论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测
论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测
原创 任峪瑾 CSIG文档图像分析与识别专委会
原文地址:https://mp.weixin.qq.com/s/5Yj9Vs2eCOYNAG_vellU2w
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第1张图片](http://img.e-com-net.com/image/info8/124d0f5b2ee641ddbe904633bcd27d87.jpg)
本文简要介绍PR 2021的论文“TextMountain: Accurate scene text detection via instance segmentation”的主要工作。本文提出了一种新颖的场景文本检测方法—TextMountain,TextMountain的核心思想是充分利用边界-中心信息,与先前将中心-边界视为二分类问题的工作不同,TextMountain对Text Center-border Probability(TCBP)和Text Center-direction(TCD)进行预测,TCD可以帮助TCBP更好地学习。TextMountain的标注规则不会导致角度变换时定义模糊的问题,因此该方法对多方向文本具有鲁棒性,并且还可以较好地处理弯曲文本。在MLT、ICDAR2015、RCTW-17和SCUT-CTW1500数据集上进行的实验表明,该方法在准确性和效率上都达到了更好或相当的性能。本文代码即将开源。
一、研究背景
场景文本检测是计算机视觉领域的研究热点之一,在生活中得到了广泛的应用。例如:图片和视频检索、自动驾驶和场景文本翻译等。场景文本在形状、尺寸、角度方面有很大的区别并且存在着复杂的背景,因此场景文本检测任务仍极具挑战性。
二、方法原理简述
TextMountain通过一个全卷积网络(FCN)生成分割图用来预测Text Score(TS)、Text Center-border Probability(TCBP)和Text Center-direction(TCD)。首先,设置一个阈值用来从TCBP和TS中生成文本中心实例图和文本边界图。然后用在TS上的平均分数计算每个文本中心实例的分数,文本中心可以分隔在TS中不容易分隔的文本行。接下来,文本边界图上的每个像素都按上升方向或直接使用TCD方向通过TCBP搜索其峰值。每个像素都朝着文本中心移动,直到到达一个文本中心,然后就认为该像素属于该文本中心。
作者用TCBP梯度对文本行分类,可以用TCD或TCBP来计算。与之前[1,2]中直接按比例扩大输出矩形的方法相比,达到了更好的效果,解决了曲线文本检测问题。预测出的TCBP如图1所示,文本行边界(山脚)和中心(山峰)像素点的值分别为0和1,从中心到边界像素值逐步递减。TCBP的上升方向可以用来对像素点进行分类,按TCBP的分类方式比之前TCB Binary的分类方式要更加平滑。除此之外,文章指出引入TCD预测有助于TCBP的学习。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第2张图片](http://img.e-com-net.com/image/info8/f14c3534112040df80fd71ed5d7d903a.jpg)
图1 Text Center-border Probability(TCBP)
图2是TextMountain的网络结构,由三部分组成:1) FPN[3]构成的主干网和一个特征融合网络, 2)TS、TCBP和TCD输出,3)后处理部分。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第3张图片](http://img.e-com-net.com/image/info8/8c86ee0856a1486e87f35f78be4a75b2.jpg)
图2 TextMountain整体网络结构
总体的损失函数如公式(1)所示,由TS、TCBP和TCD损失组成,其中![]() 和
和![]() 是TCBP和TCD损失的权重,分别设置为5和2.5。
是TCBP和TCD损失的权重,分别设置为5和2.5。
![]()
TS将每个像素点按文本和非文本进行分类。由于一张图中大部分像素点都是负样本,因此存在较严重的类别不平衡问题,本文采用Hard Negative Mining方法将正负样本比例设定为1:3,之后用交叉熵损失函数进行训练,如公式(2)所示。

之前的文本检测方法[1,2,4,5]把中心-边界问题定义成一个二分类问题,作者认为应该把中心-边界看作概率图,因为很难准确判断中心和边界,而且在TCBP中包含了更多的信息,概率增长的上升方向指向文本中心,这对像素分类很有用。下面介绍TCBP的计算方式。为了便于网络学习,作者提出了一种更简单的标注方式,只使用四条边的垂线来计算Label,如图3所示。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第4张图片](http://img.e-com-net.com/image/info8/17e5d96e47ec4d0da3cf934fd86c2d69.jpg)
图3 四条边的垂线计算Label
按式(3)近似计算文本高度
![]()
点x的TCBP由式(4)计算,TCBPX是[0,1]内的连续函数
![]()
TCBP的损失函数由式(5)计算,其中TS x *是TS的GT,该方法只需要计算文本区域内的损失
尽管TCBP中有足够的信息来对像素进行分组,但是作者发现网络可以通过预测TCD来实现更好的性能。TCD上的每个像素都将指向其所属的中心,方向向量如公式(6)所示,其中[z]+代表取z和0之间的最大值。

作者认为每侧都有推力将点推到中心,推力方向是从一边到另一点的垂线。越靠近点的位置,推力越大。如果距离大于高度的一半,则推力为零。两条相邻文本行的交点边缘上的像素具有相似的TCBP值但完全不同的TCD值,因此可以帮助分离相邻文本行。
TCD的损失函数也可以用L1 Loss来计算,如公式(7)所示,其中γ是中心阈值。值得注意的是,LTCD仅在边界区域有效,因为TCD可能会增加中心区域的歧义,并且TCD仅由边界像素进行推断。

对于SCUT-CTW1500数据集中的弯曲文本,本文也给出了标签计算的细节。SCUT-CTW1500数据集用14个顶点标记每个文本,其中七个顶点形成一条曲线。如图4所示,弯曲文本行也有四个侧面,其中两个侧面是弯曲的,并且线条的方向是顺时针方向。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第5张图片](http://img.e-com-net.com/image/info8/1f2de2c8a2184a94a54fcfbf0bc455c5.jpg)
图4 弯曲文本行标注图
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第6张图片](http://img.e-com-net.com/image/info8/c57c070ab78240c4a2f633a808c54273.jpg)
图5 弯曲文本行上边缘
实际上,曲线是平滑的并且线的角度逐渐变化,用有限点标注会导致突变。因此在计算标签之前,首先要平滑线的角度。以图5为例,一条边用7个点和6条线标注。![]() 是第
是第![]() 条线,
条线,![]() 和
和![]() 分别是
分别是![]() 的起点和终点。
的起点和终点。![]() 是第
是第![]() 条线的单位向量,
条线的单位向量,![]() 是第
是第![]() 个点上的单位向量,作者用该点临近线的均值作为
个点上的单位向量,作者用该点临近线的均值作为![]() 的值,如公式(8)所示。
的值,如公式(8)所示。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第7张图片](http://img.e-com-net.com/image/info8/55ab48073c4a4efa8cd31b63554d5268.png)
其他点的单位向量通过双线性插值计算,如公式(9)所示,其中![]() 是
是![]() 到
到![]() 的距离。
的距离。

![]() 与中心方向的夹角通过公式(10)计算得出,取单位向量角度后顺时针旋转90度使其指向中心。
与中心方向的夹角通过公式(10)计算得出,取单位向量角度后顺时针旋转90度使其指向中心。
![]()
弯曲文本的TCBP按照公式(11)和(12)进行计算,![]() 是待计算点x到文本行四条边最短直线的交点,
是待计算点x到文本行四条边最短直线的交点,![]() 是
是![]() 与x的距离。
与x的距离。
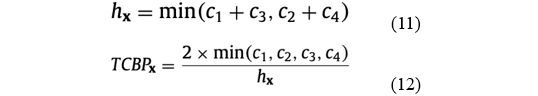
计算TCD之前,首先需要用公式(9)和(10)计算出![]() 的角度记作
的角度记作![]() ,然后按照公式(13)、(14)和(15)计算出TCD的值。
,然后按照公式(13)、(14)和(15)计算出TCD的值。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第8张图片](http://img.e-com-net.com/image/info8/557372b8271145769ab13448e1418562.jpg)
在得到TS、TCBP和TCD后,用大于中心阈值![]() 的TCBP来生成山峰图。下面需要预测山脚的像素属于哪个山峰。首先,可以通过TCBP或TCD生成有向图。对于TCBP,选择每个像素的8个邻居中的最大点作为下一个点;对于TCD,下一点的计算如公式(16)和(17)所示,其中
的TCBP来生成山峰图。下面需要预测山脚的像素属于哪个山峰。首先,可以通过TCBP或TCD生成有向图。对于TCBP,选择每个像素的8个邻居中的最大点作为下一个点;对于TCD,下一点的计算如公式(16)和(17)所示,其中![]() 是TCD预测向量的归一化结果。
是TCD预测向量的归一化结果。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第9张图片](http://img.e-com-net.com/image/info8/678c37a5b9104a7ca14f4af436fffa46.jpg)
生成定向图后,山脚上的每个像素都会逐步爬到对应的山峰,边界获得和中心相同的分割结果。每个点的方向都是确定的,因此可以并行有效地解决此任务,所有像素都可以同时爬到山上。在获得像素级分割结果之后,可以通过FindContours找到每个实例分割的轮廓。对于弯曲的文本,直接输出文本的轮廓;对于四边形的文本,通过MinAreaRect计算包围轮廓的最小区域的旋转矩形。
三、主要实验结果及可视化效果
作者对TextMountain中用到的TS、TCBP和TCD进行了消融实验,结果如表1所示。可以看出加入本文提出的TCBP和TCD方法,模型性能均有所提高。
表1 TextMountain的消融实验结果
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第10张图片](http://img.e-com-net.com/image/info8/70fb0595e2f24d1395c0b816d6414448.png)
同时作者在四个公开的数据集(MLT、ICDAR2015、RCTW-17和SCUT-CTW1500)上与之前的方法进行对比实验,均达到了更好或相当的结果,实验结果分别如表2~表5所示。特别是在MLT数据集上,F-measure达到了76.85%,大幅领先其他方法。
表2 TextMountain与其他方法在MLT数据集上的性能比较
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第11张图片](http://img.e-com-net.com/image/info8/865455d019564a478252a0e44cb7c1c4.jpg)
表3 TextMountain与其他方法在ICDAR2015数据集上的性能比较
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第12张图片](http://img.e-com-net.com/image/info8/4e92d72215de41e08fdabaea176fd336.jpg)
表4 TextMountain与其他方法在RCTW-17数据集上的性能比较
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第13张图片](http://img.e-com-net.com/image/info8/4ebafa329c004c139aafb2604bf1a569.jpg)
表5 TextMountain与其他方法在SCUT-CTW1500数据集上的性能比较
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第14张图片](http://img.e-com-net.com/image/info8/a13ad34568304747977abbbe6e272bfb.jpg)
TextMountain方法的一些可视化结果如图6所示,从左到右分别是来自MLT、ICDAR2015、RCTW-17和SCUT-CTW1500数据集的图片。
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第15张图片](http://img.e-com-net.com/image/info8/ecaf6732eb24487392ae4d9108e505c8.jpg)
图6 TextMountain方法的可视化结果
![论文推荐| [PR 2021] TextMountain:基于实例分割的精准场景文本检测_第16张图片](http://img.e-com-net.com/image/info8/115260c7fa534cb8966ab49205218f83.jpg)
图7 TCBP(上)和TCB binary(下)的可视化比较
图7是TCBP方法TCB Binary方法比较的可视化结果,从左到右分别是:检测结果、TS图、TCBP或TCB binary分类图和中心-边界图,从图中可以观察到TCBP方法对于形状、角度和大小的变化具有鲁棒性。
四、总结及讨论
本文提出了一种新颖的文本检测方法—TextMountain。该方法使用TCBP准确定义中心和边界概率,并使用TCBP的梯度对文本行进行分组。所提出的方法在四边形标注的数据集(MLT、ICDAR2015、RCTW-17)和多边形标注的弯曲文本数据集(SCUT-CTW1500)上均达到了更好或相当的性能。相比于RCTW和ICDAR15,本文所提出的方法在MLT上获得了更好的结果。作者认为TextMountain是基于分割的方法,与回归方法必须覆盖文本行的长边和短边相比,分割方法仅需要覆盖文本行的短边,它只需要较小的感受野。因此,TextMountain在文本行较长的MLT数据集上可以实现更好的性能。但是ICDAR2015是英文文本数据集与MLT相比单词较短,分割方法没有优势。
五、相关资源
论文地址:https://doi.org/10.1016/j.patcog.2020.107336
项目地址:https://github.com/uunnhh/TextMountain
参考文献
[1] T. He, W. Huang, Y. Qiao, J. Yao, Accurate text localization in natural image with cascaded convolutional text network, (2016). arXiv:1603.09423
[2] Y. Wu, P. Natarajan, Self-organized text detection with minimal post-processing via border learning, in: Proc. ICCV, 2017.
[3] T.-Y. Lin, P. Dollár, R.B. Girshick, K. He, B. Hariharan, S.J. Belongie, Feature pyra- mid networks for object detection., in: CVPR, 1, 2017, p. 4.
[4] D. Deng, H. Liu, X. Li, D. Cai, PixelLink: detecting scene text via instance seg- mentation, in: Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He, J. Liang, East: an efficient and accurate scene text detector, in: Proc. CVPR, 2017, pp. 2642–2651.
原文作者:Yixing Zhu, Jun Du
撰稿:任峪瑾
编排:高 学
审校:殷 飞
发布:金连文
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。