时域特征提取MATLAB,强大的时间序列多特征提取工具介绍
hctsa对时间序列进行特征提取的使用流程
时间序列在许多领域中都有重要应用,如信号分析、金融量化分析、气象分析以及人体行为分析等等。通常对时间序列的处理需要进行特征分析, 关于特征提取分析的问题,主要是时域和频域特征,用滑动窗口提取特征,比如平均数、方差、过零率等,还有傅里叶变换后的幅度、频率、均值等。而这种特征分析通常需要一些特定领域内的专业知识,因此也就进一步提升了预处理的门槛。例如压力脉搏信号,不仅需要分析时域的幅度、均值、周期性等,也需要分析频域中的基频和倍频信号,以及各种频带的功率谱等等。
目前关于自动提取时间序列特征的开源库,包括python版本的tsfresh,下载链接https://github.com/blue-yonder/tsfresh/tree/master/tsfresh, 以及Matlab版本的hctsa,下载链接https://github.com/benfulcher/hctsa。这两个库都有比较详细的英文使用手册,但对没有机器学习基础的同学使用还是比较困难,目前工作中对tsfresh暂时还没有用到,下面给出hctsa的使用步骤。数据以TimeSeries中数据INP_test_ts.txt为例,注意先行其中的分类标签都改为1个,3个互不相同为宜。
step1:安装hctsa代码包,运行install.m文件;
step2:添加hctsa代码包运行需要的所有路径,运行startup.m文件;
step3:初始化输入函数:TS_init(INP_ts,INP_mops,INP_ops,beVocal,outputFile);其中
INP_ts: 格式可以参考文件夹TimeSeries里面的HCTSA.mat或INP_test_ts.txt,此项必须有输入;
INP_mops: 主操作函数定义, 默认输入为DataBase文件夹中的INP_mops.txt;
INP_ops: 计算序列特征的函数定义,默认输入为DataBase文件夹中的INP_mops.txt;
beVocal: 长度为3的逻辑行向量,是否显示对应输入变量脚本运行的进度信息,默认有输入的变量都显示;
outputFile: 输出文件名,包括主操作函数(MasterOperations),特征计算函数(Operations),原始数据(TimeSeries),初始化的特征值矩阵(TS_DataMat)、计算每个特征需要的时间(TS_Calc-Time)以及每个特征质量标签;
备注: TimeSeries是单一变量,均匀采样,按时间排序的序列,每个序列可以不等长。
图1 原始信号
step4:计算原始数据(TimeSeries)特征,生成的值对特征值矩阵(TS_DataMat)、计算每个特征需要的时间(TS_Calc-Time)以及每个特征质量标签进行覆盖,TS_compute(doParallel,ts_id_range,op_id_range,computeWhat,customFile,beVocal)
doParallel: 1开启并行运算,0不开启,默认为0;
ts_id_range: 时间序列范围,如[2:100],默认为所有序列;
op_id_range: 操作序列范围,默认为所有操作(示例为7873个)
computeWhat: 对应质量标签的取值;
customFile: 输出文件名,默认为HCTSA.mat;
beVocal: 逻辑变量,是否显示脚本运行的进度信息,默认显示;
step5:质量标签统计分析,TS_InspectQuality(inspectWhat,customFile)
inspectWhat: 显示质量标签输出,选择分类的有效性特征;
customFile: 输出文件名,默认为HCTSA.mat;

图2 生成特征的有效性图示
step6:滤除和归一化数据,outputFileName =TS_normalize(normFunction,filterOptions, fileName_HCTSA,classVarFilter,subs),
normFunction: 归一化函数;
filterOptions: 好值的比例,长度为2的行向量,分别为行列的比例阈值,默认[0.7,1];
fileName_HCTSA: 导入数据的文件,默认HCTSA.mat;
classVarFilter: 是否滤除方差为0的类(即常量序列);
subs: 需要处理的某个子序列;
outputFileName: 处理后保存数据的文件名;
step7:使用指定的关键字标记时间序列的组,[groupLabels,newFileName] =TS_LabelGroups(whatData,keywordGroups,saveBack,filterMissing)
whatData:取出并且重新覆盖标签的数据文件,默认为HCTSA.mat;
keywordGroups:标签元胞数组;
saveBack:可以设置为false以停止将分组保存回输入文件;
filterMissing:设置为true可删除与任何关键字不匹配的数据;
groupLabels:与关键字组中的每个关键字对应的索引;
newFileName:保存修改的数据名;
step8:使用所有特征对数据进行分类,TS_classify(whatData,whatClassifier,doPCs,doNull,seedReset)
whatData:加载数据的文件名,默认为HCTSA_N.mat;
whatClassifier: 分类器,默认为svm_linear,这个需要注意;
doPCs: 逻辑变量;
doNull: 逻辑变量;
seedReset: 随机种子;

图3 分类的混淆矩阵

图4 2-折交叉验证svm分类效果
step9:显示分类效果好的特征及特征分类函数,[ifeat,testStat,testStat_rand]= TS_TopFeatures(whatData,whatTestStat,varargin);
whatData: 使用的数据文件名;
whatTestStat: 测试统计量来量化每个特征的优点;
varargin: 额外选项,参看文件;
ifeat: 特征计算的性能排序;
testStat: 特征计算的统计;
testStat_rand: 测试统计数据组成的空分布。
运行过程显示所有操作的平均线性分类准确性,以及具有最佳性能的操作列表(按其测试统计排序,其ID显示在方括号中,关键字显示在圆括号中)。
Using overall classificationaccuracy as output measure
Comparing the (in-sample)performance of 7149 operations for 3 classes using a linear SVM classifier...
(should take approx 2.8min tocompute for all 7149 features)
Done in 2.7min.
Mean linear SVM classifierperformance across 7149 operations = 98.15%
(Random guessing for 3 equiprobableclasses = 33.33%)
[2] mean(distribution,location,raw,locdep) -- 100.00%
[3] harmonic_mean(distribution,location,raw,locdep) -- 100.00%
[4] median(distribution,location,raw,locdep) -- 100.00%
[5] trimmed_mean_1 (distribution,location,raw,locdep)-- 100.00%
[6] trimmed_mean_5(distribution,location,raw,locdep) -- 100.00%
[7] trimmed_mean_10(distribution,location,raw,locdep) -- 100.00%
[8] trimmed_mean_25(distribution,location,raw,locdep) -- 100.00%
[9] trimmed_mean_50 (distribution,location,raw,locdep)-- 100.00%
[10] midhinge(distribution,location,raw,locdep) -- 100.00%
[12] DN_HistogramMode_10(distribution,location) -- 100.00%
[13] DN_HistogramMode_20(distribution,location) -- 100.00%
[14] maximum (distribution) -- 100.00%
[15] miminmum (distribution) --100.00%
[16] rms(distribution,location,raw,locdep,spreaddep) -- 100.00%
[17] burstiness_Goh(distribution,raw,locdep,spreaddep) -- 100.00%
[18] burstiness_Kim(distribution,raw,locdep,spreaddep) -- 100.00%
[19] standard_deviation(distribution,spread,raw,spreaddep) -- 100.00%
[20] mean_absolute_deviation(distribution,spread,raw,spreaddep) -- 100.00%
[21] interquartile_range(distribution,spread,raw,spreaddep) -- 100.00%
[22] median_absolute_deviation(distribution,spread,raw,spreaddep) -- 100.00%
[23] DN_Moments_3(distribution,moment,shape) -- 100.00%
[24] DN_Moments_4(distribution,moment,shape) -- 100.00%
[25] DN_Moments_5(distribution,moment,shape) -- 100.00%
[26] DN_Moments_6(distribution,moment,shape) -- 100.00%
[27] DN_Moments_7(distribution,moment,shape) -- 100.00%
[28] DN_Moments_8(distribution,moment,shape) -- 100.00%
[29] DN_Moments_9(distribution,moment,shape) -- 100.00%
[30] DN_Moments_10(distribution,moment,shape) -- 100.00%
[31] DN_Moments_11(distribution,moment,shape) -- 100.00%
[32] DN_Moments_raw_3(distribution,moment,shape,raw,spreaddep) -- 100.00%
[33] DN_Moments_raw_4(distribution,moment,shape,raw,spreaddep) -- 100.00%
[34] DN_Moments_raw_5(distribution,moment,shape,raw,spreaddep) -- 100.00%
[35] DN_Moments_raw_6(distribution,moment,shape,raw,spreaddep) -- 100.00%
[36] DN_Moments_raw_7(distribution,moment,shape,raw,spreaddep) -- 100.00%
[37] DN_Moments_raw_8(distribution,moment,shape,raw,spreaddep) -- 100.00%
[38] DN_Moments_raw_9(distribution,moment,shape,raw,spreaddep) -- 100.00%
[39] DN_Moments_raw_10(distribution,moment,shape,raw,spreaddep) -- 100.00%
[40] DN_Moments_raw_11(distribution,moment,shape,raw,spreaddep) -- 100.00%
[41] skewness_pearson(distribution,moment,shape,raw,locdep) -- 100.00%
[42] skewness_bowley(distribution,moment,shape) -- 100.00%
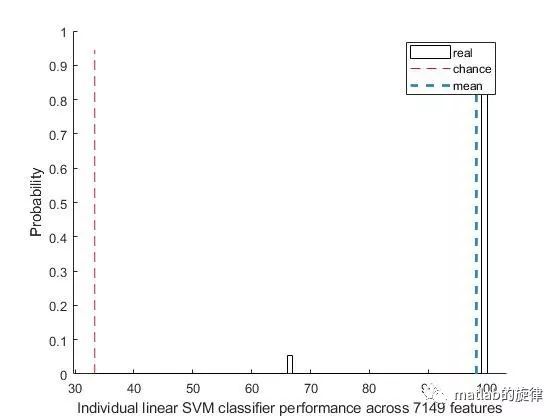
图5 完整库与随机标签的分类效果比较
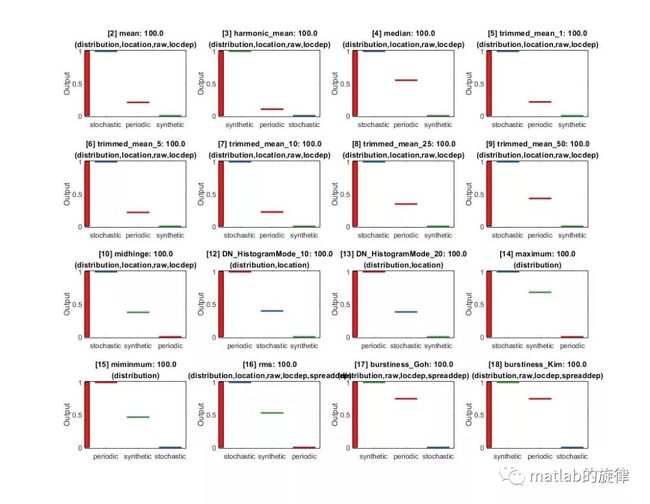
图6 显示最优特征的类概率分布
图7 最优特征计算函数的关系图
根据索引(ID值)查找对应的特征计算函数和主操作函数
如在命令窗口输入Operations([Operations.ID] == 6610)显示
struct with fields:
CodeString: 'WL_cwt_db3_32.stat_5_s_s'
Name: 'WL_cwt_db3_32_stat_5_s_s'
Keywords: 'wavelet,cwt'
ID: 6610
MasterID: 989
再通过MasterID查找主操作函数,在命令窗口输入MasterOperations([MasterOperations.ID] == 989)显示
struct with fields:
Code: 'WL_cwt(y,'db3',32)'
Label: 'WL_cwt_db3_32'
ID: 989
其中的WL_cwt就是主操作函数,通过editWL_cwt就可以查看对应的源码。
总结
hctsa库给从事时间序列特征提取提供了数字依据,也为没有相关知识的同学快速寻找时间序列预处理提供了思路。不过hctsa库只针对单变量的时间序列,在实际工作中经常面对的是多变量的时间序列,如多通道的ECG信号、EEG信号以及三轴加速度信号等等。这就需要在使用hctsa库前先将待处理的多变量时间序列转化单变量时间序列,以三轴加速度信号为例,可以将三轴加速度融合为合加速度,也可以用PCA降维处理。最后感谢作者们的工作以及分享,感谢伸展同学的推荐。