基于中国剩余定理的秘密共享方案(Python实现)
说明
这是某电网信院的密码学实验3
一、实验目的(包括实验环境、实现目标等等)
1、实验环境:Windows11
- Windows11
- PyCharm2019.3.3 x64
2、实现目标:
- 通过编写代码实现基于中国剩余定理的秘密共享方案,加深对中国剩余定理的理解,体会中国剩余定理在解决实际问题的价值;
- 将密码学和数学知识相联系,并灵活运用到密码学的设计方案中;
- 提高实践能力和逻辑思维能力。
二、方案设计(包括背景、原理、必要的公式、图表、算法步骤等等)
1、背景
1983年,ASMUTH和BLOOM提出基于中国剩余定理的(t,n)门秘密共享方案。
2、原理
(t,n)门秘密共享方案:将秘密k分成n个子秘密k1, k2, …, kn,满足下面两个条件:
- 如果已知任意t个ki值,易于恢复出k;
- 如果已知任意t - 1个或更少个ki值,不能恢复出k。
3、公式
(t,n)门限,一个秘密k,被分割成n个子秘密(di, ki )
对于某个秘密k,计算
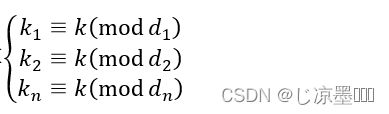 则子秘密为(di, ki )。
则子秘密为(di, ki )。
-
要求1: n个整数d1, d2, …, dn,满足
- d1
- (di, dj)=1, i ≠ j,两两互素;
- N=d1×d2×…×dt, M=dn-t+2×dn-t+3×…×dn,有N>M。t个最小的di的乘积严格大于t-1个最大的di的乘积
- d1
-
要求2:N>k>M,任选t个(di1, ki1), (di2,ki2 ), ⋯, (dit, kit),恢复出秘密k:
计算

恢复出秘密x ≡ k(mod N1),N1 = di1, di2, …, dit。
任选 t - 1 个(dj1, kj1), (dj2, kj2), ⋯, (djt-1, kjt-1) ,x ≡ k(mod M1),M1 = dj1, dj2, …, djt-1。t个子秘密能恢复出秘密,t-1个子秘密不能。
N1 > N > k > M > M1
4、中国剩余定理
设正整数m1,m2,…,mk两两互素,对任意整数a1,a2,…,ak,一次同余方程组
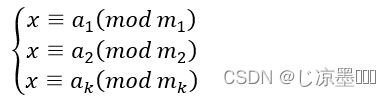 在模m意义下有唯一解,该解表示为
在模m意义下有唯一解,该解表示为
x = M1M1-1a1 + M2M2-1a2 + … + MkMk-1ak(mod m),
其中m = m1m2…mk, Mj = m / mj, MjMj-1 = 1(mod mj), j = 1, 2, …, k
5、算法步骤
(1)读入文件中500位左右的大整数,作为秘密k;
(2)随机生成5个d值;
(3)计算N,M值并输出;
(4)计算ki ≡ k(mod di);
(5)任选3组子秘密,利用中国剩余定理进行恢复;
(6)将原秘密与恢复得到的相比,分析是否恢复正确。
三、方案实现(包括算法流程图、主要函数的介绍、算法实现的主要代码等等)
1、流程图
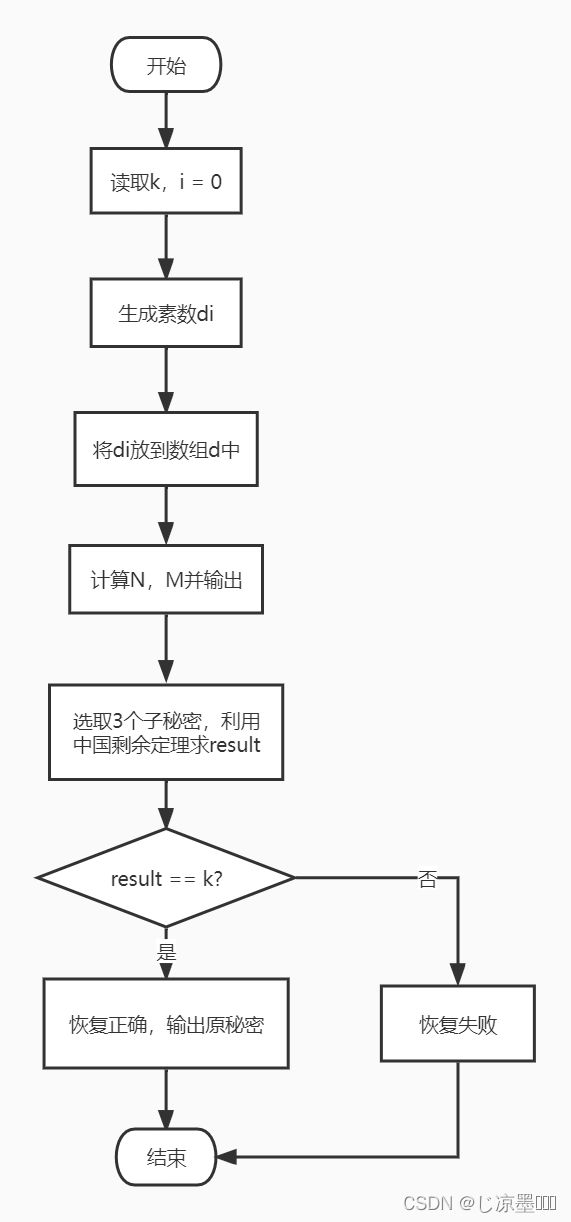
2、主要函数
(1)gad(a, b):求参数a和参数b的最大公约数,采用欧几里得算法;
(2)findModReverse(a, m):扩展欧几里得算法求模逆;
(3)fun():计算N和M;
(4)ChineseSurplus():利用中国剩余定理求解方程;
(5)find_d():产生符合条件的di值(利用随机数),然后将产生的di放入到数组d中;
(6)judge_d():定义数组d。
3、Python代码
import random
def gcd(a, b):
if b == 0:
return a
else:
return gcd(b, a % b)
def findModReverse(a, m):
if gcd(a, m) != 1:
return None
u1, u2, u3 = 1, 0, a
v1, v2, v3 = 0, 1, m
while v3 != 0:
q = u3 // v3
v1, v2, v3, u1, u2, u3 = (u1 - q * v1), (u2 - q * v2), (u3 - q * v3), v1, v2, v3
return u1 % m
def divresult(m):
Mj = [1, 1, 1, 1, 1, 1, 1, 1, 1]
for i in range(0, len(m)):
for j in range(0, len(m)):
if i == j:
Mj[i] = Mj[i] * 1
else:
Mj[i] = Mj[i] * m[j]
return Mj
def fun(d, t):
N = 1
M = 1
for i in range(0, t):
N = N * d[i]
for i in range(len(d) - t + 1, len(d)):
M = M * d[i]
return N, M
def findk(d, k):
k1 = [1, 1, 1, 1, 1, 1, 1]
for i in range(0, len(d)):
k1[i] = k % d[i]
k1 = k1[0:len(d)]
return k1
def ChineseSurplus(k, d, t):
m = d[0:t]
a = k[0:t]
flag = 1
m1 = 1
for i in range(0, len(m)):
m1 = m1 * m[i]
Mj = divresult(m)
Mj1 = [0, 0, 0, 0, 0, 0, 0]
for i in range(0, len(m)):
Mj1[i] = findModReverse(Mj[i], m[i])
x = 0
for i in range(0, len(m)):
x = x + Mj[i] * Mj1[i] * a[i]
result = x % m1
return result
def judge_d(m, num):
flag = 1
for i in range(0, num):
for j in range(0, num):
if (gcd(m[i], m[j]) != 1) & (i != j):
flag = 0
break
return flag
def find_d():
d = [1, 1, 1, 1, 1]
temp = random.randint(pow(10, 167), pow(10, 168))
d[0] = temp
i = 1
while i < 5:
temp = random.randint(pow(10, 167), pow(10, 168))
d[i] = temp
if judge_d(d, i + 1) == 1:
i = i + 1
return d
k = int(input("请输入秘密k:"))
d = find_d()
print("数组d为:")
print(d)
N, M = fun(d, 3)
print("N的值为:")
print(N)
print("M的值为:")
print(M)
k1 = findk(d, k)
result = ChineseSurplus(k1, d, 3)
print("最后恢复的明文为:")
print(result)
if result == k:
print("恢复正确!")
else:
print("恢复错误!")
四、数据分析(包括算法测试数据的分析,运行结果截图等等)
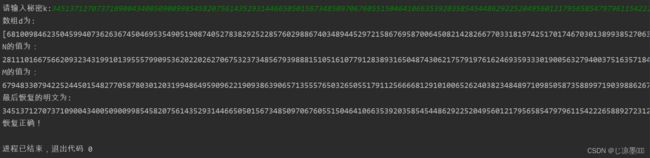
1、测试数据1(secret1)
34513712707371090043400509009985458207561435293144665050156734850970676055150464106635392035854544862922520495601217956585479796115422265889272312112460676286676002639176428018428110501603858423653391913799566813168343496159580747338826480697660522927181825310390154470363345038219192650075737129895819591216748784152267758174110791876279446873375543750375483617833468974263170064305100280485303368221268987883665789183494148190239289344532645805573919693262044556121484486211305720303265273494061665
运行截图:
2、测试数据2(secret2)
17478026666831342165607225368616063321718469751086098129424513844183358424079116995431214409628223777290633100657385400167527602481955811267190102034135644678975332538402411252204599772483146656099060144969961437110041474027934832041351813583159652034964431257857287075228427404692047523442305548984024079911564277739000132521183888591292001268001699186206357791036971642713788106200272066299890847864165018226431988593865501936053961710499420525798158420768632815038342235167689001130965331812773662
运行截图:
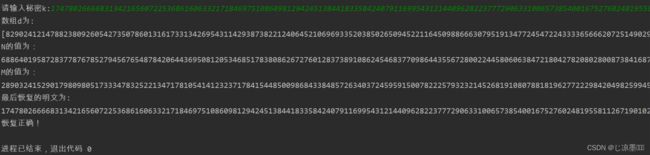
结论:通过多组测试数据验证,可以肯定的是程序时正确的,能够将秘密成功划分为多个子秘密,t个子秘密能恢复出秘密,t-1个子秘密不能。
五、思考与总结
1、在基于中国剩余定理的(t, n)秘密共享方案中,少于t个子秘密,是否能够正确恢复出秘密?请简述原因。
答:不能。关键在于N>k>M,如果模一个大于原秘密k的大数,则k就是k,算出来的结果不需要改动;但模一个小于或等于原秘密k的大数M,则算出来的结果是k % M,必定小于M(从而小于k),因此这样就得不到原秘密。