【SegNeXt】语义分割中对卷积注意力设计的反思
目录
1.摘要
2.相关工作
2.1语义分割
2.2多尺度网络
2.3注意力机制
3.网络结构
3.1卷积编码器
3.2解码器
4.实验
个人总结:
论文链接:论文
代码链接:代码
论文发表于NeurIPS 2022,值得注意的是,在Transformer风很大的时候,有人提出卷积才是王道的idea,勇气可嘉!
1.摘要
论文提出一种简单的卷积神经网络结构用于语义分割任务。最近基于transformer机制的模型由于其自注意力机制在编码空间信息上的效率主导了语义分割领域。本文中,我们发现卷积注意力比transform中的自注意力更能有效的编码上下文信息,通过重新审视成功者在分割模型中所拥有的特征,我们发现了几个导致分割模型性能改进的关键组件。这促使我们设计一种使用廉价卷积运算的新型卷积注意力网络。 我们的SegNeXt网络在几个常见的数据集上都取得了 SOTA的效果,比如ADE20K,Cityscapes, COCO-Stuff, Pascal VOC, Pascal Context, iSAID。SegNeXt网络比EfficientNet-L2 w/ NAS-FPN在PascalVOC数据集上miou提升到了90.6%,并且只使用了其10%的参数量,平均而言,SegNeXt与最先进的方法相比,在具有相同或更少计算量的 ADE20K 数据集上实现了约 2.0% 的 mIoU 改进。
2.相关工作
2.1语义分割
通常的语义分割模型都可以被分成两部分:编码器和解码器。其中
编码器通常使用常用的分类网络(ResNet ResNeXt 、DenseNet),然而,语义分割与图像分类不同,是一种稀疏预测的任务,因此为分割量身定制的编码器出现,比如Res2Net , HRNet , SETR, SegFormer , HRFormer, MPViT ,DPT。
对于解码器,对于不同的任务会有不同种类,包括多尺度感知、多尺度分割、扩大感知域、增强边缘特征和获取上下文信息。
在本文中,我们总结了那些为语义设计的成功模型的特征分割并提出一个基于 CNN 的模型,命名为 SegNeXt。它将k×k卷积分解为一对k×1和1×k卷积。 尽管这项工作表明大卷积核在语义分割中很重要,它忽略了多尺度感受野的重要性,并没有考虑如何利用这些多尺度大核提取的特征以注意力的形式进行分割。
2.2多尺度网络
设计多尺度网络是计算机视觉中的热门方向之一。 用于分割模型中,多尺度模块出现在编码器 和解码器 部分。GoogleNet 是与我们的方法最相关的多尺度架构之一,它使用多分支结构实现多尺度特征提取。 另一项与我们有关的工作方法是HRNet 。 在更深的阶段,HRNet 还保留了高分辨率的特征,即与低分辨率特征聚合,以实现多尺度特征提取。
与以往的方法不同,SegNeXt 除了在编码器中捕获多尺度特征外,还引入了一种高效的注意力机制,并采用了更便宜、更大的核卷积。 这些使我们的模型能够实现比上述分割方法更高的性能。
2.3注意力机制
基础的注意力机制是一种自适应选择过程,旨在使网络专注于重要的部分。 一般来说,在语义上可以分为两类分割,包括通道注意力和空间注意力。 不同类型的注意游戏不同的角色。 例如,空间注意力主要关注重要的空间区域。不同的是,使用通道注意力的目标是让网络有选择地参与那些重要的对象,这在以前的工作中已经被证明是重要的。说到最近流行的vision transformers,他们
通常忽略渠道维度的适应性。
3.网络结构
3.1卷积编码器

对于编码器部分,我们使用了类似于ViT的,但与之不同的是,ViT使用的是自注意力机制,本文你设计了多尺度卷积自注意力机制(multi-scale convolutional attention (MSCA))。MSCA模块包含三个部分:总计局部信息的深度可分离卷积、获取多尺度上下文信息的多分支深度条带卷积、以及可联通不同通道之间信息的1*1卷积。1*1卷积的输出作为与MSCA的输入进行重新赋权重使用。公式表示如下:

i={0,1,2,3}代表不同分支,在每个分支中,我们使用两个深度条带卷积来近似标准具有大内核的深度卷积。 这里,每个分支的内核大小分别设置为 7、11 和 21。(为了模拟内核大小为 7 × 7 的标准 2D 卷积,我们只需要一对 7×1 和 1×7 卷积),这种条带卷积的优势主要有两个:一方面可以有效减少计算量,另一方面可以对窄长型的目标进行有效表征,比如行人和电线杆。
通过将多个MSCA模块进行序列拼接的方式即可得到MSCAN。MSCAN包含了4个阶段,尺寸分别为 H/4 × W/4 , H/8 × W/8 , H/16 × W/16 和 H/32 × W/32。每个阶段都通过3*3卷积核,stride为2的卷积运算和一个BN层进行下采样。

3.2解码器
分割网络中,编码器通常都是在ImageNet数据集上预训练得到的,因此获取高维的语义信息的解码头非常重要。本文中,我们调查了3种解码器。

1. 单纯的MLP结构:SegFormer
2. 基于CNN结构:ASPP , PSP ,DANet
3. SegNeXt结构:我们聚合了最后三个阶段的特征并使用轻量级Hamburger进一步模拟全局上下文信息。 结合我们强大的卷积编码器,我们发现使用轻量级解码器可以提高性能计算效率
与 SegFormer 不同,SegFormer 的解码器将 Stage 1 的特征聚合到第 4 阶段,我们的解码器仅接收最后三个阶段的特征。 这是因为我们的 SegNeXt基于卷积。 第1 阶段的特征包含太多低级信息,并且拉低性能。 此外,Stage 1 的操作带来了较大的计算量。 在我们的实验部分,我们将证明我们的卷积 SegNeXt 比最近最先进的基于编码器的 SegFormer 和 HRFormer更好。
4.实验
在ImageNet验证集和遥感数据集iSAID上表现SOTA
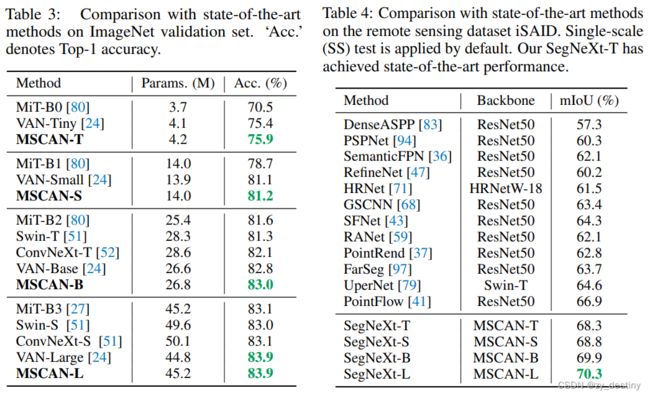
编码器在ImageNet上表现:


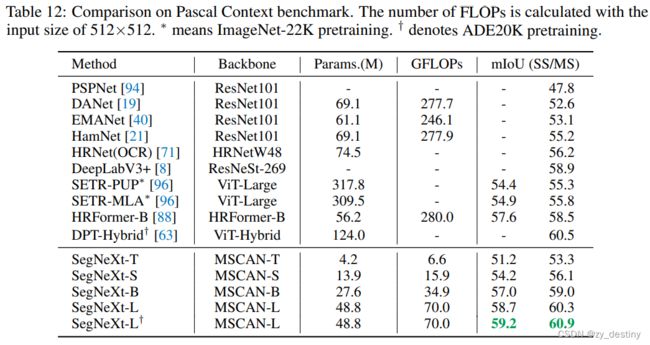
PascalVOC数据集上表现:

个人总结:
精妙的编码器结构(MSCAN),采用不同于自注意机制的多尺度注意力机制方法进行编码,一方面可以得到多尺度特征和融合上下文信息的目的,另一方面减少了计算量。
整理不易,欢迎一键三连!!!