深度学习归一化方法总结(BN、LN、IN、GN)
目录
一、批量归一化 (BatchNorm)
二、层归一化(Layer Normalization)
三、Instance Normalization
四、Group Normalization
一般在神经网络中会用到数据的归一化,比如在卷积层后进行归一化然后再下采样然后再激活等。目前比较受欢迎的数据归一化层有:BN(Batch Normalization),LN(Layer Normalization),IN(Instance Normalization),GN(Group Normalization)这4种。本篇文章主要是对比一下它们各自是怎么计算的。
先看对数据的归一化是这么操作的。其实就是先计算均值和方差然后再标准化即可。具体的对一个标量数据![]() ,在给定的数据集
,在给定的数据集![]() 中进行标准化是按如下进行计算的:
中进行标准化是按如下进行计算的:
先计算给定数据集的均值和方差:
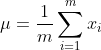
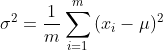
然后对这个数据集中的每个数进行标准化(归一化):
![]()
BN、LN、IN、GN这4种归一化方法的区别就是用于计算均值和方差的数据集不同。后面我以卷积层后跟归一化来举例,我叫需要进行标准化的值为一个像素点,那么数据集叫像素集。我们来看一下这4种方法它们计算均值和方差的像素集有什么区别。(蓝色区域即为该方法对应的计算一次均值和方差的像素集,当然最终是要将整个方块按区域划分分别进行一次归一化)。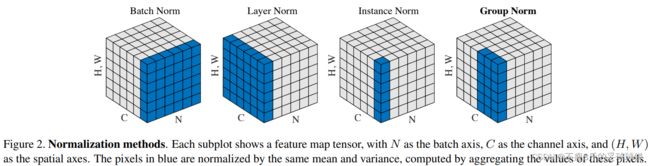
假如现在图像先进行了卷积运算得到如上图所示的激活状态(N,C,H,W),其中N是样本数,C为通道数即特征图数。
- BN:取不同样本的同一个通道的特征做归一化,逐特征维度归一化。这个就是对batch维度进行计算。所以假设5个100通道的特征图的话,就会计算出100个均值方差。5个batch中每一个通道就会计算出来一个均值方差。
- LN:取的是同一个样本的不同通道做归一化,逐个样本归一化。5个10通道的特征图,LN会给出5个均值方差。
- IN:仅仅对每一个图片的每一个通道最归一化。也就是说,对【H,W】维度做归一化。假设一个特征图有10个通道,那么就会得到10个均值和10个方差;要是一个batch有5个样本,每个样本有10个通道,那么IN总共会计算出50个均值方差。
- GN:这个是介于LN和IN之间的一种方法。假设Group分成2个,那么10个通道就会被分成5和5两组。然后5个10通道特征图会计算出10个均值方差。
一、批量归一化 (BatchNorm)
论文针对训练过程中容易出现的分布跳动问题引起的问题,提出了归一化的思路,为简化计算过程和实现难度,提出了批量归一化的思路。论文的神来之笔是 和
和 参数,在一定程度上实现了维持原数据特征的能力。
参数,在一定程度上实现了维持原数据特征的能力。
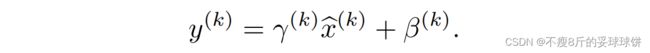
归一化算法思路:

论文要点
- 各个批次的数据分布最好一致,对大批次数据有效果,后人根据这个问题提出了小批次数据的改进算法
- 归一化能加速收敛速度
- 归一化与激活函数的位置其实也是一个值得讨论的问题,论文做了探讨
BN的操作是,对同一批次的数据分布进行标准化,得出的均值方差,其可信度受batch size影响。很容易可以想到,如果我们对小batch size得出均值方差,那势必和总数据的均值方差有所偏差。这样就解释了BN的第一个缺点:BN特别依赖Batch Size。
BN在大batchsize的情况下效果好,缺点是:
- BN特别依赖Batch Size;当Batch size很小的情况下BN的效果就非常不理想了。对于目标检测,语义分割,视频场景等,输入图像尺寸比较大,而限于GPU显卡的显存限制,导致无法设置较大的 Batch Size,如 经典的Faster-RCNN、Mask R-CNN 网络中,由于图像的分辨率较大,Batch Size 只能是 1 或 2。通常会有其他比较麻烦的手段去解决这个问题,比如MegDet的CGBN等
- BN对处理序列化数据的网络不太适用,如RNN,LSTM等,尤其当序列样本的长度不同时。So,BN的应用领域减少了一半。
- 训练集与测试集的分布。BN只在训练的时候用,BN处理训练集的时候,采用的均值和方差是整个训练集的计算出来的均值和方差 (这一部分没有看懂的话,可能需要去看一下BN算法的详解);inference的时候不会用到,因为inference的输入不是批量输入。所以测试和训练的数据分布如果存在差异,那么就会导致训练和测试之间存在不一致现象(Inconsistency)。
李宏毅老师关于batch normalization的视频讲解:
李宏毅深度学习(2017)_哔哩哔哩_bilibili https://www.bilibili.com/video/av9770302?p=10
二、层归一化(Layer Normalization)
LN是Hinton及其学生提出来的,论文链接:https://arxiv.org/abs/1607.06450v1
LN取的是同一个样本的不同通道做归一化,逐个样本归一化。
LN的操作类似于将BN做了一个“转置”,对同一层网络的输出做一个标准化。注意,同一层的输出是单个图片的输出,比如对于一个batch为32的神经网络训练,会有32个均值和方差被得出,每个均值和方差都是由单个图片的所有channel之间做一个标准化。这么操作,就使得LN不受batch size的影响。同时,LN可以很好地用到序列型网络如RNN中。同时,LR在训练过程和inference过程都会有,这就是和BN很大的差别了。
三、Instance Normalization
对于IN,它的一个像素集为一个特征图像素点集合,那么对于输入需要进行N×C次的归一化。
IN适用于生成模型中,比如图片风格迁移。因为图片生成的结果主要依赖于某个图像实例,所以对整个Batch进行Normalization操作并不适合图像风格化的任务,在风格迁移中适用IN不仅可以加速模型收敛,并且可以保持每个图像实例之间的独立性。
下面是IN的公式:

其中t代表图片的index,i代表的是feature map的index。
四、Group Normalization
Group Normalization(GN)是由2018年3月份何恺明团队提出,论文链接:https://arxiv.org/abs/1803.08494
Group Normalization(GN) 则是提出的一种 BN 的替代方法,GN优化了BN在比较小的mini-batch情况下表现不太好的劣势。其是首先将 Channels 划分为多个 groups,再计算每个 group 内的均值和方法,以进行归一化。对于GN,它的一个像素集为一个样本的一部分连续特征图的像素点集合。GB的计算与Batch Size无关,因此对于高精度图片小BatchSize的情况也是非常稳定的。

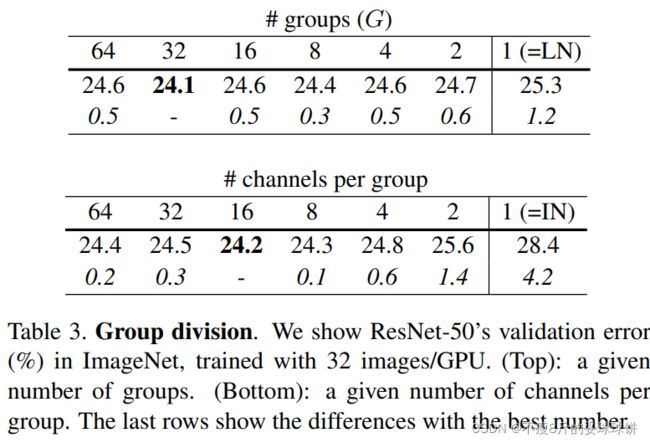
- 第一个表格展示GN的group Number不断减小,退化成LN的过程。其实,分组32个group效果最好;
- 第二个表格展示GN的每一组的channel数目不断减小,退化成IN的过程。每一组16个channel的效果最好 ,我个人在项目中也会有优先尝试16个通道为一组的这种参数设置。
参考链接:
https://blog.csdn.net/buchidanhuang/article/details/99675646
https://blog.csdn.net/leviopku/article/details/83182194