【大数据技术】Spark MLlib机器学习线性回归、逻辑回归预测胃癌是否转移实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
线性回归
过工具类MLUtils加载LIBSVM格式样本文件,每一行的第一个是真实值y,有10个特征值x,用1:double,2:double分别标注,即建立需求函数:
y=a_1x_1+a_2x_2+a_3x_3+a_4x_4+…+a_10x_10
通过样本数据和梯度下降训练模型,找到10个产生比较合理的参数值(a_1到a_10)
回归结果如下

部分代码如下 需要全部代码和数据集请点赞关注收藏后评论区留言私信
package com.etc
import org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object LinearRegressionDemo {
def main(args: Array[String]): Unit = {
//创建SparkContext
val conf = new SparkConf().setMaster("local[4]").setAppName("LinearRegression")
val sc = new SparkContext(conf)
sc.setLogLevel("error")
//加载数据样本
val path = "data1.txt"
//通过提供的工具类加载样本文件,每一行的第一个是y值,有10个特征值x,用1:double,2:double分别标注
//即y=a1x1+a2x2+a2x2+a3x3+a4x4+a5x5+a6x6+a7x7+a8x8+a9x9+a10x10
//-9.490009878824548 1:0.4551273600657362 2:0.36644694351969087 3:-0.38256108933468047 4:-0.4458430198517267 5:0.33109790358914726 6:0.8067445293443565 7:-0.2624341731773887 8:-0.44850386111659524 9:-0.07269284838169332 10:0.5658035575800715
val data: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, path).cache()
//迭代次数
val numIterations = 100
//梯度下降步长
val stepSize = 0.00000001
//训练模型
val model = LinearRegressionWithSGD.train(data, numIterations, stepSize)
//模型评估
val valuesAndPreds = data.map { point =>
//根据模型预测Label值
val prediction = model.predict(point.features)
println(s"【真实值】:${point.label} ;【预测值】:${prediction}")
(point.label, prediction)
}
//打印模型参数
println("【参数值】:"+model.weights)
//求均方误差
val MSE = valuesAndPreds.map{ case(v, p) => math.pow((v - p), 2) }.mean()
println("训练模型的均方误差为 = " + MSE)
sc.stop()
}
}
逻辑回归预测胃癌转移
建立随机梯度下降的回归模型预测胃癌是否转移,数据特征说明如下:
y:胃癌转移情况(有转移y=1;无转移y=0)
x1:确诊时患者的年龄(岁)
x2:肾细胞癌血管内皮生长因子(VEGF)其阳性表述由低到高共三个等级
x3:肾细胞癌组织内微血管数(MVC)
x4:肾癌细胞核组织学分级,由低到高共4级
x5:肾癌细胞分期,由低到高共4期。
预测结果如下
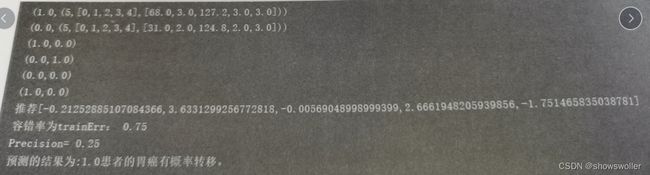
部分代码如下 需要全部代码和数据集请点赞关注收藏后评论区留言私信
package com.etc
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.classification.{LogisticRegressionWithLBFGS, LogisticRegressionWithSGD}
import org.apache.spark.mllib.evaluation.MulticlassMetrics
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.util.MLUtils
object LogisticRegressionDemo{
def main(args: Array[String]): Unit = {
//建立spark环境
val conf = new SparkConf().setAppName("logisticRegression").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("error")
//通过MLUtils工具类读取LIBSVM格式数据集
val data = MLUtils.loadLibSVMFile(sc , "wa.txt")
//测试集和训练集按2:8的比例分
val Array(traning,test) = data.randomSplit(Array(0.8,0.2),seed = 1L)
println(traning.count ,test.count)
traning.foreach(println)
//建立LogisticRegressionWithLBFGS对象,设置分类数 2 ,run传入训练集开始训练,返回训练后的模型
val model = new LogisticRegressionWithLBFGS()
.setNumClasses(2)
.run(traning)
//使用训练后的模型对测试集进行测试,同时打印标签和测试结果
val labelAndPreds = test.map{ point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
labelAndPreds.foreach(println)
println("推荐"+model.weights)
val trainErr = labelAndPreds.filter( r => r._1 != r._2).count.toDouble / test.count
println("容错率为trainErr: " +trainErr)
val predictionAndLabels = test.map{ //计算测试值
case LabeledPoint(label,features) =>
val prediction = model.predict(features)
(prediction,label) //存储测试值和预测值
}
val metrics = new MulticlassMetrics(predictionAndLabels) //创建验证类
val precision = metrics.precision //计算验证值
println("Precision= "+precision)
val patient = Vectors.dense(Array(20,1,0.0,1,1))
val d = model.predict(patient)
print("预测的结果为:" + d)
//计算患者可能性
if(d == 1){
println("患者的胃癌有几率转移。 ")
} else {
println("患者的胃癌没有几率转移 。")
}
}
}
创作不易 觉得有帮助请点赞关注收藏~~~