机器学习实战(jupyter)/第一部分第二章/划分数据集的方式
# 加载库
import os
import tarfile
import pandas as pd
from six.moves import urllib
导入数据集
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
#当数据会定期发送变换,还可以写个小脚本。
# def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
# os.makedirs(housing_path, exist_ok=True)
# tgz_path = os.path.join(housing_path, "housing.tgz")
# urllib.request.urlretrieve(housing_url, tgz_path)
# housing_tgz = tarfile.open(tgz_path)
# housing_tgz.extractall(path=housing_path)
# housing_tgz.close()
# fetch_housing_data()
# 加载数据
def load_housing_data(housing_path=HOUSING_PATH):
csv_path=os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path)
方式1:随机排列,按行号去取数
import numpy as np
np.random.seed(42) #np.random.seed() 利用随机数种子,指定了一个随机数生成的起始位置,使得每次生成的随机数相同
#这样每次验证程序时更容易发现问题
def split_train_test(data,test_ratio=0.2):
shuffled_indices=np.random.permutation(len(data)) #洗牌指数shuffled_indices 随机排列序列
test_set_size=int(len(data)*test_ratio)
test_indices=shuffled_indices[:test_set_size] #0-test_set_size 为测试集行号(随机排列的前test_set_size个)
train_indices=shuffled_indices[test_set_size:] #test_set_size-len(data)
return data.iloc[train_indices],data.iloc[test_indices] #iloc函数:通过行号来取行数据(如取第二行的数据)
train_set,test_set=split_train_test(housing,0.2)
print(len(train_set),"train+",len(test_set),"test")
方式2:根据hash的最后字节来放置数据
哈希值(hash values)是使用哈希函数(hash function)计算得到的值。哈希函数是是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。就是根据数据内容计算得到相应的"摘要",根据这个摘要可以区分该数据与其他数据。
from zlib import crc32
def test_set_check(identifier,test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio*2**32
def split_train_test_by_id(data,test_ratio,id_column):
ids=data[id_column]
in_test_set=ids.apply(lambda id_:test_set_check(id_,test_ratio))
return data.loc[~in_test_set],data.loc[in_test_set] #loc函数:通过行索引 "Index" 中的具体值来取行数据(如取"Index"为"A"的行)
housing_with_id=housing.reset_index()
train_set,test_set=split_train_test_by_id(housing_with_id,0.2,"index")
print(len(train_set),"train+",len(test_set),"test")
方式3:使用稳定特征(经纬度组合)作为ID
from zlib import crc32
def test_set_check(identifier,test_ratio):
return crc32(np.int64(identifier)) & 0xffffffff < test_ratio*2**32
def split_train_test_by_id(data,test_ratio,id_column):
ids=data[id_column]
in_test_set=ids.apply(lambda id_:test_set_check(id_,test_ratio))
return data.loc[~in_test_set],data.loc[in_test_set] #loc函数:通过行索引 "Index" 中的具体值来取行数据(如取"Index"为"A"的行)
# 使用稳定特征
#将经纬度组合作为主键
housing_with_id["id"] = housing["longitude"] * 1000 + housing["latitude"]
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "id")
print(len(train_set),"train+",len(test_set),"test")
test_set.head()
方式4:直接使用sklearn提供的函数
# 我们可以直接使用sklearn提供的函数
from sklearn.model_selection import train_test_split
train_set,test_set=train_test_split(housing,test_size=0.2,random_state=42)
print(len(train_set),"train+",len(test_set),"test")
test_set.head(20)
以上方法均为随机抽样,分析具体数据时可能有必要进行分层抽样划分数据集
分层抽样
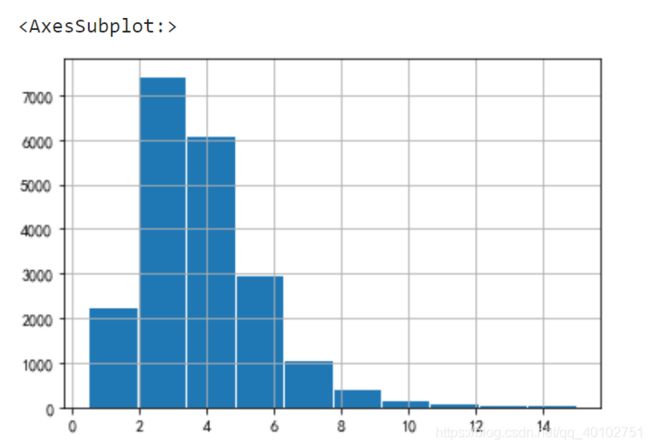
housing["median_income"].hist(edgecolor="white")
#收入中位数范围0.5-15,分10份
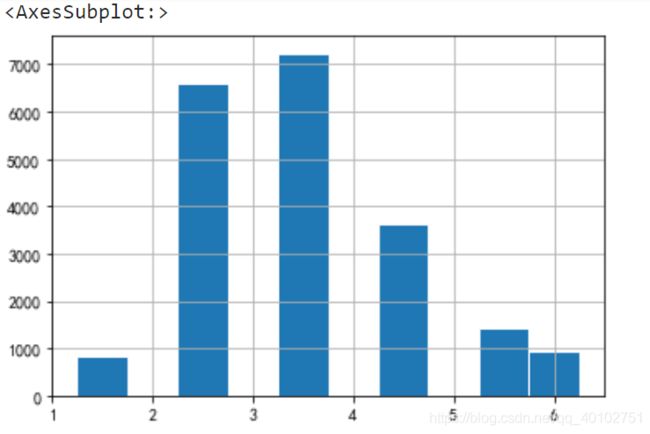
housing["income_cat"] = pd.cut(housing["median_income"], #income_cat
bins=[0, 1.5, 3., 4.5, 6., 7.5, np.inf], #分层界限
labels=[1, 2, 3, 4, 5, 6]) #层编号
#bins=[0, 1.5, 3., 4.5, 6.,7.5, 9., 10.5, 12., np.inf], #分层界限
#labels=[1, 2, 3, 4, 5, 6, 7, 8, 9 ]) #层编号
housing["income_cat"].hist(edgecolor="white",align="right")
housing.head()
# 根据收入进行分层抽样
from sklearn.model_selection import StratifiedShuffleSplit #分层抽样函数
split=StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42) # n_splits是将训练数据分成train/test对的组数
for train_index,test_index in split.split(housing,housing["income_cat"]):
strat_train_set=housing.loc[train_index] #分层训练集
strat_test_set=housing.loc[test_index] #分层测试集
print(len(strat_train_set),len(strat_test_set))
验证分层划分训练集和测试集的效果
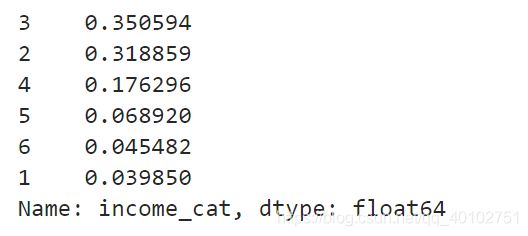
strat_train_set["income_cat"].value_counts()/len(strat_train_set) #训练集每层的平均收入 按大小降序
strat_test_set["income_cat"].value_counts()/len(strat_test_set) #测试集每层的平均收入

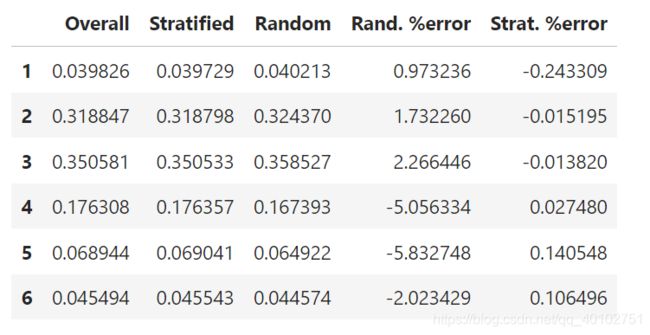
比较分层抽样和随机抽样,测试集的样本比例分布和完整数据集的差异
def income_cat_proportions(data):
return data["income_cat"].value_counts() / len(data)
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)
compare_props = pd.DataFrame({
"Overall": income_cat_proportions(housing),
"Stratified": income_cat_proportions(strat_test_set),
"Random": income_cat_proportions(test_set),
}).sort_index()
compare_props["Rand. %error"] = 100 * compare_props["Random"] / compare_props["Overall"] - 100
compare_props["Strat. %error"] = 100 * compare_props["Stratified"] / compare_props["Overall"] - 100
compare_props
github源码
源码内容包含整章,本文单独摘出部分内容理解细节