深度学习-服装种类识别实例(超详细的tensorflow讲解)
深度学习-服装种类识别实例
大体说明
这是一个技术tensorflow的技术文档,这个指南将训练一个神经网络模型,对运动鞋和衬衫等服装图像进行分类。指南使用了tf.keras,它是 TensorFlow 中用来构建和训练模型的高级 API。
引入所需要的工具模块
#首先我们需哟引入我们需要的工具模块
import tensorflow as tf
from tensorflow import keras
# 引入数据分析工具和画图工具
import numpy as np
import matplotlib.pyplot as plt
引入数据集
首先我们理清楚,我们训练一个模型往往需要两个很重要的部分,就是训练集和测试集,这里我们引入官方的提供的数据集合。
加载数据集会返回四个 NumPy 数组:
train_images 和 train_labels 数组是训练集,即模型用于学习的数据。test_images 和 test_labels 数组会被用来对模型进行测试。
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
在没有的下载的情况下,运行程序会自动下载的图片,我们接下来会使用这些图片来进行训练。

我们可以看下这个数据包含了什么内容
由于数据集不包括类名称,请将它们存储在下方,供稍后绘制图像时使用:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
浏览数据
这里我就不给出代码了,这个过程是为了让我们能够更好的理解理解数据。


数据预处理
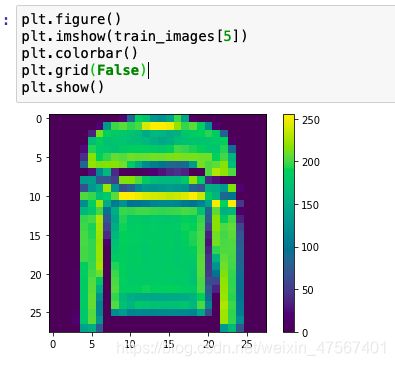
在训练网络之前,必须对数据进行预处理。如果检查训练集中的第个六图像,会看到像素值处于 0 到 255 之间:
plt.figure()
plt.imshow(train_images[5])
plt.colorbar()
plt.grid(False)
plt.show()
将这些值缩小至 0 到 1 之间,然后将其馈送到神经网络模型。为此,请将这些值除以 255。接下里以相同的方式对训练集和测试集进行预处理:
train_images = train_images / 255.0
test_images = test_images / 255.0
那接下来我们看看下前25图像是怎么样子的
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

构建模型
首先我们就要选择要使用的模型,再去编译模型
设置层
神经网络的基本组成部分是层。层会从向其馈送的数据中提取表示形式。大多数深度学习都包括将简单的层链接在一起。大多数层(如 tf.keras.layers.Dense)都具有在训练期间才会学习的参数。
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
该网络的第一层 tf.keras.layers.Flatten 将图像格式从二维数组(28 x 28 像素)转换成一维数组(28 x 28 = 784 像素)。将该层视为图像中未堆叠的像素行并将其排列起来。该层没有要学习的参数,它只会重新格式化数据。
展平像素后,网络会包括两个 tf.keras.layers.Dense 层的序列。它们是密集连接或全连接神经层。第一个 Dense 层有 128 个节点(或神经元)。第二个(也是最后一个)层会返回一个长度为 10 的 logits 数组。每个节点都包含一个得分,用来表示当前图像属于 10 个类中的哪一类。
编译模型
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
损失函数 - 用于测量模型在训练期间的准确率。您会希望最小化此函数,以便将模型“引导”到正确的方向上。
优化器 - 决定模型如何根据其看到的数据和自身的损失函数进行更新。
指标 - 用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
训练模型
训练神经网络模型需要执行以下步骤:
将训练数据馈送给模型。在本例中,训练数据位于 train_images 和 train_labels 数组中。
模型学习将图像和标签关联起来。
要求模型对测试集(在本例中为 test_images 数组)进行预测。
验证预测是否与 test_labels 数组中的标签相匹配。
model.fit(train_images, train_labels, epochs=10)
评估准确率
接下来,比较模型在测试数据集上的表现:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)

我的准确度尚可,88%
应用
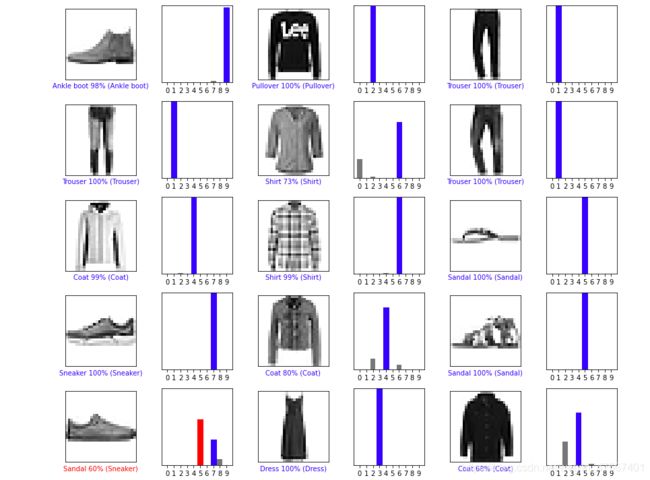
让我们用模型的预测绘制几张图像。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()
我们来看下对这些图片的预测效果怎么样?
这里有比较贴合的,也有失败的