HDFS知识点
HDFS
- 知识点结构图
一、HDFS概述
1.1 HDFS定义
1.1.1 Hadoop是什么?
Hadoop由三个模块组成:分布式存储HDFS,分布式计算MapReduce和资源调度引擎 yarn 。
假设现需要在图书馆找一本叫做hadoop的书籍,有一个馆长yarn,100个普通工作人员即cpu/io/内存,N个分馆(图书馆),而MapReduce就是统计哪些书架有hadoop这本书。
-
分布式是什么?
分布式:利用一批通过网络连接的,廉价普通的机器,完成单个机器无法完成的存储和计算任务。
1.1.2 HDFS定义
HDFS(Hadoop Distributed File System),它是一个分布式文件系统,用于存储文件,通过目录树结构来定位文件,并由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景,并且不支持文件的修改,适合用来做数据分析,不适用做网盘应用。
1.2 HDFS优缺点
1.2.1 优点
- (1)高容错率
- 数据自动保存多个副本,他通过增加副本的形式,提高容错率
- 某一个副本丢失以后,他可以自动恢复
- (2)适合处理大数据(分布式文件)
- 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据
- 文件规模:能够处理百万规模的文件数据,数量很大。
- (3)可构建在廉价机器上,通过多副本机制,提高可靠性,并且其扩展性强,比如结合框架使用(Hive、HBase等)
1.2.2 缺点
- (1)不适合低延时数据访问,比如毫秒级的存储数据。
- (2)无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量内存来存储文件目录和块信息,这样不可取,因为NameNode的内存是有限的
- 小文件存储的寻址时间会超过读取时间,他违反了HDFS的设计目标
- (3)不支持并发写入、文件随意修改
- 一个文件只能有一个写,不允许多个线程同时写
- 仅支持数据追加,不支持文件的随机修改。
1.3 HDFS组成架构
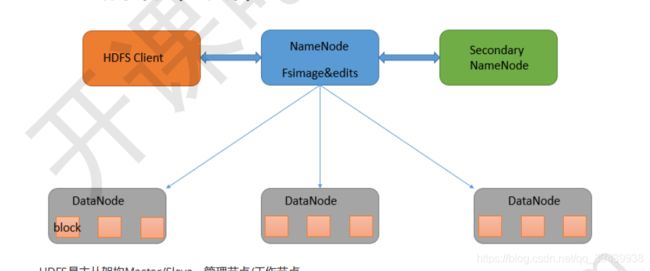
HDFS是主从架构Master/Slave,客服端通过Namenode主节点访问存放在各个datanode上的文件信息,namenode管理每个子节点,同时还有secondaryNamenode做备份主节点。
1.3.1 NameNode
NameNode是主节点,它可以看作一个文件系统,用来管理存储,读取数据。
在Namenode中会存有元数据(metadate),由Namenode存储在内存当中,这个元数据信息是指像告知客户端block1放在哪台服务器这种信息。
元数据信息以命名空间镜像文件fsimage和编辑日志edits log的方式保存:
fsimage:元数据镜像文件,保存了文件系统目录树信息和文件,块的对应关系
edits log:日志文件,保存文件系统的更改日志。
归纳来说主要有以下几点作用:
- (1)管理DataNode,负责管理文件系统和名称空间;
- (2)存放HDFS的元数据,元数据存有文件系统树,所有的文件和目录,每个文件的块列表,块所在的datanode等信息。
- (3)配置副本策略,块的数量通过配置参数设置
- (4)处理客户端请求
1.3.2 DataNode
DataNode是从节点,NameNode下达命令,DataNode执行实际操作。
归纳作用如下:
- (1)存储实际的数据块,以及block元数据的数据长度,块数据的校验和,时间戳等信息
- (2)执行数据块的读、写操作。
1.3.3 Secondary NameNode
Secondary NameNode备份元数据信息,但并不能说是NameNode的热备,当NameNode挂掉时,Secondary NameNode不能马上替换NameNode并提供服务
归纳作用如下:
-
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
-
(2)在紧急情况下,可以辅助恢复NameNode,提高namenode从故障当中的恢复速度
具体提高恢复速度原理如下:
Secondary NameNode会周期性(每隔一小时执行一次)的将从NameNode同步过来的edits log和fsimage合并到一个checkpoint(edit log记录了对HDFs的操作),然后发送给NameNode,这样namenode的重启就会Load最新的一个checkpoint,并replay EditLog中 记录的hdfs操作,从而提高NameNode重启速度。
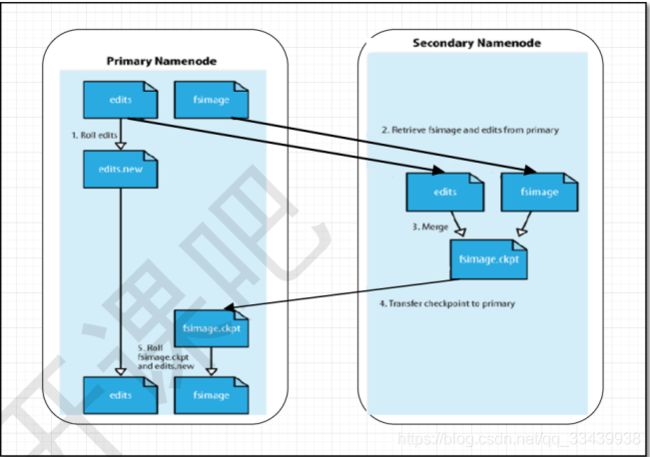
hadoop的默认配置中让snn进程默认运行在了namenode的那台机器上,但是这样的话,如果这台机器出错,宕机,对恢复HDFS文件系统是很大的灾难,更好的方式是:将snn的进程配置在另外一台机器 上运行。
1.3.4 Client
客户端,归纳作用如下
- (1)文件切分。文件上传到HDFS时,Client将文件切分成一个个block,然后再上传
- (2)与NameNode交互获取文件位置信息,与DataNode交互进行读、写操作
- (3)Client提供一些命令来管理HDFS,比如NameNode格式化
- (4)Client可以通过一些命令来访问HDFS,比如对HDFS的增删改查。
二、核心概念blocks
2.1 HDFS上的blocks块
HDFS中的文件在物理上是分块存储的,分散的存储在集群的不同数据节点datanode上。
块的大小可以通过配置参数dfs.blocksize来决定,默认老版本是64M,在Hadoop 2.x开始是128M。
128M是指上限,实际可能block文件的大小不到128M。
2.2 blocks副本数
作用:保证数据的可用及容错,blocks默认是3个。
可以通过设置hadoop-3.1.2/etc/hadoop/hdfs-site.xml文件中的dfs.replication来控制副本个数
<property>
<name>dfs.replicationname>
<value>3value>
property>
官网说明:https://hadoop.apache.org/docs/r3.1.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
2.3 机房存储策略
在配置文件hdfs-site.xml中配置了副本数为3,那么首先有一个主节点(namenode)和其他从节点(datanode),在服务器中就会确保每一个数据节点都能有另外两个block副本备份,其中block1会存放在同一机架上的服务器,第二个block和第三个block会存放在另一台机架上的服务器,其他节点也类似这样存放。
假如第一台机架上的block1暂时奔溃了,主节点为了保持block1维持3个block数,会按照已有的block2副本再创建一个block1,当原有的block1恢复时主节点就考虑删除其中一个副本。
三、HDFS机制
3.1.Secondary NameNode和NameNode的工作机制
Secondary NameNode专门用于 FsImage 和 Edits 的合并,工作机制如下图所示:
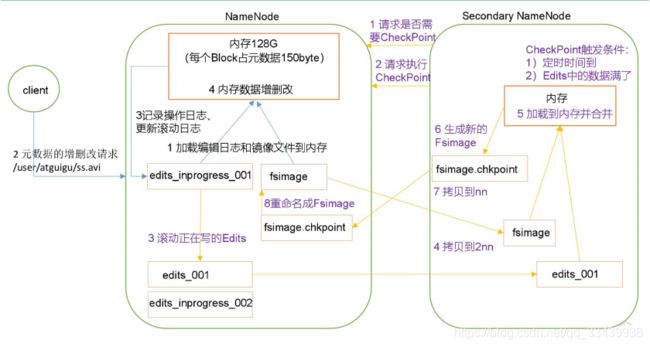
- 第一阶段:NameNode启动
- 第一次启动NameNode格式化后,创建FSimage和Edit文件,如果不是第一次启动就直接加载Edit和Fsimage镜像文件到内存
- 然后客户端对元数据进行增删改查的请求
- NameNode记录操作日志,更新Edit日志
- NameNode在内存中对数据进行增删改查
- 第二阶段:Secondary NameNode工作
- Secondary NameNode定时询问NameNode是否需要checkpoint
- 如果是edits中的数据满了,Secondary NameNode则请求执行checkpoint
- NameNode接受到后,将更新后的Edit日志和Fsimage镜像文件拷贝到Secondary NameNode
- Secondary NameNode加载Edit日志和Fsimage到内存并合并,生成新的fsimage.checkpoint镜像文件、
- fsimage.checkpoint镜像文件发送到NameNode,NameNode将其重命名为fsimage。
所谓合并,就是将 Edits 和 Fsimage 加 载 到 内 存 中 , 照 着 Edits 中 的 操 作 一 步 步 执 行 , 最 终 形 成 新 的 Fsimage。
NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在 Fsimage 中。
3.2 NameNode和DataNode的心跳机制
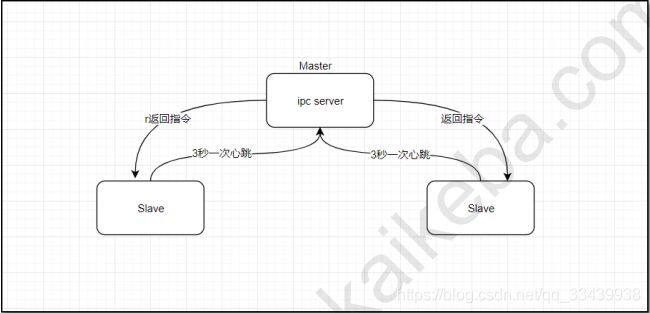
3.2.1 工作原理
- 1.master启动的时候,会开一个icp server;
- 2.slave启动,连接上master,每隔3秒向master发送一个“心跳”,携带状态信息;
- 3.master通过这个心跳的返回值,向slave节点传达命令。
3.2.2 作用
-
1.Namenode全权管理,它周期性地从集群中的每个datanode接受心跳信号和块状态报告(block report),接受到心跳信号意味着该节点工作正常。块状态报告包含了一个该datanode上所有数据的列表。
-
2.Datanode启动后向Namenode注册,通过后,周期性(1小时)向Namenode上报所有的数据块列表;每3秒向Namenode发送一次心跳,返回Namenode给它的命令;如果Namenode超过10分钟没有收到某个Datanode的心跳,则认为该节点不可用。
(假如有一个节点挂了,主节点就会告诉某个正在报告的从节点,告诉它要复制一份block到新的节点上,维持总block数。)
-
hadoop集群启动时,会进入安全模式,就用到了心跳机制。
刚启动时会进入安全模式,这个模式会在从节点向主节点汇报过程中,主节点只有获取到整个文件系统中有99.9%(可以配置的)的块满足最小副本才会自动退出安全模式,否则,外部只能读取hdsf数据而不能写入hdfs,大于等于99.9%时才会解除安全模式。
但要注意,这里的刚启动不能是刚格式化后的,因为hadoop集群此时还没有任何设置任何块,所以NameNode不会进入安全模式。
3.3 负载均衡
负载均衡会迁移block到磁盘空间比较大的磁盘。大于5%的利用率就会触发负载均衡,读写都会出发负载均衡。负载均衡是namenode做的。
手动启动均衡:
[hadoop@node_1 ~]$ $HADOOP_HOME/sbin/start-balancer.sh -t 5%
四、HDFS读写流程
4.1 写流程
写过程:
- (1)HDFS Client客户端和NameNode先取得联系,假设请求上传文件
- (2)NameNode响应可以上传文件,在这之前NameNode会做以下几件事:
- 判断DateNode是否正常运行
- 判断文件是否存在
- 判断client是否有权限
- 向edit 日志文件写日志做记录
- (3)然后Client向NameNode请求要上传的blocks块,等待NameNode返回给客户端各个Block应该存到哪个节点
- (4)开始写入节点的过程:
- (4.1)首先客户端中的 FSDataOutputStream拿到block的数据后,是按一个一个字节来将数据写入到一个名为chunk的小块,chunk能存储512byte的数据再加上一个4byte的校验值
- (4.2)写满chunk之后,再将chunk放到一个package中,package容量为64KB,可以放很多个chunk,当放满一个package后,该package就会加入到一个data queue队列。
- (4.3)data queue中的package,会逐步被发送到node1,node2,node3中写数据,写的过程,同时会把package写入到另一个ack(确认)queue的队列中,供后续校验。
- (4.4)待package的chunk数据写入到节点后,对每个节点的package重新生成校验值,将该校验值和ack queue中的package作对比,相等说明校验成功,就将package从ack queue删除,如果校验不成功,那么重新将p1添加回data queue ,再传输一次。
4.2 读过程

读过程:
- (1)客户端通过分布式文件系统向NameNode发送请求,假设请求下载文件。
- (2)NameNode查询后返回客户端目标文件的元数据,元数据中有关于块的位置信息。
- (3)接着客户端挑选一台DataNode服务器(网络拓扑-就近原则),通过FSDataInputStream的read方法与datanode建立连接,请求读数据
- (4)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Package为单位)
- (5)客户端也以package为单位接收,先在本地缓存,然后写入目标文件。
datanode分割存储数据的时候,本身还会生成一个packet校验和,是一个关于crc32位的校验码。读取给客户端时,校验和会一并跟着数据返回给FSInputStream,FSInputStream就会重新对数据做一次校验和,看重做的校验和与一开始生成的校验和是否相等,相等则说明读取跟存入block的是同一个文件。
五、Hadoop-HA高可用
5.1 HA概述
HA = High Availability,即高可用(7*24 小时不中断服务)。
假设原来只有一个namenode,并且namenode出故障挂掉后,要恢复namenode的元数据,原先通过元数据的FS加载到内存执行并且edit日志的操作重新执行才能恢复数据,但这个过程耗费时间(主要的矛盾点是要花时间恢复元数据metadata)。
NameNode 主要在以下两个方面影响 HDFS 集群 :
-
NameNode 机器发生意外,如宕机,集群将无法使用,直到管理员重启
-
NameNode 机器需要升级,包括软件、硬件升级,此时集群也将无法使用
实现高可用最关键的是消除单点故障,HA是通过双NameNode和切换Active/Standby两个状态消除单点故障的。
5.2 Hadoop-HA工作机制

步骤:
-
(1)在hadoop的高可用中,会有两台namenode:NN1和NN2,NN2为备份的namenode。正常情况下,NN1在使用中,状态为Active,NN2状态为Standby。
-
(2)在client连接NN1产生操作日志过程中,会将edit日志信息发送给共享存储里面,共享存储再把edit日志发送给NN2,使得NN2时刻与NN1保持元数据一致。
-
(3)而Datanode会同时向两个namenode注册,发送datanode report报告块信息,但只听从状态为active的主节点命令。
-
(4)在NN1和NN2中同时都有一个ZKFC管理,zkfc会周期性的向它监控的namenode发生健康探测命令,如果得知NN1出问题,会通过Zookeeper告知另一个NN2管理的ZKFCNN1挂了,让NN2切换状态为active工作,而NN1切换成standby。
注意:
- Edits 日志只有 Active 状态的 NameNode 节点可以做写操作
- 内存中各自保存一份元数据
- 两个 NameNode 都可以读取 Edits
- 共享的 Edits 放在一个共享存储中管理
- 当需要进行状态切换时,由 zkfailover来负责切换,切换时需要防止 brain split 现象的发生,也就是脑裂,不应该同时有两个Active状态的NameNode在工作,可以kill掉。
- 隔离(Fence),即同一时刻仅仅有一个 NameNode 对外提供服务
六、Hadoop联邦
集群规模达到几千台的情况下可能用到联邦。
联邦是指支持多个namenode,每个namenode分管一部分元数据目录,并共享所有datanode存储资源。
6.1 为什么需要用到联邦?
Hadoop集群的元数据是保存在namenode中的,元数据记录文件,目录,block占用约150字节,这样单个namenode所能存储的对象有限制,并且整体性能方面吞吐量受单namenode的影响。对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向扩展的瓶颈。
而联邦可以解决内存受限问题,通过多个namenode/namespace把元数据的存储和管理分散到多个节点中,使到namenode/namespace可以通过增加机器来进行水平扩展。
6.2 联邦的优点
- 扩展性:多个NameNode分管一部分namespace,相当于namenode是一个分布式的,可以有很好的内存上限。
- 吞吐量:多个NameNode同时对外提供服务,提供更高的读写吞吐率
- 隔离性:可以通过多个namenode来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的namenode中
七、HDFS编程
7.1 HDFS常用命令
基本语法:bin/hadoop fs 具体命令 OR bin/hdfs dfs 具体命令
# 调用jar包
$ hadoop jar 完整jar包 jar包中的类名 被调用文件 [输出路径]
# 启动hadoop集群
$ sbin/start-all.sh
# 显示目录信息
$ hadoop fs -ls /
# 在 HDFS 上创建目录
$ hadoop fs -mkdir -p /sanguo/shuguo
# 从本地剪切粘贴到 HDFS
$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
# 从本地文件系统中拷贝文件到 HDFS 路径去
$ hadoop fs -copyFromLocal README.txt /
# 追加一个文件到已经存在的文件末尾
$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
# 显示文件内容
$ hadoop fs -cat /sanguo/shuguo/kongming.txt
# -chgrp 、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限
$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
# 从 HDFS 拷贝到本地
$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
# 从 HDFS 的一个路径拷贝到 HDFS 的另一个路径
$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
# 在 HDFS 目录中移动文件
$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/
# -get:等同于 copyToLocal,就是从 HDFS 下载文件到本地
$ hadoop fs -get /sanguo/shuguo/kongming.txt ./
# -getmerge:合并下载多个文件,比如 HDFS 的目录 /user/atguigu/test 下有多个文 件:log.1, log.2,log.3,...
$ hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt
# -put:等同于 copyFromLocal
$ hadoop fs -put ./zaiyiqi.txt /user/atguigu/test/
# 显示一个文件的末尾
$ hadoop fs -tail /sanguo/shuguo/kongming.txt
# 删除文件或文件夹
$ hadoop fs -rm /user/atguigu/test/jinlian2.txt
# 删除空目录
$ hadoop fs -rmdir /test
# -du 统计文件夹的大小信息
$ hadoop fs -du -h /user/atguigu/test
1.3 K /user/atguigu/test/README.txt
15 /user/atguigu/test/jinlian.txt
1.4 K /user/atguigu/test/zaiyiqi.txt
# -setrep:设置 HDFS 中文件的副本数量,实际要看DataNode的数量。
$ hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
7.2 修改配置
7.2.1 NameNode多目录配置
NameNode 的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
具体配置如下:
- 在 hdfs-site.xml 文件中增加如下内容
<property>
<name>dfs.namenode.name.dirname><value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.t mp.dir}/dfs/name2value> property>
# 停止集群,删除 data 和 logs 中所有数据。
[atguigu@hadoop102 hadoop-2.7.2]$ rm -rf data/ logs/
[atguigu@hadoop103 hadoop-2.7.2]$ rm -rf data/ logs/
[atguigu@hadoop104 hadoop-2.7.2]$ rm -rf data/ logs/
#格式化集群并启动
$ bin/hdfs namenode –format
$ start-dfs.sh
#查看结果
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 atguigu atguigu 4096 12 月 11 08:03 data
drwxrwxr-x. 3 atguigu atguigu 4096 12 月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12 月 11 08:03 name2
7.2.2 集群安全模式
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
相关命令如下:
-
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
-
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
-
(3)bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
-
(4)bin/hdfs dfsadmin -safemode wait(功能描述:等待安全模式状态)
# 示例
$ hdfs dfsadmin -safemode get
7.2.3 CheckPoint时间设置
- 通常情况下,SecondaryNameNode 每隔一小时执行一次
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.periodname> <value>3600value>
property>
- 然后设置为一分钟检查一次操作次数, 当操作次数达到 1 百万时,SecondaryNameNode 执行一次。
<property>
<name>dfs.namenode.checkpoint.txnsname>
<value>1000000value>
<description>操作动作次数description>
property>
<property>
<name>dfs.namenode.checkpoint.check.periodname>
<value>60value>
<description> 1 分钟检查一次操作次数description>
property >
八、项目案例
8.1 集群处于安全模式无法退出
手动退出安全模式:
$ hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
$ hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
$ hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
$ hdfs dfsadmin -safemode wait(功能描述:等待安全模式状态)
8.2 NameNode故障处理
NameNode出现故障宕机,就要考虑到用Secondary NameNode来帮助恢复重启。
NameNode 故障后,可以采用如下两种方法恢复数据。
-
方法一:将 SecondaryNameNode 中数据拷贝到 NameNode 存储数据的目录;
- kill -9 NameNode 进程
- 删除 NameNode 存储的数据(/hadoop-2.7.2/data/tmp/dfs/name)
$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*- 拷贝 SecondaryNameNode 中数据到原 NameNode 存储数据目录
$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/names econdary/* ./name/- 重新启动 NameNode
$ sbin/hadoop-daemon.sh start namenode -
**方法二:**使 用 -importCheckpoint 选 项 启 动 NameNode 守 护 进 程 , 从 而 将
SecondaryNameNode 中数据拷贝到 NameNode 目录中。
- 修改 hdfs-site.xml 中的
<property> <name>dfs.namenode.checkpoint.periodname> <value>120value> property> <property> <name>dfs.namenode.name.dirname> <value>/opt/module/hadoop-2.7.2/data/tmp/dfs/namevalue> property>- kill -9 NameNode 进程
- 删除 NameNode 存储的数据(/hadoop-2.7.2/data/tmp/dfs/name)
$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/*- 如果 SecondaryNameNode 不和 NameNode 在一个主机节点上,需要将SecondaryNameNode 存储数据的目录拷贝到 NameNode 存储数据的平级目录,并删除 in_use.lock 文件
$ scp -r atguigu@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/names econdary ./ $ rm -rf in_use.lock $ pwd /opt/module/hadoop-2.7.2/data/tmp/dfs- 导入检查点数据(等待一会 ctrl+c 结束掉)
$ bin/hdfs namenode -importCheckpoint # 启动 NameNode #$ sbin/hadoop-daemon.sh start namenode
8.3 HDFS 存储多目录
若 HDFS 存储空间紧张,需要对 DataNode 进行磁盘扩展。

-
(1)在 hdfs-site.xml 文件中配置多目录,注意新挂载磁盘的访问权限问题
下面的类似${hadoop.tmp.dir}/dfs/data1 目录要提前先创建好。
<property>
<name>dfs.datanode.data.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///hd2/dfs/
data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4value>
property>
- (2)增加磁盘后,保证每个目录数据均衡
# 开启数据均衡命令:
bin/start-balancer.sh –threshold 10
# 对于参数 10,代表的是集群中各个节点的磁盘空间利用率相差不超过 10%,可根据实际情况调整。
#停止数据均衡命令:
bin/stop-balancer.sh
# 不停止会带来其他压力,比如实时的通信,实时的检测,浪费一定的资源。
九、HDFS 2.X新特性
9.1 集群间数据拷贝
9.1.1 scp实现两个远程主机之间的文件复制
如果在两个远程主机之间 ssh 没有配置的情况下可以使用该方式。
语法:scp [可选参数] file_source file_target
# 将hello.txt复制到103的机器
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt
#将103机器的这个文件拷贝过来到当前目录下
scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt
9.1.2 distcp 命令实现两个 Hadoop 集群之间的递归数据复制
$ bin/hadoop distcp hdfs://haoop102:9000/user/atguigu/hello.txt hdfs://hadoop103:9000/user/atguigu/hello.txt
9.2 小文件存档
使用HDFS存档或者Har文件,即HDFS存档文件对内来说还是一个个独立文件,但对NameNode来说却是一个整体,减少了NameNode的使用。
9.3 回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
9.4 快照管理
快照相当于对目录做一个备份,并不会立即复制所有文件,而是记录文件变化。
十、存储大量小文件
-
扩展链接:https://blog.51cto.com/jaydenwang/1839660
-
start-yarn.sh 启动yarn
-
小文件存在问题:namenode存储着文件系统的元数据,元数据存有文件,目录,块,大约占150字节大小,如果小文件过多,会占用元数据中记录文件的内存,给namenode造成压力,并且影响hadoop存储和访问的效率。
-
解决方法:HAR文件方案(启动mr程序,需要启动yarn)和Sequence Files方案
- HAR文件方案
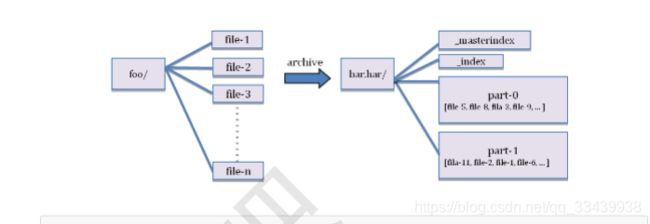
本质上是在HDFS上构建一个分层文件系统,通过执行hadoop archive命令将小文件压缩成一个har文件,然后用户可以通过har://的协议访问HAR文件中的小文件。
使用这种方式可以减少HDFS中文件的数据,但实际上会降低hadoop的访问效率,常用于文件归档。
下面是Har文件方案用到的命令:
#因为用到mr程序,需要先开启yarn
start-yarn.sh
#创建archive文件,其中-archiveName指定创建后的har名,-p指定要归档的地址,后面可以空#格加具体某个文件目录。/outhar是归档后输出的地址。
[hadoop@node_1 ~]$ hadoop archive -archiveName test.har -p /test /outhar #此时源文件还在,需要手动删除。

#查看archive
[hadoop@node_1 ~]$ hdfs dfs -ls -R har:///outhar/test.har
#解压archive文件
[hadoop@node_1 ~]$ hdfs dfs -cp har:///outhar/test.har hdfs:/unarchivef
#顺序
[hadoop@node_1 ~]$ hadoop fs -ls /unarchivef
#并行启动MR
[hadoop@node_1 ~]$ hadoop distcp har:///outhar/test.har hdfs:unarchivef2
- Sequence File方案
参考链接:https://blog.csdn.net/bitcarmanlee/article/details/78111289
额外扩展问题:
1.block块为什么设置比较大?(面试)
-
HDFS中平均寻址时间大概为10ms;
-
经过前人的大量测试发现,寻址时间为传输时间的1%时,为最佳状态;
所以最佳传输时间为10ms/0.01=1000ms=1s
-
目前磁盘的传输速率普遍为100MB/s;
计算出最佳block大小:100MB/s x 1s = 100MB
所以我们设定block大小为128MB。
实际在工业生产中,磁盘传输速率为200MB/s时,一般设定block大小为256MB,所以块大小取决于磁盘传输速率,目的是为了最小化寻址开销。
另一个问题,是否块越大或者越小较好?
这个问题,如果块太小,那么就会产生跟hdfs存储大量小文件一样,会给namenode造成内存的压力,不可取;如果块太大,磁盘传输数据的时间会明显变慢,mapreduce中的map任务运行任务也会变很慢。
参考链接:https://blog.csdn.net/wx1528159409/article/details/84260023
修改记录
| 时间 | 内容 |
|---|---|
| 2020年04月10日 | 第一次发布 |
| 2020年9月13日 | 结合新课程,重新整理知识点框架 |
- 学习参考:
《开课吧-大数据开发高级工程师一期》课程
《尚硅谷大数据项目数据仓库,电商数仓V1.2新版》课程
本文为学习课程做的笔记,如有侵权,请联系作者删除。