpha_i αi≥0;∑i=1Nαiyi=0;w=∑i=1Nαiyiximax 21∥i=1∑Nαiyixi∥2+i=1∑Nαi
之所以可以这么做,是因为在进行对偶后自变量发生了改变,整个是 α \alpha α的函数,内外就可以分离了。
提出一个负号,问题就变成了:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j x i T x j − ∑ i = 1 N α i s.t ∑ i = 1 N y i α i = 0 ; α i ≥ 0 , for i = 1 , 2 , … , N \begin{aligned} \min _{\alpha} & \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} x_{i}^{T} x_{j}-\sum_{i=1}^{N} \alpha_{i} \\ \text { s.t } & \sum_{i=1}^{N} y_{i} \alpha_{i}=0 ; \\ & \alpha_{i} \geq 0, \text { for } i=1,2, \ldots, N \end{aligned} αmin s.t 21i=1∑Nj=1∑NαiαjyiyjxiTxj−i=1∑Nαii=1∑Nyiαi=0;αi≥0, for i=1,2,…,N
1.4对偶支撑向量机求解
对于上面一节的问题,我们可以对比二次规划的标准型:
min q ( z ) = 1 2 z T G z + z T c s.t. a i T x ≥ b i , i ∈ τ \begin{aligned} &\min q(z)=\frac{1}{2} z^{T} G z+z^{T} c\\ \text{s.t.}\quad&\quad a_{i}^{T} x \geq b_{i}, \quad i \in \tau \end{aligned} s.t.minq(z)=21zTGz+zTcaiTx≥bi,i∈τ
和上一篇一样,我们只需要令
z = α ; G i , j = y i y j x i T x j ; c = − 1 ; a i T = y i ; b i = 0 z=\alpha; G_{i,j}=y_iy_jx_i^Tx_j ; c=\mathbf{-1} ; \mathbf{a}_{i}^{T}=y_i; b_{i}=0 z=α;Gi,j=yiyjxiTxj;c=−1;aiT=yi;bi=0
就能转化成二次规划问题了。
求解出了 α i \alpha_i αi,就可以根据 w = ∑ i = 1 N α i y i x i w = \sum_{i=1}^N\alpha_i y_ix_i w=∑i=1Nαiyixi得出向量 w w w,根据 a i n ( 1 − y i ( w T x i + b ) ) = 0 a_in(1 - y_i(w^Tx_i + b)) = 0 ain(1−yi(wTxi+b))=0,求得 b b b。 a n > 0 a_n > 0 an>0的这些向量就是所谓的支撑向量,处在边界上的这些向量。
2.核向量机
2.1问题提出
核向量机是基于对偶向量机的。在对偶向量机中,虽然优化的维度不随特征的维度增加而增加,但是并不代表向量的特征维度不会影响计算复杂度,可以看到,式中有一项 x i T x j x_i^Txj xiTxj,复杂度很高的。因此就提出了核向量机的概念,即——升维后的内积是不是可以由升维前的内积直接得到。
2.2核函数和核矩阵
假设 ϕ ( x ) \phi(x) ϕ(x)是升维的函数,那么核函数用数学语言描述就是:
K < x , z > = < ϕ ( x ) , ϕ ( z ) > K
K表示对
ϕ ( x 1 ) T ϕ ( x 2 ) = < ( x 1 2 , 2 x 1 y 1 , y 1 2 ) , ( x 2 2 , 2 x 2 y 2 , y 2 2 ) > = x 1 2 x 2 2 + 2 x 1 y 1 x 2 y 2 + y 1 2 y 2 2 = ( x 1 y 1 + x 2 y 2 ) 2 = ( x 1 T x 2 ) 2 \begin{aligned} \phi(x_1)^T\phi(x_2) = & <(x_1^2, \sqrt{2}x_1y_1, y_1^2),(x_2^2, \sqrt{2}x_2y_2, y_2^2)>\\ = & x_1^2x_2^2 + 2x_1y_1x_2y_2 + y_1^2y_2^2\\ =&(x_1y_1 +x_2y_2)^2\\ =&(x_1^Tx_2)^2 \end{aligned} ϕ(x1)Tϕ(x2)====<(x12,2x1y1,y12),(x22,2x2y2,y22)>x12x22+2x1y1x2y2+y12y22(x1y1+x2y2)2(x1Tx2)2
核函数的方式,等于说仅仅计算了升维前的内积,可以大大减少计算量。常用的多项式核函数有如下的形式:
K ( x i , x j ) = ( α + β x i T x j ) n K(x_i,x_j) = (\alpha + \beta x_i^Tx_j)^n K(xi,xj)=(α+βxiTxj)n
另外高斯核函数也是常用的核函数,形式如下:
K ( x i , x j ) = e − ∥ x i − x j ∥ 2 2 σ 2 K(x_i,x_j) = e^{-\frac{\|x_i - x_j\|^2}{2\sigma^2}} K(xi,xj)=e−2σ2∥xi−xj∥2
高斯核又称无穷维度的核函数,原理很简单,用微积分里的麦克劳林展开公式展开这个指数函数就行了,会发现是一个无穷维度多项式求和的形式。在sklearn库里常用的RBF核就是高斯核,参数gamma就正比于 1 σ 2 \frac{1}{\sigma^2} σ21,我个人的理解 σ \sigma σ类似于一个样本的影响范围,当它很大,高斯函数就比较平缓,一个正样本会增加附近样本的正向概率,当它很小,一个正样本很可能只能保证自己的正向概率,类比起来就像是连绵的群山和山洞里的钟乳石这样。
当然,我们自然可以自己设计这么一个核函数,要求就是满足核矩阵板正定,也就是
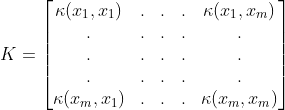 半正定 x T K x ≥ 0 x^TKx \ge 0 xTKx≥0,这方面没有学习,有兴趣可以自己搜索相关内容
半正定 x T K x ≥ 0 x^TKx \ge 0 xTKx≥0,这方面没有学习,有兴趣可以自己搜索相关内容
2.3核向量机
有了上面的基础,核向量机也就自然而然可以写出来了,形式为:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K < x i , x j > − ∑ i = 1 N α i s.t ∑ i = 1 N y i α i = 0 ; α i ≥ 0 , for i = 1 , 2 , … , N \begin{aligned} \min _{\alpha} & \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} K
到这里,支撑向量机部分施工完毕。