天池大赛o2o优惠券第一名代码笔记之_xgb
源码在我python3.6上出来点小问题 如图:

问题解决方法
源码:
import pandas as pd
import xgboost as xgb
from sklearn.preprocessing import MinMaxScaler
dataset1 = pd.read_csv('data/dataset1.csv')
dataset1.label.replace(-1,0,inplace=True)
dataset2 = pd.read_csv('data/dataset2.csv')
dataset2.label.replace(-1,0,inplace=True)
dataset3 = pd.read_csv('data/dataset3.csv')
dataset1.drop_duplicates(inplace=True)
dataset2.drop_duplicates(inplace=True)
dataset3.drop_duplicates(inplace=True)
dataset12 = pd.concat([dataset1,dataset2],axis=0)
#15天之内使用了券标签1
dataset1_y = dataset1.label
dataset1_x = dataset1.drop(['user_id','label','day_gap_before','day_gap_after'],axis=1) # 尝试发现'day_gap_before','day_gap_after' cause overfitting, 0.77
dataset2_y = dataset2.label
dataset2_x = dataset2.drop(['user_id','label','day_gap_before','day_gap_after'],axis=1)
dataset12_y = dataset12.label
dataset12_x = dataset12.drop(['user_id','label','day_gap_before','day_gap_after'],axis=1)
dataset3_preds = dataset3[['user_id','coupon_id','date_received']]
dataset3_x = dataset3.drop(['user_id','coupon_id','date_received','day_gap_before','day_gap_after'],axis=1)
#print(dataset1_x.shape,dataset2_x.shape,dataset3_x.shape)
dataset1 = xgb.DMatrix(dataset1_x,label=dataset1_y)
dataset2 = xgb.DMatrix(dataset2_x,label=dataset2_y)
dataset12 = xgb.DMatrix(dataset12_x,label=dataset12_y)
dataset3 = xgb.DMatrix(dataset3_x)
params={'booster':'gbtree',
'objective': 'rank:pairwise',
'eval_metric':'auc',
'gamma':0.1,
'min_child_weight':1.1,
'max_depth':5,
'lambda':10,
'subsample':0.7,
'colsample_bytree':0.7,
'colsample_bylevel':0.7,
'eta': 0.01,
'tree_method':'exact',
'seed':0,
'nthread':12
}
# =============================================================================
# #train on dataset1, evaluate on dataset2
# watchlist = [(dataset1,'train'),(dataset2,'val')]
# model = xgb.train(params,dataset1,num_boost_round=3000,evals=watchlist,early_stopping_rounds=1)#round=1调试程序用
# =============================================================================
#训练模型
watchlist = [(dataset12,'train')]
model = xgb.train(params,dataset12,num_boost_round=3500,evals=watchlist)
#predict test set
dataset3_preds['label'] = model.predict(dataset3,ntree_limit=model.best_ntree_limit)
#标签归一化在[0,1]原作者代码这里有错
#修改前
#dataset3_preds.label = MinMaxScaler(copy=True,feature_range=(0,1)).fit_transform(dataset3_preds.label)
#修改后
dataset3_preds.label = MinMaxScaler(copy=True,feature_range=(0,1)).fit_transform(dataset3_preds.label.reshape(-1,1))
dataset3_preds.sort_values(by=['coupon_id','label'],inplace=True)
dataset3_preds.to_csv("xgb_preds.csv",index=None,header=None)
print(dataset3_preds.describe())
#save feature score
# =============================================================================
# get_fscore(fmap='')
# Get feature importance of each feature.
# Parameters: fmap (str (optional)) – The name of feature map file
# =============================================================================
feature_score = model.get_fscore()
feature_score = sorted(feature_score.items(), key=lambda x:x[1],reverse=True)#value逆序排序
#调整一下输出的格式_见图
# =============================================================================
# print('{}网址: "{}!"'.format('菜鸟教程', 'www.runoob.com'))
# 菜鸟教程网址: "www.runoob.com!"
# =============================================================================
#把tuple换个形式
fs = []
for (key,value) in feature_score:
fs.append("{0},{1}\n".format(key,value))
with open('xgb_feature_score.csv','w') as f:
f.writelines("feature,score\n")#添加列名字
f.writelines(fs)#fs写进去
# =============================================================================
# #!/usr/bin/python
# # -*- coding: UTF-8 -*-
#
# # 打开文件
# fo = open("test.txt", "w")
# print( "文件名为: ", fo.name)
# seq = ["菜鸟教程 1\n", "菜鸟教程 2"]
# fo.writelines( seq )
# # 关闭文件
# fo.close()
# =============================================================================
model.get_fscore()查看
结果:
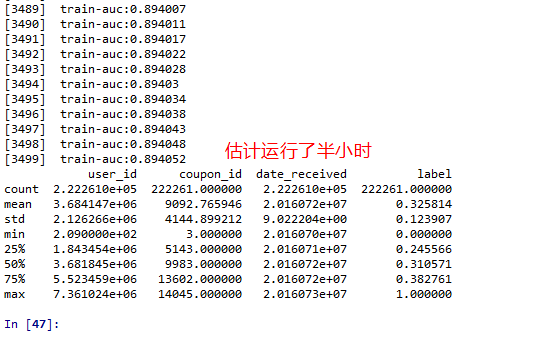
其他结果:




| 教训: | |
| 1、深入理解数据分布,尤其是测试目标的数据分布,是成功的第一步 | |
| 2、特征决定上限,调参只是帮助你逼近这个上限而已 | |
| 3、多与人交流,自己埋头苦干很容易跳进坑里一辈子出不来 |