1 代码
引用库文件
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import pandas as pd import tensorflow as tf from tensorflow import feature_column from tensorflow.keras import layers from sklearn.model_selection import train_test_split
加载数据集,生成数据帧资源句柄
# 将heart.csv数据集下载并加载到数据帧中 path_data = "E:/pre_data/heart.csv" dataframe = pd.read_csv(path_data)
将pandas dataframe 数据格式转变为 tf.data 格式的数据集形式
# 拷贝数据帧,id(dataframe)!=id(dataframe_new) dataframe_new = dataframe.copy() # 从dataframe_new数据中获取target属性 labels = dataframe_new.pop('target') # 要构建Dataset内存中的数据 dataset = tf.data.Dataset.from_tensor_slices((dict(dataframe_new), labels)) # 将数据打乱的混乱程度 dataset = dataset.shuffle(buffer_size=len(dataframe_new)) # 从数据集中取出数据集的个数 dstaset = dataset.batch(100) # 指定数据集重复的次数 dataset = dataset.repeat(2)
2 shuffle、batch、repeat三个方法 / 函数
2.1 shuffle方法 / 函数
2.1.1 shuffle 函数实现过程
shuffle 是用来打乱数据集的函数,也即对数据进行混洗,此方法在训练数据时非常有用。
dataset = dataset.shuffle(buffer_size)
参数buffer_size值越大,意味着数据混乱程度也越大。具体原理如下所示。
假设buffer_size = 9,也即先从 dataset 数据集中取出 9 个数据“拖”到 buffer 区域中,后续训练数据的每一个样本将从 buffer 区域中获取。

比如从 buffer 区域取出一个数据 item7,现 buffer 区域内只有 8 个数据。
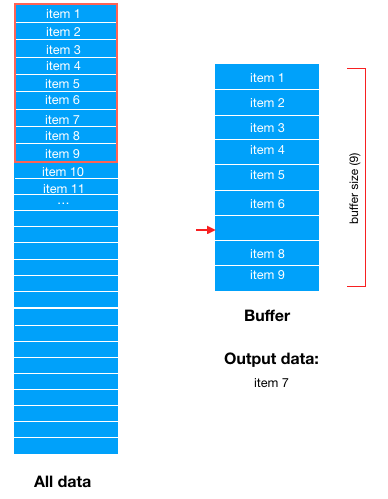
然后从 dataset 中按顺序取出一条数据(item10)再次“拖”到 buffer 区域补缺。

然后训练数据时再随机从 buffer 区域内随机选择一条数据;buffer 区域又形成数据空缺。
需要说明的是,这里的一条数据 item 只是一个抽象描述,其实为 bach_size 量的数据大小。
实际上,我们可以发现,buffer 其实是定义了一个数据池的大小 buffer size,当数据从被从 buffer 中取走后,就会从源数据集中抽出样本补缺到 buffer 中。
2.1.2 shuffle 方法的参数
buffer_size = 1 数据集不会被打乱
buffer_size = 数据集样本数量,随机打乱整个数据集
buffer_size > 数据 集样本数量,随机打乱整个数据集
shuffle是防止数据过拟合的重要手段,然而不当的buffer size,会导致shuffle无意义,具体可以参考这篇Importance of buffer_size in shuffle()
2.2 repeat方法 / 函数
repeat 方法在读取到组后的数据时重启数据集。要限制epochs的数量,可以设置count参数。
为了配合输出次数,一般默认repeat()空
repeat函数类似与 epoch
现在用的优化器SGD是stochastic gradient descent的缩写,但不代表是一个样本就更新一回,还是基于mini-batch的。
那 batch epoch iteration代表什么呢?
(1)batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次,通俗的讲epoch的值就是整个数据集被轮几次。
比如训练集有500个样本,batchsize = 10 ,那么训练完整个样本集:iteration=50,epoch=1.
---------------------
作者:bboysky45
来源:CSDN
原文:https://blog.csdn.net/qq_18668137/article/details/80883350
版权声明:本文为博主原创文章,转载请附上博文链接!
2.3 batch 方法 / 函数
一次喂入神经网络的数据量(batch size)。
3 shufle、repeat、batch三者之间的关系
官方网站上,阐述了 repeat 在 shuffle 之前使用可以有效提高性能,但是模糊了数据样本的 epoch
实际上,可以这样理解shuffle取之前已经重置了源数据集,
即先repeat,后shuffle。tf会将数据集乘以repeat次数,然后整个打乱一次,把它当作一个数据集
dataset = dataset.shuffle(buffer_size=10000) dataset = dataset.batch(32) dataset = dataset.repeat(num_epochs)
4 出处
深度学习中的batch、epoch、iteration的含义 https://blog.csdn.net/qq_18668137/article/details/80883350
tf.data.Dataset.from_tensor_slices( ) https://blog.csdn.net/u012193416/article/details/83720078
TensorFlow.org教程笔记(二) DataSets 快速入门 https://www.cnblogs.com/HolyShine/p/8673322.html
tensorflow dataset.shuffle dataset.batch dataset.repeat 理解 注意点https://blog.csdn.net/qq_16234613/article/details/81703228该文详细讲解了三者的含义,评论的内容也很重要
dataset中shuffle()、repeat()、batch()用法https://blog.csdn.net/angel_hben/article/details/84341421,一段代码示例
tf.data.Dataset.shuffle(buffer_size)中buffer_size的理解https://www.jianshu.com/p/1285036e314c 图片及相应的解说引用这篇文章