《InfoGAN: Interpretable Representation Learning》翻译
本文对《InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets》一文的主要内容进行翻译和记录。
1 引言
无监督学习可以被描述为从大量无标签数据中提取价值的问题。一个流行的无监督学习框架是表征学习(representation learning),其目标在于通过无标签数据学习表征,该表征能将重要语义特征阐述为易于解耦的因素(easily decodable factors)。能学习上述表征的方法对下游任务有帮助,如分类、回归、增强学习中的策略学习等。
由于在训练时相关下游任务是未知的,无监督学习实际上是不适定的(ill-posed)。但一种能显式表征数据显著属性的解耦表征(disentangled representation)对相关未知任务也是有帮助的。
生成模型研究推动了无监督学习的进展。因为人们相信生成观测数据的能力需要基于一定形式的理解,并且人们希望好的生成模型能自动学习解耦表征。尽管实际上任意糟糕的表征也能构建好的生成模型。(个人理解是,这里的任意糟糕的表征主要指常规GAN中采用随机噪声向量z生成数据,相比解耦表征,由于缺乏解释性,z其实是糟糕的表征)
本文对生成对抗网络进行了简单的修改,通过最大化GAN的噪声变量中的固定小子集和观测数据间的互信息,鼓励网络学习可解释和有意义的表征。尽管简单,该方法被证实在许多图像数据集上能发现具有高度语义的隐藏表征。本文无监督解耦表征的质量能和先前使用标签信息监督学习的方法相匹配。
2 相关工作
(具体参考文献不在这里赘述,详见原文)
目前已经存在很多无监督表征学习的研究。但先前解耦表征的研究主要基于监督学习(bilinear models、multi-view perceptron、adversarial autodecoders)。近期有提出一些弱监督学习方法(disBM、DC-IGN)以减少显式标签的需求。但其依然依赖可能无法获得的有监督数据分组。
与先前解耦表征方法不同,本文提出的InfoGAN不需要任何形式的监督。并且相比另一种只能解耦表征离散的隐藏特征的无监督学习方法hossRBM,InfoGAN能够解耦表征离散和连续的隐藏因素,且能拓展到复杂数据集,训练时间不多于常规GAN。
3 背景:生成对抗网络
常规GAN通过下式实现生成器和鉴别器的博弈:

(关于GAN的详细理论请参考原文及Goodfellow的文章,在此不做赘述)
4 引导隐藏编码的互信息
GAN中使用简单的连续噪声向量z,且对生成器使用噪声的方式没有约束。因此,生成器可能以高度纠缠的方式使用噪声,导致z的各维度与语义特征无法对应。
但很多领域会自然地分解出语义上有意义的变化因素。如生成MNIST数据集图像时,理想的情况是模型自动分配一个随机变量表示数字类型,并选择额外的两个连续随机变量表示数字角度和笔画粗细。这些属性都是独立且显著的,如果能够通过简单地指定MNIST数字由一个0-10 的变量和两个独立连续变量生成,从而无监督地恢复这些属性,将是很有用的。
本文将输入噪声分为两部分:(1) z,对应不可压缩(incompressible)的噪声 (2) c,称为隐藏编码(latent code),用来对应数据分布的显著结构化语义特征。 用![]() 表示结构化隐藏变量,
表示结构化隐藏变量, 表示所有隐藏变量的串联,并假设分布
表示所有隐藏变量的串联,并假设分布![]() 。
。
接着提出发掘隐藏因素的无监督方法,z和c均被提供给生成器,生成器形式变为![]() 。但对于标准GAN,生成器可以通过找到满足的
。但对于标准GAN,生成器可以通过找到满足的![]() 解从而忽略隐藏编码c。因此本文提出一种信息论正则化方法:隐藏编码c和生成器分布
解从而忽略隐藏编码c。因此本文提出一种信息论正则化方法:隐藏编码c和生成器分布![]() 必须具有较高的互信息
必须具有较高的互信息![]() 。
。
在信息论中,X、Y的互信息 I(X, Y) 衡量从随机变量Y的知识中学习到的关于另一个随机变量X的“信息量”。互信息可以表示为两个信息熵的差:
![]()
该定义具有直观的解释:I(X, Y) 是当Y被观测后X的不确定性的减少。若X、Y相互独立,则I(X, Y)=0。相反,若X、Y以一个特定的、可逆的函数相关联,将能获得最大互信息。在构建代价函数时,希望对给定的任意![]() ,
,![]() 具有较小的熵,即隐藏编码c的信息不应在生成过程中损失。因此给出含有信息论正则化的博弈:
具有较小的熵,即隐藏编码c的信息不应在生成过程中损失。因此给出含有信息论正则化的博弈:
![]()
5 变分互信息最大化(Variational Mutual Information Maximization)
在实践中,计算互信息![]() 需要知道
需要知道![]() ,因此很难直接最大化。但可以通过定义辅助分布
,因此很难直接最大化。但可以通过定义辅助分布![]() 估计
估计![]() ,从而获得互信息的下界。
,从而获得互信息的下界。
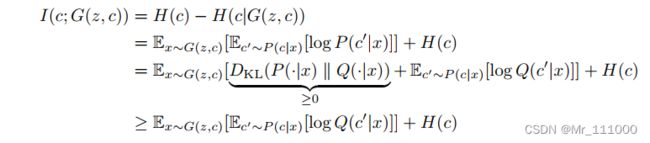
这种求互信息下边界的技术被称为变分信息最大化 (Variational Information Maximization)。尽管H(c)也可以优化,但本文简单起见,将H(c)视为常量。目前为止,避免了需要显式计算![]() 的困难,但仍然需要从内部期望的后验中采样。因此介绍引理用来移除从后验采样的要求。
的困难,但仍然需要从内部期望的后验中采样。因此介绍引理用来移除从后验采样的要求。
引理5.1:适当正则条件下的随机变量X,Y和![]() 有:
有:
![]()
基于引理,可以定义互信息的变分下界![]()
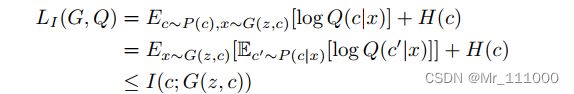
需要注意![]() 容易通过蒙特卡洛模拟来近似。此外
容易通过蒙特卡洛模拟来近似。此外![]() 可以直接关于Q最大化,且可以通过重参数技巧关于G最大化。因此
可以直接关于Q最大化,且可以通过重参数技巧关于G最大化。因此![]() 可以在不改变GAN训练过程的情况下加入到目标函数中。这样的算法称为信息最大化生成对抗网络(InfoGAN)。
可以在不改变GAN训练过程的情况下加入到目标函数中。这样的算法称为信息最大化生成对抗网络(InfoGAN)。
6 实现
实践中将辅助分布Q参数化为一个神经网络。在多数实验中,Q和D共享卷积层,在最后用一个全连接层输出条件分布![]() 的参数,这意味着InfoGAN实际上只给GAN增加了少量的计算量。此外本文还观察到
的参数,这意味着InfoGAN实际上只给GAN增加了少量的计算量。此外本文还观察到![]() 比常规GAN的目标更快收敛。
比常规GAN的目标更快收敛。
对于类别相关的隐藏编码 使用softmax来表示
使用softmax来表示![]() 。对于连续隐藏编码
。对于连续隐藏编码 的
的![]() ,根据
,根据![]() 后验的实际形式选择。在本文实验中发现简单地采用因子高斯分布(factored Gaussian)就足够了。
后验的实际形式选择。在本文实验中发现简单地采用因子高斯分布(factored Gaussian)就足够了。
InfoGAN引入的超参数 λ 很容易调整。对于离散的隐藏编码 λ 设为1就足够了,当隐藏编码包含连续变量时,通常选择较小的λ来确保![]() 与GAB的目标在同一尺度。
与GAB的目标在同一尺度。
考虑到GAN难以训练,本文基于DC-GAN介绍的技术进行实验。
7 实验
实验部分包括两个目标。第一个目标是研究算法是否可以有效地最大化互信息。第二个目标是研究InfoGAN是否可以学习到解耦的可解释的表征,具体是通过一次只改变生成器输入的一个隐藏因素并观察生成图像是否只产生对应的一个语义变化。
7.1 互信息最大化
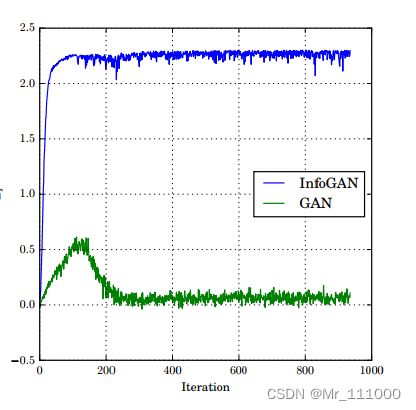
基于MNIST数据集训练InfoGAN,隐藏编码c服从均匀类别分布![]() 。图1中下界
。图1中下界![]() 迅速最大化到
迅速最大化到![]() ,意味着下界很紧,提出算法能实现最大化。
,意味着下界很紧,提出算法能实现最大化。
作为对照,还训练了一个具有辅助分布Q但没有互信息最大约束的常规GAN。同样用神经网络参数化Q,假设Q可以逼近后验![]() 。由图1可以看到,使用常规GAN,隐藏编码和生成图像几乎没有互信息(接近0)。说明在常规GAN中,无法保证生成器使用隐藏编码。
。由图1可以看到,使用常规GAN,隐藏编码和生成图像几乎没有互信息(接近0)。说明在常规GAN中,无法保证生成器使用隐藏编码。
 L下界
L下界
7.2 解耦表征
为了解耦MNIST的数字形状特征,采用以下方式对隐藏编码建模:一个离散的类别编码![]() ,和两个捕捉连续变量的编码,
,和两个捕捉连续变量的编码,![]() 。
。
图2表明离散编码确实捕捉到数字形状变化。更改 使得生成图像的数字发生变化。因此即使是无监督训练,也可以将用于分类。将与类别匹配,在分类MNIST数字式能实现仅5%的错误率。
使得生成图像的数字发生变化。因此即使是无监督训练,也可以将用于分类。将与类别匹配,在分类MNIST数字式能实现仅5%的错误率。
连续变量![]() 捕捉数字样式的连续变化:
捕捉数字样式的连续变化: 控制旋转程度,
控制旋转程度, 控制笔画宽度。为了检验InfoGAN学到的特征能否推广,以更夸张的方式改变隐藏编码,将其由从-2到2变化,而不是训练过程中见到的-1到1,结果仍然得到了有意义的推广,见图2。
控制笔画宽度。为了检验InfoGAN学到的特征能否推广,以更夸张的方式改变隐藏编码,将其由从-2到2变化,而不是训练过程中见到的-1到1,结果仍然得到了有意义的推广,见图2。
 图2 改动隐藏编码:每个数字表示生成器输入不同向量时生成的结果。每张子图中一列从上到下为输入不同隐藏编码和噪声产生的随机样本;一行中从左到右只改变只改变一个隐藏编码的值,其他值均不变。(a)一列包含5个相同c1的生成样本,一行中为改变c1不同值的生成样本。c1的每个类别基本对应一类数字。需注意(a)中的各列有出于可视化重新排列。因为无监督学习使得各数字类别和c1类别并不按顺序对应。(b)改变未经信息正则化训练的GAN的生成器输入的c1,会产生不可解释的变化。(c)一行中仅改变c2,发现c2越小生成数字越左倾,反之越右倾。(d)一行中仅改变c3,生成图像的笔画粗细平滑变化。
图2 改动隐藏编码:每个数字表示生成器输入不同向量时生成的结果。每张子图中一列从上到下为输入不同隐藏编码和噪声产生的随机样本;一行中从左到右只改变只改变一个隐藏编码的值,其他值均不变。(a)一列包含5个相同c1的生成样本,一行中为改变c1不同值的生成样本。c1的每个类别基本对应一类数字。需注意(a)中的各列有出于可视化重新排列。因为无监督学习使得各数字类别和c1类别并不按顺序对应。(b)改变未经信息正则化训练的GAN的生成器输入的c1,会产生不可解释的变化。(c)一行中仅改变c2,发现c2越小生成数字越左倾,反之越右倾。(d)一行中仅改变c3,生成图像的笔画粗细平滑变化。
此后在人脸图像、椅子图像、街景房屋编号(SVHN)图像、CelebA等三维图像数据集上评估算法。结果表明InfoGAN在无监督的情况下取得了媲美此前监督学习DC-IGN算法的效果。由于其验证与MNIST类似,这里就不再进一步翻译,详见原文。
8 结论
本文介绍了称为信息最大化生成对抗网络(Info GAN)的表征学习算法。和先前研究不同,Info GAN完全无监督,可以在复杂数据集上学习可解释和解耦的表征。此外Info GAN值在GAN的基础上增加了很少的计算量,且易于训练。该算法使用互信息来引导表征学习的核心思路也可以用于其他方法,很有研究前景。其他可能的改进包括:学习层次化的隐藏表征,改进半监督学习,使用Info GAN进行高维数据挖掘工具等。