基于深度残差和特征金字塔网络的实时多人脸关键点定位算法--谢金衡
[1]谢金衡, 张炎生. 基于深度残差和特征金字塔网络的实时多人脸关键点定位算法[J]. 计算机应用, 2019, 39(12):6.
深度学习中关键点定位的方法有检测人脸再定位和直接热力图定位,检测人脸再定位导致时间成本增加,本文则剔除将人脸关键点生成对应的热力图作为标签,使用残差结构提取特征,使用特征金字塔融合多尺度特征,由粗到精一次性回归图中所有人脸关键点。该算法前向传播约需0.0075s,再WFLW测试集中取得了6.06%的平均误差和11.70%的错误率。
总之就是,1)使用热度图思想回归关键点;2)使用残差网络提取多尺度特征;3)用特质金字塔特征融合;4)中间监督网络辅助训练。
- 0、引言
- 1、本文方法
-
- 1.1、数据集预处理
- 1.2、关键点热度图
- 1.3、特征提取网络和特征融合
-
- 1.3.1、深度残差网络的改动
- 1.3.2、使用特征金字塔进行特征融合
- 1.4、预测
-
- 1.4.1、预测网络
- 1.4.2、Loss函数
- 2、实验与结果分析
-
- 2.1、数据增强
- 2.2、实验细节
- 2.3、评估结果
0、引言
大部分关键点定位都是先检测人脸,然后遍历每个人脸进行单人脸的关键点定位,人脸一多时间成本剧增。本文主要思想如下:
- 本文借鉴人体姿态估计算法中利用热度图回归人体关键的思想;
- 采用一个中间监督网络,由粗到精回归关键点(中继监督优化(intermediate supervision))
- 网络结构上使用特征金字塔网络融合不同尺度的特征。充分利用深浅层语义特征(特征金字塔:FPN(Feature Pyramid Networks)),减少卷积核的使用减少参数冗余
- 预测上分成了上半脸45个关键点预测分支和下半脸53个关键点预测分支。分支采用一级中间监督网络,更容易由粗到精回归。
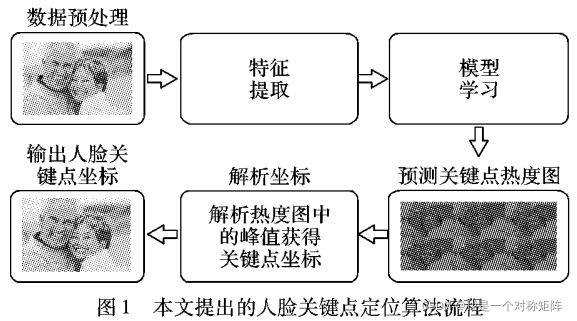
1、本文方法
基于热度图回归的模型是利用人脸关键点坐标生成关键点的概率分布热度,将坐标回归问题转化为热度图回归问题。总之该方法往往更容易训练,并且可以取得更好的效果。
本文采用WFLW数据集作为算法的训练集和测试集,为使网络更容易地学习关键点周围的概
率分布,降低单个预测网络拟合数据的难度,将人脸分为上、下两个部分,采用两个并行分支回归人脸关键点, 同时采用一个中间监督网络,驱使预测网络由粗到精地回归关键点热度图。
1.1、数据集预处理
本文使用WFLW数据集(来源于Wider Face人脸检测数据集)中有7500张标记了关键点(98点)的人脸作为训练集,2500张人脸作为测试集。
本文的算法没有经过人脸检测算法,一次回归图中出现的所有人脸的关键点,由于数据集中每张图片中只有部分人脸有标注,于是数据集中没有标注关键点的人脸成了训练中的干扰。 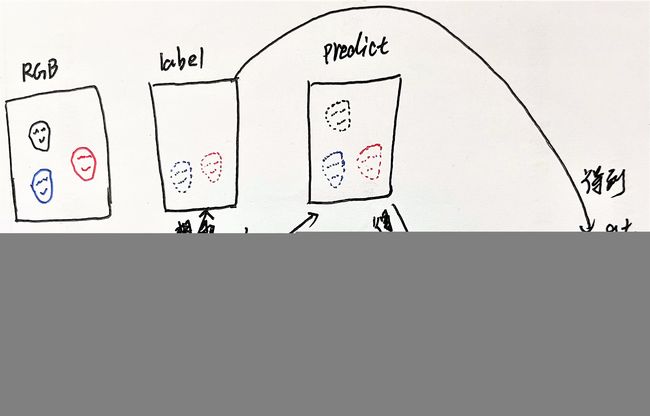
将这种没标注的区域称为噪声区域,作者的做法是该区域无论在预测图还是标注图中全部置0,让计算loss时,该区域不参与计算。
将预测出来的没有gt标注的人脸关键点去掉,比如上图中RGB图中有3个人脸,但是有关键点标注的只有2个脸,但是模型是能够把图像中所有人脸的关键点预测出来的,所有预测的有3个脸的关键点。所以根据没有标注的人脸的位置生成一个mask(未标注人脸区域value=0,其余value=1),与预测结果相乘,最终得到的结果是预测出了有gt的两个人脸关键点的位置,现在两个人脸的gt和预测值都知道了,就可以计算Loss了。
1.2、关键点热度图
模型的直接输出时热度图,而标签是数值型关键点位置,所以要将标签转化为gt热力图。
每个样本图像生成了100张48*48的关键点热度图(98+2,2张辅助热力图,类似边界关系,帮助更好回归位置)。
如果一个图中有3个脸,那么这三个脸都有98个关键点。对于第一张热度图,应当如下图所示,三个颜色方块表示模型预测出图像中所有人脸的第1个关键点的位置。
第n张热度图表示被预测图像中,所有人脸第n个关键点的为位置。所以会有98张热度图。

同时,本文将98个关键点分成了两部分,上分支46个关键点(标号33~75、96~97),下分支54个关键点(标号0~32,76~95)
1.3、特征提取网络和特征融合
本文算法采取深度残差网络,并结合特征金字塔网络来提取特征。
1.3.1、深度残差网络的改动
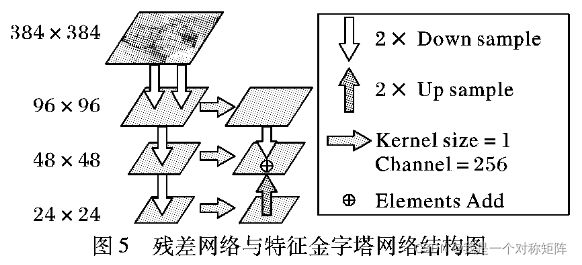
原始的残差网络如下图所示,本文的改动有二:1)将最开始的7*7卷积核修改为3*3卷积核;2)删除网络的第4个残差网络块和最后的全连接层,也即删除了最后的蓝色的卷积区块和全连接层。

网络的输入为384*384,三个残差网络块的输出尺寸为96*96、48*48、24*24,他们分别代表了网络在不同深度捕捉的不同大小感受野的图像特征,由此形成多尺度的特征金字塔
1.3.2、使用特征金字塔进行特征融合
我们通过残差网络得到特征金字塔,
- 高分辨率(浅层网络输出)输出更多细节特征,蕴含丰富的原始图像信息。细节特征帮助网络学习关键点区域具有何种几何特征,判断该区域是否存在该类关键点。
- 低分辨率(深层网络输出)学习到更多高级抽象特征,他们具有高感受野,包含全局信息,有助于网络进行关键点的定位。
由上可以看出,深浅特征一个帮助定位,一个帮助判断是否存在关键点。
如果要同时利用深浅特征,则使用特征金字塔来进行多尺度的特征融合。虽然也有其他方法多尺度特征的利用,但是特征金字塔能减少卷积核的使用,轻量化网络。
如下是特征融合结构图,左侧是残差网络原图+3个残差块的输出特征。不同于标准特征金字塔进行融合时是层层递进,本文是将将深浅层网络输出特征向中间尺寸融合。
1.4、预测
1.4.1、预测网络
结构如下:
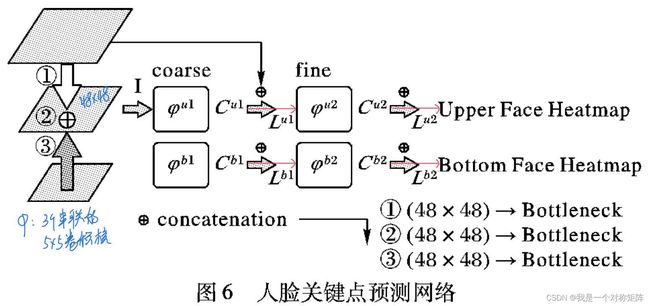
当我们得到一个融合的特征层 I I I时,它作为出入送入两个并行的分支,上分支负责上部分关键点的回归,下分支负责下部分关键点的回归。
这里介绍 φ 、 C 和 L φ、C和L φ、C和L:
- φ φ φ:代表操作,这里的φ应该是3个5*5的卷积核构成
- C C C:代表经过φ的输出
- L L L:表示在这里计算Loss
1.4.2、Loss函数

- C ∗ C^* C∗表示关键点标签, C u C_u Cu表示上部分关键点,同理 C b C_b Cb表示下部分关键点。
- ( p ) (p) (p)表示第p个关键点, ∑ p \sum_p ∑p表示对所有关键点的L2损失求和。
- t t t:∈{1,2},当t=1时即 L u 1 L^{u1} Lu1表示在第一级中间监督网络的输出(coarse的输出)上计算预测的上部分关键点值。
综上,上述的两个式子最终产生4个 L o s s = { L u 1 , L u 2 , L b 1 , L b 2 } Loss=\{L^{u1},L^{u2},L^{b1},L^{b2}\} Loss={Lu1,Lu2,Lb1,Lb2},这在图中也有标注。
则有 L t o t a l = ∑ t = 1 T ( L u t + L b t ) = L u 1 + L u 2 + L b 1 + L b 2 L_{total}=\sum^T_{t=1}(L^{ut}+L^{bt})=L^{u1}+L^{u2}+L^{b1}+L^{b2} Ltotal=t=1∑T(Lut+Lbt)=Lu1+Lu2+Lb1+Lb2
2、实验与结果分析
2.1、数据增强
- 随即旋转,θ∈[-45°,45°]
- 随即缩放,缩放因子范围为[0.8,1.3]
- 左右镜像,同时要对关键点顺序做镜像处理
- 随即裁剪,以中心沿四周裁剪为384*384
- WFLW有较多的模糊样本,所以还是用了随即角度的运动模糊与随机选取高斯核与方差进行的高斯模糊
2.2、实验细节
| item | detail |
|---|---|
| CPU | i7-8700 3.4GHz |
| RAM | 15GB |
| GPU | GTX1080 |
| 框架 | pytorch |
| 优化器 | Adam |
| 正则化 | 无 |
| 学习率 | 初始为0.0001,120轮后为0.00001 |
| batch size | 10 |
经过一天的实践迭代200轮后,损失在0.00015左右震荡。
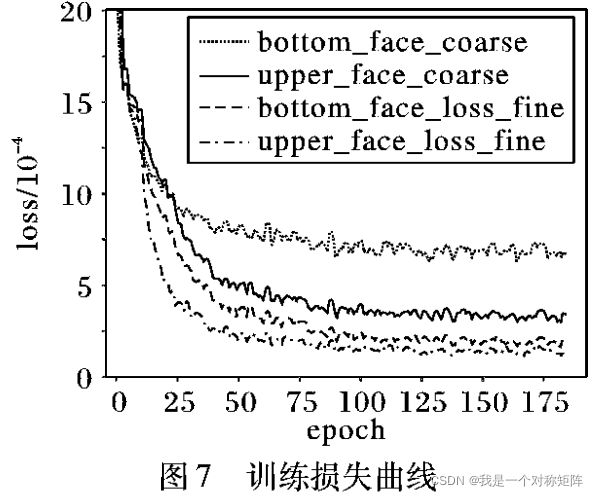
2.3、评估结果
WFLW的2500张测试集包括了Pose、Expression、Ilhimination、Make-up、Occlusion 与 Blur。
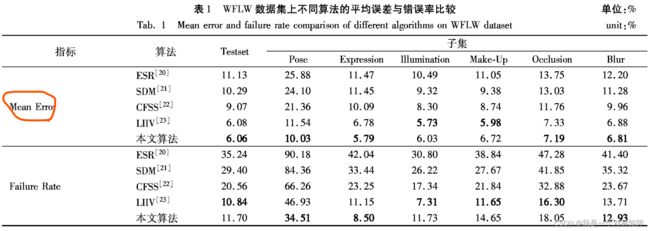
- ESR( ExplicitShape Regression)是通过形状回归的方法获得人脸矫正结果
- SDM( Supervised Descent Method)利用线性模型与尺度不变特征变换(Scale Invariant Feature Transform, SIFT)特征获得人脸矫正结果
- CFSS( Coarse to Fine Shape Regression) 也是通过形状回归的方法获得人脸矫正结果
- LIIV(Leveraging Intra and Inter-dataset Variations)旳则是利用数据集内与数据集间的某种变化来获得更好的人脸关键点定位效果
速度上的比较:
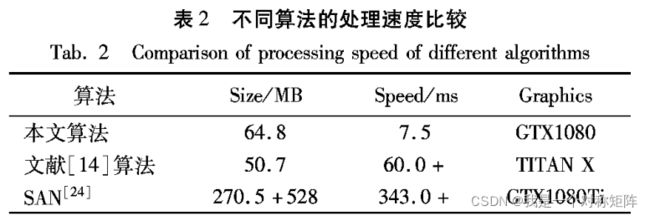
- SAN ( Style Aggregated Network) 是利用多阶段预测网络检测人脸关键点的方法