【图像/视频压缩】论文笔记整理
图像压缩
【2018-02】Variational image compression with a scale hyperprior
作者指出,以往的图像压缩模型都是通过对潜在表示(latent representation)整体进行熵模型(entropy model)估计,如假定整个潜在表示都服从同一分布。然而,事实证明当潜在表示存在统计依赖关系,即空间耦合性(下图中左)时,这种全分解(factorized)的熵模型并不能达到最优的压缩效果。

因此,作者提出了超先验(hyperprior)的概念,指出应该为潜在表示下的每个像素点分别估计各自的分布、均值和方差,在熵编码阶段中依据该信息,可以有效的消除原潜在表示中存在的边信息(side information),得到消除空间冗余后的潜在表示(上图右),可以得到更优的熵编码,进一步获得更优的压缩效果。
整个网络架构如下图所示。红框中的区域为自编码器网络,绿框中的区域为超先验网络。后者读入图像的隐空间表示y,提取各像素点的分布信息,分别输入图像压缩网络的熵编码器(AE,消除空间冗余)和熵解码器(AD,为复原图像重新加入空间耦合信息),以实现图像更高效的压缩和更好的复原。

【2018-09】joint autoregressive and hierarchical priors for learned image compression
本文在上述《Variational image compression with a scale hyperprior》的模型基础上做了改进。在保留核心自编码器网络和超先验网络的结构下,添加了基于自回归(autogressive)的上下文模型。自编码器网络学习图像量化后的潜在表示;上下文模型通过自回归预测熵模型的概率分布;而超先验网络学习图像的隐空间表示y的表示信息,用于修正和调整上下文模型的预测结果。上下文模型和超先验网络结合形成子网络,共同学得量化后潜在表示的概率分布模型,最终将结果发送给熵编码器(AE)和熵解码器(AD),指导更好的完成图像压缩和复原。

视频压缩
【2019- 】DVC: An End-to-end Deep Video Compression Framework
本文是首个端到端优化的基于深度学习的视频压缩方法。
以压缩和复原视频t时刻的图像xt为例,传统的视频压缩方法可以分为以下几个步骤:
0、图像分块:一般是将原图像分解成等大的小方块(如8x8)。
1、运动估计(motion estimation):将xt和重建好的t-1时刻的图像 x ^ \hat{x} x^t-1输入基于图像块的运动估计模块,得到对应每个图像分块的运动向量vt。
2、运动补偿(motion compensation):基于第1步中定义的运动向量vt,通过将 x ^ \hat{x} x^t-1中对应的像素移动到指定位置的方法,获得t时刻重建图像 x ^ \hat{x} x^t的预测 x ‾ \overline{x} xt。结合xt,求得两者的残差为rt=xt- x ‾ \overline{x} xt。
3、变换和量化(transform and quantization):对rt进行线性变换(如DCT)以获得更好的压缩性能,然后对结果进行量化,得到 y ^ \hat{y} y^t。
4、逆变换(inverse transform):对 y ^ \hat{y} y^t进行逆变换,得到重构的残差 r ^ \hat{r} r^t。
5、熵编码(entropy coding):这一步是为将视频信息以码流形式存储在计算机上,熵编码器分别读入 y ^ \hat{y} y^t和vt并编码成比特流的形式写入文件并存储。当需要进行视频复原时,再将比特流解码并复原出这些信息。
6、帧重构(frame reconstruction):通过结合 r ^ \hat{r} r^t和 x ‾ \overline{x} xt得到t时刻图像的重构 x ^ \hat{x} x^t,完成t时刻图像的压缩和复原。最后将 x ^ \hat{x} x^t存入已解码帧的缓冲区(decoded frames buffer)中,为t+1时刻图像的压缩和复原做准备。
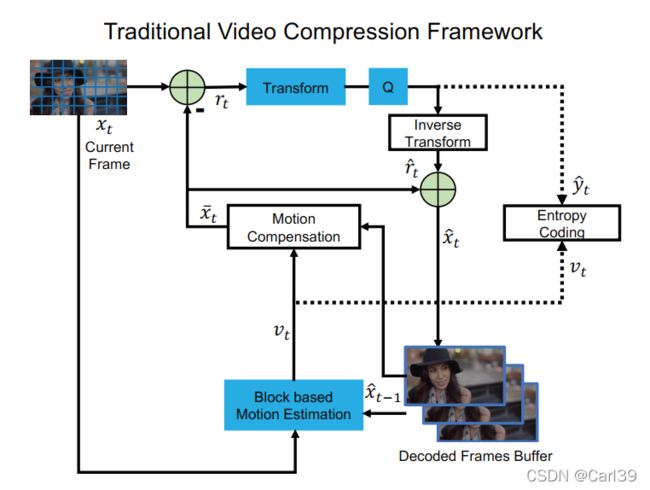
而基于深度学习的端到端视频压缩方法步骤如下:
1、运动估计和压缩:使用CNN估计xt和 x ^ \hat{x} x^t-1间的光流信息作为运动信息vt,并添加一组编解码器以进一步压缩vt中包含的光流信息,得到mt和量化后的结果 m ^ \hat{m} m^t,最后再通过解码器得到重建的运动信息vt。
2、运动补偿:使用神经网络替代传统方法中的同名模块。
3-4、变换、量化和逆变换:将传统方法中的线性变换改为非线性的残差编解码器网络,将残差rt非线性变化得到yt,进一步量化得到 y ^ \hat{y} y^t。 y ^ \hat{y} y^t经过残差解码网络得到重建的残差 r ^ \hat{r} r^t,用于图像的复原。
5、熵编码:将 y ^ \hat{y} y^t和 m ^ \hat{m} m^t输入比特流估计网络进行码率估计。若是要存储在计算机上,则可进一步进行熵编码操作。根据估计的结果、原t时刻图像xt和复原的t时刻图像 x ^ \hat{x} x^t的信息设计整个端到端网路的损失函数。
6、帧重构:与传统方法一致。

【2019-1】Video Compression Based on Spatio-Temporal Resolution Adaptation
在时域空域两个层面上对视频进行压缩,以减小传输码率。在host端预先定义一些量化参数(编码方式、质量要求等),输入给QRO(Quantisation-Resolution Optimization)模块。目标视频送入网络后将依次经过Temporal下采样和Spatial下采样网络。Temporal下采样以每两帧为单位,由QRO模块判断合并这两帧后的质量能否达到要求,若能则标记并合并,否则保持原样;Spatial下采样以GOP为单位,由QRO模块判断缩放该GOP后质量能否达到要求,若能则标记并缩放,否则保持原样。通过两步操作完成原视频在时空域上的双重压缩,降低传输码率。
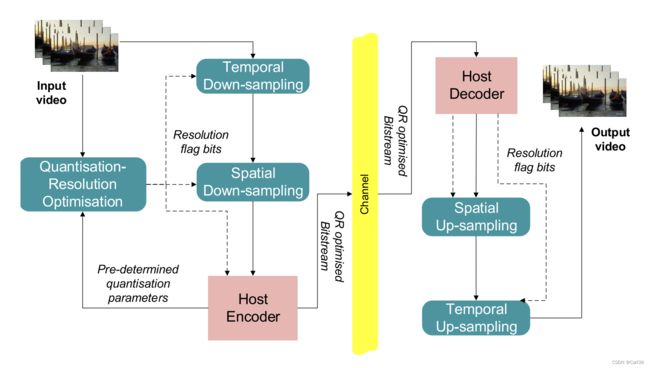
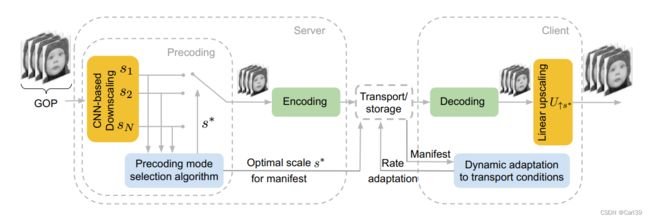
【2020-12 】Deep Video Precoding
模型提出的主要目的是在不耗费额外网络带宽的前提下,提升网络流式传输视频的质量。对每个GOP首先经过基于CNN的下采样进行缩放,由选择算法(Precoding mode selection algorithm)根据网络带宽等因素,从s1~sN中选出最佳的缩放比例s*,对原GOP按比例进行缩小,之后再经过编解码器传输,到达客户端后,再进行s*比例的线性上采样以复原到原尺寸,实现在不增加带宽的条件下提升视频质量,提高用户观看体验。网络结构和选择算法伪代码在文中有给出。
【2021- 】FVC: A New Framework towards Deep Video Compression in Feature Space
本文作者指出先前的基于深度学习的视频压缩方法都依靠在像素尺度(pixel space)上的混合编码以达到消除时间和空间冗余的效果,而这可能会导致不准确的运动估计和不够有效的运动补偿。故提出了特征空间的视频编码网络(feature-space video coding network, FVC),在特征空间上进行各种视频压缩的主要操作(运动估计、运动压缩、运动补偿和残差压缩),网络结构如下图所示。

首先,通过添加特征提取(feature extraction)和特征重建(feature reconstruction)模块,实现了图像从像素域到特征域的转换,将图像的压缩和复原由基于像素转化为基于特征。两个模块使用了残差网络,下图分别是提取模块的结构(左)、重建模块的结构(中)和残差块内部结构(右)。

之后进入可变形补偿(deformable compensation)模块。分为运动估计、动作压缩和动作补偿三个模块,前两个模块分别用于获取运动信息和压缩运动信息,动作补偿中使用了可变形卷积(deformable convolution)的设计,将复原的偏移信息 O ^ \hat{O} O^t(offset map)作为可变形卷积的偏移量,基于参考特征图Freft-1(上标带ref的特征被称为参考特征,下同)生成t时刻特征图的预测 F ‾ \overline{F} Ft,如下图所示。

而后,计算t时刻特征图Ft和预测 F ‾ \overline{F} Ft的残差Rt并输入残差压缩模块。该模块和上述运动压缩模块都是类似自编码器风格的网络。当不立即进行视频的复原时,经残差压缩模块压缩的残差信息,和运动压缩模块压缩的运动信息将会输入熵编码模块进行编码,最终以比特流的形式保存在计算机上。该模块输出为复原的残差信息 R ^ \hat{R} R^t,与 F ‾ \overline{F} Ft结合后得到初始的重建特征 F ~ \tilde{F} F~t,输入下一模块。
多帧特征融合(multi-frame feature fusion)模块从残差压缩模块读入 F ~ \tilde{F} F~t,并从参考特征缓冲区(reference feature buffer)读入t时刻之前3个时刻(t-1、t-2和t-3时刻)的重建帧的特征,基于注意力机制进行合成,以进一步调整 F ~ \tilde{F} F~t,得到最终重建的特征 F ^ \hat{F} F^t。再经过解码网络得到t时刻的重建帧 X ^ \hat{X} X^t。