3D模型的生成式AI
生成式 AI 席卷了 2022 年,我们最近决定 Physna 不应错过这个热点。 因此,尽管生成 AI 并不是我们的商业模式—Physna 是一家 3D 搜索和分析公司,专注于 AR/VR 和制造中的工程和设计应用—我们还是决定为 3D 模型和场景生成 AI 构建一个非常基本的原型,由三名工程师进行为期两周的冲刺。 为什么?
1、生成式AI与3D
随着 Metaverse、增强现实、虚拟现实和混合现实变得更加主流,3D 内容消费将急剧增加。 这增加了对 3D 内容的需求,并为 3D 创作者提供了千载难逢的机会。 生成式AI——如果使用得当和公平——有可能大大提高创作者的生产力。 我们相信,通过克服 3D 数据固有的复杂性问题,我们可以释放 3D 的最大优势:它的数据非常丰富。 这可能意味着可以使用相当少量的 3D 模型来创建或影响全新生成的模型。 换句话说:创作者自己过去的作品可以用于新作品的开发。 这将使 3D 模型和场景不仅对用户更有价值,而且可以克服与使用第三方数据相关的风险。
尽管有机会和巨大的潜力,生成 AI 比其他地方需要更长的时间才能达到 3D:
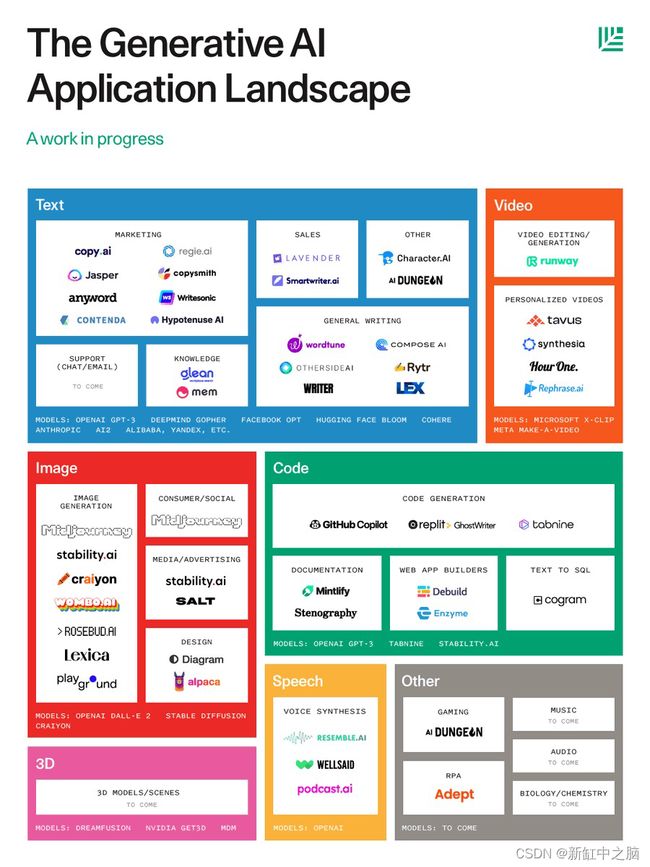
红杉资本对生成式 AI 应用程序的概览展示了一系列公司生成从创意文本到视频、代码和图像的一切内容。 但作为一家专注于 3D 的科技公司,Physna 引起我们注意的是那个空的粉红色盒子:用于 3D 模型和场景的生成 AI 是唯一留空的盒子。
那么,是什么让生成式 AI 在 3D 中如此困难,而它在其他地方发展得如此之快?
2、3D模型生成式AI的挑战
问题 1:3D 模型……很复杂
一个问题是 3D 本身的复杂性所固有的:模型传统上很难创建,存在各种不兼容的格式中,令人惊讶的是,与 2D(文本、图像、视频、 ETC。)相比,越来越少的公司有能力专注于 3D,因为它在分析层面通常更难突破——更不用说生成 AI 了。
问题 2:缺乏标记的 3D 数据
谷歌的 DreamFusion 团队在他们 9 月份的文章中或许对另一个问题做了最好的总结:3D 数据不如 2D 数据多。 就像 Nvidia 最近宣布的 Magic3D 一样,Google 的 DreamFusion 团队使用了 NeRFs(神经辐射场),最好将其视为介于 2D 和 3D 之间的东西……考虑到这篇博文的“2.5D”。 它们也是空的“壳”,因为它们没有任何内部组件和几何形状。 这意味着拟不仅掌握的关于手头物体的信息更少,而且也更难得出关于是什么造就了它的结论。 因此,尽管在 NeRFs 上进行训练可能比使用 2D 更有益,但正如谷歌的 DreamFusion 团队指出的那样:NeRFs 根本不是真正的、带标签的 3D 模型的很好替代品。 这意味着,如果没有解决方案,在可预见的未来,生成式 AI 将无法在 3D 领域和其他领域发挥作用。
3、如何克服困难
我们意识到可以通过一种非常简单的方式克服 3D 数据稀缺的问题:Physna 拥有世界上最大的标记 3D 数据库,以及使用它的适当许可。 但考虑到生成式 AI 的计算成本,利用它来运行原型将是一种昂贵的方式。 相反,我们意识到更有价值的是简单地确定是否可以用比以前想象的少得多的 3D 数据在生成式 AI 中完成更多工作。
我们的假设很简单:对手头 3D 模型的更深入理解意味着需要更少的模型来实现可扩展且有意义的 3D 生成 AI。 毕竟,虽然 3D 的缺点是数据的复杂性,但优点是与 2D 图像等其他资产相比,这些 3D 模型的数据有多丰富。
这是一个我们认为非常适合解决的问题。 我们的整个业务都建立在我们的核心技术之上,该技术“编码”了 3D 模型——也就是说,它创建了一个数字“DNA”,以标准化的方式代表模型的几何形状、特征和属性。 这样做使我们能够确定所有模型如何相互关联——包括在子模型级别。 这个关系矩阵允许我们使用人工生成的标签以指数方式传播更多的标签(在两到三个数量级之间)。 而且这个标签系统不仅具有可扩展性,而且相当可靠,因为我们在创建过程中使用了两个步骤:
第 1 步:我们使用一组获得专利的确定性算法来创建模型“DNA”的第一层。 这会绘制出模型的每个属性、其确切的几何形状和特征,并对模型进行标准化。 这一步对于确保在精度是关键时不会错误识别看起来模糊的事物至关重要,并且它显示了每个特征或部分应该如何组合在一起。
第 2 步:然后,我们使用一组由深度学习增强的专有非确定性算法,这对于启用模型生成同样重要。 此步骤还确保在概念层面理解不同大小和形状的模型(即没有“匹配”的几何或属性)。
这两层的结合使我们能够深入了解每个模型、它与其他模型的关系、构成模型的特征/组件以及它们存在的其他位置。 这意味着对于训练中使用的每个 3D 模型或场景,我们可以学到更多——并使 3D 模型和场景生成更有效——所有这些都需要更少的数据。
3、3D模型生成式AI测试
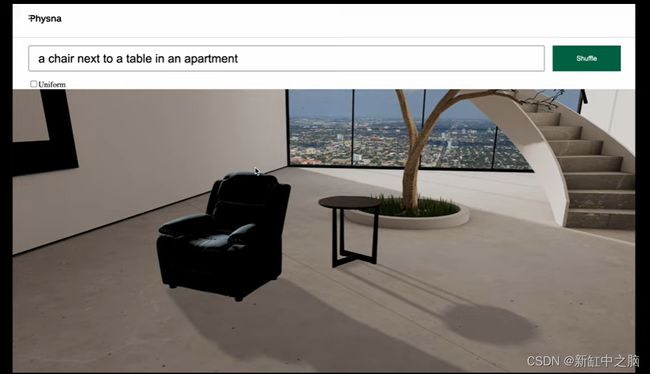
在我们生成芝士汉堡和纸杯蛋糕(我们喜欢食物)的 3D 模型的简短“阶段 1”之后,我们进入阶段 2 中更具挑战性的原型:场景生成。 毕竟,一旦可以同时生成模型和整个场景,你距离添加运动并创建你选择的整个“Metaverse”或混合现实世界的能力仅一步之遥(也许非常小)。
我们将我们的项目限制在 Amazon-Berkeley 库中的大约 8,000 个模型。 以任何标准来看,这都没有什么可训练的(二维稳定扩散最初训练了大约 6 亿张图像以进行比较)。 我们相信,通过首先分析上述模型,这个小数据集很有可能足以创建一个非常简单的原型。
我们提到的简单,确实意味着简单。 正如你在下面的视频中注意到的那样,这个原型仅限于家具。 展示的一些例子可能有点傻——比如在外太空沙发周围布置的花瓶——但重点是从中获得乐趣,看看有什么——如果有的话——可以由三名工程师在短短两周内完成,同时接受培训 8,000 个模型。
4、结束语
结果肯定比我们希望的要多。 从这些测试中得出的一个意外收获是,使用上述方法,3D 生成式 AI 中最困难的部分不是生成模型或场景本身,而是在较短的开发时间框架内克服相对简单的错误(如模型碰撞)。 虽然只使用如此小的数据集的决定肯定会限制原型的范围,但结果证明,3D 中的生成式 AI——无论是在对象还是场景级别——都可以利用 3D 模型中存在的庞大数据量。
这对最终用户来说是一个特别有希望的消息:即使是相对较小的数据集也足以极大地影响生成的模型。 这意味着个人和企业可以使用他们自己的模型来生成为他们量身定制的新 3D 资产。 3D 生成 AI 不仅可以作为设计师和创作者的力量倍增器,还可以让你牢记自己的风格和用例。
志愿参与这项工作的三位工程师正在休几天假来恢复体力,由于他们的努力和测试的积极结果,我们正在 Physna 积极扩大对 AI 的关注。
这篇文章的目的有两个:分享我们的发现和它们所带来的机会,并向任何可能有兴趣加入该团队的人工智能研究人员敞开大门。
原文链接:3D模型生成式AI — BimAnt