卷积拆分与分组卷积的典型代表网络的总结
目录
1,卷积常规参数计算
2 ,卷积拆分网络
2.1 使用小的卷积核替代大的卷积核(VGG)
2.2 因式分解卷积
3, 通道分组卷积网络
3.1,简单的通道数分组
3.1.1 AlexNet
3.1.2 Xception
3.1.3 MobileNet
3.1.4 ShuffleNet
3.1.5 CondenseNet
3.2 级联通道分组
3.2.1 IGCV1
3.2.2 IGCV2
3.3 多分辨率卷积核通道分组网络
3.3.1 SqueezeNet
3.3.2 MixNet
3.4 多尺度通道分组网络(Big-Little Net)
3.5 多精度通道分组网络
1,卷积常规参数计算

2 ,卷积拆分网络
一个多通道的普通2D卷积包含了三个维度,分别是通道,长,宽,如下图(a)。
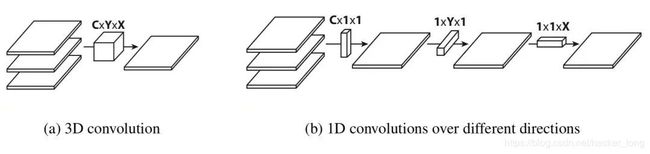
然后将这个卷积的步骤分解为3个独立的方向[1],即通道方向,X方向和Y方向,如上图(b),则具有更低的计算量和参数量。
假如X是卷积核宽度,Y是卷积核高度,C是输入通道数,如果是正常的卷积,那么输出一个通道,需要的参数量是XYC,经过上图的分解后,参数量变为X+Y+C,一般来说C>>X和Y,所以分解后的参数对比之前的参数约为1/(XY)。
2.1 使用小的卷积核替代大的卷积核(VGG)
对于3×3的卷积,相当于参数量降低一个数量级,计算量也是相当,可见这是很高效的操作。
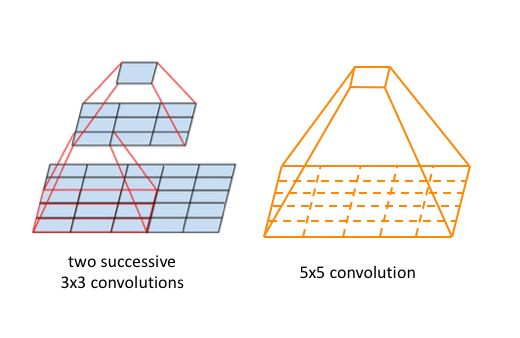
大卷积核替换为多个堆叠的小核(VGG),比如5 × 5 替换为2个3 × 3 ,7 × 7替换为3个3 × 3 ,保持感受野不变的同时,减少参数量和计算量,相当于把 大数乘积 变成 小数乘积之和,如下面公式所示:
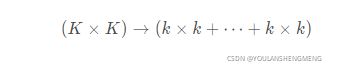
2.2 因式分解卷积
二维卷积变为行列分别卷积,先行卷积再列卷积,称为Factorized Convolution(代表Inception V2),

当然,还可以只分解其中的某些维度,比如在Inception V3的网络结构中,就将7×7的卷积拆分为1×7和7×1两个方向。从另一个角度来看,这还提升了网络的深度。
下图从左到右是Inception V1~IncVeption V3

Inception的原理:
- 首先通过‘1x1’卷积,将输入数据拆分cross-channel相关性,拆分成3或者4组独立的空间
- 然后,通过‘3x3’或者‘5x5’卷积核映射到更小的空间上去
3, 通道分组卷积网络
标准卷积实际上是完成同一通道内局部信息的提取和不同通道间的信息融合
标准的卷积是使用卷积核前一个通道内的所有的卷积分别卷积然后将结果进行线性叠加,该输出实际上是同时完成了同一通道里局部信息的提取以及不同通道之间的信息融合。每个输出通道都是接受前一个通道的所有的输入。分组卷积的思想是将将输出的通道不是和每一个输入通道都相关,两者的区别可以参考3.1的图像。
标准的卷积是使用多个卷积核在输入的所有通道上分别卷积提取特征,而分组卷积,就是将通道进行分组,组与组之间相关不影响,各自得到输出。
3.1,简单的通道数分组
3.1.1 AlexNet
Group Convolution(AlexNet),对输入进行分组,卷积核数量不变,但channel数减少,相当于
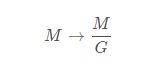

对于平移,旋转等刚体运动来说,它们可以被拆分成不同的维度,因此使用上面的separable(可分离) convolution,实现起来也很简单,就是先进行通道的分组,这在AlexNet网络中还被当作一个训练技巧。
3.1.2 Xception
Xception的演变过程可以参考博文:
深度学习网络结构笔记----Depthwise卷积与Pointwise卷积--深度可分卷积-- GoogleNet,Xception,MobileNetv1--v3_YOULANSHENGMENG的博客-CSDN博客
下图是Xception的基本组成单元
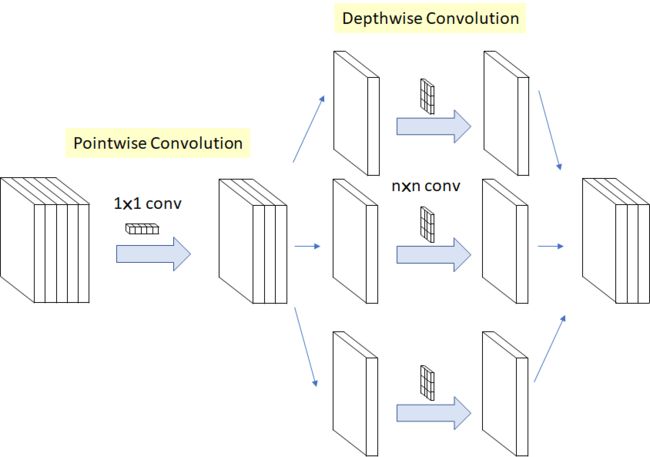
对应的总的网络结构为:

3.1.3 MobileNet
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。
要说MobileNet网络的优点,无疑是其中的Depthwise Convolution结构(大大减少运算量和参数数量)。下图展示了传统卷积与DW卷积的差异,在传统卷积中,每个卷积核的channel与输入特征矩阵的channel相等(每个卷积核都会与输入特征矩阵的每一个维度进行卷积运算)。而在DW卷积中,每个卷积核的channel都是等于1的(每个卷积核只负责输入特征矩阵的一个channel,故卷积核的个数必须等于输入特征矩阵的channel数,从而使得输出特征矩阵的channel数也等于输入特征矩阵的channel数)下面主要以MobileNetv1为说明,从v1--v3的变化过程可以参考博文:
深度学习网络结构笔记----Depthwise卷积与Pointwise卷积--深度可分卷积-- GoogleNet,Xception,MobileNetv1--v3_YOULANSHENGMENG的博客-CSDN博客
MobileNetv1的基本单元结构

左侧的表格是mobileNetv1的网络结构,表中标Conv的表示普通卷积,Conv dw代表刚刚说的DW卷积,s表示步距,根据表格信息就能很容易的搭建出mobileNet v1网络。在mobilenetv1原论文中,还提出了两个超参数,一个是α一个是β。α参数是一个倍率因子,用来调整卷积核的个数,β是控制输入网络的图像尺寸参数,下图右侧给出了使用不同α和β网络的分类准确率,计算量以及模型参数:
3.1.4 ShuffleNet
ShuffleNet是Face++的一篇关于降低深度网络计算量的论文,号称是可以在移动设备上运行的深度网络。这篇文章可以和MobileNet、Xception和ResNeXt结合来看,因为有类似的思想。
shuffleNet v1中的shuffle unit类似于ResNet中的bottleneck unit(Fig.2(a)),(b)为一个标准的shuffle unit,将1x1的pointwise group convolution后加入channel shuffle(通道打乱的操作),再进行depthwise convolution,最后再进行一次pointwise group convolution,需要注意的是,在第二个pointwise group convolution后,不添加ReLu层,而是在Add之后才添加,我认为这是防止信息损失过量。(c)中为步长为2的shuffle unit,可用于降采样。 通过使用depthwise convolution以及pointwise group convolution,shuffleNet可以在一定计算资源限制得情况下,竟可能的增加通道信息,提高准确率。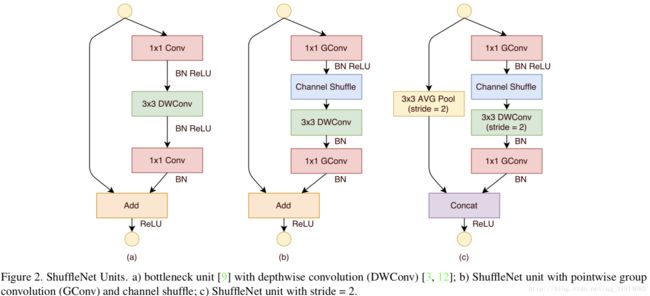
3.1.5 CondenseNet
CondenseNet是康奈尔大学的黄高,主要在于优化了DenseNet网络,使其计算效率更高且参数存储更少。在DenseNet博客中介绍过DenseNet最大的一个缺点就是显存占用较大,主要原因在于生成了额外的较多特征层。在DenseNet后面紧接着有一篇技术文章通过开辟统一存储空间用于存储额外生成的特征,可以在一定程度上减少模型训练时候的显存占用。这篇文章则主要通过卷积的group操作以及在训练时候的剪枝来达到降低显存提高速度的目的。
作者的实验证明,CondenseNet可以在只需要DenseNet的1/10训练时间的前提下,达到和DenseNet差不多的准确率。
总结下这篇文章的几个特点:
1、引入卷积group操作,而且在1*1卷积中引入group操作时做了改进。
2、训练一开始就对权重做剪枝,而不是对训练好的模型做剪枝。
3、在DenseNet基础上引入跨block的dense连接。
基于可学习分组卷积提出CondenseNet,能够在训练阶段自动稀疏网络结构,选择最优的输入输出连接模式,并在最后将其转换成常规的分组卷积分组卷积结构。
分组卷积能够有效地降低网络参数,对于稠密的网络结构而言,可以将3*3卷积变为3*3分组卷积。然而,若将1*1卷积变为1*1分组卷积,则会造成性能的大幅下降,主要由于1*1卷积的输入一般有其内在的联系,并且输入有较大的多样性,不能这样硬性地人为分组。随机打乱能够一定程度地缓解性能的降低,但从实验来看还不如参数较少的DenseNet。
另外,论文认为稠密连接虽然有利于特征复用,但是存在较大的冗余性,但很难定义哪个特征对当前层是有用的。为此,论文引入了可学习的分组卷积来解决上述问题。
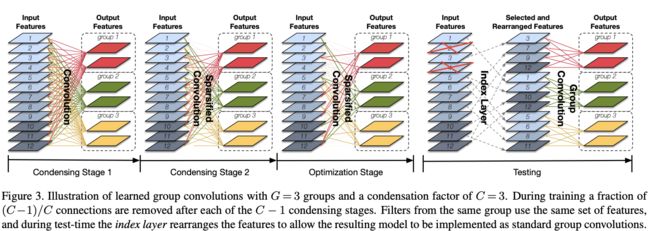
Figure1中左边图是DenseNet的结构。第三层的1*1 Conv主要起到channel缩减的作用(channel数量从lk减到4k),第五层的3*3 Conv生成k个channel的输出。Figure1中间图是CondenseNet在训练时候的结构,Permute层的作用是为了降低引入1*1 L-Cconv对结果的不利影响,实现的是channel之间的调换过程。需要注意的是原来1*1 Conv替换成了1*1 L-Conv(learned group convolution),原来的3*3 Conv替换成了3*3 G-Conv(group convolution)。Figure1中右边图是CondenseNet测试时候的结构,其中的index层的作用在于feature selection,具体要选择哪些feature map,是在Figure1中间图中训练完的时候就确定的,因此index层只是一个类似0-1操作。另外要注意由于添加了Index层,所以原来Figure1中间图中的1*1 L-Conv层在Figure1右边图中替换成常规的卷积group层:1*1 G-Conv,这是训练和测试时候的一个不同点。

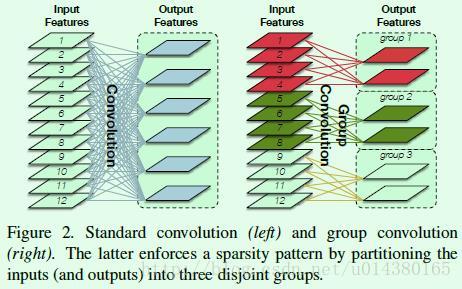
Figure2是卷积中group操作的示意图,其实就是将输入channel分成n个group(图中是3个group),同时卷积核也会分成n个group;然后每个group里的卷积核(图中每个group有2个卷积核)只跟一一对应的group中的feature map(图中是4个feature map)做卷积得到输出。能减少多少计算量呢?假设Figure2中左图的输入输出channel数各是R和O,那么Figure2左图的计算量暂且用R*O表示(更准确的表示是:k^2*m^2*R*O,其中k是卷积核大小(假设是正方形的),m是输出feature map的大小。如果采用G个group来做,计算量就是(R/G)*(O/G)*G=R*O/G(更准确的表示是:k^2*m^2*R*O/G),所以相比之下就是原来计算量的1/G。
前面提到一个名词:Learn Group Convolution,这个和普通的group convolution有什么不同呢?这得从1*1卷积讲起。作者想要在DenseNet的卷积操作中引入group,在3*3卷积中问题不大,但是在1*1卷积中发现直接这样做对最后的结果影响较大,一般1*1卷积层的作用是对前面层的输出特征做channel上的融合,因此如果加入group,那么融合的输入就少了许多,因此输出的多样性就得不到保证。所以如果能弄个像ShuffleNet那样的shuffle操作,就能增加输出多样性。因此作者通过添加Permute层(该层是变换通道顺序的作用,类似shuffle操作,这样后面每个group的3*3卷积的输入就可以包含1*1卷积的所有group输出),这可以在一定程度上降低在1*1卷积中引入group操作对结果的影响,当然作者也说了,这样做的效果还是不如相同计算量下的直接用更小的DenseNet网络的效果。
Figure3是关于Learned Group Convolution,由前面的解释可知,这主要是针对在1*1卷积中引入group操作。Figure3中文字部分的condensation factor C=3表示每个group可以包含的输入channel个数是[R/C],R是输入channel的总数,[]是取整的意思,也就是剪枝的结果是最终保留1/C的连接。接下来按Figure3从左往右来看。
Condensing Stage1是普通的卷积过程。
Condensing Stage2是自动选择group的过程,假如模型一共要迭代M个epoch,那么stage1+stage2的迭代次数为M/(2*(C-1))。
Optimization Stage是在group确定的前提下进行的剪枝,也就是筛选出每个group中不是很重要的输入feature map。那么怎么衡量重要性呢?比如要衡量第j个channel的输入feature map和卷积核的第g个group之间的重要性,那么就用j和g这个group之间的所有连接(g这个group有多少个卷积核,就有多少个连接)的权重的平均绝对值衡量重要性,本质上就是求权值的L1范数。显然这种剪枝的操作会使得同一个group中的卷积核都是和相同的输入channel做连接,当然这也是作者希望出现的。另外作者还引入了L1正则化,想要达到group-level sparisity的目的,当然文中有一句话不是很懂:To reduce the negative effects on accuracy introduced by weight pruning, L1 regularization is commonly used to induce sparsity。一般在过拟合的时候会通过加大L1正则化权重的方式来减轻过拟合,而且一般会对准确率有影响,这里却说为了提高模型的效果而引入L1正则化。
Testing部分主要是一个index layer操作和一个常规的group操作,比较简单。
3.2 级联通道分组
3.2.1 IGCV1
简单通道的分组,都是只有一个分组,而以IGCV(Interleaved Group Convolutions交替组卷积)系列为代表的模型采用了多个分组卷积结构级联的形式。
IGCV1
论文:https://arxiv.org/pdf/1707.02725v2.pdf
代码:https://github.com/zlmzju/fusenet
创新点
它的重点在于一个新颖的构建块:是由一对连续且相互交错的组卷积组成。
这两个组卷积是互补的:
在第一个组卷积中的卷积都是空间域卷积;
第二个组卷积中的卷积是逐点卷积;
第二个组卷积中同一个分组内的所有通道来自于第一个组卷积中不同分组;
比起普通卷积,在网络参数量和计算复杂度不变的同时,使得网络变得更宽了。
交错组卷积
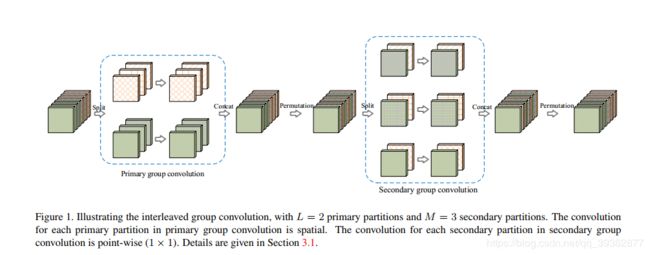
网络的结构如上图所示,它是一种交错组卷积块的堆叠结构。每个块包含两个组卷积: 第一次组卷积核第二次组卷积,所谓组卷积就是在卷积时有两个分组。
第一次组卷积是把输入通道划分为L个组,每个组包含M个通道,然后将L个分组卷积的结果拼接在一起得到新的输入其仍然有LxM个通道之后打乱顺序
第二次组卷积划分了M个组,每个组包含L个通道,且这L个通道来自第一次分组卷积时的不同组。
同时第一次卷积做的是空间域卷积,第二次做的是逐点卷积。
3.2.2 IGCV2
IGCV2的主要创新点也就是在IGCV1的基础上,对于block里第二次组卷积再进行一次IGC,让我们看一下图:
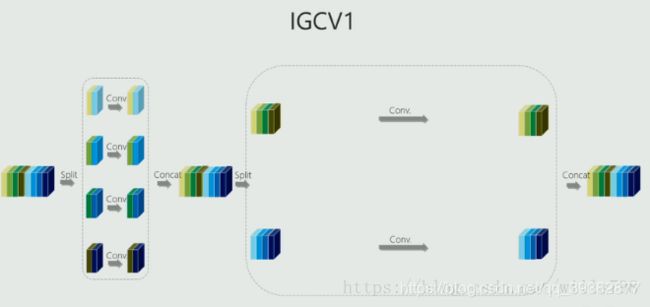
这是IGCV1的结构,可以看出第二次组卷积的时候,每一组的通道数仍然很多,文中的话就是比较dense,
因此想到对于每一组再进行IGC,这样就能进一步提升计算的效率了,也就是IGCV2,

将每个组的普通卷积替换成交错组卷积,具体可见下图,
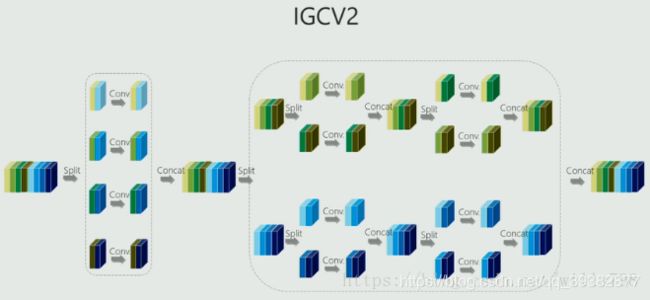
网络结构
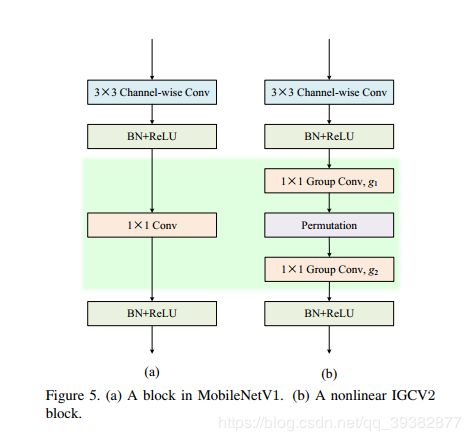
3.3 多分辨率卷积核通道分组网络
3.3.1 SqueezeNet
这类型的经典网络为 SqueezeNet, SqueezeNet主要采用的是fire module模块组成。它从卷积层conv1开始,接着8个fire module,最后以卷积层conv10结束。
1)Fire Module结构
Fire Module是由一个Squeeze(挤压)(全部由1*1卷积组成)和Expand(扩张)(由1*1卷积和3*3卷积组成)模块组成,且Squeeze的通道数小于Expand通道数,从而实现参数的压缩主要作用是进行通道的降维。Expand是由1*1卷积和3*3的卷积组成,进行通道的升维。
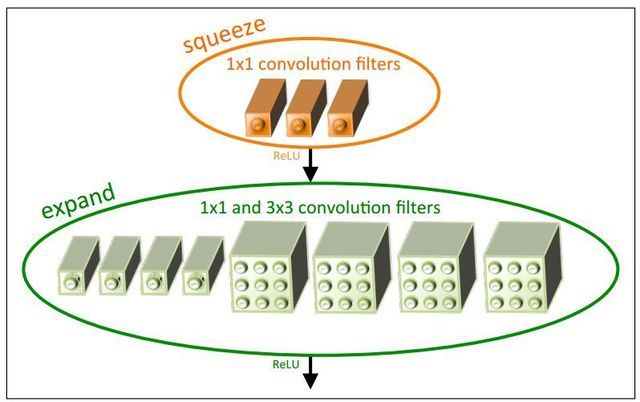

参数分析:
输入M个通道,输出N个通道。直接使用3*3的卷积,参数为M*N*3*3;
如果使用上图的结构参数为:M*1*1*3+3*N/2*1*1+3*N/2*3*3;
比例关系K=(3M+15N)/9MN=1/(3N)+5/(3M),所以当M和N很大的时候,可以实现很大的压缩比

该模块的可调参数为:S1,e1,e3
总结
1)Fire module由两层构成,分别是squeeze层和expand层,如上面的图所示,squeeze层是由s1个1x1卷积核组成的,expand层由e1个1x1的卷积核和e3个3x3的卷积核组成的,得到的feature map进行concat。对应策略1
2)一般令s1 < e1 + e3, 这样可以限制输入到3x3卷积核的channels。对于策略2
2)SqueezeNet 网络结构
SqueezeNet是一种轻量化网络结构
1.相同准确率下,更少参数量的模型有几点好处:
1)更加高效的分布式训练
2)向客户端提供新模型的开销更小
3)FPGA和嵌入式设备部署更便利
2.网络结构的设计策略
1)使用1x1的卷积核代替3x3的卷积核,可以减少9倍参数
2)减少输入3x3卷积的特征图的数量,因为参数由NCHW决定。
3)延后下采样,使得卷积层有较大的activtion maps。较大的特征图会带来较高的准确率。
其它细节:
在3x3的输入特征图上加了1像素的zero-padding,使其与1x1的输出大小一致
squeeze和expand层后跟ReLU激活函数
fire9后加0.5的Dropout
没有FC层(可以较少大量参数)

SqueezeNet小结:
1)Fire module与GoogLeNet思想类似,采用1x1卷积对feature map的维数进行[压缩],从而达到减少权值参数的目的;
2)采用与VGG类似的思想–堆叠的使用卷积,这里堆叠使用的是Fire module。
3.3.2 MixNet
MixNet是谷歌新出的一篇关于轻量级网络的文章,主要工作的重点就在于探索不同大小的卷积核的集合,这是因为:
小的卷积核感受野小,参数少,但是准确率不高
大的卷积核感受野大,准确率相对略高,但是参数也相对增加了很多
其主要创新点是,研究不同卷积核尺寸的影响和观察到组合不同尺寸的卷积核能提高准确率。作者将混合了不同尺寸的卷积核的卷积操作命名为MDConv,并将其使用在深度可分离卷积中,能提高显存的MobileNet的准确率。
基于AutoML的搜索空间,提出了一系列的网络叫做MixNets,结果比目前所有的轻量级网络都要好,在ImageNet上Top1比MobileNetV2高4.2%,比ShuffleNetV2高3.5%,比MnasNet高1.3%等等。
但是否卷积核越大,准确率就越高呢?作者首先在mobilenet上分析了,不同尺寸的卷积核对准确率的影响,得出卷积核越大,模型的大小也随之增加;随着卷积核增加,准确率先上升,后下降。说明了,卷积核并不是越大越好,过大的卷积核会损伤模型的准确率。对比实验也表明了:我们需要大卷积核来高分辨率、小卷积核来适应低分辨率。
MixNet核心结构mixed depthwise convolution(MDConv)模块,其实由多个不同尺寸的卷积核组成,如Fig.2所示。左图是深度可分离间距,其每个通道都是由同一尺寸的卷积核来进行运算;右图是MDConv模块,将通道分成若干组,每一组由同一尺寸的卷积核进行运算,每组的卷积核尺寸不同。最后通过MDConv计算后,将不同组的特征图进行concat起来。注意一点是,在每组中,每个通道都与这个卷积核进行depthwise convolution,而不是普通的convolution。

回忆下什么depthwise convolution,可以回去参考博文:
https://blog.csdn.net/YOULANSHENGMENG/article/details/121159448
这里给出depthwise convolution卷积的示意图

从Fig.2图就可以很清楚的看出来,将输入的Tensor分成几个不同的group,每个group用不同大小的卷积核,每个group分别用Depthwise Conv,最后将所有的通道Concat,也就就是MDConv。
基于TensorFlow实现MDConv demo如下所示,仅需这几行便可以实现:
def mdconv(x, filters, **args):
G = len(filters)
y = []
for xi, fi in zip(tf.split(x, G, axis=-1), filters):
y.append(tf.nn.depthwise_conv2d(xi, fi, **args))
return tf.concat(y, axis=-1) MDConv设计问题
Group Size
决定一个输入张量使用多少种不同类型的卷积核。在g=1的极端情况下,MixConv等价于普通的深度卷积。
在作者的实验中,发现g=4通常是MobileNets的一个安全选择,但在神经架构搜索的帮助下,发现从1到5的各种组大小可以进一步提高模型的效率和准确性。
Kernel Size Per Group
理论上,每个组可以有任意的核大小。但是,如果两个组具有相同的内核大小,那么就相当于将这两个组合并成一个组,因此限制每个组具有不同的核大小。此外,由于小的卷积核大小通常具有更少的参数和FLOPs,限制核大小总是从3×3开始,并且每组单调地增加2。换句话说,组i的核大小总是2i+1。例如,4组MixConv总是使用内核大小{3×3,5×5,7×7,9×9}。有了这个限制,每个组的核大小都是为任何组大小g所预定义的,从而简化了我们的设计过程。
例如group =4 的情况下,MDConv就是{3x3,5x5,7x7,9x9}。
Channel Size Per Group
考虑了两种情况,
一种是每组的通道数都相等
一种是根据组号指数衰减:第i组约占总通道的2^(−i)部分
例如输入channel = 32,group =4,那么
第一种每组通道数{8,8,8,8}
第二种每组通道数{16,8,4,4}
Dilated Convolution
大的卷积核意味着参数更多,因此可以用Dilated Conv(空洞卷积)来代替,这样更少的参数也能获得同样的感受野。
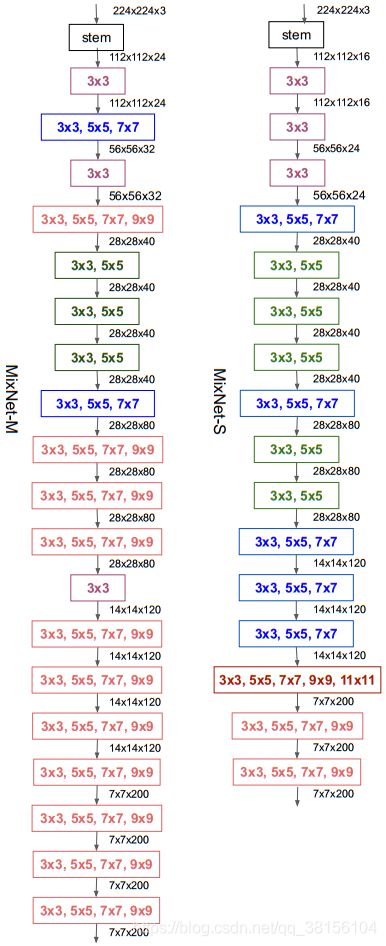
MixNet架构
下图为MixNet-S和MixNet-M的网络架构。
它们都在整个网络中使用各种不同核大小的MixConv:
为了节省计算成本,小的卷积核在早期更为常见,而大的卷积核在后期更为常见,以获得更好的准确性
较大的MixNet-M倾向于使用更大的核和更多的层来追求更高的精度,而代价是更多的参数和FLOPs。
与对于较大的核大小会导致严重的精度下降(图1)普通的深度卷积不同MixNets能够使用非常大的核,比如9×9和11×11,从输入图像中捕捉高分辨率的模式,而不会影响模型的精度和效率。
3.4 多尺度通道分组网络(Big-Little Net)
该类结构采用不同的尺度对信息进行处理,其对于分辨率大的分支使用更少的卷积通道,对于分辨率小的分支,使用更多的卷积通道。其代表类型为Big-Little Net
原文:《Big-Little Net: An Efficient Multi-Scale Feature Representation for Visual and Speech Recognition》
code:
https://github.com/IBM/BigLittleNetgithub.com/IBM/BigLittleNet
Big-Little Net使用多尺度特征表达的实现是通过多分支的网络结构,每个分支有不同的尺度,通过不断的融合不同尺度的特征来获得多尺度的特征。

设计原则:
1. 每个分支只有一个单一的图像尺度;
2. 计算花费和图像尺度的大小相反,即高计算花费的用在低分辨率分支,低计算花费的用在高分辨率分支。
如上图所示,图中的b图是一个低分辨率通道,也称为Big通道,维度为C,下面的是高分辨率通道,也称为Little通道,维度是C/![]() ,其中
,其中![]() 是一个大于1的缩放因子。两个通道各自完成学习,然后通过维度的变换后进行合并.合并前高分辨率低维度通道要使用1*1的卷积升维,低分辨率高纬度通道则需要进行空间上采样。
是一个大于1的缩放因子。两个通道各自完成学习,然后通过维度的变换后进行合并.合并前高分辨率低维度通道要使用1*1的卷积升维,低分辨率高纬度通道则需要进行空间上采样。
一些多尺度通道分组网络,还存在两个通道中,在学习过程中还存在信息交换,如octave convolution为代表的操作。
OctConv操作符实现的细节如下图所示。它由四条计算路径组成,两条绿色路径对应于高频和低频特征图的信息更新,两条红色路径便于两个octave之间的信息交换。

3.5 多精度通道分组网络
所谓多精度,是指分组卷积的计算精度不同。该类结构的代表为分布偏移卷积(Distribution Shifting Convolution DSConv)。它主要 是将卷积核分为两个部分,一部分是整数分量,另外一部分是分数分量。
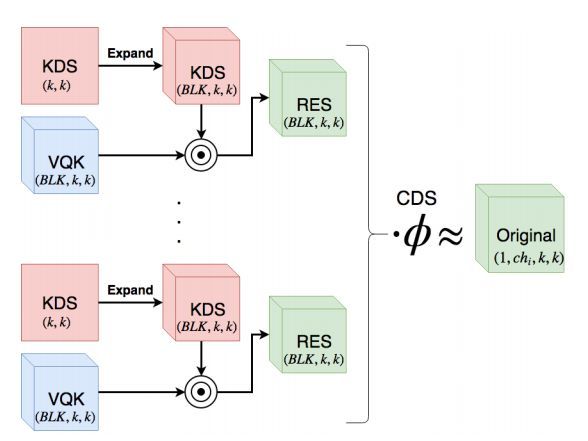
上图的结构称为DSConv(分布偏移卷积),其可以容易地替换进标准神经网络体系结构并且实现较低的存储器使用和较高的计算速度。 DSConv将传统的卷积内核分解为两个组件:可变量化内核(VQK整数部分)和分布偏移KDS(浮点型)。
通过在VQK中仅存储整数值来实现较低的存储器使用和较高的速度,同时通过应用基于内核和基于通道的分布偏移来保持与原始卷积相同的输出。
作者在ResNet50和34以及AlexNet和MobileNet上对ImageNet数据集测试了DSConv。 通过将浮点运算替换为整数运算,在卷积内核中实现了高达14x的内存使用量减少,并将运算速度提高了10倍。
参考博文
从卷积拆分和分组的角度看CNN模型的演化 - shine-lee - 博客园
【AI不惑境】移动端高效网络,卷积拆分和分组的精髓_hacker_long的专栏-CSDN博客_卷积拆分