统计学习(五):线性模型选择与正则化
文章目录
- 线性模型选择与正则化
-
- 子集选择
-
- 最优子集选择
- 逐步选择
-
- 向前逐步选择
- 向后逐步选择
- 混合方法
- 选择最优模型
-
- C~p~,AIC,BIC与调整R^2^
- 验证与交叉验证
- 压缩估计方法
-
- 岭回归
- lasso
-
- 岭回归和lasso的其他形式
- 对比lasso与岭回归
- 岭回归和lasso的贝叶斯解释
- 选择调节参数
- 降维方法
-
- 主成分回归
-
- 主成分分析(PCA)
- 主成分回归方法(PCR)
- 偏最小二乘
线性模型选择与正则化
线性模型
Y = β 0 + β 1 X 1 + ⋯ + β p X p + ε Y=\beta_0+\beta_1X_1+\cdots+\beta_pX_p+\varepsilon Y=β0+β1X1+⋯+βpXp+ε尽管线性模型很简单,但该线性模型在其可解释性方面具有明显的优势,并且往往表现出良好的预测性能。
下面我们讨论可替代普通最小二乘拟合的一些拟合方法(更高的预测准确率和更好的模型解释力)。
- 子集选择:从 p p p 个预测变量中挑选出与响应变量相关的变量形成子集,再对缩减的变量集合使用最小二乘方法。
- 压缩估计:基于全部 p p p 个预测变量进行模型的拟合。可以将估计系数往零的方向进行压缩,通过系数缩减(又称正则化)减少方差。
- 降维法:将 p p p 维预测变量投影到 M M M 维子空间中, M < p M
M<p
。通过计算这 p p p 个变量的 M M M 种不同的线性组合或称投影来实现。将这 M M M 个不同的投影作为预测变量,再使用最小二乘法拟合线性回归模型。
子集选择
最优子集选择
- 记不含预测变量的零模型为 M 0 M_0 M0,只用于估计各观测的样本均值。
- 对于 k = 1 , 2 , ⋯ , p k=1,2,\cdots,p k=1,2,⋯,p:
- 拟合 ( p k ) \left(\begin{matrix}p\\k\end{matrix}\right) (pk) 个包含 k k k 个预测变量的模型。
- 在 ( p k ) \left(\begin{matrix}p\\k\end{matrix}\right) (pk) 个模型中选择 R S S RSS RSS 最小或 R 2 R^2 R2 最大的作为最优模型,记为 M k M_k Mk。
- 根据交叉验证预测误差、 C p ( A I C ) C_p(AIC) Cp(AIC)、 B I C BIC BIC 或者调整 R 2 R^2 R2 从 M 0 , ⋯ , M p M_0,\cdots,M_p M0,⋯,Mp 中选择出一个最优模型。
我们也可以对其他模型进行最优子集选择,例如逻辑斯蒂回归模型。在逻辑斯蒂回归模型中使用最优子集选择方法时,应使用偏差(diviance) 替代原先的RSS对模型进行选择,偏差适用范围更广。
逐步选择
由于运算效率的限制,当 p p p 很大时最优子集选择方法不再适用,且存在一些统计学上的问题。从一个巨大搜索空间中得到的模型通常会有过拟合和系数估计方差高的问题。逐步选择限制了搜索空间,提高了运算效率。
向前逐步选择
向前逐步选择以一个不包含任何预测变量的零模型为起点,依次往模型中添加变量,直至所有的预测变量都包含在模型中,特别之处在于,每次只将能够最大限度提升模型效果的变量加入模型中。
- 记不含预测变量的零模型为 M 0 M_0 M0。
- 对于 k = 0 , 1 , 2 , ⋯ , p − 1 k=0,1,2,\cdots,p-1 k=0,1,2,⋯,p−1:
- 从 p − k p-k p−k 个模型中进行选择,每个模型都在模型 M k M_k Mk 的基础上增加一个变量;
- 在 p − k p-k p−k 个模型中选择 R S S RSS RSS 最小或 R 2 R^2 R2 最大的作为最优模型,记为 M k + 1 M_{k+1} Mk+1。
- 根据交叉验证预测误差、 C p ( A I C ) C_p(AIC) Cp(AIC)、 B I C BIC BIC 或者调整 R 2 R^2 R2 从 M 0 , ⋯ , M p M_0,\cdots,M_p M0,⋯,Mp 中选择出一个最优模型。
但该方法无法保证找到的模型是所有 2 p 2^p 2p 个模型中最优的。
在高维数据中,甚至 n < p n n<p
向后逐步选择
以包含全部 p p p 个变量的全模型为起点,逐次迭代,每次移除一个对模型拟合结果最不利的变量。
- 记包含全部 p p p 个预测变量的全模型为 M p M_p Mp。
- 对于 k = p , p − 1 , ⋯ , 1 k=p,p-1,\cdots,1 k=p,p−1,⋯,1:
- 在 k k k 个模型中进行选择,在模型 M k M_k Mk 的基础上减少一个变量,则模型只包含 k − 1 k-1 k−1 个变量;
- 在 k k k 个模型中选择 R S S RSS RSS 最小或 R 2 R^2 R2 最大的作为最优模型,记为 M k − 1 M_{k-1} Mk−1。
- 根据交叉验证预测误差、 C p ( A I C ) C_p(AIC) Cp(AIC)、 B I C BIC BIC 或者调整 R 2 R^2 R2 从 M 0 , ⋯ , M p M_0,\cdots,M_p M0,⋯,Mp 中选择出一个最优模型。
该方法同样无法保证找到的模型是包含 p p p 个预测变量子集的最优模型。
向后选择方法需满足样本量 n n n 大于变量个数 p p p 的条件,而向前逐步选择即使在 p > n p>n p>n 的情况下也能使用,因此当 p p p 非常大的时候,向前逐步选择是唯一可行的方法。
混合方法
逐次将变量加入模型,然而在加入新变量的同时,该方法也移除不能提升模型拟合效果的变量。
选择最优模型
估计测试误差:
- 根据过拟合导致的偏差对训练误差进行调整,间接地估计测试误差。
- 通过验证集方法或交叉验证方法直接估计测试误差。
Cp,AIC,BIC与调整R2
这些方法可以根据模型的size调整训练误差,并且可用于在一组具有不同变量数量的模型中进行选择。
采用最小二乘法拟合一个包含 d d d 个预测变量的模型, C p C_p Cp 值的计算公式为:
C p = 1 n ( R S S + 2 d σ ^ 2 ) C_p=\frac{1}{n}(RSS+2d\hat{\sigma}^2) Cp=n1(RSS+2dσ^2)
其中 σ ^ 2 \hat{\sigma}^2 σ^2 是线性模型中各响应变量观测误差的方差 ε \varepsilon ε 的估计值。
AIC准则适用于使用极大似然法进行拟合的模型,一般而言:
A I C = − 2 log L + 2 d AIC=-2\log L+2d AIC=−2logL+2d
其中 L L L 是估计模型的似然函数的最大值, d d d 为预测变量个数。
若模型误差项服从高斯分布,极大似然估计和最小二乘估计是等价的:
A I C = 1 n σ ^ 2 ( R S S + 2 d σ ^ 2 ) AIC=\frac{1}{n\hat{\sigma}^2}(RSS+2d\hat{\sigma}^2) AIC=nσ^21(RSS+2dσ^2)
假设 y i y_i yi 服从 N ( x i β , σ 2 ) N(x_i\beta,\sigma^2) N(xiβ,σ2):
L ( β , σ 2 ∣ x i ) = ∏ i = 1 n 1 2 π σ e x p { − ( y i − x i β ) 2 2 σ 2 } log L = − ∑ i = 1 n ( y i − x i β ) 2 2 σ 2 − n 2 log σ 2 − 2 log L = 1 σ 2 R S S + n log σ 2 L(\beta,\sigma^2|x_i)=\prod_{i=1}^n\frac{1}{\sqrt{2\pi}\sigma}exp\{-\frac{(y_i-x_i\beta)^2}{2\sigma^2}\}\\\log L=-\sum_{i=1}^n\frac{(y_i-x_i\beta)^2}{2\sigma^2}-\frac{n}{2}\log \sigma^2\\-2\log L=\frac{1}{\sigma^2}RSS+n\log\sigma^2 L(β,σ2∣xi)=i=1∏n2πσ1exp{−2σ2(yi−xiβ)2}logL=−i=1∑n2σ2(yi−xiβ)2−2nlogσ2−2logL=σ21RSS+nlogσ2
BIC是从贝叶斯观点中衍生出来的,对于包含 d d d 个预测变量的最小二乘模型:
B I C = 1 n ( R S S + log ( n ) d σ ^ 2 ) BIC=\frac{1}{n}(RSS+\log(n)d\hat{\sigma}^2) BIC=n1(RSS+log(n)dσ^2)
类似于 C p C_p Cp,测试误差较低的模型BIC统计量取值也较低。BIC将 C p C_p Cp 中的 2 d σ ^ 2 2d\hat{\sigma}^2 2dσ^2 替换成 log ( n ) d σ ^ 2 \log(n)d\hat{\sigma}^2 log(n)dσ^2,其中 n n n 是观测数量。对于任意的 n > 7 n>7 n>7,有 log n > 2 \log n>2 logn>2,BIC统计量通常给包含多个变量的模型施以较重的惩罚,所以与 C p C_p Cp 相比,得到的模型规模更小。
调整 R 2 R^2 R2 是另一种方法。
A d j u s t e d R 2 = 1 − R S S / ( n − d − 1 ) T S S / ( n − 1 ) 其 中 : T S S = ∑ ( y i − y ˉ ) 2 Adjusted \ R^2=1-\frac{RSS/(n-d-1)}{TSS/(n-1)}\\其中:TSS=\sum(y_i-\bar{y})^2 Adjusted R2=1−TSS/(n−1)RSS/(n−d−1)其中:TSS=∑(yi−yˉ)2
调整 R 2 R^2 R2 越大,模型测试误差越低。最大化 R 2 R^2 R2 等价于最小化 R S S n − d − 1 \frac{RSS}{n-d-1} n−d−1RSS。RSS随着模型包含的变量个数的增加而减少,而由于d在分母中的出现, R S S n − d − 1 \frac{RSS}{n-d-1} n−d−1RSS 可能增加也可能减小。
验证与交叉验证
为每个可能最优的模型计算验证集误差或者交叉验证误差,然后选择测试误差估计值最小的模型。
与AIC、BIC、 C p C_p Cp 和调整 R 2 R^2 R2 相比,优势在于,它给出了测试误差的一个直接估计,并且对真实的潜在模型有较少的假设。
验证与交叉验证方法的适用范围更广,即便在很难确定模型自由度,或难以估计误差方差 σ 2 \sigma^2 σ2 的情况下仍可使用。
一倍标准误差准则(one-standard-error rule):首先计算不同规模下模型测试均方误差估计值的标准误差,然后选择测试样本集误差估计值在曲线最低点一倍标准误差之内且规模最小的模型。原因是在一系列效果近似相同的模型中,总是倾向于选择最简单的模型,即具有最少预测变量的模型。
压缩估计方法
将系数估计值往零的方向压缩,通过压缩系数估计值,显著减少了估计量方差。两种最常用的将回归系数往零的方向进行压缩的方法是岭回归(ridge regression)和lasso。
岭回归
岭回归系数估计值 β ^ R \hat{\beta}^R β^R 通过最小化下式得到:
∑ i = 1 n ( y i − β 0 − ∑ j = 1 p β j x i j ) 2 + λ ∑ j = 1 p β j 2 = R S S + λ ∑ j = 1 p β j 2 \sum_{i=1}^n(y_i-\beta_0-\sum_{j=1}^p\beta_jx_{ij})^2+\lambda\sum_{j=1}^p\beta_j^2=RSS+\lambda\sum_{j=1}^p\beta_j^2 i=1∑n(yi−β0−j=1∑pβjxij)2+λj=1∑pβj2=RSS+λj=1∑pβj2
其中 λ ≥ 0 \lambda\geq0 λ≥0 是一个调节参数,将单独确定。 ∣ ∣ β ∣ ∣ 2 = ∑ j = 1 p β j 2 ||\beta||_2=\sqrt{\sum_{j=1}^p\beta_j^2} ∣∣β∣∣2=∑j=1pβj2,称为 l 2 l_2 l2 惩罚项。
与最小二乘相同,岭回归通过最小化RSS寻求能较好地拟合数据的估计量,此外,另一项 λ ∑ j = 1 p β j 2 \lambda\sum_{j=1}^p\beta_j^2 λ∑j=1pβj2 称为压缩惩罚(shrinkage penalty),当 β 1 , ⋯ , β p \beta_1,\cdots,\beta_p β1,⋯,βp 接近零时比较小,因此具有将 β i \beta_i βi 估计值往零的方向进行压缩的作用。调节参数 λ \lambda λ 的作用是控制这两项对回归系数估计的相对影响程度。
不过,该公式并未对 β 0 \beta_0 β0 进行惩罚。
最小二乘系数估计是尺寸不变的(scale equivariant): X j X_j Xj 乘以常数c,最小二乘系数估计结果是原来的值乘以1/c,即无论第j个预测变量如何按比例变化, X j β ^ j X_j\hat\beta_j Xjβ^j 保持不变。但是,岭回归系数估计值可能会发生显著的改变。
因此,在使用岭回归前,最好先用如下公式进行标准化:
x ~ i , j = x i j 1 n ∑ i = 1 n ( x i j − x ˉ j ) 2 \tilde x_{i,j}=\frac{x_{ij}}{\sqrt{\frac{1}{n}\sum_{i=1}^n(x_{ij}-\bar x_j)^2}} x~i,j=n1∑i=1n(xij−xˉj)2xij
与最小二乘相比,岭回归的优势在于综合权衡了误差与方差。随着 λ \lambda λ 的增加,岭回归拟合结果的光滑度降低,虽然方差降低,但是偏差在增加。
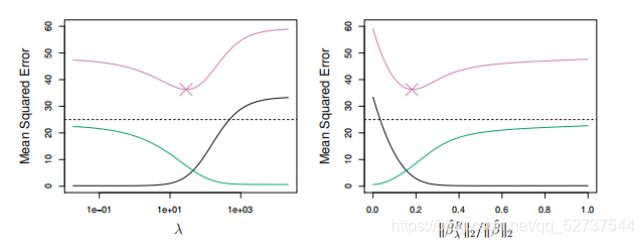
当最小二乘估计方差很大时,岭回归效果更好。
岭回归的劣势:最终模型包含全部的 p p p 个变量,惩罚项可以将系数往0的方向进行缩减,但是不会把任何一个变量的系数确切地压缩到0。这种设定不影响预测精度,但是当变量个数 p p p 非常大时,不便于模型解释。
lasso
lasso的系数 β ^ λ L \hat\beta_\lambda^L β^λL 通过求解下式的最小值得到:
∑ i = 1 n ( y i − β 0 − ∑ j = 1 p β j x i j ) 2 + λ ∑ j = 1 p ∣ β j ∣ = R S S + λ ∑ j = 1 p ∣ β j ∣ \sum_{i=1}^n(y_i-\beta_0-\sum_{j=1}^p\beta_jx_{ij})^2+\lambda\sum_{j=1}^p|\beta_j|=RSS+\lambda\sum_{j=1}^p|\beta_j| i=1∑n(yi−β0−j=1∑pβjxij)2+λj=1∑p∣βj∣=RSS+λj=1∑p∣βj∣
∣ ∣ β ∣ ∣ 1 = ∑ ∣ β j ∣ ||\beta||_1=\sum|\beta_j| ∣∣β∣∣1=∑∣βj∣,称为 l 1 l_1 l1 惩罚项。
与岭回归相同,lasso也将系数估计值往0的方向进行缩减,但当调节参数 λ \lambda λ 足够大时, l 1 l_1 l1 惩罚项具有将其中某些系数的估计值强制设定为0的作用,完成了变量选择,更易于解释。
lasso得到了稀疏模型(sparse model)——只包含所有变量的一个子集的模型。
岭回归和lasso的其他形式
m i n i m i z e β { ∑ i = 1 n ( y i − β 0 − ∑ j = 1 p β i x i j ) 2 } , ∑ j = 1 p ∣ β j ∣ ≤ s m i n i m i z e β { ∑ i = 1 n ( y i − β 0 − ∑ j = 1 p β i x i j ) 2 } , ∑ j = 1 p β j 2 ≤ s minimize_{\beta}\{\sum_{i=1}^n(y_i-\beta_0-\sum_{j=1}^p\beta_ix_{ij})^2\},\sum_{j=1}^p|\beta_j|\leq s\\minimize_{\beta}\{\sum_{i=1}^n(y_i-\beta_0-\sum_{j=1}^p\beta_ix_{ij})^2\},\sum_{j=1}^p\beta_j^2\leq s minimizeβ{i=1∑n(yi−β0−j=1∑pβixij)2},j=1∑p∣βj∣≤sminimizeβ{i=1∑n(yi−β0−j=1∑pβixij)2},j=1∑pβj2≤s
在 s s s 控制 ∑ j = 1 p ∣ β j ∣ \sum_{j=1}^p|\beta_j| ∑j=1p∣βj∣ 大小的限制下,或在 ∑ j = 1 p β j 2 \sum_{j=1}^p\beta_j^2 ∑j=1pβj2 不超过 s s s 的条件下,尽可能寻找使得RSS最小的系数。
对比lasso与岭回归
一般情况下,当一小部分预测变量是真实有效的而其他预测变量系数非常小或者等于零时,lasso要更为出色;当响应变量是很多预测变量的函数并且这些变量系数大致相等时,岭回归较为出色。
然而,对于一个真实的数据集,与响应变量有关的变量个数无法事先知道,因此提出了像交叉验证这样的方法,用于决定哪个方法更适合某个特定数据集。
例子:考虑 n = p n=p n=p, X X X 是对角线都为1、非对角线都为0的对角矩阵,没有截距的回归,此时,普通最小二乘问题就简化为寻找 β 1 , ⋯ , β p \beta_1,\cdots,\beta_p β1,⋯,βp 来最小化:
∑ j = 1 p ( y j − β j ) 2 \sum_{j=1}^p(y_j-\beta_j)^2 j=1∑p(yj−βj)2
此时,最小二乘的解是 β ^ j = y j \hat\beta_j=y_j β^j=yj。岭回归:
∑ j = 1 p ( y j − β j ) 2 + λ ∑ j = 1 p β j 2 \sum_{j=1}^p(y_j-\beta_j)^2+\lambda\sum_{j=1}^p\beta_j^2 j=1∑p(yj−βj)2+λj=1∑pβj2
使上式达到最小的估计系数为:
β ^ j R = y j / ( 1 + λ ) \hat\beta_j^R=y_j/(1+\lambda) β^jR=yj/(1+λ)
lasso:
∑ j = 1 p ( y j − β j ) 2 + λ ∑ j = 1 p ∣ β j ∣ \sum_{j=1}^p(y_j-\beta_j)^2+\lambda\sum_{j=1}^p|\beta_j| j=1∑p(yj−βj)2+λj=1∑p∣βj∣
使上式达到最小的估计系数为:
β ^ j L = { y j − λ 2 , y j > λ 2 y j + λ 2 , y j < − λ 2 0 , y j ≤ ∣ λ 2 ∣ \hat\beta_j^L=\begin{cases}y_j-\frac{\lambda}{2},y_j>\frac{\lambda}{2}\\y_j+\frac{\lambda}{2},y_j<-\frac{\lambda}{2}\\0,y_j\leq|\frac{\lambda}{2}|\end{cases} β^jL=⎩⎪⎨⎪⎧yj−2λ,yj>2λyj+2λ,yj<−2λ0,yj≤∣2λ∣
岭回归和lasso的贝叶斯解释
假设普通线性模型:
Y = β 0 + X 1 β 1 + ⋯ + X p β p + ε Y=\beta_0+X_1\beta_1+\cdots+X_p\beta_p+\varepsilon Y=β0+X1β1+⋯+Xpβp+ε
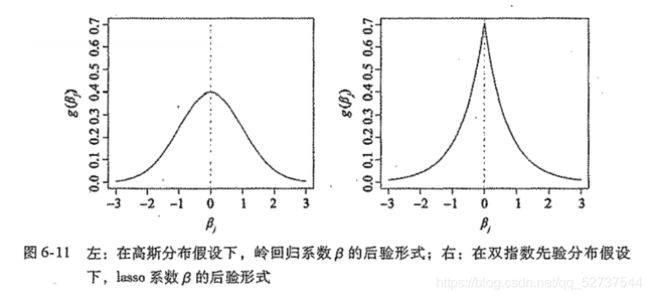
残差独立并服从正态分布, p ( β ) = ∏ j = 1 p g ( β j ) p(\beta)=\prod_{j=1}^pg(\beta_j) p(β)=∏j=1pg(βj),g是密度函数:
- 如果g是高斯分布,均值为零,标准化为 λ \lambda λ,那么给定数据, β \beta β 后验形式最可能为岭回归所得到的结果。
- 如果g是双指数(拉普拉斯)分布,均值为零,尺度参数为 λ \lambda λ,那么 β \beta β 的后验形式最可能是lasso的结果。
选择调节参数
使用交叉验证:选择一系列 λ \lambda λ 值,计算每个 λ \lambda λ 的交叉验证误差,然后选择使得交叉验证误差最小的参数值,最后,用所有可用变量和选择的调节参数对模型进行重新拟合。
降维方法
令 Z 1 , Z 2 , ⋯ , Z M Z_1,Z_2,\cdots,Z_M Z1,Z2,⋯,ZM 表示M个原始预测变量的线性组合(M
其中 ϕ 1 m , ϕ 2 m , ⋯ , ϕ p m \phi_{1m},\phi_{2m},\cdots,\phi_{pm} ϕ1m,ϕ2m,⋯,ϕpm 是常数, m = 1 , ⋯ , M m=1,\cdots,M m=1,⋯,M。可用最小二乘拟合线性回归模型:
y i = θ 0 + ∑ m = 1 M θ m Z i m + ε i , i = 1 , 2 , ⋯ , n y_i=\theta_0+\sum_{m=1}^M\theta_mZ_{im}+\varepsilon_i,i=1,2,\cdots,n yi=θ0+m=1∑MθmZim+εi,i=1,2,⋯,n
使估计p+1个系数 β 0 , β 1 , ⋯ , β p \beta_0,\beta_1,\cdots,\beta_p β0,β1,⋯,βp 的问题简化为估计M+1个系数 θ 0 , θ 1 , ⋯ , θ M \theta_0,\theta_1,\cdots,\theta_M θ0,θ1,⋯,θM 的问题,M
系数形式上的约束很可能使估计结果有偏,但当p远大于n时,选择一个 M ≪ p M\ll p M≪p 可以显著地降低拟合系数的方差。如果 M = p M=p M=p,所有的 Z m Z_m Zm 线性无关。实际未施加任何约束。
主成分回归
主成分分析(PCA)
第一主成分 Z 1 Z_1 Z1 是具有最大方差的变量线性组合。
第二主成分 Z 2 Z_2 Z2 是所有与第一主成分 Z 1 Z_1 Z1 无关的原始变量的线性组合中方差最大的。
Z 1 、 Z 2 Z_1、Z_2 Z1、Z2 的零相关关系等价于 Z 1 Z_1 Z1 的方向是垂直或者正交于 Z 2 Z_2 Z2。
实线代表第一主成分方向,虚线代表第二主成分方向。

主成分回归方法(PCR)
PCR是指构造前 M M M 个主成分 Z 1 , ⋯ , Z M Z_1,\cdots,Z_M Z1,⋯,ZM,然后以这些主成分作为预测变量,用最小二乘拟合线性回归模型。
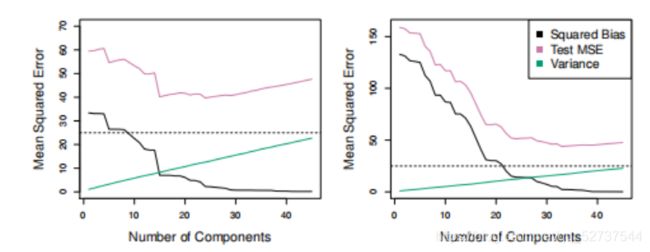
随着引入回归模型的主成分越来越多,偏差随之降低,而方差随之增大,使均方误差呈现出U形。
如果只需前几个主成分就可以充分捕捉预测变量的变动及其与响应变量的关系,主成分回归的效果会更好。
尽管主成分分析在实践中效果不错,但当模型只包含特征变量的一个小子集时,它对模型的提升能力并不明显。主成分分析更接近岭回归。
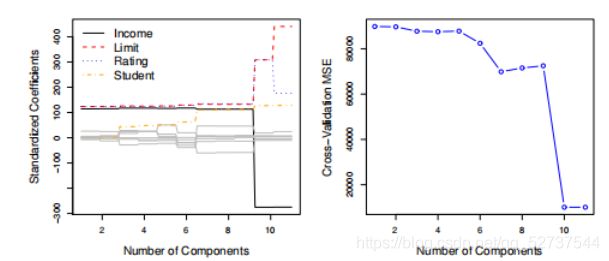
主成分数量 M M M 一般通过交叉验证确定。建议在构造主成分分析之前,对每个变量进行标准化处理,保证所有变量在相同尺度上。
上图中,最小交叉验证误差出现在有 M = 10 M=10 M=10 个主成分的情况下。
偏最小二乘
主成分回归(PCR)可以最大限度地代表预测变量 X 1 , ⋯ , X p X_1,\cdots,X_p X1,⋯,Xp 的线性组合或方向。这些方向是通过无指导方法得到的,因此响应变量 Y Y Y 对选择主成分方向并无帮助,响应变量没有指导主成分的构造过程,无法保证那些很好地解释预测变量的方向同样可以很好地预测响应变量。
偏最小二乘(PLS)是一种有指导的主成分回归替代方法,也是一种降维手段,将原始变量的线性组合 Z 1 , ⋯ , Z M Z_1,\cdots,Z_M Z1,⋯,ZM 作为新的变量集,然后用这 M M M 个新变量拟合最小二乘模型。与PCR不同,PLS通过有指导的方法进行新特征提取,利用了响应变量 Y Y Y 的信息筛选变量。
简单来说,偏最小二乘试图寻找一个可以同时解释响应变量和预测变量的方向。
方法:对第一个偏最小二乘方向 Z 1 Z_1 Z1,对 p p p 个预测变量进行标准化后,PLS将
Z 1 = ∑ j = 1 p ϕ j 1 X j Z_1=\sum_{j=1}^p\phi_{j1}X_j Z1=j=1∑pϕj1Xj
中的各个系数 ϕ j 1 \phi_{j1} ϕj1 设定为 Y Y Y 对 X j X_j Xj 简单线性回归的系数,可证明此系数同 Y Y Y 和 X j X_j Xj 的相关系数成比例,因此在计算 Z 1 = ∑ j = 1 p ϕ j 1 X j Z_1=\sum_{j=1}^p\phi_{j1}X_j Z1=∑j=1pϕj1Xj 时,PLS将最大权重赋给与响应变量相关性最强的变量。
为确定第二个PLS方向,首先用 Z 1 Z_1 Z1 中每个变量对 Z 1 Z_1 Z1 做回归,取其残差来调整每个变量,残差可以理解为没有被第一PLS方向解释的剩余信息,然后利用这些正交数据计算 Z 2 Z_2 Z2。这个迭代过程重复进行 M M M 次来确定多个PLS成分 Z 1 , ⋯ , Z M Z_1,\cdots,Z_M Z1,⋯,ZM。最后,用 Z 1 , ⋯ , Z M Z_1,\cdots,Z_M Z1,⋯,ZM 拟合线性最小二乘模型来预测 Y Y Y。
PLS方向的个数 M M M 也是个需要调整的参数,一般通过交叉验证选择。