Redis高可用架构—Redis集群(Redis Cluster)详细介绍
前面文章Redis高可用方案—主从(masterslave)架构中我们了解了redis主从复制架构,知道了该模式的工作模式为提供多台redis服务,选择其中的一台作为master节点向外提供读写服务,剩下的作为slave节点从master节点复制数据,只向外提供读服务。并且在Redis高可用架构—哨兵(sentinel)机制详细介绍中引入了Redis哨兵,实现了对所有redis节点的监控和master的自动故障转移。一般情况下来说,上面两种方式结合起来使用已经可以满足大部分的redis高可用场景,但它有一个很明显的缺点:只有一台master节点向外提供写服务,其他的slave节点只能提供读服务。所以,当写操作并发量很大的,无法缓解写操作的压力。针对这种场景,Redis在3.0版本中引入了Redis集群的部署架构。
什么是Redis集群
Redis集群是一个提供在多个Redis节点之间共享数据的程序集。它并不像Redis主从复制模式那样只提供一个master节点提供写服务,而是会提供多个master节点提供写服务,每个master节点中存储的数据都不一样,这些数据通过数据分片的方式被自动分割到不同的master节点上。
为了保证集群的高可用,每个master节点下面还需要添加至少1个slave节点,这样当某个master节点发生故障后,可以从它的slave节点中选举一个作为新的master节点继续提供服务。不过当某个master节点和它下面所有的slave节点都发生故障时,整个集群就不可用了。这样就组成了下图中的结构模式:
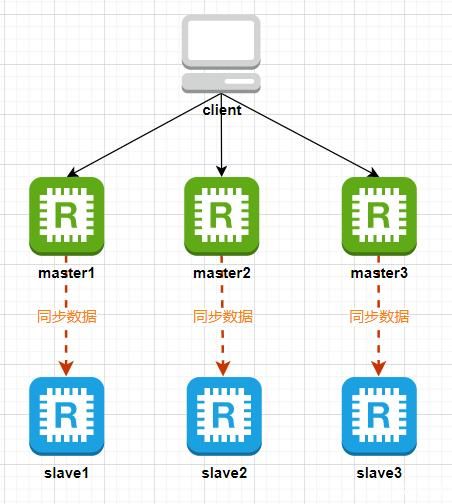
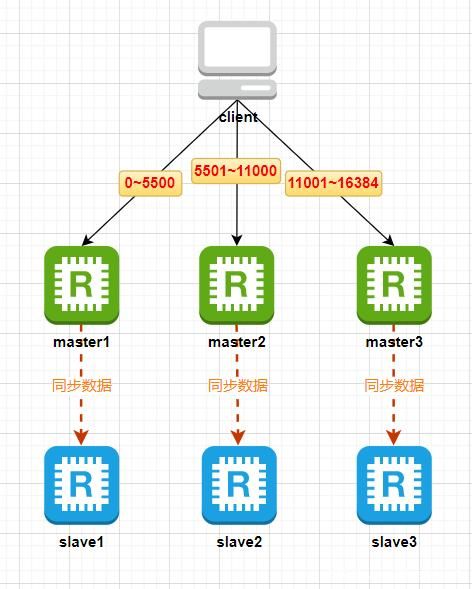
Redis集群中的哈希槽
Redis集群中引入了哈希槽的概念,Redis集群有16384个哈希槽,进行set操作时,每个key会通过CRC16校验后再对16384取模来决定放置在哪个槽,搭建Redis集群时会先给集群中每个master节点分配一部分哈希槽。比如当前集群有3个master节点,master1节点包含0~5500号哈希槽,master2节点包含5501~11000号哈希槽,master3节点包含11001~16384号哈希槽,当我们执行“set key value”时,假如 CRC16(key) % 16384 = 777,那么这个key就会被分配到master1节点上,如下图:
Redis集群中节点的通信
既然Redis集群中的数据是通过哈希槽的方式分开存储的,那么集群中每个节点都需要知道其他所有节点的状态信息,包括当前集群状态、集群中各节点负责的哈希槽、集群中各节点的master-slave状态、集群中各节点的存活状态等。Redis集群中,节点之间通过建立TCP连接,使用gossip协议来传播集群的信息。如下图:
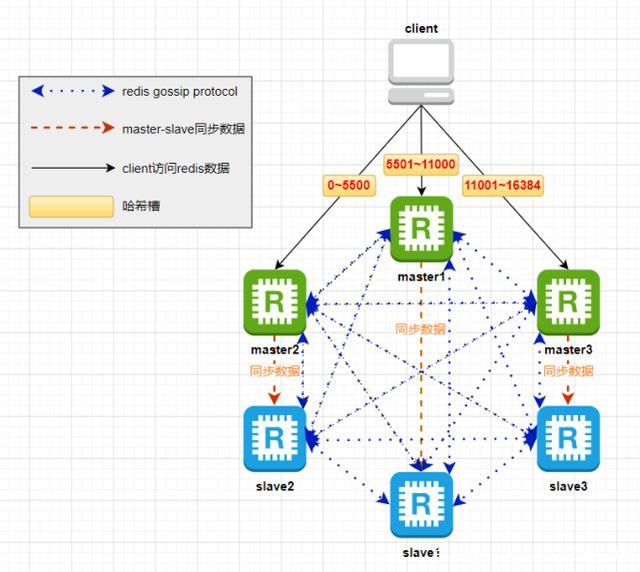
所谓gossip协议,指的是一种消息传播的机制,类似人们传递八卦消息似的,一传十,十传百,直至所有人都知道这条八卦内容。Redis集群中各节点之间传递消息就是基于gossip协议,最终达到所有节点都会知道整个集群完整的信息。gossip协议有4种常用的消息类型:PING、PONG、MEET、FAIL。
● MEET:当需要向集群中加入新节点时,需要集群中的某个节点发送MEET消息到新节点,通知新节点加入集群。新节点收到MEET消息后,会回复PONG命令给发送者。
● PING:集群内每个节点每秒会向其他节点发送PING消息,用来检测其他节点是否正常工作,并交换彼此的状态信息。PING消息中会包括自身节点的状态数据和其他部分节点的状态数据。
● PONG:当接收到PING消息和MEET消息时,会向发送发回复PONG消息,PONG消息中包括自身节点的状态数据。节点也可以通过广播的方式发送自身的PONG消息来通知整个集群对自身状态的更新。
● FAIL:当一个节点判定另一个节点下线时,会向集群内广播一个FAIL消息,其他节点接收到FAIL消息之后,把对应节点更新为下线状态。
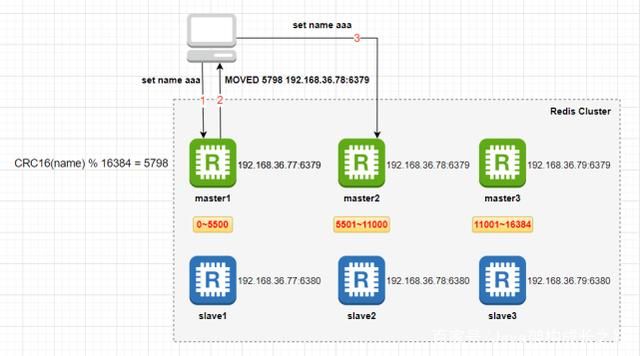
Redis集群的MOVED重定向
Redis客户端可以向Redis集群中的任意master节点发送操作指令,可以向所有节点(包括slave节点)发送查询指令。当Redis节点接收到相关指令时,会先计算key落在哪个哈希槽上(对key进行CRC16校验后再对16384取模),如果key计算出的哈希槽恰好在自己节点上,那么就直接处理指令并返回结果,如果key计算出的哈希槽不在自己节点上,那么当前节点就会查看它内部维护的哈希槽与节点ID之间的映射关系,然后给客户端返回一个MOVED错误:MOVED [哈希槽] [节点IP:端口]。这个错误包含操作的key所属的哈希槽和能处理这个请求的Redis节点的IP和端口号,例如“MOVED 3999 127.0.0.1:6379”,客户端需要根据这个信息重新发送查询指令到给定的IP和端口的Redis节点。
Redis集群的搭建及使用
要让集群正常运作至少需要3个master节点,为了高可用,每个master节点至少要有一个slave节点,所以我们就用3个master节点+3个slave节点来搭建集群。
首先准备三台虚拟机,并在每台虚拟机上安装好redis。我本地的三台虚拟机为:192.168. 31.77、192.168. 31.78、192.168. 31.79。如果本地还未安装过虚拟机,可以根据我之前的教程配置安装: VMware Workstation 14安装教程 、 虚拟机环境搭建(VMware Workstation14 + centos7) 、 VMware+CentOS7 网络及静态IP配置、 Linux安装Redis 。
以192.168.31.77这台虚拟机操作演示,拷贝出两份单独的redis配置文件,其中一个作为master节点的配置,一个作为slave节点的配置。
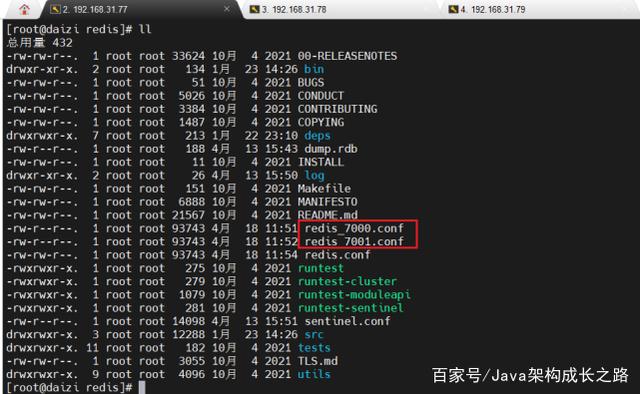
修改这两个配置文件,下面是一个集群需要的最少选项配置:
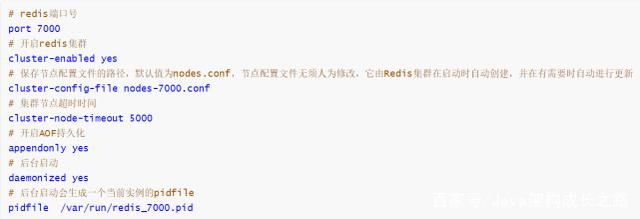
基于这两个配置文件分别启动一个redis实例:
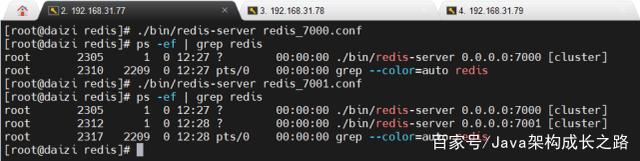
另外两台虚拟机执行同样的步骤启动好各自的两台redis实例。此时,我们就有了6台运行中的redis实例:
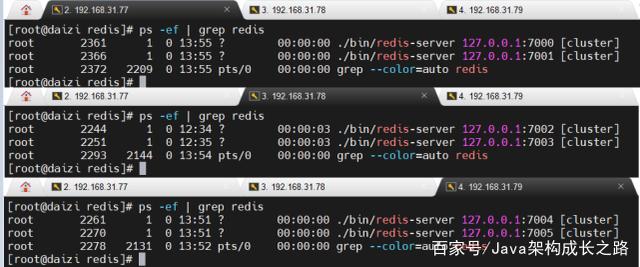
接下来我们需要使用这些实例来创建集群。在Redis3.x版本中,只能用redis-trib.rb程序来创建集群,redis-trib.rb是一个Ruby程序,使用前需要先配置Ruby环境。创建集群命令如下:
其中,--replicas 1 表示为集群中的每个master节点创建一个slave节点。Redis4.x版本后,Redis提供了另一种创建集群的方式,即使用 redis-cli 命令,该命令多了一个可以认证集群密码的功能,所以后来Redis就推荐使用 redis-cli 的方式来创建集群,命令如下:
其中,--cluster-replicas 1 表示为集群中的每个master节点创建一个slave节点。我们在任意一台虚拟机上执行上面的命令:
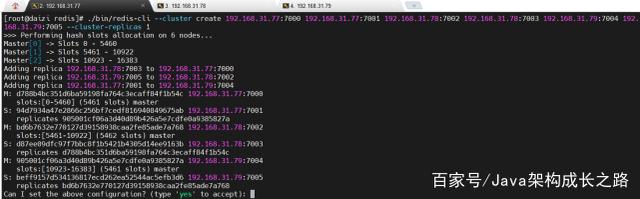
可以看到创建的集群信息,包括master节点及其哈希槽信息、slave节点信息。输入“yes”确认信息,即可看到集群创建成功:
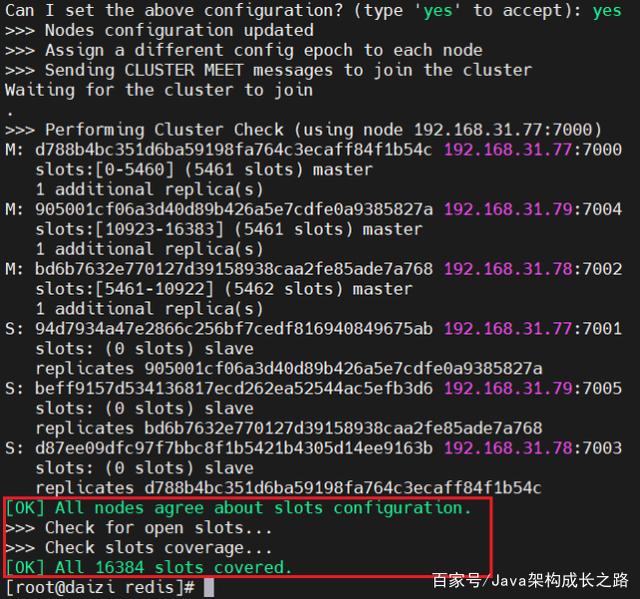
至此,我们的集群就创建好了,接下来就可以测试一下集群是否正常。在任意一台虚拟机上测试都可以,比如我们在192.168.31.77的master节点上添加一条数据,执行以下命令:

可以看到,当我们执行“set name aaa”的时候,自动重定向到了192.168.31.78:7002这台Redis实例中执行,而且也可以正常获取数据。
向Redis集群中添加新节点
如果我们要向上面运行的Redis集群中添加一个新节点,分两种情况:添加一个master节点,添加一个slave节点。这两种情况的第一步都是要新启动一个Redis实例,启动使用的配置文件与上面集群中的各节点的配置文件一致,只需要改一下port、cluster-config-file、pidfile三个选项的配置。此处,我们先在192.168.31.79虚拟机上启动一个端口号为7006的Redis实例。
●添加一个master节点:如果要添加一个master节点到集群中,需要执行以下命令:
./bin/redis-cli --cluster add-node 192.168.31.79:7006 192.168.31.77:7000
其中,第一个参数是新的Redis节点的IP和端口,第二个参数是任意一个已经存在的Redis节点的IP和端口。执行之后效果如下:
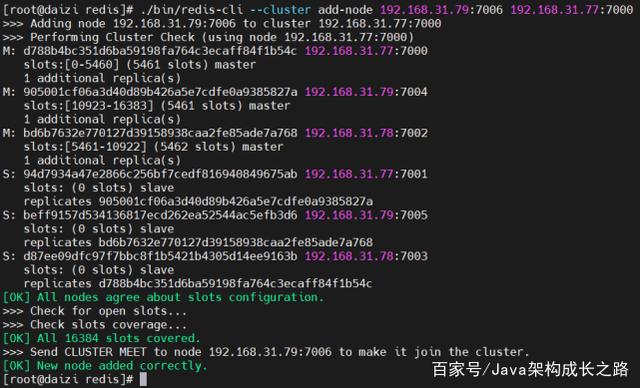
上面命令执行成功之后,新的节点就已经添加到集群中了,可以通过cluster nodes命令查看:

但此时,这个新的master节点上是没有分配任何哈希槽的,我们还需要使用下面命令重新分配master节点的哈希槽:
redis-cli --cluster reshard 192.168.31.79:7006 --cluster-from 已有节点id,多个id之间使用半角逗号分隔 --cluster-to 新节点id --cluster-slots 新节点的哈希槽数量
其中,节点id可以从cluster nodes结果中查看:

此处,我们需要将之前已存在的3个master节点上的部分哈希槽重新分配给新的节点,执行后结果如下:
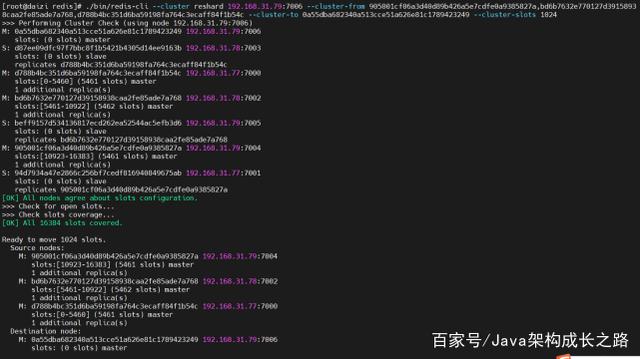
输入yes确认后,结果如下,可以看到哪些哈希槽被分配到了新节点:
此时,就可以用该节点操作数据了:

●添加一个slave节点:添加slave节点与添加master节点差不多,我们首先在一台虚拟机上启动一个端口为7007的Redis实例,然后执行下面的命令将该Redis实例添加到集群中:
./bin/redis-cli --cluster add-node --slave 192.168.31.79:7007 192.168.31.77:7000 --cluster-master-id 0a55dba682340a513cce51a626e81c1789423249
其中,--slave表示添加的是slave节点,192.168.31.79:7007是要添加的新节点,192.168.31.77:7000是集群中任意一个节点,--cluster-master-id后面跟的是新的slave节点要添加到哪个master节点下面,此处,我们将新的slave节点添加到192.168.31.79:7006这台master节点下。执行结果如下:
此时,cluster nodes结果中可以看到新的节点已经加入集群中了:

并且,使用新的节点也可以正常查询数据:

从Redis集群中移除节点
移除集群中某个节点也分两种情况:移除master节点和移除slave节点。
●移除master节点:由于master节点上分配的有哈希槽,所以当移除某个master节点之前,需要先将该节点上的哈希槽分配到其他节点上,然后在移除该节点。
首先通过下面命令重新分配哈希槽:
redis-cli --cluster reshard 192.168.31.79:7006
其中,192.168.31.79:7006表示要删除的master节点地址和端口。
然后,执行下面命令移除该节点:
redis-cli --cluster del-node 192.168.31.79:7006 节点id。
●移除slave节点:移除slave节点比较简单,直接执行下面命令移除即可:
redis-cli --cluster del-node 192.168.31.79:7007 节点id
其中,192.168.31.79:7007表示要删除的slave节点地址和端口,节点id表示该节点的id。