MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image阅读笔记
本文是2022CVPR的一篇文章,主要讲述的是一种基于单目图像移动友好手部网格重建,整体流程主要包含三个部分2D编码,2D到3D映射,3D解码。其中还涉及到轻量化的问题。
摘要部分介绍了本文提出的手部网格重建方法的大致内容。第一部分介绍,主要讲述了单视图手网重建的典型流程,时间相干性,以及本文的主要工作内容。第二部分相关工作,主要讲述了手部网格估计,轻量级网络,时间一致性的人体重建,像素对齐表示的流行方法以及本文采用的方法。第三部分我们的方法,主要讲述了本文是怎么重建手部网格的,包括堆叠编码网络,特征提升模块,深度可分离螺旋卷积以及损失函数。第四部分经验,主要讲述了实现细节,评价标准,模块消融实验。第五部分总结与展望。
摘要:本文提出了一种基于单目图像移动友好手部网格重建,该框架可以同时实现高重建精度、快速推断速度和时间相干性(连续帧之间的平滑变化)。具体实现上,对于2D编码,我们使用轻量级但有效的堆叠结构。对于三维解码,我们提供了一种高效的图算子,即深度可分螺旋卷积。此外,我们还提出了一种新的特征提升模块,用于弥合2D和3D表示之间的差距。本模块从基于图的位置回归(MapReg)块开始,集成热图编码和位置回归范式的优点,以提高2D精度和时间相干性。此外,MapReg之后是位姿池化和位姿到顶点提升方法,它们将2D位姿编码转换为3D顶点的语义特征。总的来说,我们的手部重建框架,称为MobRecon,包含了合理的计算成本和微型模型尺寸,在Apple A14 CPU上达到了83FPS的高推断速度。在FreiHAND、RHD和HO3Dv2等流行数据集上的大量实验表明,我们的MobRecon在重建精度和时间相干性方面取得了优异的性能。
1.介绍
单视图手网重建技术被广泛研究。现有的典型方法主要关注的是重建精度,而实际应用还需要推理效率和时间一致性。移动设备包含有限的内存和计算预算,本工作旨在探索移动平台的三维手部重建。
单视图手部重建的典型流程包括三个阶段:2D编码、2D-to-3D映射和3D解码。在二维编码中,现有的方法通常采用计算密集型网络来处理这种高度非线性的任务,这很难部署在移动设备上。相反,如果天真地利用一个成熟的移动网络,它不是为我们的目标任务量身定制的,重建精度会大大降低。因此,我们开发一种轻量级的2D编码结构,以平衡推理效率和准确性。此外,2D-to-3D映射和3D解码的效率还相对未被探索。因此,我们打算探索一种轻量级而有效的提升方法来解决2D到3D的映射问题,并设计一个高效的图形算子来处理3D网格数据。
尽管在实际应用中,时间相干性与精度一样重要,但在三维手部重建中,时间相干性往往被忽略。以往的方法采用顺序模型,同时考虑过去和未来用于稳定预测的语义信息。由于这种方法是离线的或计算昂贵的,这些方法很难用于移动应用程序。因此,我们受到启发,用非顺序的方法来探索时间相干性。在这项工作中,我们提出了用于3D手的移动网格重建(MobRecon),以同时探索卓越的准确性、效率和时间相干性。对于2D编码,我们利用沙漏网络的精神来设计有效的堆叠编码结构。在三维解码方面,我们提出了深度可分离螺旋卷积(DSConv),这是一种基于螺旋采样的新型图算子。DSConv的灵感来自深度可分离卷积,导致有效处理图结构的网格数据。对于2D-to-3D映射,我们提出了一个具有基于地图的位置回归(MapReg)、位姿池化和位姿到顶点提升(PVL)方法的特征提升模块。在本模块中,我们首先研究了基于热图和位置回归的二维姿态表示的优缺点,然后提出了一种混合方法MapReg,以同时提高二维姿态的精度和时间一致性。此外,PVL基于可学习的提升矩阵将2D姿态编码转换为3D顶点特征,从而提高了3D精度和时间一致性。与传统的基于潜空间全连通操作的方法相比,我们的特征提升模块也显著减小了模型尺寸。此外,我们建立了一个具有均匀分布的手姿态和视点的合成数据集。参考图1,我们在精度、速度和模型大小方面取得了更好的性能。

主要工作内容如下:
•我们提出了MobRecon作为一种移动友好的手工网格重建管道,它只涉及1.23亿个乘法-添加操作(multi - added)和5M个参数,在Apple A14 CPU上可以运行高达83FPS。
•我们提出了轻量级堆叠结构和DSConv,用于高效的2D编码和3D解码。
•我们提出了一个新的特征提升模块,使用MapReg、姿态池化和PVL方法来桥接2D和3D表示。
•通过与最先进的方法进行综合评估和比较,我们证明了我们的方法在模型效率、重建精度和时间一致性方面取得了优异的性能。
2.相关工作
手部网格估计。目前流行的手网估计方法可分为五种,其核心思想分别是基于参数模型、体素表示、隐式函数、UV映射和顶点位置。
基于模型的方法通常使用MANO作为参数模型,它将手网格分解为形状和姿态系数。然而,这不适合用于轻量级网络,因为系数估计是一个高度抽象的问题,忽略了空间相关性。
基于体素的方法以2.5D的方式描述3D数据。Moon等提出了I2L-MeshNet,将体素空间划分为三个lixel空间,并使用1D热图来减少内存消耗。尽管进行了优化,I2L-MeshNet仍然需要占用大量内存来处理lixelstyle 2.5D热图。因此,基于体素的方法对于内存受限的移动设备并不友好。
隐函数具有连续性和高分辨率的优点,最近被用于关节人的数字化。然而,隐式方法通常需要计算数千个3D点,在移动设置中缺乏效率。
Chen等将手网重建作为一种图像到图像的转换任务,使用UV地图连接2D和3D空间。可以通过合并几何相关性来改进该方法。
基于顶点的方法直接预测3D顶点坐标,通常遵循2D编码、2D- 3D映射和3D解码的过程。例如,Kulon等设计了基于ResNet、全局池化和螺旋卷积(SpiralConv)的编码器解码器来获取3D顶点坐标。我们用高效的模块重新构建了基于顶点的方法,即用于2D编码的轻量级堆叠结构,用于2D-to-3D映射的特征提升模块,以及用于3D解码的DSConv。因此,我们获得了较高的重建精度和跨时间一致性。
轻量级网络,为了在计算量有限的平台上及时实现,轻量级网络已经研究了多年。我们利用流行的高效思想为欧几里得2D图像设计堆叠网络,并为非欧几里得3D网格设计图形网络。更具体地说,我们提出了一个特征提升模块来有效地处理2d到3d映射问题。作为一个高度相关的工作,MobileHand能够在移动CPU上以75FPS的速度运行。相比之下,我们的MobRecon在准确性和推理速度方面表现更强大。
时间一致性的人体重建。目前对人/手网格重建的时间相干性研究有限,但在实际应用中,时间相干性与重建精度一样重要。先前的研究主要集中在使用时间方法研究时间性能。Kocabas等人使用双向门控循环单元进行融合跨时间特征,使SMPL参数可以与时间线索回归。这种顺序的方式可能会增加计算成本,甚至需要未来的信息。相比之下,我们设计了一个MapReg特征提升模块来增强非顺序单视图方法的时间相干性。
像素对齐表示。卷积特征由密集和规则结构的2D线索组成,但稀疏和无序的点表示3D数据。为了更好地提取图像特征来描述3D信息,最近的作品通常采用像素对齐表示。受它们的启发,我们使用像素对齐的思想进行特征提升,并设计PVL将姿态对齐的编码转换为顶点特征。值得注意的是,上述文献使用了热图或位置作为二维表示。Li等对基于热图和基于位置的人体姿态进行了精度分析,并提出了RLE来实现高精度回归。我们从时间相干的角度考虑这两种表示,并提出MapReg来整合基于热图和基于位置的二维表示的优点。
3.我们的方法
以单视图图像为输入,我们的目标是用预测顶点![]() 和预定义人脸
和预定义人脸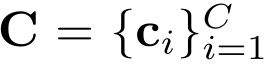 来推断三维手网格。图2展示了MobRecon的整体架构,包括三个阶段。对于2D编码,我们利用卷积网络提取图像特征。在特征提升模块中,使用MapReg描述二维姿态,然后使用姿态池来检索姿态对齐的特征。然后利用PVL得到顶点特征。对于三维解码,我们开发了一种有效的图网络来预测顶点坐标。
来推断三维手网格。图2展示了MobRecon的整体架构,包括三个阶段。对于2D编码,我们利用卷积网络提取图像特征。在特征提升模块中,使用MapReg描述二维姿态,然后使用姿态池来检索姿态对齐的特征。然后利用PVL得到顶点特征。对于三维解码,我们开发了一种有效的图网络来预测顶点坐标。
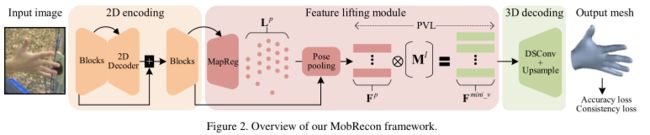
3.1堆叠编码网络
受沙漏网络的启发,我们开发了一个堆叠的编码网络,以获得逐渐细化的编码特征。如图3所示,堆叠网络由两组级联的编码块组成,第一组编码块后面是上采样模块用于特征融合。以单视图图像为输入,生成编码特征![]() ,其中C、H、W表示张量通道大小、高度和宽度。我们设计了两个备选块。根据DenseNet和SENet,我们提出了一个密集块来形成DenseStack(见图3)。为了进一步缩小模型尺寸,我们利用ghost操作来开发GhostStack,其中廉价的操作可以在主特征的基础上产生ghost特征。在128 × 128的输入分辨率下,DenseStack包含373.0M mult -加法和6.6M参数,而GhostStack包含96.2M mult -加法和5.0M参数。相比之下,ResNet18的堆叠网络有2391.3M个multi - added参数和25.2M个参数,不能用于移动应用。
,其中C、H、W表示张量通道大小、高度和宽度。我们设计了两个备选块。根据DenseNet和SENet,我们提出了一个密集块来形成DenseStack(见图3)。为了进一步缩小模型尺寸,我们利用ghost操作来开发GhostStack,其中廉价的操作可以在主特征的基础上产生ghost特征。在128 × 128的输入分辨率下,DenseStack包含373.0M mult -加法和6.6M参数,而GhostStack包含96.2M mult -加法和5.0M参数。相比之下,ResNet18的堆叠网络有2391.3M个multi - added参数和25.2M个参数,不能用于移动应用。

3.2特征提升模块
提升是指2D-to-3D映射。对于特征提升,需要考虑两个问题:(1)如何收集二维特征,(2)如何将二维特征映射到三维域。为此,以往的方法倾向于通过全局平均池化操作将编码特征嵌入为潜在向量。然后,利用全连通层(FC)将潜在向量映射到三维域,通过向量重排得到顶点特征;这种方式由于FC的尺寸较大,使得模型尺寸增大,即当通道大小256时,该层包含3.2M参数。最近的研究报道了基于二维标记点和像素对齐特征池的像素对齐特征提取。热图通常用于编码二维标志,与直接回归二维位置Lp相比,得到更准确的标志。
基于地图的位置回归。图4全面研究了这些2D表示。可以看出,热图是一个高分辨率的表示(图4(a))。如图4(b)所示,soft-argmax是一种可微技术,可以将热图解码到相应的2D位置。相比之下,直接位置回归(图4(c))是一种低分辨率的表示,它可以产生二维位置而无需求助于热图。事实证明,人体姿态估计任务需要低分辨率和高分辨率的编码。因此,融合特征的跳跃连接是热图卓越精度背后的主要原因。然而,我们的关键见解是,用于预测二维位置的全局特征(分辨率为1 × 1)(见图4(c))将由于全局语义和接受场而诱导更好的时间相干性。该全局性质能较好地描述手姿态的铰接关系。相反,热图是通过卷积和高分辨率特征来预测的,其中有限的接受野导致缺乏地标间约束。如图4(d)所示,我们提出了一种中分辨率方法MapReg,通过(1)融合低分辨率和高分辨率特征以获得准确性,(2)使用全局接受场来获得时间相干性,将热图和基于位置的范式的优点结合起来。为此,我们将跳跃连接纳入位置回归范式,生成空间小尺寸(例如16 × 16)的特征图。然后,每个特征通道被平铺成一个向量,然后由多层感知器(MLP神经网络)生成2D位置。通过这种方式,我们获得了优于热图的中分辨率空间复杂度,因为只涉及两次2×-upsampling操作(4倍上采样结构)。

姿态池化。在获得2D表示后,可以检索像素对齐的特征。我们称之为姿态池化过程,并捕获带有N个2D关节地标的姿态对齐特征。若采用热图作为二维表示,则采用联合池化(jointwise pooling)[74](图4(e))进行位姿池化,可表示为![]() 其中[·]表示连接。首先将热图的空间大小插值为
其中[·]表示连接。首先将热图的空间大小插值为![]() ,然后将插值后的热图与编码特征进行通道乘法。通过这种方式,与关节标志无关的特征被抑制。为了提取关节特征,设计了特征约简Ψ。详细地说,Ψ表示全局最大池化或空间和约简,它产生一个长度特征向量。拼接后,
,然后将插值后的热图与编码特征进行通道乘法。通过这种方式,与关节标志无关的特征被抑制。为了提取关节特征,设计了特征约简Ψ。详细地说,Ψ表示全局最大池化或空间和约简,它产生一个长度特征向量。拼接后,![]() 表示位姿对齐特征。如果我们用直接位置回归表示代替热图来描述二维姿态,通过网格采样(图4(f))可以实现姿态池化,
表示位姿对齐特征。如果我们用直接位置回归表示代替热图来描述二维姿态,通过网格采样(图4(f))可以实现姿态池化,![]() 。最终,将卷积编码转化为姿态对齐表示。
。最终,将卷积编码转化为姿态对齐表示。
姿势到顶点提升。我们设计了一个线性算子用于向三维空间进行特征映射,该算子具有一些可学习参数,即PVL。mano式手网由V个顶点和N个关节组成,其中V = 778, N = 21。因为V要比N高,所以很难将姿态对齐表示转换成V个顶点特征。相反,我们对模板网格进行4倍的2因子采样,并获得V mini = 49个顶点的最小尺寸手工网格。然后,我们设计了一个可学习提升矩阵![]() ,用于二维到三维的特征映射。因此,PVL为
,用于二维到三维的特征映射。因此,PVL为![]() 其中Fmini v表示最小尺寸顶点特征。PVL将特征映射的计算复杂度从
其中Fmini v表示最小尺寸顶点特征。PVL将特征映射的计算复杂度从![]() 降低到
降低到![]() 。
。
3.3深度可分离螺旋卷积
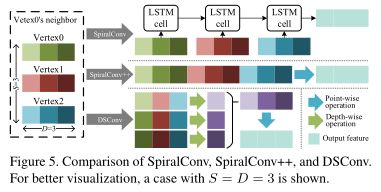
SpiralConv[44]作为一个图算子,等价于欧氏卷积,它设计了一个螺旋邻居为 其中N提取顶点v的邻域,使用k-disk(v), SpiralConv将卷积作为一个顺序问题,并利用LSTM[27]进行特征融合:
其中N提取顶点v的邻域,使用k-disk(v), SpiralConv将卷积作为一个顺序问题,并利用LSTM[27]进行特征融合:![]() 其中
其中![]() 表示v处维数为D的特征向量。由于串行序列处理,使用LSTM的SpiralConv可能会潜在地变慢。
表示v处维数为D的特征向量。由于串行序列处理,使用LSTM的SpiralConv可能会潜在地变慢。
通过显式地制定聚集相邻顶点的顺序,spiralconv++提供了一个有效的SpiralConv版本。为了提高效率,spiralconv++只采用了固定大小的S顶点螺旋邻居,并利用FC来融合这些特性:![]() 其中[·]表示串联;k-disk(v)S包含k-disk(v)中的前S个元素;W和b是可学习参数。由于FC的大尺寸,spiralconv++显著增加了模型的大小。
其中[·]表示串联;k-disk(v)S包含k-disk(v)中的前S个元素;W和b是可学习参数。由于FC的大尺寸,spiralconv++显著增加了模型的大小。
作为一种有效的图卷积,我们提出DSConv与深度可分离卷积[29]的精神。对于顶点v, k-disk(v)S按公式4采样。DSConv包括一个深度操作和一个点操作,前者可以表述为![]() 那么,逐点操作可以表述为
那么,逐点操作可以表述为![]()
图5说明了SpiralConv、spiralconv++和DSConv之间的区别。spiralconv++的计算复杂度服从![]() , DSConv的计算复杂度为
, DSConv的计算复杂度为![]() 。因此,我们从本质上提高了可分离结构的效率。3D解码器由四个模块组成,每个模块涉及上采样、DSConv和ReLU。在每个块中,顶点特征被上采样2倍,然后由DSConv处理。最后,通过DSConv预测顶点坐标V。
。因此,我们从本质上提高了可分离结构的效率。3D解码器由四个模块组成,每个模块涉及上采样、DSConv和ReLU。在每个块中,顶点特征被上采样2倍,然后由DSConv处理。最后,通过DSConv预测顶点坐标V。
3.4损失函数
精度损失。我们使用L1范数来表示三维网格损失Lmesh和二维位姿损失Lpose2D。根据,网格平滑度采用法向损耗Lnorm和边长损耗Ledge。正式意义上,我们有
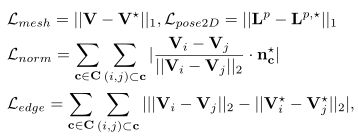
其中C、V为一个网格的面和点集;![]() 表示面单位法向量;
表示面单位法向量;![]() 表示真实数据。
表示真实数据。
一致性的损失。受自我监督任务的启发,我们设计了不需要时间数据的基于增强的一致性监督。即基于二维仿射变换和颜色抖动的图像样本可以衍生出两个视图。我们将两个视图之间的相对仿射变换表示为T1→2,其中包含相对旋转R1→2。我们在3D和2D空间进行一致性监管: T虽然包含了二维空间中旋转、移位和缩放的变化,但只有R影响了V,因为它是以手腕地标为根的。我们的总体损失函数是Ltotal = Lmesh +Lpose2D + Lnorm + Ledge + Lcon2D + Lcon3D。
T虽然包含了二维空间中旋转、移位和缩放的变化,但只有R影响了V,因为它是以手腕地标为根的。我们的总体损失函数是Ltotal = Lmesh +Lpose2D + Lnorm + Ledge + Lcon2D + Lcon3D。
4.经验
4.1实现细节
我们使用Adam优化器来训练网络,迷你批处理大小为32。我们实验中的所有模型都经过了38个周期的训练。初始学习率为10的-3次方,在第30代时除以10。对于超参数,输入分辨率为128 × 128, S = 9, Ce = 256, D ={256, 128, 64,32}。现有的3D手姿估计数据集通常存在手姿和视点的长尾分布。因此,我们开发了一个包含1520个姿态和216个视点的合成数据集,它们都均匀分布在各自的空间中。由于这种优越的性能,在训练中可以起到很好的补充作用。
4.2评价标准
我们在下面列出的几个常用基准上进行实验
FreiHAND包含130,240张训练图像和3,960个评估样本。评估集的注释是不可用的,所以我们将我们的预测提交到官方服务器进行在线评估。
Rendered Hand Pose Dataset (RHD)(渲染Hand Pose Dataset, RHD)由41,258和2,728个合成手数据组成,分别用于手姿估计的训练和测试。
HO3Dv2是一个3D手对象数据集,包含66,034个训练样本和11524个评估样本。评估集的注释没有,所以我们使用官方服务器进行在线评估。我们还使用这个数据集来评估时间性能。我们在定量评估中使用以下指标。
MPJPE/MPVPE通过估计坐标和真实坐标之间的欧几里得距离(mm)来测量每个关节/顶点位置误差的平均值。
PA-MPJPE/MPVPE采用Procrustes分析对MPJPE/MPVPE进行修正,忽略全局变化。为简洁起见,该指标缩写为PJ/PV。
Acc以像素/s2或mm/s2为单位捕获2D/3D关节地标的加速度,以反映时间相干性。
AUC是指PCK(正确关键点的百分比)与n ~ 50mm(用于3D测量)或0 ~ 30像素(用于2D测量)的误差阈值曲线下的面积。n = 0或20。
F-Score是两个网格之间的召回率和精度之间的谐波平均值。一个特定的距离阈值。F@5/F@15对应的阈值为5mm/15mm。
Mult-Adds计数乘法添加操作。
#Param参数个数
4.3消融实验
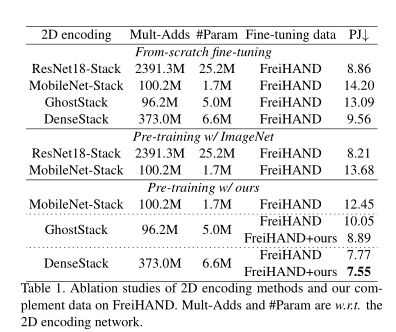
我们的堆叠网络和补充数据。我们以CMR为基线,采用FC进行2D-to3D特征映射,采用spiralconv++进行3D解码。对于相同的超参数,我们只更改用于比较的2D编码网络和数据设置。一方面,我们通过从零开始的训练来研究不同的堆叠结构。如表1所示,我们使用ResNet和MobileNet来设计堆叠结构,前者计算量大。尽管MobileNet在计算上易于处理,但它大大降低了性能(即PAMPJPE)。另一方面,使用ImageNet进行分类任务,其中的知识很难转移到2D/3D位置回归中。因此,ImageNet预训练带来不到1mm的PAMPJPE改进。根据表1,我们的补体数据可以包含在预训练和微调步骤中,DenseStack/ hoststack诱导7.55/8.89mm PAMPJPE。因此,我们在不牺牲重建精度的情况下,显著降低了计算成本编码结构和数据集,使我们的DenseStack/GhostStack适合移动环境。
特征提升模块。通过DenseStack,我们进行了准确性和时间相干性的联合研究。在表2中,我们没有使用顺序模块、时间优化或后处理。
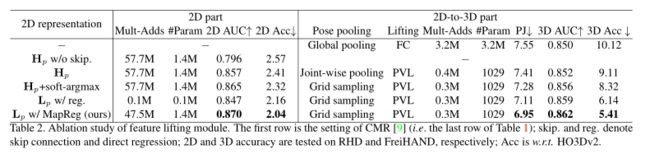
首先,我们详细探讨了各种二维姿态表示。热图Hp(图4(a))是一个高精度的表示,跳过连接被证明是融合高分辨率和低分辨率特征的关键。因此,当跳过连接被移除时,Hp在精度上表现很差。soft-argmax作为一种可微的选择最大位置的形式,可以从Hp生成更平滑的2D位置,从而提高2D AUC和Acc。此外,Lp w/ reg。(图4(c))精度相对适中,但由于全局感受野的存在,产生了更好的时间性能。最终,我们的MagReg通过集成基于热图和基于回归的范式的优点,获得了更好的2D精度和时间一致性。为了清楚地揭示细节,我们在图6中说明了映射。

对于Hp+soft-argmax,我们额外使用相同的损失设置(式9)进行训练,即不涉及热图监督。这种方式天真地导致了Hp的平滑版本,因为启发式的soft-argmax忽略了视觉语义。在MapReg中,我们在地图被平铺成一个向量之前呈现它。与Hp不同的是,该地图可以自适应描述联合地标约束,然后利用自适应局部全局信息预测二维位置。例如,当预测拇指上的地标时,整个拇指都被激活。因此,我们的MapReg可以产生更合理的铰接结构,以提高时间相干性。随后,我们探索了具有2D姿态对齐特征的3D性能。在姿态池化过程中,可以使用关节池化(图4(e))来获得基于Hp的二维姿态对齐特征,而在使用soft-argmax或Lp时,通常采用网格采样(图4(f))。值得注意的是,尽管Lp w/ reg在二维精度方面滞后,PAMPJPE优于Hp+soft-argmax。因此,在相同的姿态池化方法下,在建立稳定的训练过程中,2D一致性比准确性更重要。最终,magrep基Lp诱导出最佳的PAMPJPE和3D Acc。在PVL中,我们设计了一个提升矩阵Ml∈RV mini×N的线性运算,将特征从二维位姿空间转换到三维顶点空间。因此,V个迷你顶点特征是由N个地标特征的线性组合产生的。图7描述了一个训练良好的提升矩阵,其中我们绘制了abs(Ml),以清楚地揭示关节顶点关系。
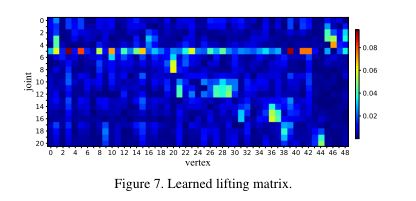
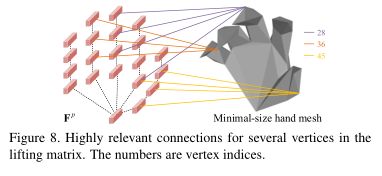
可以观察到,习得的Ml是稀疏的。一个关节地标(即位于食指根的关节5)作为全局信息,贡献了大部分顶点。此外,一些联合标志特征被传播到它们对应的顶点。图8描述了Ml中高度相关的连接,表明PVL方法可以保持语义一致性。
与CMR(表2的第一行)相比,我们的特征提升模块获得了更好的PAMPJPE和3D Acc。此外,我们还大大降低了2D-to-3D部分的计算开销。尽管在2D部分使用了额外的multi- added,但由于多任务学习和根恢复任务,2D姿态预测在3D手部重建中已被证明是有益的。
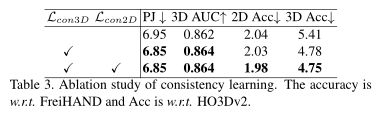
为了平衡模型的效率和性能。我们设计了3D/2D一致性损失来进一步提高性能。从表3可以看出,一致性学习提高了时间一致性。
此外,精度和时间相干性可以相互促进,从而提高PAMPJPE。如表4所示,DSConv极大地减少了3D解码器的multi - add和#Param,与spiralconv++相比,DSConv获得了相同的性能,有时甚至更好。总的来说,我们使用DenseStack/GhostStack的MobRecon在Apple A14 CPU上可以达到67/83 FPS。
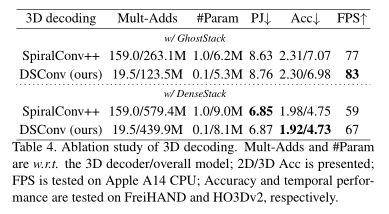
讨论。MobRecon有一个限制,即DSConv会增加内存访问成本,因此需要进行一些工程优化以获得更高的推理速度。
4.4与现有方法比较
在FreiHAND数据集上,我们用224 × 224的输入分辨率放大了基于resnet的模型,以进行公平的比较。如表5所示,我们用ResNet50超越了以前的方法,达到了一个新的水平,即5.7mm PAMPJPE。
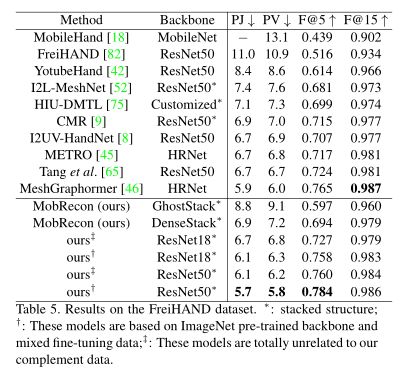
基于DenseStack或GhostStack,我们的MobRecon优于一些基于resnet的方法。
从图9可以看出,本文提出的MobRecon在3D PCK上具有较好的性能。
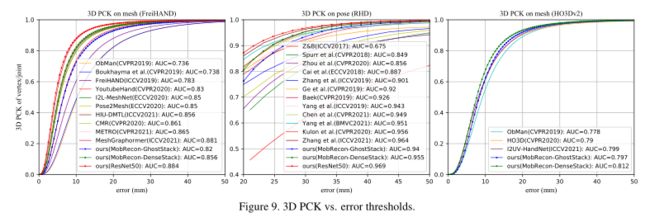
除了精度高,我们也达到卓越的推理速度,如图1所示。在RHD和HO3Dv2的实验中,我们的补体数据仅用于预训练DenseStack/GhostStack。在RHD数据集上,我们与图9中的几种姿态估计方法(如[1,5,62,72])进行了比较。我们的MobRecon与DenseStack/GhostStack的3D AUC分别为0.955和0.940,优于大多数比较方法。采用HO3Dv2数据集进行评价。从表6可以看出,我们的MobRecon优于现有的方法。
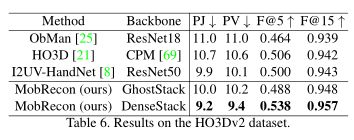
由于严重的物体遮挡,HO3Dv2比FreiHAND和RHD更具挑战性。在这种情况下,MobRecon优于一些基于resnet的方法,因为它具有更好的泛化能力。此外,我们在这个顺序任务中也获得了更好的时间一致性。
5.结论及未来工作
在这项工作中,我们提出了一种新的手网格重建方法,具有优越的效率,准确性和时间相干性。首先,我们提出了用于2D编码的轻量级堆叠结构。然后,采用MapReg、位姿池和PVL方法设计了一个特征提升模块,用于2d - 3d映射。此外,为了有效地处理三维解码任务,还开发了DSConv。我们的MobRecon仅涉及123M multi - added和5M参数,在Apple A14 CPU上达到了83FPS的快速推断速度。此外,我们在FreiHAND, RHD和HO3Dv2上实现了最先进的性能。我们计划研究手部交互的有效方法。
补充材料:
6.动机
如表7所示,许多数据集被开发用于三维手部姿态估计。为了收集真实世界的手部数据,通常使用多视图工作室捕获现有数据集,并通过半自动模型拟合进行注释。然而,这些模型拟合的数据集通常受到噪声注释、缺乏背景多样性和昂贵的数据收集的影响。另一种方法是计算机辅助合成数据,这种方法在可伸缩性、分布、注释和收集成本方面都有优势。此外,一个好的训练数据集应该避免长尾分布。即手的姿态和视点都要均匀分布。不幸的是,我们不知道任何现有的数据集符合这一要求。一些数据集试图通过多视图渲染来缓解视点有限的问题(例如,MVHM包含8个视图),但它们仍然过于稀疏,无法覆盖所有可能的视图。Boukhayma et al对MANO PCA分量进行均匀采样,生成各种手部姿势。但是PCA空间没有描述物理因素,因此无法直观地控制相应的采样结果。因此,我们受到启发,生成一个更全面的手数据集,具有足够的和均匀分布的手姿势和视点。
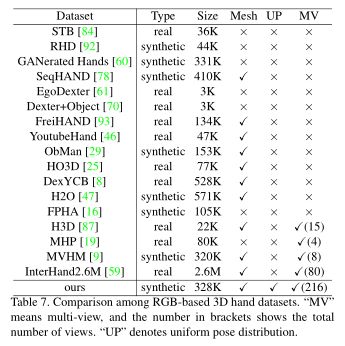
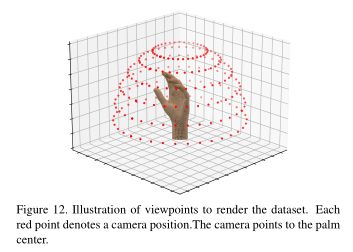
数据设计。我们设计了一个具有5633个顶点和11232个面的高保真手网格。与现有的手部数据集不同,我们统一设计手部姿势。首先,如图10所示,我们为每根手指设置两个状态,即完全弯曲和伸展。然后结合五种手指状态,得到32个基本姿态。两者的结合基本姿势的结果是496个姿势对。对于每一对,我们在Maya软件中均匀地从一个姿势插入到另一个中间姿势1(如图11所示)。我们总共得到了1520个均匀分布的手姿势。对于每个姿态样本,我们通过渲染提供其密集视点。为此,我们统一定义了216个半球面布置的相机位置。
如图12所示,经度范围为0 ~ 2π,纬度范围为0 ~ π/2。相邻位置在经度或纬度上相差π/18或π/12。所有相机都指向手掌中心,这样手就位于渲染图像的中心。因为腕关节末端位于球体中心,所以半球面采样包含了第一人称视角。对于背景,我们收集了具有真实场景和光照的高动态范围(HDR)图像进行渲染,使我们的手网格能够真实地融入各种场景。图20展示了使用我们的视点呈现的示例。自动生成的注释不涉及噪音。与主流数据集一致,我们设计了一个姿态不可知矩阵,将我们的密集拓扑映射到具有778个顶点和1538个面的MANOstyle网格。

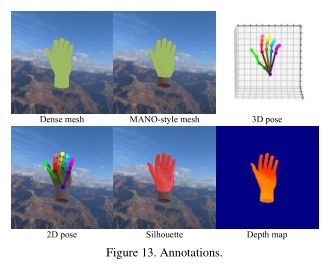
如图13所示,我们提供了我们设计的密集网格、mano风格网格、3D姿态、2D姿态、剪影、深度图和相机内在参数的注释。
讨论。我们的数据的局限性是缺乏形状/纹理多样性。此外,我们只考虑手指弯曲,我们计划建模手指伸展来扩展这个数据集,以均匀地覆盖整个姿态空间。
网络训练。为了预先训练二维编码网络,我们设计了一个不需要三维注释的二维姿态估计任务。在正文中,我们用热图和位置回归分析了二维表示。因此,如图14所示,我们在预训练步骤中同样地考虑这些表示。即热图和位置关节标志都有监督。该模型预训练了80个epoch,迷你批量大小为128。初始学习率为10的−3次方,除以10在第20,40和60epochs。输入分辨率为128 × 128。

7. 分析与应用
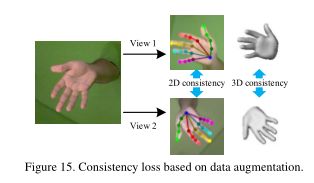
一致性损失。如图15所示,使用输入图像的数据增强派生了两个视图。那么一致性损失可以在二维和三维空间设计。
数据集设置说明。在正文的烧蚀研究中,我们使用RHD, FreiHAND和HO3Dv2来评估不同的性能。由于FreiHAND和HO3Dv2不发布ground truth,且官方工具不支持2D评估,因此使用RHD测试2D精度。HO3Dv2是一个序列数据集,因此采用它来反映时间相干性。但是HO3Dv2突出了手物交互,这不是我们的主题。相比之下,FreiHAND突出各种手部姿势,照明条件等,所以我们用它来评估3D精度。
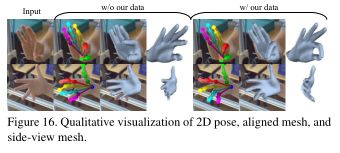
我们的补体数据在微调期间的影响。如图16所示,当我们的数据用于微调步骤时,可以提高模型在困难姿态预测时的性能。
HO3Dv2的可视化。从正文中的表6可以看出,我们的MobRecon优于一些基于resnet的模型。我们观察到这种现象与泛化性能有关。如图17所示,HO3Dv2含有大量严重闭塞的样品。在这种极端条件下,当基于resnet的模型崩溃时,我们的模型可以产生物理上正确的预测。

故障案例分析。如图18所示,MobRecon在挑战姿势时可能会出现失败的情况。通常,手指伸展的自遮挡很难准确预测,因为它们在大多数数据集中都是尾部分布的姿势。我们将通过改进补体数据来解决这个问题,如上一节所述。

更多的定性结果。图21展示了我们预测的二维位姿、对齐网格和侧视图网格的综合定性结果。挑战包括挑战性的姿势,对象遮挡,截断,和糟糕的照明。克服了这些困难,我们的方法可以生成精确的二维姿态和三维网格。

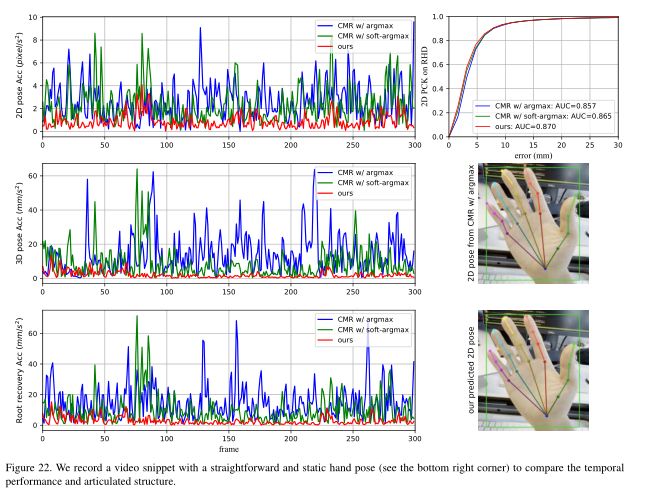
时间相干性的定性比较。我们录制了一个视频片段来演示时间一致性,在那里我们保持相机和手静止以产生低加速度。尽管网络输入是静态的,但由于检测抖动等原因,网络输入可能是暂时不稳定的。真实手姿很直观(见图22),所有比较的模型都很容易获得较高的精度。因此,时间性能可以在本实验中独家揭示。如图22所示,我们的MobRecon在2D/3D姿态一致性方面优于CMR[11]。此外,我们还利用[11]中的方法计算根坐标,获得了更好的根恢复稳定性。此外,我们还将二维PCK曲线补充到RHD上,证明了我们的方法具有更好的二维位姿精度。除了准确性和时间一致性之外,由于全局接受野和自适应地标间约束,我们使用MapReg的MobRecon可以产生更好的铰接结构。
移动应用程序。基于我们的MobRecon,虚拟戒指可以通过AR技术佩戴(图19)。

论文链接:
https://arxiv.org/abs/2112.02753
代码链接:
https://github.com/SeanChenxy/HandMesh