BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis
1.Introducton
本篇文章是2022年发表于ACL的一篇文章,在这篇文章中,不同于其他文章中单单使用句子依赖树的句法信息,作者通过挖掘句子结构树的语法信息来解决问题。在文中作者提到,由于结构树拥有精确且有区分的短语分割以及层级的组成结构。前者可以自然的将一个复杂的句子分成多个从句,后者可以辨别方面之间不同的关系从而来推断不同方面的情感关系。因此作者通过这一有效的方法,提出了一个全新的框架Bi-Syntax aware Graph Attention Network (BiSyn-GAT+),通过对上下文内(intra-context)和上下文间(inter-context)建模来有效利用构造树的句法信息。在BiSyn-GAT+上作者使用了:1)一个以自下而上方式融合同一句子句法信息的句法图嵌入来对方面的上下文内(intra-context)进行一个编码,这种编码方式结合了句子构造树短语级别的句法信息以及句子依赖树从句级别的句法信息。
2.Model
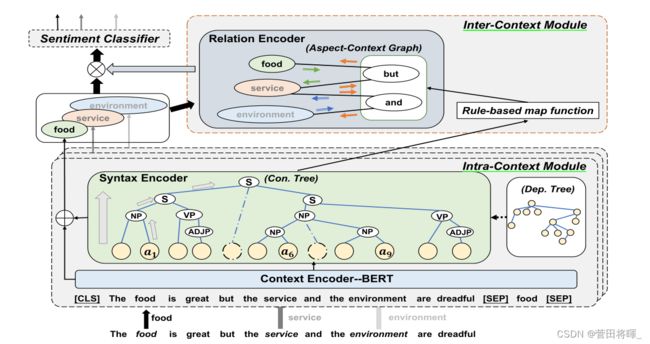
如图1:模型的大致结构
从整个模型上我们可以看到,它将句子和方面词作为输入从而输出所有方面的情感预测。整个模型主要由三个部分组成:1)上下文内模块(intra-context module)包括了两个编码器:一个输出上下文单词表示的上下文编码器,一个利用解析过的结构树(或者依赖树)的句法编码器。从这两个编码器输出的表示会被融合来产生特殊的方面表示。2)上下文间模块(inter-context module)包括一个关系编码器,这个关系编码器被用来构造方面上下文图来获得关系增强表示。方面上下文图包括了所有的方面以及从应用于结构树的一个基于规则的映射函数获得的短语分词术语。3)情感分类器采用两个模块的输出来进行预测。
接下来是对模型各模块的详细介绍。
2.1 Intra-Context Module
这个部分使用了一个上下文编码器和一个句法编码器来对每一个单一方面的情感感知上下文进行建模并为每一个方面生成特定方面(aspect-specific)的表示。另外对于多方面的句子,会多次使用这个模块,因为每次都处理一个方面。
2.1.1 Context Encoder
在文本输入方面,作者使用BERT来产生上下文的表示,对于一个给定的目标方面,使用BERT-SPC来构建一个基于BERT的序列:
![]()
从而得到输出表示:
![]()
由于输入的序列会被BERT的分词器拆分成多个子词,因此作者采用了如下公式来计算序列的表示。
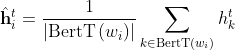
在这其中![]() 返回的是在BERT序列中
返回的是在BERT序列中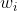 的子词的索引集(个人觉得应该是每个子词的表示),||返回他子词的长度。
的子词的索引集(个人觉得应该是每个子词的表示),||返回他子词的长度。
2.1.2 Syntax Encoder
模型的句法编码器由几个设计的分层图注意(HGAT)块堆叠而成,每个块由多个图注意(即GAT)层组成,这些图注意层在结构树(或者依赖树)的引导下分层编码句法信息。因此关键是对应图的构造。
Graph construction
图2:句子的构造树
图根据构成树来进行构造。我们可以看到,对应构造树的每一层由句子的几个短语组成(这里作者并没有引入构成树的内部节点,即“NP”,“VP”等)。于是根据这些短语作者设计了邻接矩阵CA。
![]()
具体的矩阵构造如图3所所示。
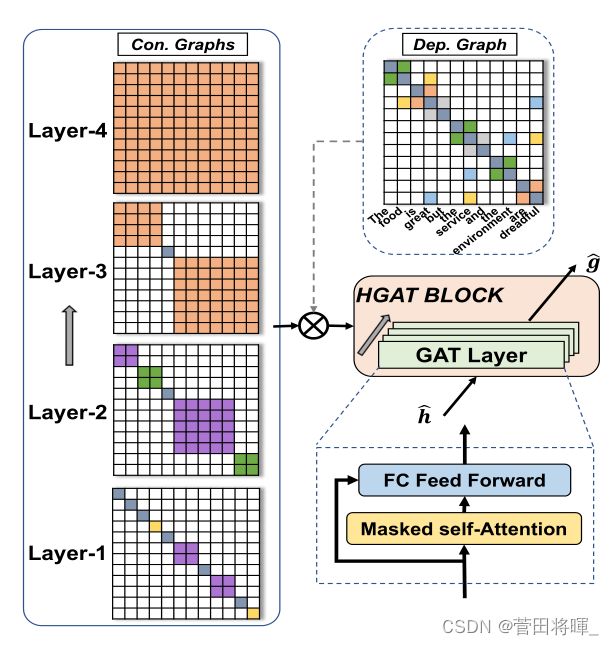
图3:HGAT块
HGAT block
HGAT块旨在将语法信息分层编码成单词表示。从图3我们可以看到,一个HGAT块由几个GAT层组成,在这其中作者使用了一个掩码的自注意力机制来聚合邻居的信息,以及一个全连接前馈层来讲表示映射到同样的语义空间,具体公式如下。
With dependency information
在文中作者同样提到了两种句法信息的融合操作。在这里我们将依赖树构成的领接矩阵叫做DA。
文中作者主要介绍了三种操作。
1)position-wise dot
FA = CA · DA
对于构造树的每一层,此操作只考虑同样处于相同短语的依赖树中的邻居。
2)position-wise add
FA = CA + DA
对于构造树的每一层,此操作将考虑相同短语中的单词和依赖树中的邻居。
3)conditional position-wise add
F A = CA ⊕ DA
该操作考虑构造树的短语级句法信息和依赖树的从句级句法信息。具体来说,它首先删除所有跨从句的依赖边(例如图2中“great”和“terrible”之间的边),然后对剩余的依赖边进行position-wise add操作。
从而得到了Intra-Context Module的最终输出。
![]()
2.2 Inter-Context Module
我们知道在intra-context 这一模块,做的更多的关于方面与上下文之间句法关系探索,因此忽略了一句话中方面与方面之间的互相影响。此模块仅适用于多方面的句子,将intra-context module中所有方面的特定方面表示作为每个方面的输入,来输出每一个方面的关系增强表示。
Phrase segmentation
这个部分主要是用来寻找方面之间的分割词。作者设计了一个基于规则的映射矩阵,大致的内容就是,对于给定的两个方面,首先在构造树中找到他们最低的公共祖先,作者认为这既包含了两个方面的信息,又最大程度的减少了不相关词的介入,具体公式如下。
Br()函数返回的是两个方面词的分割词,如果没有就返回两个方面词之间的所有词。
Aspect-context graph construction
这个部分的内容时基于Phrase segmentation而进行的。在通过Phrase segmentation提取邻居方面之间的分割词术语以后,根据将相邻方面和对应的分割词术语来构建上下文,从而推断之间关系。这里作者为了区分方面上下文图之间的双向关系,构造了两个对应的领接矩阵。即奇数下标的方面对偶数下标方面的影响与偶数下标的方面对奇数下标方面的影响。
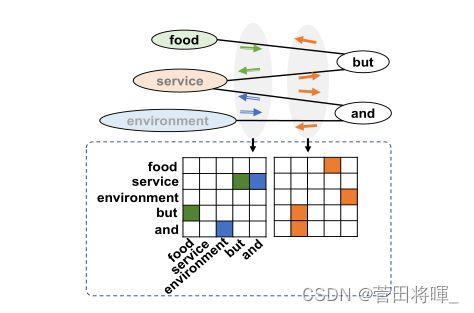
图4:方面上下文矩阵的构造
最后将Intra-Context Module的输出和经过BERT编码的分割词术语作为输入,采用上述HGAT块作为关系编码器,获得各方面的关系增强表示。
2.3 Training
将 intra-context module和inter-context module的输出做一个整合,之后放入全连接层和一个softmax层得到最后的结果。
最后是loss函数
![]()
3.Experiments
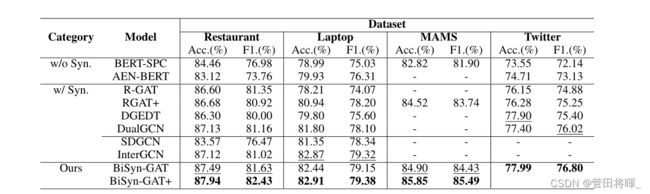
实验结果
模型比较
消融实验
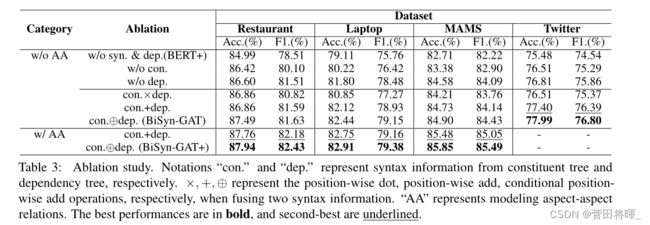
注:实验结果这一方面看的比较简单,具体内容请移步论文。
4.Conclusion
在本文中,提出了BiSyn-GA T+框架,通过充分利用构造树的语法信息来建模每个方面的情感感知上下文和跨方面的情感关系,它包括两个模块:1)intra-context module,分层次融合相关语义和语法信息;2)inter-context module,用构建的方面上下文图建模跨方面的关系。这是利用具有gnn的组成树完成ABSA任务的第一个工作。此外,提出的模型在四个基准数据集上实现了最先进的性能。
5.限制与未来工作
本节讨论了一些可以在未来工作中进行的改进。1)我们的完整模型采用了两个BERT编码器,一个在Intra-context模块中编码输入文本和方面,一个在Inter-context模块中编码短语分割词。优点是Inter-context模型可以很容易地推广到其他ABSA模型,利用它们的输出方面表示,生成关系增强表示。然而,这导致BiSyn-GA T+的参数高达233M。以后将考虑其他编码策略,而不是简单地使用另一个BERT;2)注意到来自构造树的标签信息也可以提供有价值的信息,如NP节点和VP节点共同构成S节点,可以分别包含方面词和相应的观点词,如图3所示。构造树提供的更多信息值得尝试利用,我们将在今后的工作中继续探索。