Summary——Learning Category-Specific Mesh Reconstruction from Image Collections
Contributions:给出了一个从单张图片重构3D形状的学习框架。除此之外,还能为这个3D网格贴上纹理。该方法的亮点在于不需要学习时不需要依靠3D真值或者多视角图片监督。
Empirics:CUB 和 PASCAL3D。
前者是本文的主要数据集,Caltech-UCSD Birds 200(CUB)鸟类图像数据集,包含 200 不同种鸟类,共计 11788 张图片。其中6000张图片用于训练,每张图片都包含了bounding box,visibility indicator(这个我真不知道是什么),以及14个语义关键点的位置,以及前景蒙版的真值。有300张图片由于在图片中的可见关键点小于等于六个,实验中不再使用。一半用于validation set。
看!全是鸟。

PASCAL 3D+ 是一个3D物体检测和姿态识别数据集,包括 PASCAL VOC 2012中的12个类别物体的3D标注,平均每个类别中包含3000个实例。这个其实在文中不是很重要,就是针对这些大类也用本文的方法跑了一遍,向大家展示一下方法的普适性。
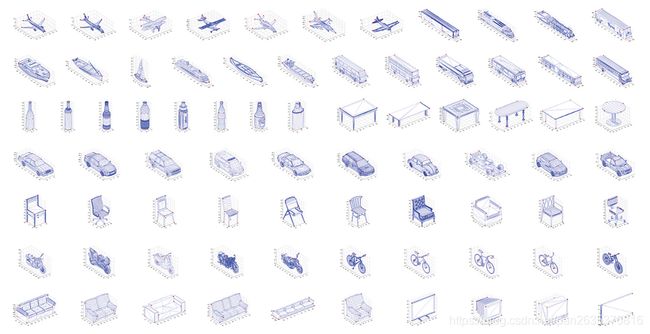
从本文的数据集选择我们可以看出来什么?
从2D图片重建3D网格的训练,不需要3D真值!对!不需要3D真值!!!
Methods:
文章的思路很清晰,先从6000张训练图片中学习一个平均的小鸟的形状 ,将它构成一个3D网格。然后针对单张图片的小鸟的形变
,将它构成一个3D网格。然后针对单张图片的小鸟的形变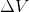 ,二者相加得到个体小鸟的最终形态
,二者相加得到个体小鸟的最终形态![]() 。
。
(看下图,是文章中的一个展示结果。作者在所有训练图片的预测形变中,做主成分分析(PCA),发现了其实这6000张小鸟的图片,大体就是朝着三个方向变化:胖和瘦,翅膀的开和关,尾巴和腿的变形)

然后是贴图的工作,在原始图片上用双线性插值学习得到UV图,这张UV图是长方形的,由于一个球体可以展开为一个平面,同理,一个长方形平面的UV图也可以变形为一个球体(使用球坐标做映射),这个球体上就是小鸟的纹理,而球体的实际上和小鸟的模型![]() 是同构的,同构变形之后,变形之后的小鸟就穿上衣服啦╭(╯^╰)╮。
是同构的,同构变形之后,变形之后的小鸟就穿上衣服啦╭(╯^╰)╮。
(上图所展示的,就是上述所说的球体和小鸟的同构关系,球体和平面的映射关系,平均形状和个体形变的关系)
大体思路就是这样子,接下来解释一下实现细节。
本文先从6000张训练图片中找到一众小鸟的平均形状,要学习得到平均形状,先要对这个平均形状做一个好的初始化,这样能够提高学习的效率。
怎么初始化这只鸟的平均形状?本文先对鸟类图片使用structure-from-motion(SfM)算法,这个算法是做什么的?看下面这个图:(来自RyuZhihao123的实验结果图Structure from motion(SFM)原理 - 附我的实现结果)
输入图片为:

输出效果为:
这也就是说,SfM算法中,输入一系列同一目标的图片(在这里是不同角度),能够得到目标的三维点云。本文的初始化过程和上述实验的不同在于,本文使用的是几万张不同鸟类的图片(上述只有10张),且本文的SfM算法是在鸟类图片的注释关键点上运行的(上述实验应该是直接在图片上提取特征吧,所以得到的点云才那么密集)。
所以啊,在SfM算法直接提取数据集上的注释关键点,得到的是如下图所示的初始化平均形状,这个形状是得到的平均关键点的凸包。顶点应该是14个,因为注释关键点是14个。

如果你对凸包还不了解,你可以这么想,它就是点集最外层的点连接起来构成的凸多边形,能包含点集中所有的点。
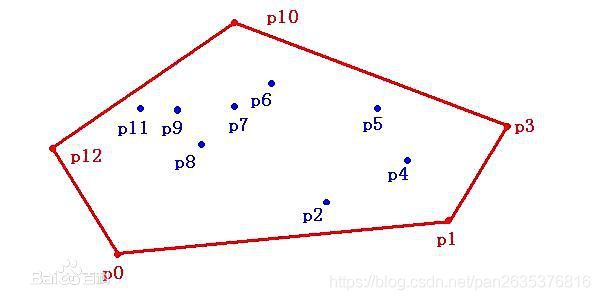
(哈哈哈哈哈我只找到二维的图片,三维的你们自己脑补下)
但是这个初始化还太过粗糙,我们还要训练数据集得到一个最终的,平均形状,它长这样:

怎么样,是不是精细很多。
这个学习,还是用卷积网络学习的,学习而得的参数是形状和相机参数,总体目标函数是这样子:
![]()
第一项![]() 是关键点投影的损失,为的是确保预测的3D结构和图片关键点的注释相匹配,具体什么样不影响大局,你萌还是回去看论文吧╭(╯^╰)╮
是关键点投影的损失,为的是确保预测的3D结构和图片关键点的注释相匹配,具体什么样不影响大局,你萌还是回去看论文吧╭(╯^╰)╮
第二项 是蒙版和网格投影的损失,表达的是目标的投影和蒙版的一致性,这里希望预测的小鸟模型的体型和图片里的尽可能像,图片也尽可能像。
是蒙版和网格投影的损失,表达的是目标的投影和蒙版的一致性,这里希望预测的小鸟模型的体型和图片里的尽可能像,图片也尽可能像。
第三项![]() 是相机姿态损失,为的是校准相机姿态以便和SfM算法得到的结果对应起来。
是相机姿态损失,为的是校准相机姿态以便和SfM算法得到的结果对应起来。
第四项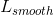 要求重构的3D网格尽可能和真实的小鸟表面一样平滑,这里要最小化平均曲率。
要求重构的3D网格尽可能和真实的小鸟表面一样平滑,这里要最小化平均曲率。
第五项![]() 用于形变调整,防止形变过于夸张,有助于学习一个有意义的平均形状。
用于形变调整,防止形变过于夸张,有助于学习一个有意义的平均形状。
第六项![]() 对所有关键点最小化平均交叉熵。目的是使每个特征点对应的系数矩阵应该是一个one-hot向量,就是说,在是关键点的位置数值为1,不是的都为0,这个在做分类实验的时候大家都用过吧╭(╯^╰)╮
对所有关键点最小化平均交叉熵。目的是使每个特征点对应的系数矩阵应该是一个one-hot向量,就是说,在是关键点的位置数值为1,不是的都为0,这个在做分类实验的时候大家都用过吧╭(╯^╰)╮
除此之外,由于本文预测的这些类(小鸟啊,小车啊,小飞机啊)都是对称的物体,所以本文限制预测的形状和形变都是镜像对称的。由于学习出的3D网格和球体是同构的,本文还在初始的结构中定义对称顶点。也就是说,不管是在学习或者预测还是的时候,都只要预测其中点对中的其中一个即可。
小鸟的3D模型做好了以后,就要开始贴图了。贴图的主要思想用的是前人的研究成果View Synthesis by Appearance Flow 。
这篇文章做的其实是从物体的一个视角,推测物体的其他视角的图片,就是下图这样:

该方法一改前人直接预测目标视角图片的像素值的思路,而是使用了CNN在原始图片上采样像素点的方法,预测的是appearance flow构造新视角的图片。这个appearance flow是一个二元数组的集合,该dense flow field每个元素![]() ,代表的是目标视角的第
,代表的是目标视角的第  个像素应该采样自原始图片的像素坐标为
个像素应该采样自原始图片的像素坐标为 ![]()
 。
。
这里采用的是双线性插值的采样方法。(这里具体的采样思路我还没看懂???????????????????????)
主要的网络结构为,提取图片特征的输入编码器(颜色,姿态,质地,形状等等)+ 将视角映射到更高维的视角转换编码器 + 组装前两个编码器提取的特征,输出场的合成解码器

别的部分不用看,我们只要看到上图右下角的箭头集合就是我们预测的 flow field,通过它,我们再对原始图片双线性插值就可以得到新视角的合成图片啦╭(╯^╰)╮
现在,让我们回到小鸟的问题上来,很显然,前人的这个成果可以用到我们手头的这个贴图工作上来。

你看,输入了小鸟的图片集之后,我们也可以训练一个网络 = 输入编码器 + 转换编码器 + 合成编码器,就可以输出appearance flow (在本文中被称作 texture flow)了,由此,我们可以对原始图片双线性插值,得到UV图片![]() ,这个UV图通过球坐标可以映射到一个球体上,由于球体和小鸟模型
,这个UV图通过球坐标可以映射到一个球体上,由于球体和小鸟模型 ![]() 是同构的,故可以再通过变形,将这个贴上了纹理的球体转变为一只小鸟,怎么样,是不是可生动,可形象了╭(╯^╰)╮
是同构的,故可以再通过变形,将这个贴上了纹理的球体转变为一只小鸟,怎么样,是不是可生动,可形象了╭(╯^╰)╮
而由于这个小鸟的纹理根本就是采样得来的,而且这个UV图也具备了不少图片的信息。这个重建的3D模型的关键点具备了更多语义信息。