爬虫疫情数据可视化(可视化图表)
由于本人才疏学浅,难免有纰漏,欢迎指正。
由于本篇文章内容过多,本文只提供大致思路和分享代码,如有运行相关问题,请留言。
本次内容需要用到的相关库:numpy pandas matplotlib pyecharts tqdm
目录
本次实现效果图
1Top10国疫情对比——条形图动画编辑
2.zm疫情对比-折线图动画编辑
3.各省新增本土病例-柱状图编辑
4.各省新增本土病例-地图编辑
5. 国内现存确诊/累计确诊/治愈/死亡-地图编辑
6.当前确诊-柱状图编辑
7.疑似病例柱状图编辑
8. 当前确诊饼图编辑
9.疑似病例饼图编辑
10.中风险地区柱状图编辑
具体实现内容
1Top10国疫情对比——条形图动画
中美疫情对比-折线图动画:
2..各省新增本土病例-柱状图,各省新增本土病例-地图
3.国内现存确诊/累计确诊/治愈/死亡-地图
4.柱状图+饼图
当前确诊柱状图
疑似病例柱状图
当前确诊饼图
疑似病例饼图
中风险地区柱状图
本次实现效果图
1Top10国疫情对比——条形图动画
2.zm疫情对比-折线图动画
3.各省新增本土病例-柱状图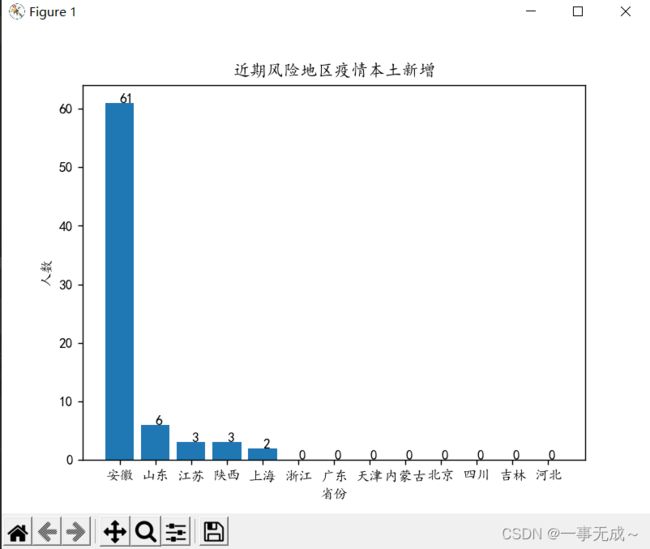
4.各省新增本土病例-地图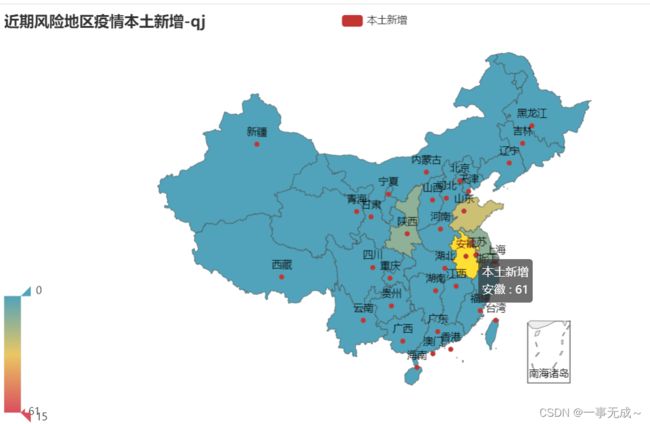
5. 国内现存确诊/累计确诊/治愈/死亡-地图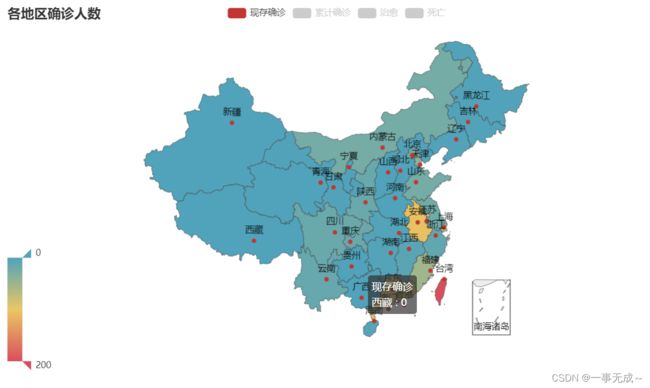
6.当前确诊-柱状图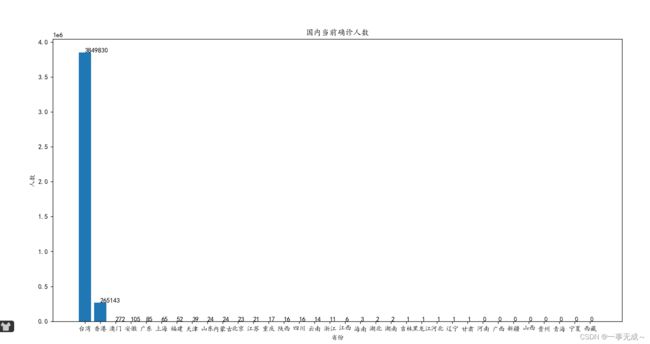
7.疑似病例柱状图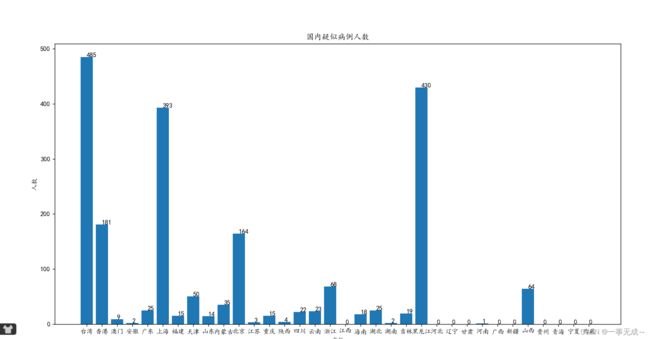
8. 当前确诊饼图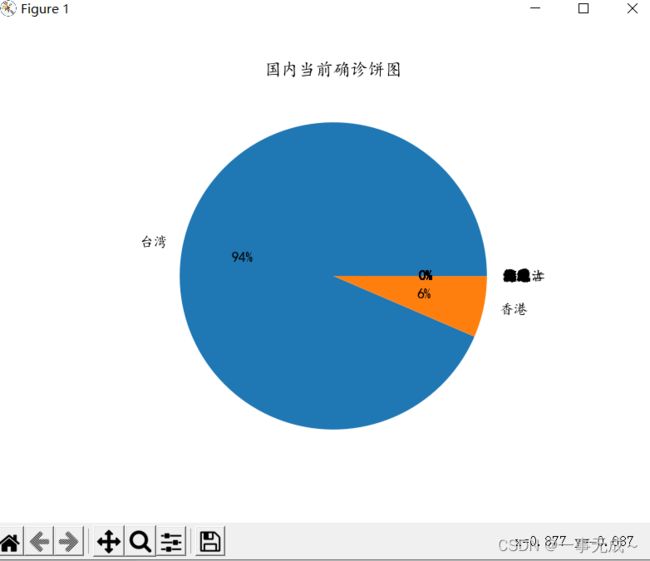
9.疑似病例饼图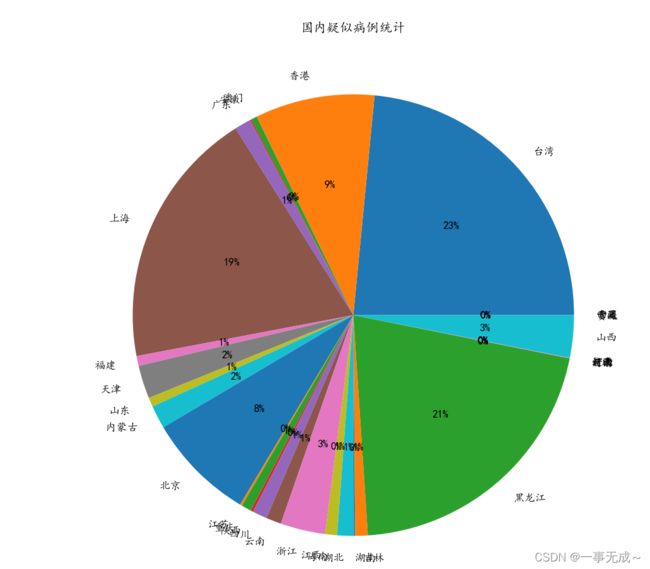
10.中风险地区柱状图
具体实现内容
1Top10国疫情对比——条形图动画
中美疫情对比-折线图动画:
思路:首先获取国外疫情数据,这里我拿到的是世界疫情数据(从疫情爆发到现在)
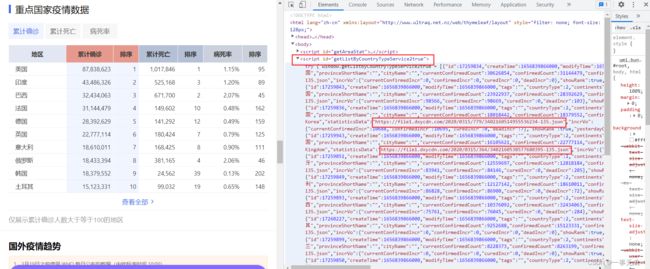
注意数据中的"statisticsData":"https://file1.dxycdn.com/.............json" 这个网个网址中包含一个国家从疫情开始到目前的详细数据。
所以要先获取第二个script下面的数据,再依次对每个国家的带有详情数据的网址进行爬取,就可以拿到历史疫情数据。
代码实现:
import json
import requests
from lxml import etree
from tqdm import tqdm
import re
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62',
}
res = requests.get(url=url,headers=headers)
res.encoding = "utf-8"
content = res.text #获取响应数据.text返回的是字符串形式的响应数据
html = etree.HTML(content)
con = html.xpath('//*[@id="getListByCountryTypeService2true"]/text()')
ls=con[0][48:198305-56]
# ==============================数据解析====================================================
datas = []#存放 国家名+此国家详情链接
detail_datas=[]#国家疫情详情
ex=r'"provinceName":"(?P.*?)".*?"statisticsData":"(?P.*?)"'
result=re.finditer(ex,ls,re.S)
#把所有的结果放在一个迭代器内
for item in result:
# provinceName=item.group('provinceName')
# statisticsData=item.group('statisticsData')
# print(provinceName,statisticsData)
datas.append(item.groupdict())
# print(datas[0])
# {'provinceName': '法国', 'statisticsData': 'https://file1.dxycdn.com/2020/0315/929/3402160538577857318-135.json'}
for i in tqdm(datas, '采集世界各国疫情数据'):
res=requests.get(url=i['statisticsData'],headers=headers).json()
data=res['data']
for d in data:
d['countryName'] =i['provinceName']
detail_datas.append(d)
# print(detail_datas)
with open('./世界各国疫情数据.json', 'w', encoding='utf8') as f:
json.dump(detail_datas, f, ensure_ascii=False)
# json.dumps()是把python对象转换成json对象的⼀个过程,⽣成的是字符串。
# json.dump()是把python对象转换成json对象⽣成⼀个fp的⽂件流,和⽂件相关
# ensure_ascii默认输出ASCLL码,如果把这个该成False就可以输出中⽂ 疫情数据爬取成功,之后进行数据处理,保存为二维格式表
数据处理部分代码
import pandas as pd
# 1. 准备数据
# 1.1 加载数据
datas = pd.read_json('./世界各国疫情数据.json')
# 1.2 按照累计确诊数量, 对数据进行排序, 获取从确诊数量从高到低的国家名称
datas.sort_values(by='confirmedCount', ascending=False, inplace=True)
country_names = datas['countryName'].unique()
# 1.3 使用透视表,统计每一天, 每个国家的确诊人数
final_data = datas.pivot_table('currentConfirmedCount', index='dateId', columns='countryName')
# 调整列的顺序
final_data = final_data[country_names]
# 1.4 使用0填充缺失值
final_data.fillna(0, inplace=True)
# 1.5 把每一天, 每个国家的确诊人数写入文件
final_data.to_csv('./世界各国疫情数据.csv')
进行绘图:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['font.sans-serif'] = ['KaiTi']
# 1. 准备数据
# 1.1 加载数据 ⽤index_col=0,直接将第⼀列作为索引
# --------------------------------------------------------
datas = pd.read_csv('世界各国疫情数据.csv', index_col=0, dtype=np.int32)
# 1.2 准确累计确诊病例数量前10的国家疫情信息
top10 = datas.iloc[4:,:10]# 根据序列iloc# 获取特定位置的值 行索引列索引从0开始
# iloc[a:b,c:d]:取行索引从a到b-1,列索引从c到d-1的数据
#绑定国家与颜色
color=['r', 'g', 'b', 'm', 'c', 'yellow', 'orange', 'yellowgreen', 'hotpink', 'gold']
name_color_map=dict(zip(top10.columns,color))
# print(name_color_map)
# {'美国': 'r', '印度': 'g', '巴西': 'b', '法国': 'm', '德国': 'c', '英国': 'yellow', '意大利': 'orange', '俄罗斯': 'yellowgreen', '韩国': 'hotpink', '土耳其': 'gold'}
# 2. 创建画布和绘图区
fig, ax = plt.subplots(figsize=(10, 6), dpi=100)
# 3. 实现动画更新方法
def update(date):
# 1. 绘制基本的条形图
# 清空画布
ax.clear()
print(date)
# 3. 对条形图按现有确诊人数降序排序
data = top10.loc[date].sort_values()#data是指定行的数据
print(data)
# 绘制条形图
color=[name_color_map[name] for name in data.index]
ax.barh(data.index, data.values,color=color
)
# 2. 添加辅助信息
# 2.1 在每一个柱状体上添加国家和现有确诊病例数量
# enumerate函数⽤于将⼀个可遍历的数据对象(如列表、元组或字符串)组合为⼀个索引序列,同时列出数据和数据下标
for i, name in enumerate(data.index):
# 获取这个国家现有确诊病例数量
value = data[name]
# print(i, name, value)
dx = data.max() / 100 # 宽度的百分之一间隔
# 现有确诊病例数量
ax.text(value + dx, i, value, fontsize=12)
# 国家名称
name_x = value - len(name) * dx * 2.5
if name_x > 0: #如果国家名字显示在框外,则不添加
ax.text(name_x, i, name, fontsize=12)
# 2.2 添加日期 transform=ax.transAxes 转换刻度(0,1)
ax.text(0.8, 0.3, date, transform=ax.transAxes, fontsize=16)
# 2.3 设置x的刻度在顶部
ax.xaxis.set_ticks_position('top')
# 2.4 添加标题
ax.text(0, 1.06, '现有确诊病例数量', transform=ax.transAxes, fontsize=14)
ax.text(0.4, 1.12, 'Top10国疫情对比', transform=ax.transAxes, fontsize=18)
# 2.5 显示网格(x轴)
ax.grid(axis='x')
# 2.6 不显示边框
plt.box(False)
# update(top10.index[60])
# 4. 创建动画并展示 top10.index就是索引(日期)
animation = FuncAnimation(fig, update, frames=top10.index, repeat=False)
plt.show()
#索引 .index
# 显示所有列名称 .columns
# 显示所有的值 .values
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
plt.rcParams['font.sans-serif'] = ['KaiTi']
# 1. 准备数据
# 1.1 加载数据
datas = pd.read_csv('世界各国疫情数据.csv')
# 1.2 准备折线图需要的数据
# 日期, 作为横轴的刻度
x_ticks = datas['dateId'].values
# print(type(x_ticks))==——》[20200119 ... 20220702]
# x轴的数据
x = list(range(x_ticks.shape[0])) #x_ticks.shape=(896,) x_ticks.shape[0]=896
# y轴
# 中国现有确诊病例数量
china = datas['中国'].values #
# 美国现有确诊病例数量
usa = datas['美国'].values #
# print(x_ticks)
# print(x)
# print(china)
# print(usa)
# 2. 创建画布
fig = plt.figure(figsize=(10, 6), dpi=100) #dpi 清晰度
# 3. 初始化折线图和坐标轴的范围与刻度
# 3.1 定义变量, 用于记录每一帧折线图显示的数据条数
line_range = 8
# 3.2 定义变量, 用于记录每一帧x轴刻度的数量
xticks_range = 10
# 3.3 初始化中美折线图对象
china_line, = plt.plot([], [], color='r', marker='o', label='中国')
usa_line, = plt.plot([], [], color='g', marker='*', label='美国')
# 3.4 显示图例
plt.legend()
# 初始化
# 3.5 设置x轴,y轴的范围以及x轴的刻度
plt.ylim(0, max(usa))
plt.xlim(0, line_range)
plt.xticks(x[0: xticks_range], x_ticks[0: xticks_range])
# 4. 实现动画的更新方法
def update(i):
# 更新折线图数据
start = 0 if i - line_range + 1 < 0 else i - line_range + 1
end = i + 1
# 更新中国折线图数据
china_line.set_data(x[start: end], china[start: end])
# 更新美国折线图数据
usa_line.set_data(x[start: end], usa[start: end])
# 设置x轴的范围和刻度
if i >= line_range:
xticks_end = end + 2
# 更新x轴范围
plt.xlim(start, xticks_end)
# 更新x轴刻度
plt.xticks(x[start: xticks_end], x_ticks[start: xticks_end])
return china_line, usa_line
# 5. 创建动画对象
animation = FuncAnimation(fig, update, frames=x, repeat=False)
# update(10)
# 6. 展示
plt.show() 2..各省新增本土病例-柱状图,各省新增本土病例-地图
风险地区疫情数据如图
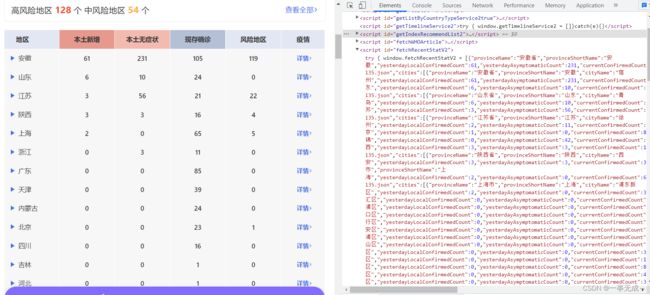
爬取数据部分代码
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62',
}
res = requests.get(url=url,headers=headers)
res.encoding = "utf-8"
content = res.text #获取响应数据.text返回的是字符串形式的响应数据
html = etree.HTML(content)
con = html.xpath('//*[@id="fetchRecentStatV2"]/text()')
con = str(con)
begin = con.index("[{")
end = con.index("}catch(e){}']")
con = con[begin : end]
ls = json.loads(con)本土新增柱状图代码
def btxzzt():
ls_provinceShortName = [] # 省份
ls_yesterdayLocalConfirmedCount= [] # 本土新增确诊
for x in ls:
provinceShortName = x["provinceShortName"]
yesterdayLocalConfirmedCount = x["yesterdayLocalConfirmedCount"]
ls_provinceShortName.append(provinceShortName)
ls_yesterdayLocalConfirmedCount.append(yesterdayLocalConfirmedCount)
x = np.array(ls_provinceShortName)
y = np.array(ls_yesterdayLocalConfirmedCount)
plt.title("近期风险地区疫情本土新增")
plt.xlabel("省份")
plt.ylabel("人数")
for i,j in zip(range(len(y)), y):
# print(i,j,j)
plt.text(i, j, j)#(i,j)表示添加标签的位置,j表示添加的内容
plt.bar(x, y)
plt.show()地图实现
# 本土新增人数地图
def dmap():
ls_provinceShortName=['台湾', '香港', '澳门', '安徽', '广东', '上海', '福建', '天津', '山东', '内蒙古', '北京', '江苏', '重庆', '陕西', '四川', '云南', '浙江', '江西', '海南', '湖北', '湖南', '吉林', '黑龙江', '河北', '辽宁', '甘肃', '河南', '广西', '新疆', '山西', '贵州', '青海', '宁夏', '西藏']
dict_ls_provinceShortName={}
for i in ls_provinceShortName:
dict_ls_provinceShortName[i] = 0
# {'台湾': 0, '香港': 0, '澳门': 0, '安徽': 0, '广东': 0, '上海': 0, '福建': 0, '天津': 0, '山东': 0, '内蒙古': 0, '北京': 0, '江苏': 0,
# '重庆': 0, '陕西': 0, '四川': 0, '云南': 0, '浙江': 0, '江西': 0, '海南': 0, '湖北': 0, '湖南': 0, '吉林': 0, '黑龙江': 0, '河北': 0,
# '辽宁': 0, '甘肃': 0, '河南': 0, '广西': 0, '新疆': 0, '山西': 0, '贵州': 0, '青海': 0, '宁夏': 0, '西藏': 0}
for i in ls:
provinceShortName=i['provinceShortName']
yesterdayLocalConfirmedCount=i['yesterdayLocalConfirmedCount']
dict_ls_provinceShortName[provinceShortName]=yesterdayLocalConfirmedCount
a=list(dict_ls_provinceShortName.items())
china_map=(
Map()
.add('本土新增',a,'china')
.set_global_opts(
title_opts=opts.TitleOpts(title='近期风险地区疫情本土新增-qj'),
visualmap_opts=opts.VisualMapOpts(max_=15,is_inverse=True)#颜色条0-20
)
)
china_map.render('./近期风险地区疫情本土新增.html')
print('本土新增人数地图绘制完成')3.国内现存确诊/累计确诊/治愈/死亡-地图
首先还是先对此部分数据进行一个爬取

数据爬取代码
import json
import requests
from lxml import etree
import csv
from pyecharts.charts import Map
import pandas as pd
from pyecharts import options as opts
url='https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62',
}
response=requests.get(url=url,headers=headers)
response.encoding = "utf-8"
content=response.text
# print(content)
tree = etree.HTML(content)
con = tree.xpath("/html/body/script[1]/text()")
con = str(con)
begin = con.index("[{")
end = con.index("}catch(e){}']")
con = con[begin : end]
json_list=json.loads(con) #json.loads()方法可用于解析有效的JSON字符串并将其转换为Python字典 dumps: 是将dict转换为string
# print(type(json_list))
f=open('./yq.csv','w',encoding='utf-8',newline='')#a 是追加保存
csv_write=csv.DictWriter(f, fieldnames=[
'地区',
'现存确诊',
'累计确诊',
'治愈',
'死亡',
])
csv_write.writeheader()
for li in json_list:
dit={
'地区':li['provinceShortName'], #省份
'现存确诊':li['currentConfirmedCount'], #现存确诊
'累计确诊':li['confirmedCount'], #累计确诊
'治愈':li['curedCount'], #治愈
'死亡':li['deadCount'], #死亡
}
# print(dit)
csv_write.writerow(dit)地图实现代码:
china_map=(
Map()
.add('现存确诊', [list(i) for i in zip(df['地区'].values.tolist(),df['现存确诊'].values.tolist())],'china')
.add('累计确诊', [list(i) for i in zip(df['地区'].values.tolist(),df['累计确诊'].values.tolist())],'china')
.add('治愈', [list(i) for i in zip(df['地区'].values.tolist(),df['治愈'].values.tolist())],'china')
.add('死亡', [list(i) for i in zip(df['地区'].values.tolist(),df['死亡'].values.tolist())],'china')
.set_global_opts(
title_opts=opts.TitleOpts(title='各地区确诊人数'),
visualmap_opts=opts.VisualMapOpts(max_=200,is_inverse=True)#颜色条0-200
)
)
china_map.render('./各地区确诊人数.html')4.柱状图+饼图
当前确诊柱状图
# 绘制柱状图
def qzzzt():
ls_province = [] # 省份
ls_currentConfirmedCount = [] # 当前确诊
for x in ls:
provinceName = x["provinceShortName"]
currentConfirmedCount = x["currentConfirmedCount"]
ls_province.append(provinceName)
ls_currentConfirmedCount.append(currentConfirmedCount)
x = np.array(ls_province)
y = np.array(ls_currentConfirmedCount)
plt.title("国内当前确诊人数")
plt.xlabel("省份")
plt.ylabel("人数")
for i,j in zip(range(len(y)), y):
# print(i,j,j)
plt.text(i, j, j)#(i,j)表示添加标签的位置,j表示添加的内容
plt.bar(x, y)
plt.show()疑似病例柱状图
# 分析疑似病例:
def yszzt():
# 绘制疑似病例柱状图
ls_province = [] # 省份
ls_suspectedCount = [] # 疑似病例
for x in ls:
provinceName = x["provinceShortName"]
suspectedCount = x["suspectedCount"]
ls_province.append(provinceName)
ls_suspectedCount.append(suspectedCount)
x = np.array(ls_province)
y = np.array(ls_suspectedCount)
plt.title("国内疑似病例人数")
plt.xlabel("省份")
plt.ylabel("人数")
for i,j in zip(range(len(y)), y):
plt.text(i, j, j)#(i,j)表示添加标签的位置,j表示添加的内容
plt.bar(x, y)
plt.show()
当前确诊饼图
def qzbzt():
# 绘制当前确诊饼图
ls_province = [] # 省份
ls_currentConfirmedCount = [] # 当前确诊
for x in ls:
provinceName = x["provinceShortName"]
currentConfirmedCount = x["currentConfirmedCount"]
ls_province.append(provinceName)
ls_currentConfirmedCount.append(currentConfirmedCount)
plt.pie(ls_currentConfirmedCount,
labels = ls_province,
autopct = "%.0f%%"
)
plt.title("国内当前确诊饼图")
plt.show()
疑似病例饼图
def ysbt():
# 绘制疑似病例饼图
ls_province = [] # 省份
ls_suspectedCount = [] # 疑似病例
for x in ls:
provinceName = x["provinceShortName"]
suspectedCount = x["suspectedCount"]
ls_province.append(provinceName)
ls_suspectedCount.append(suspectedCount)
plt.pie(ls_suspectedCount,
labels = ls_province,
autopct = "%.0f%%")
plt.title("国内疑似病例统计")
plt.show()
中风险地区柱状图
def zfxzzt():
# 绘制中风险地区柱状图
ls_province = [] # 省份
ls_midDangerCount = [] # 中风险地区
for x in ls:
provinceName = x["provinceShortName"]
midDangerCount = x["midDangerCount"]
ls_province.append(provinceName)
ls_midDangerCount.append(midDangerCount)
province = np.array(ls_province)
midDangerCount = np.array(ls_midDangerCount)
plt.title("国内中风险地区柱状图")
plt.xlabel("省份")
plt.ylabel("中风险地区个数")
for i,j in zip(range(len(midDangerCount)), midDangerCount):
plt.text(i, j, j)#表示添加标签的位置,j表示添加的内容
plt.bar(province, midDangerCount)
plt.show()