完全数据驱动的对话模型和社交机器人
研究人员最近开始探索完全数据驱动和端到端(E2E)的会话响应生成方法,例如,在序列到序列(seq2seq)框架内(Hochreiter和Schmidhuber,1997; Sutskever等, 2014)。这些模型完全根据数据进行培训,无需借助任何专业知识,这意味着它们不依赖于第4章中提到的对话系统的四个传统组件。这种端到端模型在社交机器人(chitchat)中特别成功。场景,因为社交机器人很少需要与用户的环境进行交互,并且缺乏外部依赖性(如API调用)简化了端到端培训。相反,任务完成方案通常需要例如知识库访问形式的这种API。该框架成功实现闲聊的另一个原因是它可以轻松扩展到大型自由格式和开放域数据集,这意味着用户通常可以聊聊她喜欢的任何主题。虽然社交机器人对于促进人与其设备之间的平滑交互具有重要意义,但是最近的工作还关注于超越聊天的场景,例如推荐。
5.1端到端对话模型
早期端到端模型受机器翻译(SMT)所影响。会话响应生成任务(由Ti-1时刻回应Ti时刻的内容)。这意味着可以用任何一套SMT算法去搭建响应生成系统。这是由早期数据驱动的AI会话工作者提出的,应用于基于短语的翻译方式。
有一个严重的限制是,聊天对话通常都很短(例如一些单词话语),在这种情况下,会话的关键是需要更多的背景来产生反应,Sordoni等人提出了一种基于RNN的会话响应生成方法,利用更长的上下文。
5.1.1 Lstm模型(略)
5.1.2 Hred模型(Hierarchical Recurrent Encoder-Decoder)
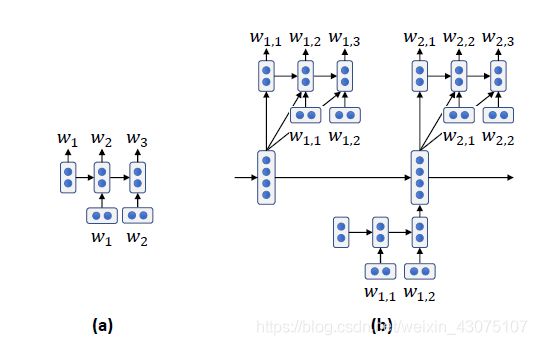
Hred模型对话使用两级层次结构,结合两个RNN:一个在词级别,另一个在对话轮次级别。这个算法框架模拟了对话历史由一系列轮次对话组成,每轮对话由一系列 tokens 组成。该模型引入一种结构:当前对话的隐状态直接依赖于前一对话的隐状态,允许信息在较长时间跨度上流动,并有助于减少梯度消失的问题。在此模型中使用GRU而不是LSTM来实现RNN的隐状态。
5.1.3 注意力模型
Seq2Seq框架在文本生成任务(如机器翻译)方面取得了巨大成功,但是将整个源序列编码为固定大小的向量具有一定的局限性,尤其是在处理长源序列时。基于注意力的模型(Bahdanau等,2015; Vaswani等,2017)通过允许模型搜索和专注于部分相关原序列预测下一个目标语句来缓解这种限制,从而避免了一个框架将整个源序列仅表示为单个固定大小的向量。虽然注意力模型和变体(Bahdanau等,2015; Luong等,2015等)促成了翻译领域的最新进展(Wu et al。,2016),并且非常普遍用于神经机器翻译中,但是注意模型在E2E对话建模中的效果稍差。这可能可以解释为注意模型尝试“联合翻译和对齐”是有效的(Bahdanau等,2015),这是机器翻译中的理想目标,因为源序列中的每个信息片段(外语句子)通常需要在目标(翻译)中传达一次,但在对话数据中则不那么正确。实际上,在对话中,来源的整个范围可能不会映射到目标中的任何内容,反之亦然.一些特定的对话注意模型已被证明是有用的(Yao等,2015; Mei等,2017; Shao et al。,2017),例如,避免单词重复(在5.2节中进一步讨论)。
5.2一些挑战
5.2.1 解决响应平淡
由神经反应生成系统产生的话语通常是平淡无奇的。虽然在其他任务中已经注意到这个问题,例如图像字幕(Mao et al。,2015),但在E2E响应生成中问题尤其严重,因为常用的模型如seq2seq往往会产生无法提供的反应,例如“我不知道”我知道“或”我很好“。 Li等人表明这是因为他们的训练目标,它会根据训练数据优化p(T|S)的概率,其中S是对话历史的资源,T是目标相应语句。p(T|S)在T和S中式不对称的,这导致训练系统无条件的偏爱高概率响应T,即,与上下文S无关。Li等人建议使用互信息 p ( T , S ) p ( T ) p ( S ) \frac{p(T, S)}{p(T) p(S)} p(T)p(S)p(T,S)取代传统的概率p(T|S),因为互信息的公式中的S和T是对称的,因此不存在激励学习将反应T偏斜,除非这种偏见来自于训练数据本身,但是优化互信息目标具有较大挑战,因此在实际过程中,Li等人使用了另个目标,它更加具体,对于给定的对话历史S,可以找到最佳的T: T ^ = argmax T { log p ( S , T ) p ( S ) p ( T ) } = argmax T { log p ( T ∣ S ) − log p ( T ) } \begin{aligned} \hat{T} &=\operatorname{argmax}_{T}\left\{\log \frac{p(S, T)}{p(S) p(T)}\right\} \\ &=\operatorname{argmax}_{T}\{\log p(T | S)-\log p(T)\} \end{aligned} T^=argmaxT{logp(S)p(T)p(S,T)}=argmaxT{logp(T∣S)−logp(T)}
超参数λ用于控制惩罚项: T ^ = argmax T { log p ( T ∣ S ) − λ log p ( T ) } = argmax T { ( 1 − λ ) log p ( T ∣ S ) + λ log p ( S ∣ T ) − λ log p ( S ) } = argmax T { ( 1 − λ ) log p ( T ∣ S ) + λ log p ( S ∣ T ) } \begin{aligned} \hat{T} &=\operatorname{argmax}_{T}\{\log p(T | S)-\lambda \log p(T)\} \\ &=\operatorname{argmax}_{T}\{(1-\lambda) \log p(T | S)\\ &+\lambda \log p(S | T)-\lambda \log p(S) \} \\ &=\operatorname{argmax}_{T}\{(1-\lambda) \log p(T | S)+\lambda \log p(S | T)\} \end{aligned} T^=argmaxT{logp(T∣S)−λlogp(T)}=argmaxT{(1−λ)logp(T∣S)+λlogp(S∣T)−λlogp(S)}=argmaxT{(1−λ)logp(T∣S)+λlogp(S∣T)}
尽管有这样的目标函数,Li等人没完全解决回复无聊的问题,因为这个目标仅用于推理而不是训练时间。最近研究人员Li;Xu等人使用生成对抗网络削减了无聊效果。直观的说,GAN对平淡的影响是:对抗性训练使用极小极大目标将判别器和生成器相互对立,并且彼此的目标是使得对方效果最差。生成器是响应生成的系统,判别器的目标是鉴别响应是人产生的还是生成器的输出。然后,若生成器总回答“我不知道”之类的无意义响应,大多数情况下,判别器将其和人类响应区分开是很容易的,因为大多数人不会一直回答“我不知道”。因此,为了欺骗判别器,生成器逐渐避开这种响应。同时,当假设分布和真实分布一致时,GAN实现最有效果,从而生成的响应能反映真实响应的多样性。为了促进响应的多样性,Zhang等人明确的优化查询和响应之间的成对互信息的变化下界。
Serban等人提出了Variable Hierarchical Recurrent Encoder-Decoder(VHRED)模型,该模型旨在产生较少的平淡回答和更具体地响应。它通过向目标添加高位随机潜变量来扩展前面描述的 Hred模型。这个额外的潜变量旨在解决浅层生成模型的挑战。正如Serban所述,从推理角度看,这一过程是存在问题的,由于生成模型被迫产生逐字基础的完整相应。在VHred模型中,生成过程更容易,因为模型利用高位潜变量确定相应的高级方面(主题,名称,动词等等),以便模型其他部分可以专注生成低级方面(确保流畅性等)。最近,zhang等人提出了一个模型,把额外的变量添加,以控制相应的具体水平:从平淡到具体。
虽然大多数上述调查时基于生成式,但是一种保守的减少平淡度的方案时用基于检索的模型代替基于生成的模型,其中可能的响应语料是预先构建的。这些方法是以降低灵活性为代价:生成过程中,可能的相应集合在单词数量上呈指数增长,但是检索式相应集合是固定的。
对话的流畅度
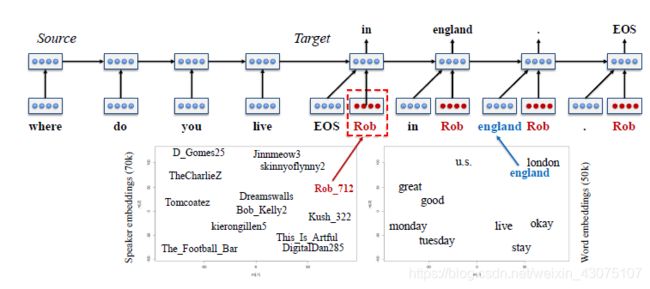
Seq2Seq模型常常产生不连贯的对话,比如可能说的内容和前一轮次的内容相反(或者有时在同一回合中)。Li表明这种不一致性可能是由于数据本身。实际上,会话数据集具有多个身份背景不同或冲突的演讲者,如对于“你多大了?”的问题,“23,27,40”这些数据都在数据集中。这将响应生成任务和传统的NLP任务区分开来:虽然机器翻译等其他任务模型都是在语义上一对一进行训练,但是会话数据通常是一对多或者多对多的。一对多训练就像任何学习算法的噪声,因此需要更具表现力的模型,利用丰富的输入更好的解释这种不同的响应。Li等人使用基于角色的相应生成系统,是LSTM模型的拓展,使用的词嵌入+speaker嵌入。直观的说,这两种嵌入工作相似:当词嵌入形成隐空间,空间上距离接近意味着词在语义上接近,speaker嵌入也构成隐空间,倾向于以相同的方式交谈,如/;具有相似的说话风格或者经常谈论相同的主题。和词嵌入一样,speaker嵌入参数和其他热门模型参数一样从其独热表示中一起学习。只需要指定说话者独热编码,以产生反应他说话风格的响应。该模型的全局体系结构如下图所示,它表明每个目标隐状态不但取决于前一时刻的隐状态和当前的词嵌入(England),还取决于speaker嵌入(Rob)。这个模型不仅有助于生成个性化的响应,还可以缓解前文提到的一对多建模问题。
其他方法也使用了个性化信息。如AI-Rfou等人提出了一个基于个性的响应生成模型,但用由21亿个巨大数据集进行检索。他们的检索模型使用深度神经网络实现为二元分类,即相应好还是不好。最近Luan等人提出了speaker嵌入的扩展:和seq2seq模型和非会话数据上训练的自编码器结合。,该方法训练了相应生成系统,而不需要任何个性化数据,这是该方法的有点。
5.2.3 词重复问题(Word Repetitions)
机器翻译是一个相对一对一的任务,其中每条信息通常在目标中传送一次,但是,对话或者文本生成类的任务收到的约束小得多,并且在问题中给定的单词可以映射到目标中的多个单词或短语。生成给定的单词或短语不完全排除再次生成相同单词或短语。注意力模型帮助阻止了机器翻译中重复问题。
基于上述,Shao等人提出了一个自注意力模型加到解码器上,旨在改善更长的连贯的响应,同时减少单词重复的问题。目标端注意帮助模型更容易跟踪到输出信息,模型可以更容易区分不必要的单词或短语重复。
5.2.4更长远的挑战
上述问题只是部分解决的重大问题,需要进一步调查。然而,这些E2E系统面临的更大挑战是响应适当性。
如第1章所述,与传统对话系统相比,早期E2E系统最显着的特征之一是缺乏基础。当被问及“明天的天气预报是什么?”时,E2E系统可能会产生诸如“晴天”和“下雨”的响应,而没有选择一个响应或另一个响应的原则基础,因为上下文或输入可能不均匀指定地理位置。 Ghazvininejad等。 (2018)认为seq2seq和类似模型通常非常善于产生具有合理整体结构的响应,但由于缺乏基础,在生成连接到现实世界的名称和事实时经常会遇到困难。换句话说,响应通常是实际上正确的(例如,问题通常后面会有答案,并且通过下载来道歉),但是响应的语义内容通常是不合适的。因此,最近对E2E对话的研究越来越多地集中于设计接地神经对话模型,我们接下来将对此进行调查。
Grounded Conversation Models
接地对话模型和面向任务的对话系统不同,大多数对话并非基于现实,这使得机器很难进行用户环境相关主题进行对话。最近的神经生成方法通过在发言者或收件人的接地系统来解决问题。在高层次上,大多数作品共同点是增加上下文编码器的,不仅和原来的对话有关,还要从用户的环境提取一些额外的输入,我们简要概述Ghazvininejad等人的模型作为举例。
该模型由两个encoders和一个decoder组成,解码器和对话编码器是相似于seq2seq模型。额外的encoder被称作facts encoder,它把事实信息或者和谈话历史相关的所谓的事实信息输入至模型,例如谈话历史中提到参观相关的评论(比如amazing sushi tasting)。虽然这项工作中的模型是通过Foursquare评估的,但是这种方法没有具体假设接地由评论组成,或者触发词是餐馆(实际上,一些触发词是例如酒店和博物馆)。为了找到与对话相关的事实,他们的系统使用IR系统使用从对话上下文中提取的搜索词从大量事实或世界事实(例如,几个大城市的所有Foursquare评论)中检索文本。虽然该模型的对话编码器是标准LSTM,但事实编码器是Chen等人的存储网络的实例。 (2016b),其使用关联存储器来模拟与特定问题相关的事实,在这种情况下,该事件是在对话中提到的餐馆。
这种方法有两个主要的好处,以及基于对话建模的其他类似工作。首先,该方法将E2E系统的输入分为两部分:来自用户的输入和来自环境的输入。这种分离是至关重要的,因为它解决了早期E2E(例如,seq2seq)模型的局限性,这些模型总是确定地响应同一查询(例如“明天的天气预报是什么?”)。通过将输入分成两个源(用户和环境),系统可以根据现实世界中的变化有效地生成对同一用户输入的不同响应,而无需重新训练整个系统。
其次,与标准的seq2seq方法相比,这种方法的样本效率更高。
对于未接地的系统产生类似于图中的响应的系统,系统将要求在会话训练数据中看到任何用户可能想到的每个实体(例如,“Kusakabe”餐厅),这是不现实的,不切实际的假设。虽然语言建模数据(即,非会话数据)的数量是丰富的并且可以用于训练扎根的会话系统(例如,使用维基百科,Foursquare),但是可用会话数据的量通常更加有限。接地的会话模型没有这种限制,例如,Ghazvininejad等人的系统。 (2018)可以谈论在会话训练数据中甚至没有提到的场地。
超越监督学习(RL)略
数据
Serban等人。 (2015)对现有数据集进行了全面调查,这些数据集在E2E和社交机器人研究之外是有用的。 E2E会话建模与其他NLP和对话任务的区别在于,数据非常大,部分归功于社交媒体(例如Twitter和Reddit)。另一方面,大多数社交媒体数据既不可再发行也不可通过语言资源组织(例如语言数据联盟)获得,这意味着仍然没有用于培训和测试响应的已建立公共数据集(使用Twitter或Reddit)。虽然这些社交媒体公司提供API访问,使研究人员能够以相对较小的数量下载社交媒体帖子,然后重建他们的对话,但这些公司指定的服务的严格法律条款不可避免地影响研究的可重复性。最值得注意的是,Twitter通过API提供某些推文(例如,从暂停的用户收回的推文或推文),并且要求删除任何此类先前下载的推文。这使得建立任何标准培训或测试数据集变得困难,因为这些数据集随着时间的推移而耗尽.10因此,在本章引用的大多数论文中,他们的作者创建了自己的(子集)会话数据用于培训和测试,然后根据这些固定数据集上的基线和竞争系统评估他们的系统。道奇等人。 (2016)使用现有数据集来定义标准训练和测试集,但它相对较小。一些最着名的E2E和闲聊数据集包括:
·推特:自从第一个数据驱动的响应生成系统(Ritter等,2011)以来,Twitter数据提供了大量无限制的会话数据,因为Twitter每天产生的新数据比大多数系统开发人员可以处理的要多。虽然数据本身可以通过Twitter API作为单独的推文访问,但其元数据可以轻松地构建对话历史记录,例如,在两个用户之间。该数据集构成了2017年DSTC任务2竞赛的基础(Hori和Hori,2017)。
·Reddit: Reddit是一个社交媒体来源,实际上也是无限制的,截至2018年7月,它代表了大约32亿次对话轮次。例如,它用于Al-Rfou等人。(2016)建立一个大规模的响应检索系统。 Reddit数据按主题(即“subreddits”)进行组织,其响应与Twitter不具有字符限制。
·OpenSubtitles:此数据集由在opensubtitles.org网站上提供的字幕组成,该网站提供许多不同语言的商业电影的字幕。截至2011年,该数据集包含大约80亿个单词,采用多种语言(Tiedemann,2012)。
·Ubuntu:Ubuntu数据集(Lowe et al。,2015)也被广泛用于E2E对话建模。它与其他数据集(如Twitter)的不同之处在于它不太关注闲聊,而是更注重目标,因为它包含许多特定于Ubuntu操作系统的对话。
·角色聊天数据集:这个众包数据集(Zhang et al。,2018c)的开发是为了满足会话数据的需求,其中对话展示了不同的用户角色。在收集角色聊天时,每个群众工作者被要求冒充使用五个事实描述的特定角色。然后那个工人在试图保持角色的同时参加了对话。结果数据集包含大约160k的话语。
5.6评估
评估是机器翻译和摘要等生成任务的长期研究课题。 E2E对话也不例外。尽管使用人类评估者评估响应生成系统是常见的(Ritter等,2011; Sordoni等,2015b; Shang等,2015等),但这种评估通常很昂贵,研究人员经常需要采用自动指标来量化日常进度和执行自动系统优化。 E2E对话研究大多借用机器翻译和摘要中的指标,使用字符串和n-gram匹配指标,如BLEU(Papineni等,2002)和ROUGE(Lin,2004)。最近提出,METEOR(Banerjee和Lavie,2005)旨在通过识别系统输出和人类参考之间的同义词和释义来改进BLEU,并且还用于评估对话。 deltaBLEU(Galley et al。,2015)是BLEU的扩展,它利用与会话响应相关的数字评级。
关于这种自动度量是否实际上适用于评估会话响应生成系统存在重大争议。例如,刘等人。 (2016)认为,通过证明大多数机器翻译指标与人类判断相关性较差,它们并不恰当。然而,他们的相关性分析是在句子层面进行的,但长期以来人们都知道即使对于机器翻译也难以实现良好的句子级别相关性(Callison-Burch等,2009; Graham等,2015),底层指标(例如,BLEU和METEOR)是专门用于的任务.12特别是,BLEU(Papineni等,2002)从一开始就被设计为用作语料级而不是句子级度量,因为基于n-gram匹配的评估在单个句子上计算时是脆弱的。
事实上,Koehn(2004)的实证研究表明,BLEU在由少于600个句子组成的测试集上不可靠。 Koehn(2004)的研究是关于翻译的,这个任务可以说比响应生成更简单,因此超越句子级关联的需要在对话中可能更为重要。在语料库或系统级别进行测量时,相关性通常远高于句子级别的相关性(Przybocki等,2009),例如Spearman’s?对于WMT翻译任务的最佳指标,大于0.95(Graham和Baldwin,2014).13在对话的情况下,Galley等人。 (2015)表明,基于字符串的度量(BLEU和deltaBLEU)的相关性随着测量单位大于句子而显着增加。具体来说,他们的Spearman’s?当测量每个100个响应的语料库的相关性时,系数从句子级别的0.1(基本上没有相关性)上升到接近0.5。
最近,Lowe等人。 (2017)提出了机器学习的E2E对话评估指标。他们提出了VHRED模型的变体(Serban et al。,2017),它将上下文,用户输入,黄金和系统响应作为输入,并产生1到5之间的定性分数。由于VHRED对建模对话有效,Lowe et人。 (2017)能够取得令人印象深刻的Spearman’s?句子层面的相关系数为0.42。另一方面,该指标可以训练的事实导致其他潜在问题,例如过度拟合和“游标指标”(Albrecht和Hwa,2007),这可能解释了为什么以前提出的机器学习评估指标(Corston- Oliver等,2001; Kulesza和Shieber,2004; Lita等,2005; Albrecht和Hwa,2007; Gim’enez和M`arquez,2008; Pado等,2009; Stanojevi’c和Sima’an ,2014年等)在官方机器翻译基准测试中并不常用。 “可玩游戏指标”的问题可能很严重,例如,在自动评估指标直接用作培训目标的常见情况下(Och,2003; Ranzato等,2015),系统开发人员可能不知道非预期的“游戏”。如果生成系统直接针对可训练的度量进行优化,则系统和度量变得类似于GAN中的对抗对(Goodfellow等,2014),其中生成系统(Generator)的唯一目标是欺骗度量(判别器)。可以说,这些尝试变得更容易使用可训练的指标,因为它们通常包含数千或数百万个参数,与BLEU这样的相对无参数的指标相比,已知这种指标对于这种利用非常强大,并且被证明是直接优化的最佳指标(Cer其他已建立的基于字符串的指标。为了防止机器学习的指标被游戏化,需要像GAN一样迭代地训练生成器和鉴别器,但是文献中的大多数可训练指标都不利用这个迭代过程。针对对话和相关任务提出的对抗性设置(Kannan和Vinyals,2016; Li等,2017c; Holtzman等,2018)为这个问题提供了解决方案,但众所周知这样的设置遭受不稳定性(Salimans)由于GAN的极小极大配方的性质,因此,2016年)。这种脆弱性可能很麻烦,因为自动评估的结果理想情况下应该是稳定的(Cer等人,2010),并且随着时间的推移可以重现,例如,追踪多年来E2E对话研究的进展。所有这些都表明,对E2E对话的自动评估远未解决问题。
开放基准
开放式基准测试是在语音识别,信息检索和机器翻译等许多AI任务中取得进展的关键。虽然端到端会话AI是一个相对新生的研究问题,但已经开发了一些开放的基准:
1、对话系统技术挑战(DSTC):2017年,DSTC首次提出了“端到端会话建模”,要求系统使用Twitter数据完全数据驱动。后续挑战中的两项任务(DSTC7)侧重于基础对话场景。一个侧重于视听场景感知对话,另一个侧重于基于外部知识的响应生成(例如,Foursquare和维基百科),从Reddit中提取对话。
2、ConvAI竞赛:这是一场NIPS竞赛,迄今为止已在两次会议上展出。它以亚马逊机械土耳其人资助的形式提供奖品。该竞赛旨在“培训和评估非目标导向对话系统的模型”,并在2018年使用Persona-Chat数据集(Zhang et al。,2018c)以及其他数据集。
3、NTCIR STC:该基准专注于“通过短文本”的对话。第一个基准专注于基于检索的方法,并在2017年扩展到评估基于生成的方法。
4、Alexa奖:2017年,亚马逊组织了一场关于建立“社交机器人”的公开竞赛,可以在一系列时事和主题上与人交谈。该竞赛使参与者能够使用真实用户(Alexa用户)测试他们的系统,并提供一种间接监督形式,因为用户被要求对每个Alexa Prize系统的每个对话进行评级。首届奖项包括15个学术团队(Ram et al。,2018)
5、JD对话挑战:18这是公司(JD.com)组织的另一项挑战。与Alexa奖一样,JD Challenge也为获奖者提供了重要的奖金,并允许参与者访问真实的用户和客户数据。