超分之BasicVSR
这篇文章是2021年的CVPR,文章作者是和EDVR同一批的人。该篇文章提出了一个轻量且高表现性能的视频超分framework——BasicVSR。BasicVSR改进了传统VSR结构中的propagation和alignment部分,分别提出了一个双向视频流的循环结构以及基于flow-based的feature-wise对齐方法。此外,在BasicVSR的基础上,作者进一步对propagation和aggregation进行优化,产生了一个更高表现性能的VSR结构——IconVSR。
参考目录:
①BasicVSR++
②源码
BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond
- Abstract
- 写在前面
- 1 Introduction
- 2 Related Work
- 3 Methodology
-
- 3.1 BasicVSR
- 3.2 From BasicVSR to IconVSR
- 4 Experiments
-
- 4.1 Comparisons with State-of-the-Art Methods
- 5 Ablation Studies
-
- 5.1 From BasicVSR to IconVSR
- 5.2 Tradeoff in IconVSR
- 6 Conclusion
Abstract
- 作者将VSR分为4个功能块,即通用的VSR的pipeline为:
Propagation、Alignment、Aggregation(Fusion)、Upsampling。作者通过设计一种双向循环结构的propagation、基于光流的feature-wise的alignment以及使用现存的一些融合和上采样方法,形成一种简单轻量的在速度和重建表现力上都优于现存VSR结构的视频超分方法——BasicVSR。 - BasicVSR可以作为一种后续研究VSR的baseline,我们可以以它为backbone,继续往上增加一些功能。
- 作者向我们展示了如何延申BasicVSR:通过对BasicVSR的propagation部分增加coupled-propagation结构,以及在Aggregation部分增加Information-refill来形成一个更高表现力且模型量略微增加的VSR模型——IconVSR,它和BasicVSR都可以作为后续研究的基石。
写在前面
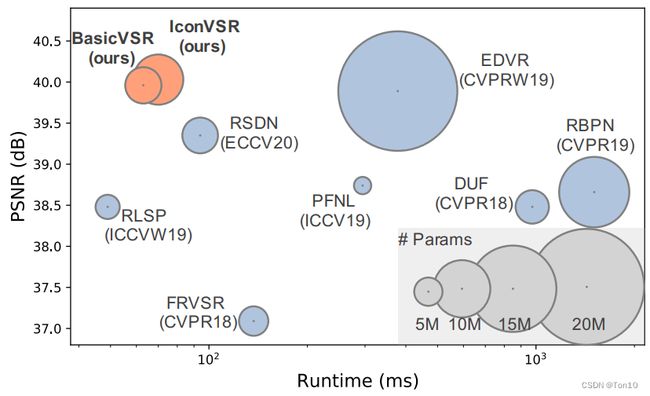
一般来说,视频超分比SISR更加复杂,因为他要处理多帧的融合问题以及不同时间帧之间的对齐问题。在EDVR中,其作者引入多尺度的可变形卷积网络来做对齐,用时间和空间注意力来做融合;类似的视频超分还有TDAN、Robust-LTD、VESPCN、DUF、FRVSR、RSDN等。这些方法基本上各有各的设计,且诸如RBPN和EDVR还会有较大的模型参数,具体如下图所示: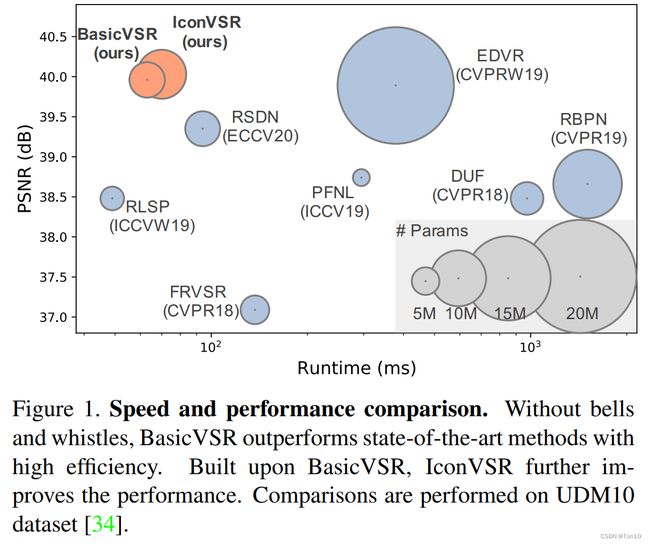
因此作者试图去设计一种更通用、更有效率、轻量的VSR模型作为我们日后研究的baseline。
于是,BasicVSR就开始了!
1 Introduction
首先将VSR分为4个部分:
①Propagation:它决定了VSR如何去利用视频序列的信息,它可以将所有的VSR分为Sliding-Window和Recurrent两类。
②Alignment:时间和空间上的关于内容对齐。
③Aggregation:特征信息的聚合,或者可以说就是Fusion,它旨在将对齐后的连续帧进行时间和空间上的特征融合。
④Upsampling:上采样层,将融合后的特征信息转变成 H R HR HR层级的信息。
作者列举了近年来的几种VSR方法,并按照上述的pipeline进行整理归纳,具体如下图所示:
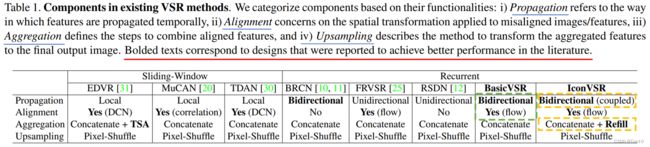
- 从图中可以看出,
BasicVSR对Propagation和Alignment做了新的设计,而对于Aggregation和Upsampling则利用之前的VSR的方法。具体而言,BasicVSR的Propagation使用了Bidirectional(双向)循环机制,分为前向分支和后向分支,将整个输入序列的所有信息都加入到后续的对齐中;而对齐子网络使用flow-based方法,但对齐是feature-wise的,即使用光流估计,但是对齐是做在feature map上的;融合使用最基本的concat(或者说就是Early fusion);上采样使用ESPCN提出的PixelShuffle,即亚像素卷积层。BasicVSR这种结构在性能和速度上都取得了很大的突破,证明了BasicVSR的可行性和轻量性。 - BasicVSR最有价值的地方在于其可以作为一个起点,一个日后VSR研究的baseline,通过不断地扩展四个部分来设计新的VSR模型。作者给了如何去扩展的例子——
IconVSR。IconVSR则是在BasicVSR的基础上,对Propagation和Aggregation做了升级。具体而言,Propagation部分进一步引入Coupled机制,旨在前向分支中加入后向分支的信息,这样的好处在于对于遮挡区域在刚露出来的时候,它可以基于后向的信息来较好的重建出这一块刚出现的区域;对齐部分还是和BasicVSR是一样的;Aggregation部分引入了Information-refill,它可以弥补BasicVSR丢失的一些信息,比如说在遮挡区域、边界区域,Information-refill就可以通过一个额外的特征提取模块对关键帧及其相邻支持帧进行对齐和融合,然后将结果和原来对齐之后的进行融合,然后送进特征校正模块去refine;此外Propagation这种方式容易长序列输入方式容易不断堆积误差,特别是对齐误差,因此会对一些细节区域造成很大影响,而Information-refill会去校正这一问题。IconVSR基于这两个提升点,超越了BasicVSR的性能,但是由于额外的特征提取模块使得IconVSR的模型参数会增加一些,但从Figure 1来看,模型量的增加还可以接受。
Note:
- 在BasicVSR中,光流估计是利用SpyNet做的。
- 在IconVSR中,额外的特征提取模块是利用一个轻量级的EDVR去做的。
2 Related Work
略
3 Methodology
3.1 BasicVSR
接下来我们具体分析BasicVSR的4个子网络的结构及其功能,首先总的模型如下所示:
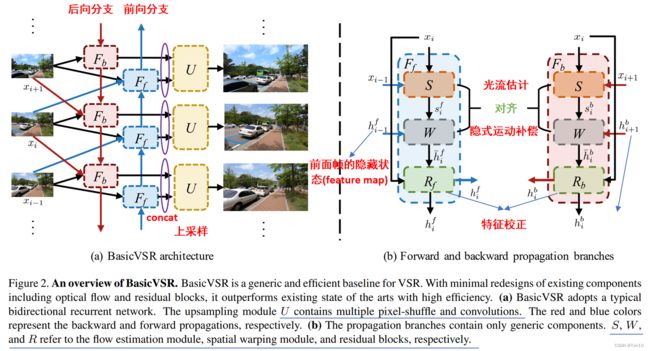
①Propagation
BasicVSR的Propagation采用双向循环机制(bidirectional),即前向分支后后向分支;而我们之前接触的例如VESPCN、TDAN、Robust-LTD、EDVR等都是每次输入一个时间窗口(比如连续5帧),这种Propagation称之为local,也就是说网络每次考虑的是一个长视频序列的局部信息。此外,FRVSR、RSDN属于另一个分支,即单向循环分支(unidirectional)。接下来我们具体分析下这3种Propagation的优点和缺点,并推出BasicVSR的做法:
-
Local:Local属于sliding-window方法,每个样本含有 D D D帧,其中 D D D是时间窗口(尺度)的大小。这种方式虽然简单,但是每次只考虑整个序列的局部信息,对于较远的输入信息是无法获取的。在我们的认知中,虽然离参考帧越近的信息越有用,所以Local类方法都只考虑邻近的支持帧,但是其实较远的帧也能提供有用的信息,甚至窗口的帧信息也不是都有用的,有的还会影响重建。因此显然Local这种Propagation考虑不全面的缺陷会限制其在VSR表现力的提升。为了证明这一点,作者做了一个实验,将一个长输入序列分为 K K K段,其中 K = 1 K=1 K=1的时候就是一整个输入序列,即Global Propagation,实验结果如下: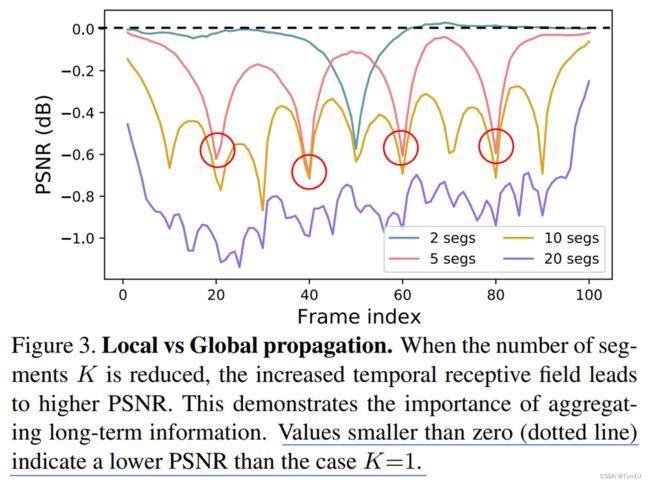
从实验中可知:①分段 K K K越小对表现力的提升越大,说明了越大的时间感受野越有利于视频超分,即较远的帧信息也很重要,不能像Local那样去忽略他们。②分段之后序列的首端和尾端出的表现力会下降比较厉害且时间窗口越小,下降的次数越多,这说明了采用一个较长序列作为输入还是有必要的。 -
Unidirectional:解决Local的一个方式就是使用从视频序列头到尾作为输入的方式,但这样也有个问题就是对于不同帧来说是不公平的。具体而言,对于首端的帧来说,其可以利用的特征信息只有它自己,而末端的帧可利用的是整个序列的所有信息。这种信息的不平衡带来的最大问题就是,早期的视频帧会陷入局部最优。为了验证这一点,作者做了相关的实验,实验结果如下: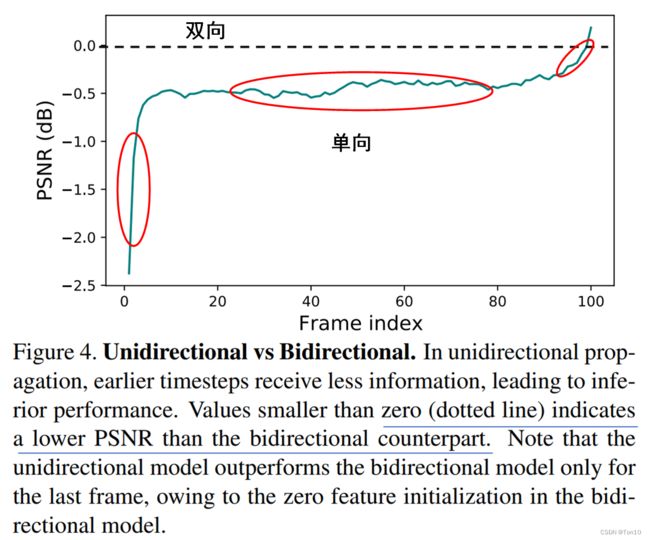
从实验结果中可知:①序列前端的重建效果比较差,后期的倒是和双向的差不多,这就体现了单向的缺陷。②中间段一直处于比双向(虚线)低了近0.5dB,这说明无法利用较后的信息会限制VSR的表现性能。 -
Bidirectional:Local的考虑不全面问题和单向的不平衡问题都可以使用一个双向机制来解决,BasicVSR设计了一个前向分支,让输入从头帧到尾帧不断进行VSR;后向分支,让输入从尾帧到头帧不断进行VSR。具体的,对于每一个参考帧 x i x_i xi,其前邻帧 x i − 1 x_{i-1} xi−1、后邻帧 x i + 1 x_{i+1} xi+1,以及2个邻帧各自相关的隐藏状态(双向机制利用RNN的存储结构,将之前或之后的信息记忆在隐藏状态 h h h中)。双向循环结构如下所示: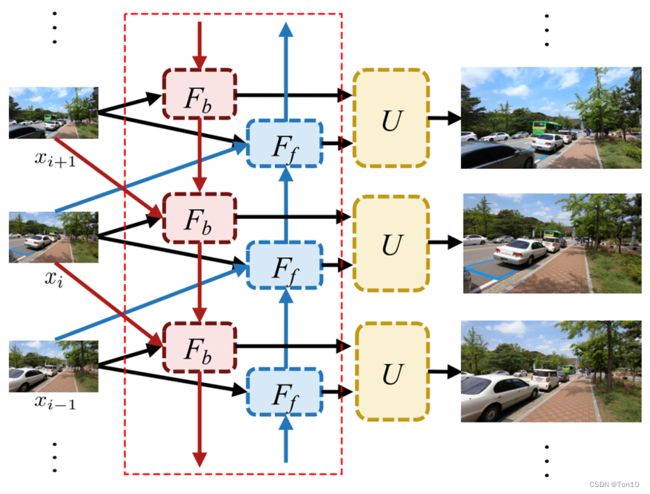
具体表达式为: h i b = F b ( x i , x i + 1 , h i + 1 b ) , h i f = F f ( x i , x i − 1 , h i − 1 f ) . (1) h_i^b = F_b(x_i, x_{i+1}, {\color{mediumorchid}h_{i+1}^b}),\\h_i^f = F_f(x_i,x_{i-1},{\color{teal} h^f_{i-1}}).\tag{1} hib=Fb(xi,xi+1,hi+1b),hif=Ff(xi,xi−1,hi−1f).(1)其中算子 F b ( ⋅ ) 、 F f ( ⋅ ) F_b(\cdot)、F_f(\cdot) Fb(⋅)、Ff(⋅)分别表示为BasicVSR的后向传播分支和前向传播分支; h i f 、 h i b h_i^f、h_i^b hif、hib表示输出的feature map,他们有2个出口,一个是分别作为各自下一参考帧的前向隐藏状态和后向隐藏状态,另一个是直接输出到Aggregation和Upsampling中去重建。
②Alignment
对齐主要分为3种:无对齐、图像对齐(image-wise)、特征对齐(feature-wise)。常见的图像级对齐有VESPCN、Robust-LTD等;特征级对齐是一种隐式对齐的方式,其对齐发生在feature map上,它通过隐式捕捉运动来完成隐式的运动补偿,常见的比如TDAN、EDVR等。接下来我们具体分析这三种方式的优缺点,并提出BasicVSR的做法:
Without alignment:RSDN采用的就是一种非对齐的方式,非对齐的方式由于节省了对齐模块,故在效率和资源消耗上会少很多。但是相比对齐,非对齐是一定会弱化最终VSR的表现力的。为了验证非对其的次优性,作者将BasicVSR的对齐模块删去,直接将非对其特征进行concat然后重建,由于BasicVSR的卷积核一般比较小,故非对齐下的PSNR下降了1.19dB,因此非对齐下想要通过更好的融合信息,需要加大感受野,增加卷积的采样范围。Image alignment:对齐方式中分为图像级对齐和特征对齐,判断的关键就是warp发生在图像上还是feature map上,或者说最后输出的是对齐的图像还是对齐的feature map。大多flow-based对齐方式都是image-wise的,例如VESPCN、Robust-LTD等,但是Understanding Deformable Alignment in Video Super-Resolution这篇文章证明了feature-wise对齐比image-wise对齐能产生更大的性能提升。这其实起源于Image-wise对齐高度依赖于运动(光流)估计的准确性,较低的精度会导致输出对齐图像上出现很多artifacts,比如模糊重影等,为后续融合SR带来性能的下降。作者做了相关实验,基于image对齐在PSNR上下降了0.17dB,这也这个证明了将对齐坐在feature-wise的重要性。Feature alignment:特征对齐的VSR有诸如TDAN、EDVR等,他们都是flow-free方法,而BasicVSR的对齐模块基于flow-based,但是对齐做在feature map上,即对feature做warp,而不是warp在Image上。其实做在feature map上的另一个好处在于对齐的feature map虽然也会因为隐式的运动补偿出现特征上的artifacts,但它可以继续通过卷积进行校正,减缓后续图像层级上artifacts的出现。在BasicVSR中,两个双向分支中都要做对齐,其包括光流估计和特征级上的warp两个过程,此外还设置让对齐之后特征图进入特征校正模块进行refine,BasicVSR中采用了残差块堆积的形式,而TDAN中的refine采用了简单的卷积层,具体对齐框架结构如下: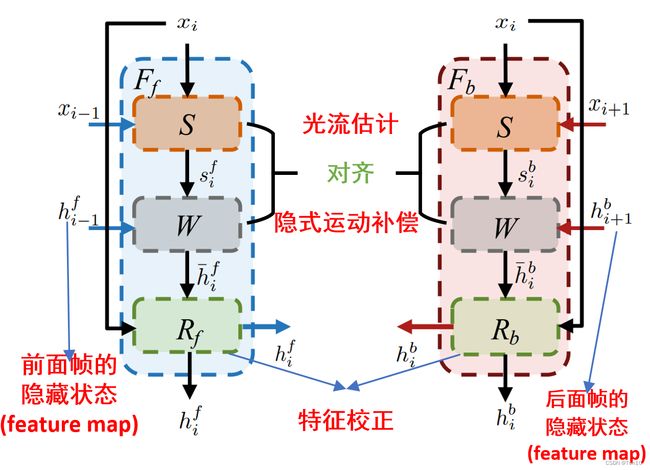 数学表达式为: s i { b , f } = S ( x i , x i ± 1 ) , h ˉ i { b , f } = W ( h i ± 1 { b , f } , s i { b , f } ) , h i { b , f } = R { b , f } ( x i , h ˉ i { b , f } ) . (2) s_i^{\{b,f\}} = S(x_i,x_{i\pm1}),\\\bar{h}^{\{b,f\}}_i=W(h_{i\pm 1}^{\{b,f\}},s_i^{\{b,f\}}),\\h_i^{\{b,f\}}=R_{\{b,f\}}(x_i,\bar{h}^{\{b,f\}}_i).\tag{2} si{b,f}=S(xi,xi±1),hˉi{b,f}=W(hi±1{b,f},si{b,f}),hi{b,f}=R{b,f}(xi,hˉi{b,f}).(2)其中算子 S ( ⋅ ) 、 W ( ⋅ ) 、 R ( ⋅ ) S(\cdot)、W(\cdot)、R(\cdot) S(⋅)、W(⋅)、R(⋅)分表表示光流估计、Warp、特征校正模块。此外,我们用表达式 F { b , f } = R { b , f } ∘ W ∘ S F_{\{b,f\}}=R_{\{b,f\}}\circ W\circ S F{b,f}=R{b,f}∘W∘S来表示双向分支和内部对齐的关系; h ˉ i { b , f } \bar{h}^{\{b,f\}}_i hˉi{b,f}表示和输入 x i x_i xi特征对齐的feature map。
数学表达式为: s i { b , f } = S ( x i , x i ± 1 ) , h ˉ i { b , f } = W ( h i ± 1 { b , f } , s i { b , f } ) , h i { b , f } = R { b , f } ( x i , h ˉ i { b , f } ) . (2) s_i^{\{b,f\}} = S(x_i,x_{i\pm1}),\\\bar{h}^{\{b,f\}}_i=W(h_{i\pm 1}^{\{b,f\}},s_i^{\{b,f\}}),\\h_i^{\{b,f\}}=R_{\{b,f\}}(x_i,\bar{h}^{\{b,f\}}_i).\tag{2} si{b,f}=S(xi,xi±1),hˉi{b,f}=W(hi±1{b,f},si{b,f}),hi{b,f}=R{b,f}(xi,hˉi{b,f}).(2)其中算子 S ( ⋅ ) 、 W ( ⋅ ) 、 R ( ⋅ ) S(\cdot)、W(\cdot)、R(\cdot) S(⋅)、W(⋅)、R(⋅)分表表示光流估计、Warp、特征校正模块。此外,我们用表达式 F { b , f } = R { b , f } ∘ W ∘ S F_{\{b,f\}}=R_{\{b,f\}}\circ W\circ S F{b,f}=R{b,f}∘W∘S来表示双向分支和内部对齐的关系; h ˉ i { b , f } \bar{h}^{\{b,f\}}_i hˉi{b,f}表示和输入 x i x_i xi特征对齐的feature map。
Note:
-
光流估计模块 S ( ⋅ ) S(\cdot) S(⋅)是使用SPyNet做的。
-
特征校正之后的输出feature map,它将接下来输送到aggregation和upsampling进行超分重建。在TDAN里面,如下图所示:
 它这里的卷积层是用来将对齐特征重建成对齐帧,当然也起到了特征校正的效果。
它这里的卷积层是用来将对齐特征重建成对齐帧,当然也起到了特征校正的效果。 -
Warp在变换网络,入STN、DCN中一般指代重采样过程,VSR利用warp产生对齐版本的支持帧,也可以看成是运动补偿的结果,是支持帧的估计值。
-
隐式的含义就是warp是直接发生在feature map上的(或者说隐式的捕捉运动信息),他一般还需要通过卷积等操作才能将变换显示在图像级上,是一种间接的方法,而不是直接在Image上进行变形。
-
关于深度学习中feature map的定义:
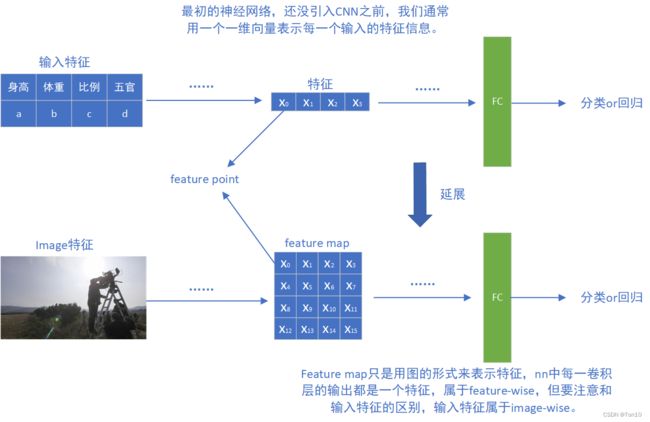
③Aggregation
融合部分和上采样部分其实都属于SR重建部分,我们通常使用SISR网络来做,只不过多了个时间融合来提取时间冗余信息,一般流程都是先融合提取特征信息,然后上采样重建过程。BasicVSR没有对这部分做出创新,只是简单的concat,即做early fusion。数学表达式为:
F f u s i o n = [ x i , h i f , h i b ] . F_{fusion} = [x_i, h_i^f,h_i^b]. Ffusion=[xi,hif,hib].其中 [ ⋅ ] [\cdot] [⋅]表示concat;输入是两个分支各自经过refine之后的对齐feature map。
④Upsampling
BasicVSR使用ESPCN提出的亚像素卷积来上采样,其中上采样模块中在PixelShuffle之前还有多层的卷积,这部分其实就是提取特征的过程,具体结构框图如下:
数学表达式为:
y i = U ( F f u s i o n ) . (3) y_i = U(F_{fusion}).\tag{3} yi=U(Ffusion).(3)其中算子 U ( ⋅ ) U(\cdot) U(⋅)表示上采样模块,其包括多个卷积层提取特征以及一个亚像素卷积层来上采样;输入是两个分支各自的对齐feature map融合的结果,输出是高分辨率的 H R HR HR图像。需要注意的是,虽然图上花了一堆的输出,但其实每次输出的只是对当前参考帧 x i L R x_i^{LR} xiLR对应的 y i H R y_i^{HR} yiHR,也就是说和其他VSR一样,每次只输出一张Image。
小结一下:
- BasicVSR使用双向循环机制来传播所有帧的信息。
- 使用flow-based对齐但是基于feature-wise,并使用特征校正来减缓特征上的artifacts。
- 融合使用简单的concat。
- 上采样使用PixelShuffle。
通过创新的Propagation和Alignments,以及现存的一些Aggregation和Upsampling方法,BasicVSR最终形成了一个简单轻量的模型,在速度和表现力上都很出色,最重要的是,我们可以以它为基础,网上增加一些功能来进化BasicVSR,为了演示这种进化,作者又提出了BasicVSR的升级版本——IconVSR,接下来我们就介绍这一新结构。
3.2 From BasicVSR to IconVSR

①:BasicVSR的Propagation带来了全局信息的输入,但是这种长距离循环传播的机制会让对齐部分的误差进行累积,从而会导致一些图片上的细节部分无法很好的恢复出来,为了解决误差累积的问题,IconVSR推出了Information-refill来填充弥补因为对齐误差导致的一些细节的损失。
②:此外,在很多情景中都会有遮挡现象,就比如说一辆车经过一棵树,假设现在有3帧,第一帧汽车遮挡住了树,第二帧汽车刚好离开树,第三帧汽车远离树,具体场景如下:

那么当你想要重建第二帧的时候,由于之前的帧没有树的信息,因此第二帧的重建就会很困难,而如果此时后向传播的信息能够加入进来,就可以恢复出这棵树的细节信息,这就是IconVSR针对BasicVSR做出的第二点改进,引入耦合传播(Coupled propagation)机制,在前向分支上加入后向分支对齐的信息。
接下来我们分别介绍IconVSR基于BasicVSR的两个创新点。
①Information-refill
在长距离的propagation上是很容易产生对齐误差的积累,首先对齐本身就是有误差的,是做不到完全精确的,其次特别是当遮挡、边界、多细节位置在对齐的时候更容易产生错误的对齐。遮挡是因为对于走出遮挡之后的帧是无法将其一帧的信息和当前帧对齐;边界是因为,前一帧或后一帧没有和图像边界相关的信息;多细节区域会由于不断累积的误差导致其能恢复出来的细节遭到了限制。
为了解决这三种场景的问题,作者对于Aggregation处引入Information-refill来进行解决。具体地,通过在对齐之后,特征校正之前引入一个额外的特征提取模块,如果当前参考帧在关键帧集合内,那么由关键帧及其相邻2个支持帧组成该模块的输入。该特征提取模块是用较轻量的EDVR来做的,因此其特征提取的结果其实就是EDVR将这3帧当成输入,最后输出这三帧经过PCD和TSA之后的融合结果 e i e_i ei。然后将 e i e_i ei和2个分支各自本身对齐的结果相融合,并通过卷积之后输出到特征校正中去。具体结构如下:
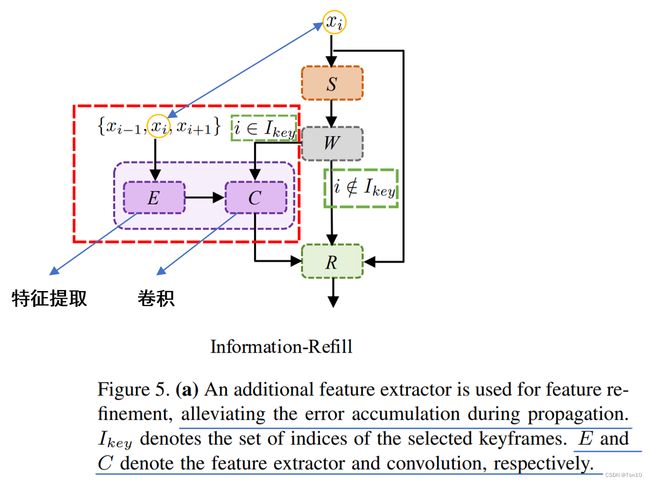
具体数学表达式为:
e i = E ( x i − 1 , x i , x i + 1 ) , h ^ i { b , f } = { C ( e i , h ˉ i { b , f } ) i f i ∈ I k e y , h ˉ i { b , f } o t h e r w i s e . (4) e_i = E(x_{i-1}, x_i, x_{i+1}),\\ \hat{h}_i^{\{b,f\}}= \begin{cases} C(e_i,\bar{h}_i^{\{b,f\}})\;\; if \;i\in I_{key},\\ \bar{h}_i^{\{b,f\}}\;\;\;\;\;\;\;\;\;\;\;\;otherwise. \end{cases}\tag{4} ei=E(xi−1,xi,xi+1),h^i{b,f}={C(ei,hˉi{b,f})ifi∈Ikey,hˉi{b,f}otherwise.(4)其中 E ( ⋅ ) 、 C ( ⋅ ) E(\cdot)、C(\cdot) E(⋅)、C(⋅)分别为特征提取模块和卷积运算; I k e y I_{key} Ikey表示参考帧集合中的参考帧序号; h ^ i { b , f } \hat{h}_i^{\{b,f\}} h^i{b,f}表示information-refill之后的结果。
Note:
- 之所于特征提取基于关键帧,是因为关键帧其在视频序列中相较其他帧具有更多的特征信息,更具代表性。在IconVSR中关键帧是通过每隔5帧选取一个关键帧,即 i n t e r v a l s = 5 intervals=5 intervals=5。此外 i ∈ I k e y i\in I_{key} i∈Ikey这种条件设置会让额外的特征提取间接性的实行,故当 i n t e r v a l s intervals intervals相对较大的时候,不会带来太大的计算复杂度。
- Information-refill在前向分支和后向分支都是存在的。
接下来将Information-refill之后的结果输送到特征校正模块中:
h i { b , f } = R { b , f } ( x i , h ^ i { b , f } ) . (5) h_i^{\{b,f\}} = R_{\{b,f\}}(x_i, {\color{cornflowerblue}\hat{h}_i^{\{b,f\}}}).\tag{5} hi{b,f}=R{b,f}(xi,h^i{b,f}).(5)
现在我们就可以分析Information-refill在遮挡、边界、多细节情景中减缓对齐误差的作用(假设 x i x_i xi刚好是关键帧):
- 在遮挡情况下,拿上述车挡树的例子来说,由于新增的特征提取块经过对齐融合,会额外包含后一帧 x i + 1 x_{i+1} xi+1的特征信息(这就好像填充了额外的信息),那么这时候将它和原有的对齐结果进行融合之后,那么这个前向分支最终产生的对齐特征 h i { b , f } h_i^{\{b,f\}} hi{b,f}就能和 x i x_i xi的特征有很好的对齐,缓解了BasicVSR中因为遮挡而产生很差的对齐效果;而后向分支中没有遮挡,所以其本身产生的对齐feature和 x i x_i xi的特征就会有很好的对齐。之后经过融合上采样之后就能产生不错的SR重建效果。
- 在边界情景下也是一样的道理,视频中不同帧的边界一定是在不断变化的,当前帧在边界出的东西,下一帧的边界上这个东西可能就不存在了,因此对齐就会很难。但是前一帧中一定是存在这个物体的,故在后向分支中,通过额外的特征提取模块,我们就可以额外获取前一帧的特征信息,这个额外的特征信息就可以弥补上后向分支在 x i + 1 x_{i+1} xi+1特征的对齐上缺省的边界特征。
- 至于在多细节特征上,这很大程度取决于长距离的propagation带来的对齐误差累积,那么额外的特征提取模块也可以作为一种精细化对齐的手段,可以看出特征提取模块的时间感受野(时间窗口)较小,比如作者使用EDVR这种Local的方法,它更强调局部信息,因此他会对于多细节块这种局部区域的对齐起到降低对齐损失的作用。
②Coupled-propagation
在BasicVSR中,2个分支其实是互相独立的,在对齐上是各做各的,只是最后在融合阶段才凑到一起。这样如果各自在对齐上出现问题,那么当后续aggregation的时候就会提取到错误的特征从而降低重建的表现力,尤其是在遮挡问题上,光一个分支独立去做对齐那肯定是要出问题的,这和information-refill对遮挡问题的处理有相似的理由。通过新增的Coupled Propagation模块,我们就可以在前向分支的对齐中加入未来帧的对齐信息,从而建立起2个分支的联系。Coupled Propagation的结构如下图:
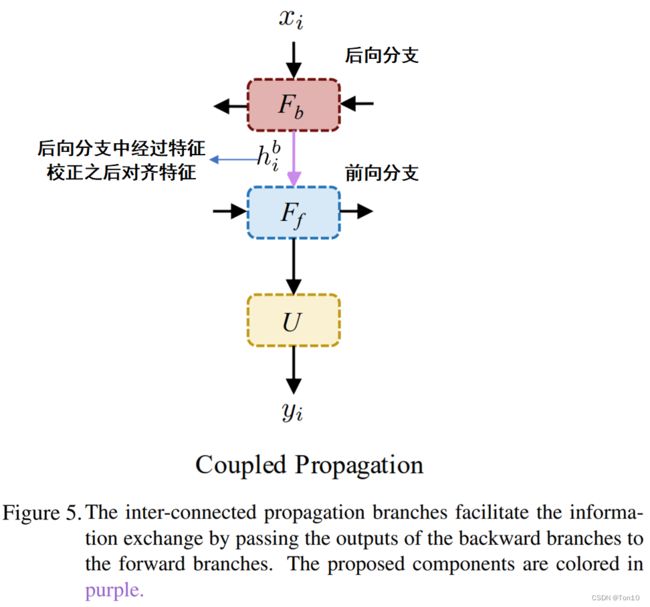
数学表达式如下:
h i b = F b ( x i , x i + 1 , h i + 1 b ) , h i f = F f ( x i , x i − 1 , h i b , h i − 1 f ) , y i = U ( h i f ) . (6) h_i^b = F_b(x_i,x_{i+1},h^b_{i+1}),\\ h_i^f = F_f (x_i, x_{i-1}, {\color{cornflowerblue}h_i^b}, h_{i-1}^f),\\ y_i = U(h_i^f).\tag{6} hib=Fb(xi,xi+1,hi+1b),hif=Ff(xi,xi−1,hib,hi−1f),yi=U(hif).(6)Note:
-
Coupled机制仅仅只是修改了下 h i b h_i^b hib输出的方向,因此对于模型复杂度的增加是很微小的。此外,上采样模块的输入只来自于前向分支的输出,而不需要后向分支的输出,这也是和BasicVSR区别的一个地方。
-
BasicVSR和IconVSR参数的主要变动在Information-refill中,两者的参数对比如下:

-
可能这时候你会有疑问,BasicVSR不是本身也有后向传播么,之后2个分支融合不是也能将前后传播信息相互结合,难道不能给给上面车挡树视频中间这一帧进行很好的重建嘛?
注意这种方式将后向的信息加入到前向的对齐操作中,所以在重建的时候,对于遮挡的物体可以根据后向信息预测出来相关细节。而BasicVSR前向和后向都是独立预测的,虽然两者都利用了前面和后面的信息,但是每一个分支在对齐的时候,是各做各的,前向分支在对齐的时候,因为没有树的信息,所以很难对齐,这时候如果有后向对齐的信息,就可以借用来做对齐。在BasicVSR中,最后第二帧中树干部分的重建其实只有后向分支的对齐是有意义的,前向由于遮挡,所以其对齐是很难的,经过之后的融合会产生不太好的效果。而IconVSR的改进使得前向也能完成很好的对齐,这样的话第二帧的重建就会有2个不错的对齐一起合力帮助后续融合超分重建出好的表现。
4 Experiments
训练集:REDS、Vimeo-90K
验证集:REDS本身的30个视频,再额外从训练集中抠出4个,记为REDSval4
测试集:Vid4、UDM100、Vimeo-90K-T
实验设置:
- 使用BI和BD两种降采样方式, r = 4 r=4 r=4。
- 使用SPyNet做光流估计(简单而高效),使用EDVR-M(轻量的EDVR)做information-refill中额外的特征提取。两个网络提前经过预训练。
- 使用Adam优化,并额外使用余弦退火。
- 关于学习率的初始化设置:EDVR-M设置为 1 × 1 0 − 4 1\times 10^{-4} 1×10−4;SPyNet设置为 2.5 × 1 0 − 5 2.5\times 10^{-5} 2.5×10−5;其余均为 2 × 1 0 − 4 2\times 10^{-4} 2×10−4。
- 训练一共30W个iterations,前5000个iterations中,SPyNet和EDVR-M的参数都保持不变。
- Batch为8;patch设置为 64 × 64 64\times 64 64×64。
- 每个分支中的特征校正都是用通道数为64的残差块,设置为30个。
- 参考帧的选取间隔为5。
当在REDS上训练时,我们控制序列为15帧;而在Vimeo-90K中,由于每个视频才7帧,故通过翻转增强之后形成14帧作为一个样本。而在测试阶段,我们的输入为所有的帧,比如REDS上就是500帧,Vimeo-90K上就是7帧。
训练损失Loss函数我们采用Charbonnier损失,它比 L 2 L2 L2损失更能提升表现力:
L = 1 N ∑ i = 0 N ρ ( y i − z i ) . (7) \mathcal{L} = \frac{1}{N}\sum_{i=0}^N\rho(y_i - z_i).\tag{7} L=N1i=0∑Nρ(yi−zi).(7)其中 ρ ( x ) = x 2 + ϵ 2 , ϵ = 1 × 1 0 − 8 \rho(x) = \sqrt{x^2+\epsilon^2},\epsilon=1\times 10^{-8} ρ(x)=x2+ϵ2,ϵ=1×10−8; z i z_i zi是Ground Truth; N N N是batch中的序列个数。
4.1 Comparisons with State-of-the-Art Methods
本节主要是BasicVSR、IconVSR和其余VSR的对比,实验结果如下:
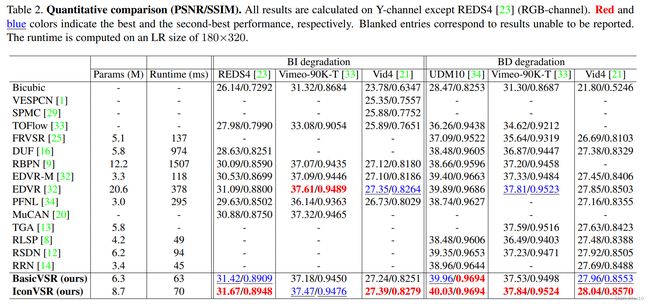
可视化结果如下:
实验结论:
- 总的来说,BasicVSR和IconVSR在表现力上超越了之前的SOTA视频超分类方法。
5 Ablation Studies
本节开始探究IconVSR的2个创新点的功能以及对IconVSR中间隔intervals的讨论。
5.1 From BasicVSR to IconVSR
①首先研究Information-refill对VSR最终性能的影响:
 如上图所示探究的是Information-refill对图像边界的影响:图像边界在在各个分支中很难实现对齐,因为视频中边界物体可能在下一帧就没有了,所以这部分边界信息无法通过warp来获取相关像素值,一旦对齐出错,那么后续的融合超分过程就会出现表现力下降。因此如果想要实现后向分支的 x i + 1 x_{i+1} xi+1特征和 x i x_i xi特征的对齐,那么势必要在后向分支中利用额外的特征提取模块去引入前一帧 x i − 1 x_{i-1} xi−1的特征信息,从而弥补上BasicVSR中对齐 x i + 1 x_{i+1} xi+1特征在边界上的缺陷。这一点从上图也得到了验证。增加了Information-fill之后,图像的边界就成功的重建了出来。
如上图所示探究的是Information-refill对图像边界的影响:图像边界在在各个分支中很难实现对齐,因为视频中边界物体可能在下一帧就没有了,所以这部分边界信息无法通过warp来获取相关像素值,一旦对齐出错,那么后续的融合超分过程就会出现表现力下降。因此如果想要实现后向分支的 x i + 1 x_{i+1} xi+1特征和 x i x_i xi特征的对齐,那么势必要在后向分支中利用额外的特征提取模块去引入前一帧 x i − 1 x_{i-1} xi−1的特征信息,从而弥补上BasicVSR中对齐 x i + 1 x_{i+1} xi+1特征在边界上的缺陷。这一点从上图也得到了验证。增加了Information-fill之后,图像的边界就成功的重建了出来。
此外,Information-refill在多细节区域中,可以利用额外的特征提取块的局部传播特性(Local)来进一步优化区域上的对齐,从而缓解了长序列下对齐误差的堆积影响。实验结果如下:

②其次研究Coupled-Propagation对VSR最终性能的影响:
耦合传播机制对于遮挡情景是最适用了,实验结果如下所示:

黄色区域是在之前的帧中是被遮挡的,那么遮挡区域刚露出来的时候,BasicVSR的前向分支很难将 x i − 1 x_{i-1} xi−1的特征对齐到 x i x_{i} xi的特征上去,因为 x i − 1 x_{i-1} xi−1没有遮挡部分的信息,通过warp是无法对齐到当前参考帧上去的。IconVSR通过利用后向分支的特征信息输出的 x i + 1 x_{i+1} xi+1的对齐特征 h i b h_i^b hib来作为前向分支的输入,有了后面帧的特征信息,则前向分支在对齐的时候就可以预测出遮挡区域的信息,从而完成较好的对齐,这对于后续的融合SR重建的表现力都是有提升作用的。
额外的实验结果如下:
小结一下:
- 在遮挡问题上,Information-refill和Coupled-Propagation对遮挡区域的对齐使用类似的处理方法,即借助未来帧的特征信息。
- 在边界问题上,Information-refill和遮挡情形相反,它借助之前帧的特征信息。
5.2 Tradeoff in IconVSR
接下来作者探究的是关键帧个数对IconVSR重建性能和速度的影响,实验结果如下:

实验结论如下:
- 显然,参考帧越多,Information-refill的使用次数越频繁,那么所造成的训练时间就会越多,但是也带来了表现力的提升。
- 当参考帧的个数为0时,IconVSR的性能仍然要比BasicVSR要高出0.21dB,从这里也反映出了Coupled-Propagation对VSR表现力的提升作用。
6 Conclusion
- 在本文中,作者将VSR分为Propagation、Alignment、Aggregation、Upsampling四部分。通过结合一个双向循环传播机制的结构、基于光流的feature-wise的对齐方法,以及结合一般的融合和上采样方式,最终设计出一个轻量级的、同时具备高表现性能的VSR方法——
BasicVSR。 - BasicVSR最大的价值在于它可以作为今后研究VSR的baseline,作者演示了如何去基于BasicVSR来设计出一个改进版本的VSR方法,这就是
IconVSR。 - 为了解决BasicVSR中因为遮挡、边界等问题造成的对齐误差问题,以及长范围的propagation产生的误差累积问题,IconVSR引入Information-refill机制;为了让每一帧的特征对齐都能利用过去和未来的特征信息,IconVSR引入Coupled-Propagation机制,通过引入这两项创新,IconVSR在略微增加模型复杂度的基础上,在表现力上超越了BasicVSR。