python图像识别与自动分类_python学习-简单图像识别分类
python学习—图像识别
这是我从零基础开始学习的图像识别,当然用的是容易上手的python来写,持续更新中,记录我学习python基础到图像识别应用的一步步过程和踩过的一些坑。最终实现得到自己的训练模型(h5或者pb模型),可随意更改需要识别的物品,只要有数据就行。(若有错误或问题,肯请指正)
安装编译环境
此前确保已经安装并配置好了Python环境,在此我选择了比较流行的pycharm,具体安装教程网上很多,也比较简单。
安装所需库
我是利用了anaconda命令安装的,本项目所需用的库为:
keras、numpy、tensorflow2.0(我的是GPU版本),
GPU版本速度快但安装起来比较麻烦。
导包
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
一、接下来就是处理你的图片数据集
在这里我只提供了需要的函数,若果是自己的数据学要修改其中的变量,包括图片路径、传入参数等。
1.转换图片像素,使其大小一致
def read_image(paths):
os.listdir(paths)
filelist = []
for root, dirs, files in os.walk(paths):
for file in files:
if os.path.splitext(file)[1] == ".jpg":
filelist.append(os.path.join(root, file))
return filelist
def im_xiangsu(paths):
for filename in paths:
try:
im = Image.open(filename)
newim = im.resize((128, 128))
newim.save('F:/CNN/test/' + filename[12:-4] + '.jpg')
print('图片' + filename[12:-4] + '.jpg' + '像素转化完成')
except OSError as e:
print(e.args)
2.图片数据转化为数组
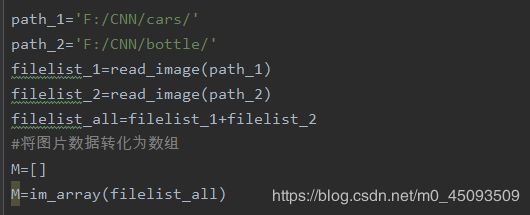
def im_array(paths):
M=[]
for filename in paths:
im=Image.open(filename)
im_L=im.convert("L") #模式L
Core=im_L.getdata()
arr1=np.array(Core,dtype='float32')/255.0
list_img=arr1.tolist()
M.extend(list_img)
return M
3.准备训练数据
dict_label={0:'汽车',1:'饮料瓶'}
train_images=np.array(M).reshape(len(filelist_all),128,128)
label=[0]*len(filelist_1)+[1]*len(filelist_2)
train_lables=np.array(label) #数据标签
train_images = train_images[ ..., np.newaxis ] #数据图片
print(train_images.shape)#输出验证一下(400, 128, 128, 1)
4.构建神经网络并保存
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(128, 128, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(2, activation='softmax'))#注意这里参数,我只有两类图片,所以是2.
model.summary() # 显示模型的架构
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#epochs为训练多少轮、batch_size为每次训练多少个样本
model.fit(train_images, train_lables, epochs=5)
model.save('my_model.h5') #保存为h5模型
#tf.keras.models.save_model(model,"F:\python\moxing\model")#这样是pb模型
print("模型保存成功!")
看一下准确度,还可以,但由于数据集太少,有可能会出现过拟合情况。

二、用上面得到的模型预测随便一张图片
新建一个py,直接放完整代码
import os
from PIL import Image
import numpy as np
import tensorflow as tf
#导入图像数据
#测试外部图片
model= tf.keras.models.load_model('my_model.h5')
model.summary() #看一下网络结构
print("模型加载完成!")
dict_label={0:'汽车',1:'饮料瓶'}
def read_image(paths):
os.listdir(paths)
filelist = []
for root, dirs, files in os.walk(paths):
for file in files:
if os.path.splitext(file)[1] == ".jpg":
filelist.append(os.path.join(root, file))
return filelist
def im_xiangsu(paths):
for filename in paths:
try:
im = Image.open(filename)
newim = im.resize((128, 128))
newim.save('F:/CNN/test/' + filename[12:-4] + '.jpg')
print('图片' + filename[12:-4] + '.jpg' + '像素转化完成')
except OSError as e:
print(e.args)
def im_array(paths):
im = Image.open(paths[0])
im_L = im.convert("L") # 模式L
Core = im_L.getdata()
arr1 = np.array(Core, dtype='float32') / 255.0
list_img = arr1.tolist()
images = np.array(list_img).reshape(-1,128, 128,1)
return images
test='F:/CNN/test/' #你要测试的图片的路径
filelist=read_image(test)
im_xiangsu(filelist)
img=im_array(filelist)
#预测图像
predictions_single=model.predict(img)
print("预测结果为:",dict_label[np.argmax(predictions_single)])
#这里返回数组中概率最大的那个
print(predictions_single)
最后结果
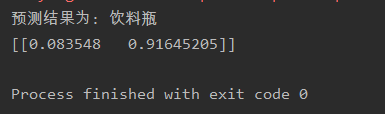
数组内的两个值分别表示为汽车和瓶子的概率大小。
三、总结
由于剩余时间有限,本项目用了两类图片汽车和瓶子进行训练预测,每类图片200张,共400张,所以很有可能出现过拟合,但增加数据集会在处理图片时耗费大量时间,所以我们尽量做个折中。一类几千张差不多就行。
图片数据不够的话可以扩充。
步骤:
1、调用上述函数,处理图片,我是把的所有图片的像素大小改成了128*128,
对应input_shape=(128, 128, 1)。
2、图片数据转成数组。
3、准备训练数据(train_images, train_lables)。
4、构建神经网络并保存模型
最后附一张我调用函数的流程: