CBAM:Convolutional Block Attention Module
目录
1、注意力机制
2、论文解读
2.1 Channel Attention Module(通道注意力机制)
2.2 Spatial attention channel
2.3 CBAM integrated with a ResBlock in ResNet
2.4 实验结果
1、注意力机制
通俗的讲,注意力机制就是希望网络自动学出图片或文字序列中需要注意的地方。比如,人眼在观察一幅画时,不会将注意力平均分配到画中的每个像素,而是更多的将注意力放到人们关注的地方。
从实现的角度讲:注意力机制通过神经网络的操作生成一个掩膜mask,mask上的值打一个分,评价当前需要关注点的评分。
注意力机制可以分为:
- 通道注意力机制:对通道生成掩膜mask,进行打分,代表是senet,Channel Attention Map
- 空间注意力机制:对空间进行掩膜的生成,进行打分,代表是Spatial Attention Map
- 混合域注意力机制:同时对通道注意力和空间注意力进行打分,代表有BAM,CBAM
2、论文解读
论文提出Convolutional Block Attention Module(CBAM),这是一种为卷积神经网络设计的,简单有效的注意力模块(Attention Module),对于卷积神经网络生成的feature map,CBAM从通道和空间两个维度来计算feature map的attention map,然后将feature map 和attention map相乘,进行自适应特征学习。CBAM是一个轻量的通用模块,适用于各种卷积神经网络中。
实现过程如下:
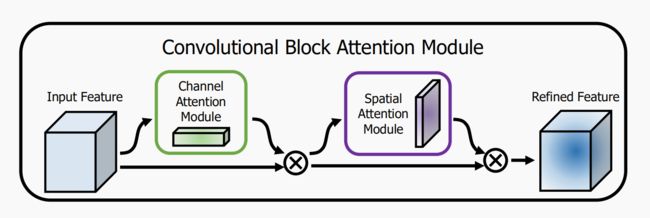
对于一个中间层的feature map:对于一个中间层的feature map: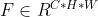 ,CBAM将会顺序推理出1维的channel attention map
,CBAM将会顺序推理出1维的channel attention map ![]() ,以及2维的spatial attention map
,以及2维的spatial attention map ![]() ,整个过程如下图所示:
,整个过程如下图所示:
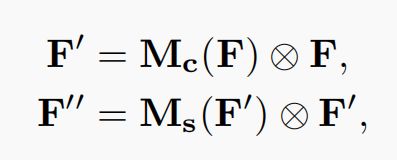
2.1 Channel Attention Module(通道注意力机制)
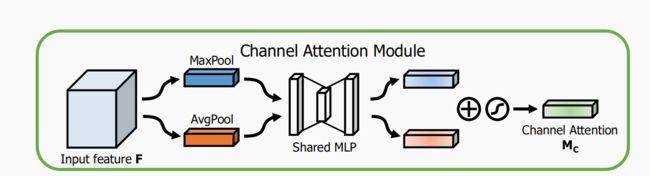
对于输入的feature map中每个channel都视为一个feature detector,channel attention主要关注输入的图片什么(what)是有意义的。为高效的计算channel attention,论文使用average-pooling和max-pooling对feature map进行空间维度上的压缩,得到两个不同的空间背景描述: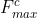 和
和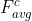 。使用由MLP(多层感知机)组成的共享网络对这两个不同的空间背景描述进行element-wise计算,再经过sigmoid函数得到channel attention map:
。使用由MLP(多层感知机)组成的共享网络对这两个不同的空间背景描述进行element-wise计算,再经过sigmoid函数得到channel attention map:![]() ,计算过程如下:
,计算过程如下:
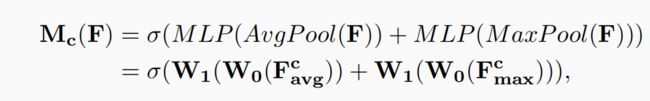
其中![]() ,
, ![]() ,W0之后使用了relu激活函数。 MLP的权重参数为W0和W1。
,W0之后使用了relu激活函数。 MLP的权重参数为W0和W1。
上图代码实现如下:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)Q:MLP中channel数为什么先降维后升维?
A:如果是经过一层的卷积,nn.Conv2d(in_planes,in_planes,1),假设输入的通道数是32,参数量为32×32×1×1=1024,论文中参数量,32×2×1×1+2×32×1×1=128,可看出参数量是原来的8倍。
2.2 Spatial attention channel
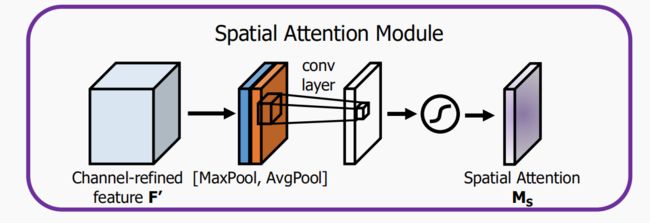
spatial attention 主要关注输入feature map的位置(where)信息,为了计算spatial attention,论文首先在channel的维度上使用最大池化和平均池化得到两个不同的特征描述![]() 和
和![]() ,然后使用concatenation将两个特征描述合并,并使用卷积操作生成spatial attention map
,然后使用concatenation将两个特征描述合并,并使用卷积操作生成spatial attention map ![]() ,计算过程如下:
,计算过程如下:
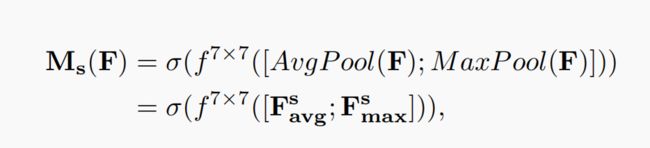
其中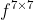 表示7*7的卷积层。
表示7*7的卷积层。
代码实现如下:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)2.3 CBAM integrated with a ResBlock in ResNet
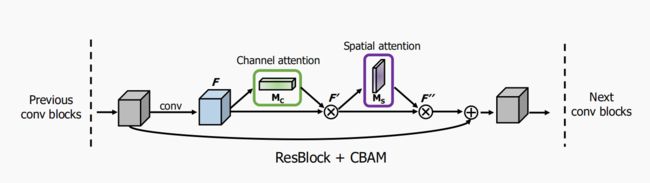
实现过程如下:
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # 广播机制
out = self.sa(out) * out # 广播机制
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return outCBAM模块:
import torch.nn as nn
class CBAMLayer(nn.Module):
super(CNAMLayer).__init__()
def __init__(self, channel, reduction=16, spatial_kernel=7):
# channel attention
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.mlp = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, bias=False),
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel, padding=spatial_kernel//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# channel attention
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
# spatial attention
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return x
2.4 实验结果
1、关于通道和空间上的串行和并行进行实验对比,发现先通道后空间实验结果会好一点。
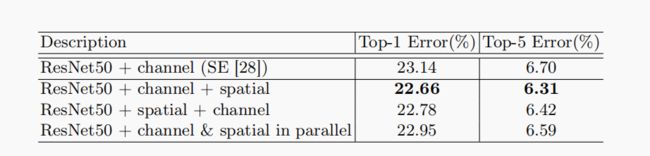
所以CBAM机制,先channel attention model 后spatial attention map
2、模型中加入CBAM机制的实验效果