区块链并行化调研
区块链并行化调研
- 一、 区块链现存问题:
-
- 1、可拓展性问题,拥堵成常态
- 2、技术创新剑走偏锋,区块链技术被肢解
- 3、闭关锁国发展,区块链呈孤岛状态
- 4、去中心化日渐中心 区块链变伪命题
- 二、 为什么是并行链?
-
- 1、并行区块链系统中,可以实现分片
- 2、并行区块链中,拓展性不再是问题
- 3、跨链性能优势,并行链释放区块链潜力
- 三、 谁能代表并行链?
-
- 1、主侧链混淆视听 伪并行链概念成风
- 2、适用于并行区块链系统的共识算法
- 四、智能合约和并行执行
-
- 1.智能合约和并行冲突
-
- 区块链
- 智能合约
- 交易
- 并行冲突
- 依赖关系
- 2. 智能合约的执行特点
- 3.并行执行可能引发的问题
-
- 并行冲突导致的执行结果错误
- 不同的串行化执行顺序导致最终状态的不一致
- 4.并行执行的关键任务
-
- 识别具有依赖关系的冲突交易
- 生成等价的执行顺序
- 五、DAG区块链
-
- 1. 什么是DAG?
- 2. DAG区块链与单链技术的对比
-
- (1)单链技术的几个问题
- (2)DAG区块链的与单链的区别
- 3. DAG 区块链的优势与价值
- 六、智能合约并行分类
-
- 1. 基于静态分析的并行执行模型
-
- 交易依赖图方法
- 资源互斥分组方法
- 2. 基于动态分析的并行执行模型
-
- 锁方法
- 多版本并发控制方法
- 软件事务内存方法
- 3.节点间并行执行模型
-
- 执行节点和执行节点之间的并行方法
- 出块节点和验证节点之间的并行方法
- 4. 分治并行执行模型
-
- 分片方法
- 通道方法
- 分区方法
- 侧链方法
- 群组方法
- 七、区块链并行处理应用实例
-
- 1. 基于DAG的并行交易执行引擎
-
- 背景
- 设计思路
- 架构设计
- 核心算法
-
- 交易DAG的数据结构
- 交易DAG的构造流程
- 交易DAG的执行流程
- 性能测评
-
- 性能测试
- 可扩展性测试
- 瓶颈
-
- 数据分析
- 根因拆解
- 优化实践
- 2. 星云链并发执行模型
- 3. XuperChain并行执行区块链结构
-
- 架构概述
- XuperModel
- XuperModel的智能缓存
- 交易冲突处理
- 智能合约的并行预执行
- 智能合约的并行验证
- 局限
- 参考文章
一、 区块链现存问题:
如果非要给区块链贴关键词的话,可以总结为:“技术很牛”,“前景不可估量”,“现实严重不落地”。现阶段区块链的发展都是以第一个标签为信仰,以第二个标签为动力,着力解决“严重不落地”的问题。从“不落地”到“大规模落地”,需要解决的问题有很多,但区块链本质上是一项技术,任何建立在区块链之上的应用和项目都需要基于靠谱的硬核技术,而区块链在“落地”过程中还未建立起完善的技术基础设施,这是区块链现存的核心也是首要问题。
区块链技术基础设施存在哪些问题?
1、可拓展性问题,拥堵成常态
目前,区块链技术最大的限制是其串行数据结构 ——出块必须逐一处理——这从根本上限制了区块链的吞吐量。虽然在应用层面上,各种区块链项目已经在变着法地玩花样,但是作为区块链的“开山鼻祖”,比特币和以太坊都还在一心解决拓展性的问题。
在保留区块链去中心化的初心下,比特币的扩容方案大体可以分为“区块派”和“隔离派”,区块派主要通过增大单个区块容量,增加单个矿工可处理的交易量事务,从而提升整体处理速度;隔离派主张建立闪电网络,通过将小额交易迁移到闪电网络,来提升链层速度,但无论区块派还是隔离派的方案都无法摆脱区块链串行数据结构的影响,最终仍会触达拓展性的天花板。以太坊在比特币基础上加入了图灵完备的智能合约,催生了1CO,但其创始人V神本人也一直在心无旁骛地解决拓展性问题,目前V神相对倾心PoS和分片两种方案,选择PoS有中心化隐患,而分片至今尚未实现。
2、技术创新剑走偏锋,区块链技术被肢解
或许是受到“建设百年公链”使命感的感召,或许是为了将自己树立为赶超比特币、以太坊的有力竞争者,在解决拓展性问题上,各类“第三代公链”也使出了浑身解数,但大多牺牲了区块链的某重要技术特征。大致来说,目前常见的方法有如下几种:一是改变共识机制,比如Hyperledger的PBFT、EOS的PoS,都破坏了区块链的去中心化特色;二是改变了网络结构,比如IOTA、byteball就使用了不同于区块链的DAG(有向无环图)的数据结构,改变了区块链的前向依赖关系关系,产生诸多安全漏洞;三是直接利用链外方式解决,比如链下的子链/侧链、状态通道,甚至是跨链中间件等,但这些Layer2处理方式最终还是要回归到一条串行区块链之上,就好比几条辅路上的车汇入主路,仍然无法避免拥堵。
3、闭关锁国发展,区块链呈孤岛状态
几年时间,行业极速发展,诞生很多区块链项目和链上应用,但每条链都是独立、垂直、封闭的体系,不同的区块链之间有天然的阻隔,就像一个个“孤岛”,价值无法自由快速流通,生态无法对接,体系无法增长,区块链呈一片散沙状态。为此,如近期出现的cosmos、polkadot,都是以解决跨链问题的项目,但因数据结构设计是异构网络环境,通过IBC协议进行链链交互,链构造环境及中继器机制使跨链协作性差,存在由于异步特性而带来的效率低下风险,而哈希锁定不支持多币种智能合约,所以无法从本质上解决跨链互联问题。
4、去中心化日渐中心 区块链变伪命题
区块链其实质上是一个由多方参与,并且共同维护的一个不断更新的分布式共享账本。多节点公平参与使区块链具备去中心化特点,但为了提升交易速度,像EOS采用的PoS共识,就牺牲了去中心化,而去中心是区块链长期拓展、保证安全和不可篡改特性,存储共识与价值的最基本特征。无法做到去中心化的区块链只能解决眼前的问题,而不能真正进行长远的价值发展。
二、 为什么是并行链?
从上面所述我们能看出,区块链多种拓展性实际受制于其串行结构本身,出块必须逐一处理。这就像车辆在单车道驾驶,受制于道路难拓,一旦车辆增多,无论车速多快,最终都会产生拥堵。用并行来解决拓展性问题,也并不是难以相见的迷思:无论是电信领域从对讲单机传输到CDMA时代,或是计算机从单核CPU到多核CPU,用并行解决拓展性问题是必然选择。
1、并行区块链系统中,可以实现分片
并行结构中,各子链可以在不影响数据一致性的前提下,根据容量需求动态的增加或减少数量。具体来说,即用户可在链上自定义分片触发条件,当达到条件时,链资源可以便捷的在子链负载过载触发机制达到的情况下开展子链分片及收拢,实现在事务增多时,必要的条件下并行出块,保证链层性能,使得底层事务处理速度不受事务容量的影响。
2、并行区块链中,拓展性不再是问题
除以上对于单条子链运用动态分片满足性能要求外,对于整个并行区块链系统通过多链并行使区块链系统资源得到无限的拓展性;同时通过非对抗性性记账方式,避免恶性节点竞争及算力浪费,且不存有特权节点,实现完全去中心化,保证系统的公平,同样保证无限资源聚集效应,使得系统具有永久拓展性。
3、跨链性能优势,并行链释放区块链潜力
在并行区块链系统下,可实现天然跨链,使得链与链之间可以实现互通,进行交互,将原来如“局域网”一般相互隔离的区块链连成一张可以无限拓展的大网。最直观的表现,就是两条链上的权益或资产价值转化,不再需要中心化交易所来完成;跨链的信息交互,就是信息的传递,在不改变原链结构的前提下,实现信息从一条链到另一条链上的传递。
未来,当区块链进而大规模、商业化落地使用的时候,并行链的天然跨链技术特性的优势将凸显出来。其不仅能实现不同链之间资产的自由流通,更重要的是能够无限释放不同链的潜力,让更多的用户参与,使更多的链可以连通,最终形成一个真正的大生态。
这样具有无限拓展性和跨链互联性的并行区块链系统才具有了成为区块链底层操作系统的资格和成为下一代价值互联网络的雏形。
三、 谁能代表并行链?
1、主侧链混淆视听 伪并行链概念成风
现在并行链项目,经常用主链、侧链、父链、子链等名词来代替并行链,其实他们与并行链有着天壤之别。侧链和主链的界定,一定程度上说明主链地位独一无二,这就无法保证多链平等一致等特征。
其次,目前大部分主链+侧链的结构中,基本都在上演侧链拿主链的秘方随意开店,并声称自己是主链的侧店,而是否和主链事务账务一致,无从查证。这更像是花开两朵,各表一枝的分叉;而不是并行运行下,身处一个时空维度的并行区块链。
2、适用于并行区块链系统的共识算法
从以上诸多伪并行链的例子上可以看出,要想真正架构并行区块链系统,必须首先解决各链之间的通讯问题,实现链链之间的并行一致性,这样才能保证每条子链在独立运行的同时,又构成了一个互通互联的并行区块链系统。
而目前成功研发出这一适用于并行系统算法的有一个名为Paralism的项目。据了解,Paralism被称为全球首家并行区块链创新项目,是并行区块链支撑的数字经济平台。Paralism将区块链从线性串行升维到并行系统,具有了以上所提到的动态分片功能、无限扩展性和跨链互联性,更重要的是,它发明了世界上现有唯一适用于并行区块链系统且完全去中心化的共识算法,并已获得授权。
从官网可知,项目从2016年起步。其从区块链原有架构出发,认为区块链发展的一个重要擎制仍是基础设施,只有在底层高效运转且可拓展的基础上,区块链商业应用才能发展和落地,区块链才能担纲未来价值互联的基础技术。
2018年12月,Paralism底层技术团队超块链提交的并行区块链基础技术获得国家授权,此类区块链专利国家级背书在并行链圈鲜见。对于并行区块链而言,最关键的是解决链与链之间的通讯和数据一致性的问题,这也是诸多采用主链+侧链结构并行区块链所存在的核心问题。
超块链自行研发了Buddy共识算法,不同于dPoS的权利为上、也不似PoW的资源浪费,是唯一适用多链环境、完全去中心化的共识算法。具体通过有同样上链请求之间的节点互证来形成共识,使所有节点可以同时参与、并行出块,满足了并行链之间形成系统级全局共识的需求,并且保证了节点之间的对等位置,实现了真正的去中心化,避免特权节点和算力浪费及两者对于网络扩展的影响。
目前,解决扩容度、交互性、个性化、安全性等诸多硬需求,且是由真正的并行区块链技术支撑的数字经济平台Paralism(http://www.paralism.com)已经上线运行。
一链一资产、一链一应用,并行链无限拓容可以做到;发布媲美比特币、各类稳定币等数字资产,可以一键自助式高效发行。破除价值孤岛,链接全球范围数字资产,Buddy共识满足跨链交互,而且,并行链为区块链小白提供了自助开发工具、适配行业需要的自定义共识,并行链的多样性与独立性,让全世界资产及权益在链上尽情传输跳动。
无论在性能上,还是在用户规模上,现在入场做价值链接及工具基础设施提供商,Paralism都以其核心并行区块链技术呈现强大潜力。正如风险投资家马克·安德森在《华盛顿邮报》的一篇采访中所说那样,“在 20 年后,我们就会像讨论今天的互联网一样讨论区块链”。而这里的并行区块链支撑的Paralism有望引领区块链所支撑的价值互联的未来。
四、智能合约和并行执行
1.智能合约和并行冲突
区块链
区块链(blockchain)可以看成是一种新型的分布式事务处理系统,其与传统的分布式事务处理系统主要有 2 点不同:
-
(1) 区块链节点是允许互相不受信任的,故每个节点需独立维护着一份与其它节点一致的账本,即一串 前后相连的区块(block).
-
(2) 对于新区块中的智能合约交易,区块链中的每个节点都将在各自的环境中执行一遍.
智能合约
智能合约(smart contract)是由用户定义并部署在区块链上的代码,类似于编程语言中的类(class),包含了一批共享数据对象和函数,可以通过函数操作数据对象,以向用户提供一些复杂功能.这些数据代表了当 前智能合约的状态,而所有智能合约的状态则构成了当前节点的区块链状态
交易
交易(transaction)又称为事务,是用户从区块链外部调用智能合约的指令,每个交易都可以指定其要调用 的智能合约函数和本次调用输入的参数值.
并行冲突
如果两个并行执行的智能合约交易访问了同一个共享数据对象,并且至少其中一个执行了写操作,那么这 两个合约交易就会产生冲突. 在这种情况下,必须等待前一个合约交易执行完毕,后一个合约交易才能执 行.
依赖关系
如果两个智能合约交易是冲突的,那么它们之间存在依赖关系. 对于一个智能合约交易 Tx, ω(Tx)代表一 组写操作,ρ(Tx)代表一组读作,timestamp(Tx)代表创建该交易的时间戳.如果两个交易 Txi 和 Txj 存在依赖关 系 Txi→Txj,当且仅当 timestamp (Txi) < timestamp (Txj)和下面的至少一个条件同时成立:

因此,判断同一时刻两个合约交易能否被并行执行,就是判断这两个智能合约交易的读写集是否存在交集, 交集为空的合约交易可以被并行执行.
2. 智能合约的执行特点
以太坊等区块链的智能合约执行模型可以抽象分为 2 个阶段.
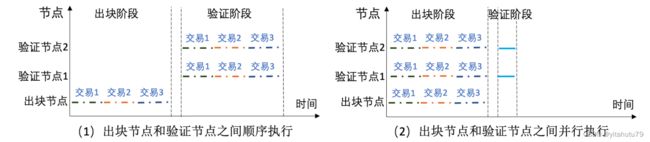
阶段 1 是出块阶段
出块节点选取一批新的智能合约交易,然后串行执行这批交易调用的智能合约以得到 区块链的最终状态(final state), 最终生成一个包含这批交易和区块链最终状态的新区块.
阶段 2 是验证阶段
验证节点接收到新区块时,重新串行执行这批智能合约交易,并将自己节点生成的最终 状态和出块节点生成的最终状态进行比对,如果一致,则接受该区块,如果不一致,则丢弃该区块
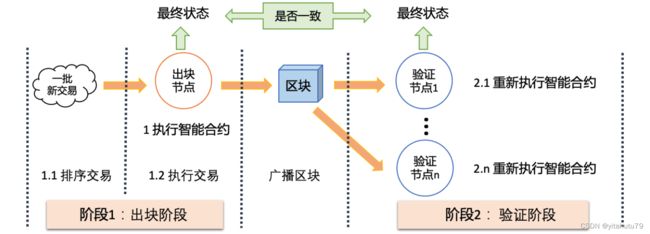
以太坊等区块链执行智能合约的特点可归结如下:
(1) 一个区块包含多个智能合约交易,类似于批处理;
(2) 一个区块中的交易是按照顺序串行执行的,类似于状态机;
(3) 执行过程中包含对共享账本的读写操作;
(4) 每个节点都需要完全执行一遍区块中的智能合约交易.出块节点必须执行这批智能合约交易,才能生成一个完整的新区块.验证节点必须重新执行新区块中的智能合约交易,才能验证该区块的有效性;
(5) 区块中的智能合约交易被执行完毕时,每个节点的最终状态应该一致.
3.并行执行可能引发的问题
并行冲突导致的执行结果错误
在一个区块中,不同的交易可能调用了同一个智能合约.如果直接并行执行这些交易,则可能对智能合约 的共享数据对象进行存在冲突的读写,从而出现丢失更新、脏读等问题,导致最终的执行结果错误.
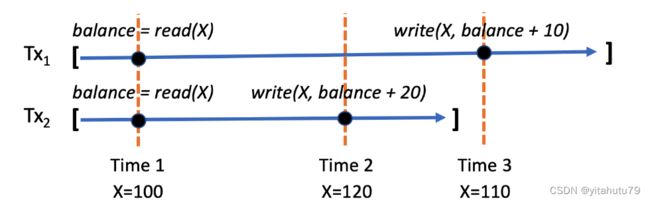
如图所示,智能合约交易 Tx1 和 Tx2 被并行执行,其中 Tx1 表示将用户 X 的账户增加 10 元,Tx2 表示将用 户 X 的账户增加 20 元.在 Time 1 时刻,Tx1 和 Tx2 读取到的 X 的值均为 100.在 Time 2 时刻,Tx2 执行了写入操作,X 的值被更新为 120.在 Time 3 时刻,Tx1 执行了写入操作,X 的值被更新为 110.显然,并行执行 Tx1 和 Tx2 生成的结 果是错误的.
不同的串行化执行顺序导致最终状态的不一致
验证一个区块的有效性需要确定性地执行智能合约交易,验证节点才能产生和出块节点一样的最终状 态.以不同的串行化顺序执行存在冲突的交易,这将可能导致不同节点得到不一致的区块链最终状态.

如图所示,出块节点对并行执行的串行化执行顺序是先执行 Tx1,再执行 Tx2,共享数据对象 a 最终的值是 20.而验证节点对并行执行的串行化执行顺序是先执行 Tx2,再执行 Tx1,共享数据对象 a 最终的值是 10.显然,验 证节点与出块节点分别得到了不一致的区块链最终状态,因此验证节点会丢弃该区块.
4.并行执行的关键任务
为解决并行执行智能合约交易可能引发的问题,实现智能合约的并行执行存在如下 2 项关键任务.
识别具有依赖关系的冲突交易
智能合约交易能否被正确地并行执行的关键在于识别出交易集中具有依赖关系的冲突交易.区块链中执行智能合约类似于多线程操作共享内存中的对象,并行执行的多个智能合约交易可能操作了同一个共享数 据对象,从而产生数据竞争,出现丢失更新和脏读等问题.同时,因为用来编写智能合约的 Solidity等语言是图 灵完备的,直接识别出冲突的合约交易是不太可能的
生成等价的执行顺序
区块链中每个节点的最终状态必须保持一致,因此要求所有节点都能以等价的执行顺序正确地并行执行 同一批智能合约交易.生成等价的执行顺序的关键在于对冲突的交易拥有相同的串行化执行顺序, 这确保了 各个节点并行执行智能合约交易时能够将其中冲突的交易按某种相同的顺序串行执行.如果验证节点只 是简单地重新并行执行新区块中的智能合约交易,则可能会产生不同的串行化执行顺序和不同的区块链最终 状态,从而导致新区块验证失败.因此,所有节点都应该确保其并行执行的串行化顺序是等价的.
五、DAG区块链
1. 什么是DAG?
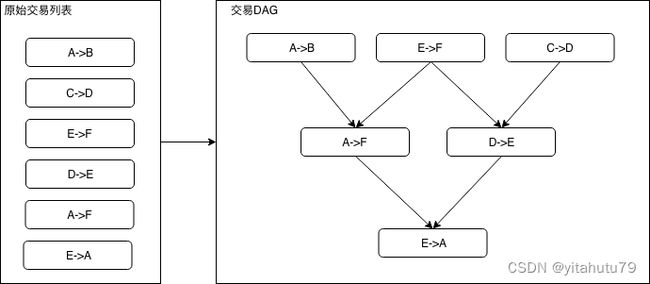
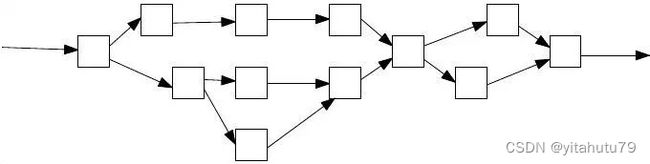
一个无环的有向图称做有向无环图(Directed Acyclic Graph),简称DAG图。在一批交易中,可以通过一定方法识别出每笔交易需要占用的互斥资源,再根据交易在Block中的顺序及互斥资源的占用关系构造出一个交易依赖DAG图,如下图所示,凡是入度为0(无被依赖的前序任务)的交易均可以并行执行。如下图所示,基于左图的原始交易列表的顺序进行拓扑排序后,可以得到右图的交易DAG。
DAG最初出现是为了解决区块链的效率问题。比特币的效率一直比较低,基于工作量证明共识下的出块机制是一个原因,由于链式的存储结构,整个网络中同时只能有一条链,导致出块无法并发执行。
针对此问题,Nxt社区提出改变区块的链式存储结构,变成区块DAG。在区块打包时间不变的情况下,网络中可以并行打包N个区块,网络中的交易就可以容纳N倍。但此种方式仍停留在类似侧链的解决思路,不同的链存储不同类型的交易,这样降低出现双花的可能,在之后某个节点需要合并的时候,几个分支再归并到一个区块。
Nxt社区提出的DAG of blocks
换一种思路,上述方案都属于有区块的情况,无论是在比特币还是以太坊中,我们都会提到出块速度这样的概念,比特币每十分钟出一个块,6 个出块确认需要一个小时,以太坊好很多,但是出块速度也要十几秒。能否舍弃区块的概念呢? 2015年社区提出DAGCoin的概念,把区块和交易融合到了一起。回想下比特币网络中区块和交易的概念,很多笔交易先打包到区块中,区块和区块之间通过 PreHash 来维护全网的交易顺序。而 DAGCoin 的思路是让每一笔交易直接参与维护全网的交易顺序。这样交易被发起后直接跳过打包区块的阶段,直接融入全网,如此达到无区块效果,且连打包交易出块的时间都省去了。如前所述, DAG 最初跟区块链的结合就是为了解决效率问题,现在不用打包确认,交易发起后直接进入确认网络,理论上效率自然会提高很多。
2. DAG区块链与单链技术的对比
(1)单链技术的几个问题
效率问题:传统区块链技术基于区块,比特币的效率一直比较低,由于 BlockChain 链式的存储结构,整个网络同时只能有一条单链,基于 PoW 共识机制出块无法并发执行。
确定性问题:比特币和以太坊存在 51% 算力攻击问题,基于 PoW 共识的最大问题隐患,就是没有一个确定的不可更改的最终状态;如果某群体控制 51% 算力,并发起攻击,比特币体系一定会崩溃;考虑到现实世界中的矿工集团,以及正在快速发展量子计算机的逆天算力,这种危险现实中会存在。
中心化问题:基于区块的PoW共识中,矿工一方面可以形成集中化的矿场集团,另一方面,获得打包交易权的矿工拥有巨大权力,可以选择哪些交易进入区块,哪些交易不被处理,甚至可以只打包符合自己利益的交易,这样的风险目前已经是事实存在。
能耗问题:由于传统区块链基于PoW算力工作量证明,达成共识机制,比特币的挖矿能耗已经与阿根廷整个国家的耗电量持平,IMF和多国政府对虚拟货币挖矿能源消耗持批评态度。Digiconomist 数据表明:全球挖矿业务总计,每年产生约 2.9 亿吨碳排放。
(2)DAG区块链的与单链的区别
单元:区块链组成单元是Block(区块),DAG组成单元是TX(交易)。
拓扑:区块链是由Block区块组成的单链,只能按出块时间同步依次写入,类似于单核单线程CPU;DAG是由交易单元组成的网络,可以异步并发写入交易,类似于多核多线程CPU。
粒度:区块链每个区块单元记录多个用户的多笔交易, DAG 每个单元记录单个用户交易。
3. DAG 区块链的优势与价值
DAG 区块链与传统区块链工作机制的不同之处在于,后者需要矿工完成工作量证明(PoW)来执行每一笔交易,而 DAG 区块链能摆脱区块链的限制来完成这样的操作。不同的是,在 DAG 区块链中一笔交易接着另外一笔,这意味着一笔交易能够对下一笔交易提供证明,由此一直排序下去。这些交易之间的连接就是 DAG,就像区块通过哈希值来向整条区块链提供它们的名字一样。
在传统块链式区块链中,每笔交易都要花费不少时间,而对于 DAG 区块链来说,交易时间将变得微不足道。由于每笔交易都与下一笔交易相连,且矿工被排除在外,交易时长会随着越来越多用户加入系统而缩短。
在DAG系统中,剔除矿工的设置能够避免像区块链系统中某一个矿池集合全网50%算力的威胁,与双重攻击的隐忧。没有了区块链中的工作量证明共识机制,DAG 的交易指令能够极快地扩散通知至全网,大部分双重支付的攻击尝试将会被系统捕捉到并立即拒绝执行。
和以太坊相比,DAG 网络虽然不具备智能合约强制执行的特性,但它能为用户提供一个相对简单、清晰易辨的架构,以太坊的系统则要复杂许多。这不仅使得用户能更容易去理解 DAG 区块链上的虚拟货币什么时候以及怎样进行支付,而非依靠着一个满是程序员和合约的世界。从这个角度来看,可以把 DAG 网络看成是一个智能合约缺席执行者和旁观者的版本。
如果DAG区块链能得到更为广泛的应用,它在几乎每个级别都能显露出比传统区块链更优的特性。在目前区块链系统中,随着交易时长这样的问题显现出来,DAG区块链势必将受到越来越广泛的关注。
六、智能合约并行分类
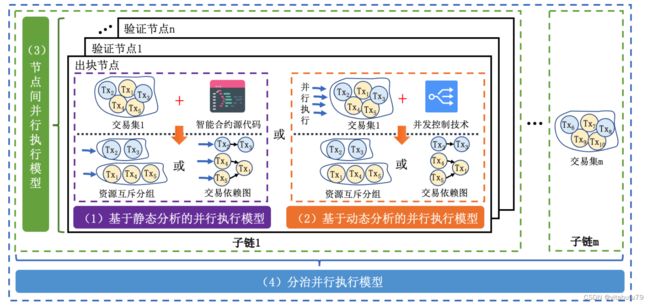
1. 基于静态分析的并行执行模型
基于静态分析的并行执行模型主要分为 2 个模块,资源占用隔离模块和并行执行模块.如图所示,资源占用隔离模块采用静态分析方法,根据智能合约源代码(或其它辅助信息)里对共享数据对象的定义,提取每个 交易将占用的资源集合.然后通过交易依赖图方法或者资源互斥分组方法记录交易间的依赖关系.并行执行模 块可以根据机器的 CPU 核数初始化对应数量的线程,不同的线程并行执行交易依赖图中不存在依赖关系的交 易(或不同的分组),同时无需担心在执行过程中会发生任何冲突.
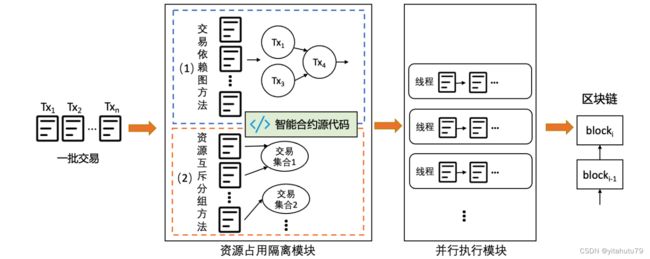
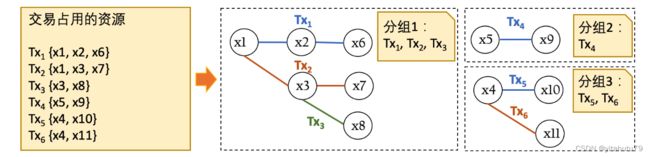
交易依赖图方法
交易依赖图通常使用有向无环图(DAG)表示,其记录了一个区块内所有交易的依赖关系,使用顶点代表交 易,使用有向边代表 2 个交易间的依赖关系,即执行顺序.
基于交易依赖图,区块链节点可以并行执行那些无依赖关系的合约交易.
(1)区块链节点首先根据机器的 CPU 核心数初始化一个相应大小的线程池.
(2)入度为 0 的合约交易允许被不同的线程直接并行执行,如图中 的 Tx1、Tx2 和 Tx3,这个过程是安全的,因为它们没有任何依赖的前驱交易.
(3)执行完毕后,如果被执行的合约交 易所在顶点的出度不为 0,则消除以该顶点为起点的有向边,以该有向边为终点的顶点的入度同时减一.
(4)重复 第 2 步和第 3 步直到区块中全部合约交易都被执行完毕.
资源互斥分组方法
资源互斥分组方法根据合约交易访问的共享资源集合,发现共享资源的占用关系,从而将合约交易按照共 享资源的占用关系划分到不同的组中.访问相同共享资源的合约交易将被划分到同一个分组中,即每个分组的 内部都是存在冲突的合约交易.同时,每个分组之间的交易都是不冲突的,因为它们之间不存在任何共享资源的 交集.
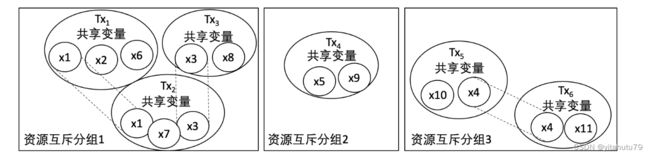
可以通过生成一个资源依赖图(无向图)求得所有分组.如图所示,每个顶点代表一个共享资源,若一个交 易占用了 2 个不同的共享资源,这两个资源的顶点之间将会生成一条无向边.互相冲突的交易将会组成一个连 通分量,每一个连通分量代表了一个独立的分组,因此可以使用并查集,求得所有互斥的分组
2. 基于动态分析的并行执行模型
区块链节点可以采用数据库中的并发控制技术试探地并行执行所有合约交易,以此 来保证并行执行的正确性.
锁方法
锁(locking)是一种悲观的并发控制方法,智能合约交易执行时对某个共享数据对象进行操作(读操作或写 操作),都会对其请求加锁,只要加锁成功,就拥有了对该共享数据对象的控制权.若是排它锁,则在其释放前,其它 智能合约交易不能再对该共享数据对象进行读取和修改;若是共享锁,则在其释放前,其它智能合约交易只能对 该共享数据对象进行读取,但不能修改.
多版本并发控制方法
多版本并发控制(MVCC)是一种可以解决读写冲突的无锁并发控制策略,即使存在读写冲突,也可以实现 不加锁的非阻塞并发读.每个智能合约交易在执行写操作时不会直接覆盖数据项,而是会保留数据项的每个版 本.每个读操作都可以读取到其想要读取版本的数据,因此可以避免因为读太迟而导致的交易冲突.总之,读操 作不用阻塞写操作,写操作不用阻塞读操作,多版本并发控制有效减少了交易冲突.
软件事务内存方法
软件事务内存(STM)作为一种新型的并行编程模式,相较锁机制存在代码复杂度高和易死锁等问题,STM 允许开发者将一组需要访问共享内存的操作封装成一个事务,然后以原子操作的方式运行.该事务满足原子 性和独立性,原子性要求这组操作要么都执行成功,要么都不执行.独立性意味着这组操作所做的更新仅在成功 提交时才对共享内存可见,因此,多个事务可以并行执行,具有乐观性质.
3.节点间并行执行模型
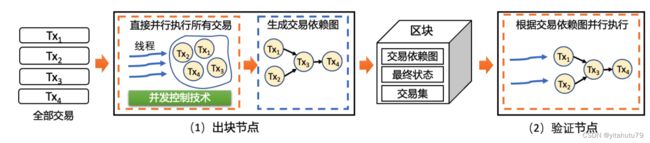
节点间并行执行模型是指通过让区块链节点在交易处理架构“排序-执行-验证-提交”的某个过程并行以 提高区块链系统的吞吐率,其主要包含 2 种并行方法,一是让将“执行交易”置于“排序交易”之前,通过让不 同的区块链节点并行执行来自不同客户端的交易,以提高区块链系统的处理能力.二是针对于全网节点在某一 时刻具有确定的待执行交易集的区块链,让出块节点和验证节点在智能合约交易的执行阶段并行,从而提高区 块链系统的吞吐率.
执行节点和执行节点之间的并行方法
受启发于数据库中乐观并发控制机制,Hyperledger Fabric提出了 一种新的交易处理架构“执行-排序-验证-提交”.这种新架构中,合约交易的排序和执行是分开的,并且将“执 行交易”置于“排序交易”之前.本文将可以执行交易的节点称为执行节点(如 Hyperledger Fabric 中的背书节 点和 XuperChain中的全节点),负责排序出块的节点仍然称为出块节点(如 Hyperledger Fabric 中的排序服务 和 XuperChain 中的矿工节点).
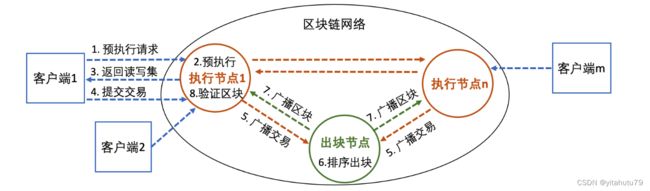
XuperChain 同样采用了“执行-排序-验证-提交”架构.如图所示,客户端首先向一个执行节点提交包含 智能合约执行参数的预执行请求(Hyperledger Fabric 中称为模拟执行);该执行节点基于当前区块链状态进行模拟执行,此过程并不修改该执行节点的区块链账本状态,然后将读写集返回给客户端;客户端组装一个包含该读 写集的交易,发送给区块链网络;出块节点收集和排序一批交易以生成一个新区块,并将其广播给所有执行节 点;执行节点验证新区块的有效性,并更新本地的区块链账本状态.
显然,一个执行节点除了自身可以并行处理不同的预执行请求,还能与其它执行节点并行处理更多的来自 不同客户端的预执行请求,这是一种并行能力的放大.
出块节点和验证节点之间的并行方法
采用 PoW 共识机制的区块链,所有节点都在争夺出块权,并不能确定哪个节点是此时的出块节点,每个节 点打包的交易集是不同的,具有随机性.因此,验证节点必须在出块节点生成新区块之后才能知道需要执行的 交易集,即验证阶段的交易执行一定位于出块阶段的交易执行之后.但对于许可链,节点间是互相信任的,可以 由专门的节点(可以是出块节点)选择一批新交易进行排序,再广播给其它节点执行.
如图所示,因为交易集和出块节点在此刻是确定的,那么可以让所有节点(包括出块节点和验证节点)同 时执行交易集,等待出块节点执行完所有智能合约交易之后,出块节点将包含执行结果的新区块广播给其它节 点,其它节点通过比较自己的区块链最终状态和出块节点的区块链最终状态是否一致以判断出块节点生成的 新区块的有效性.
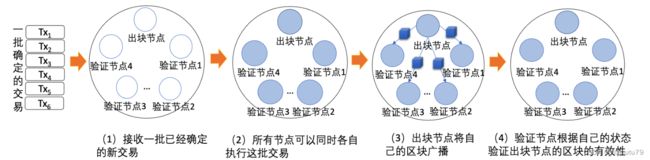
这种出块节点和验证节点并行的方式,让验证节点不必等待出块节点将智能合约交易执行 完毕就可以开始执行这批智能合约交易,这极大地缩短了验证阶段的耗时.
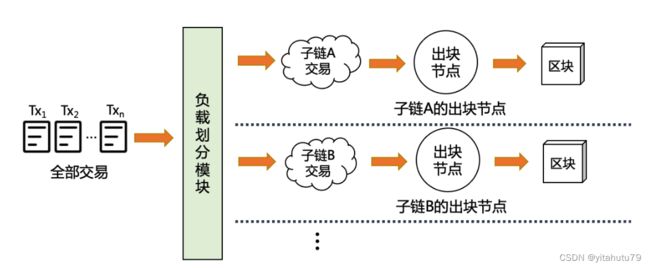
4. 分治并行执行模型
分治并行执行模型如图所示,负载划分模块根据一定的规则,将全部的合约交易划分为不同的子集,并 分配到不同的子链进行执行.因为子链之间是并行的,从而提高了整个区块链系统的吞吐率.
分片方法
分片方法(sharding) 是一种被给予厚望的并行方案, 其能够对网络中的计算资源实现更有效的管理.分片方法将整个区块链根据一定规则划分成多个子集,每个子集被称为一个分片(shard),每个分片具 有独立的状态和账本.区块链网络中所有新交易将按照规则分配到不同的分片中,分片间并行执行这些交易.由 于每个分片只需要处理一部分交易,因此增加了整个区块链系统的吞吐量.在比特币、以太坊等传统区块链中, 增加节点的数量只会增加系统的安全性,但不会增加系统的吞吐率.与此不同的是,采用分片方法的区块链因为 分片数量的增加,其交易处理的并行度也将线性增加.
通道方法
通道方法(channel)被开源的企业级许可链平台 Hyperledger Fabric采用,具有极佳的保密性和可伸缩 性.比如在一个供应链金融的区块链网络中,参与方包括核心企业、供应商、银行和物流企业等.不同的参与方 各自运行一个区块链节点.显然,该区块链提供的金融服务不需要物流企业的节点参与共识和保存账本数据.同 时,该区块链提供的物流服务也不需要金融机构的节点参与共识和保存账本数据.通道方法允许需要进行私有 交易的成员与业务竞争者或其他受限制的成员在同一个区块链网络中共存.
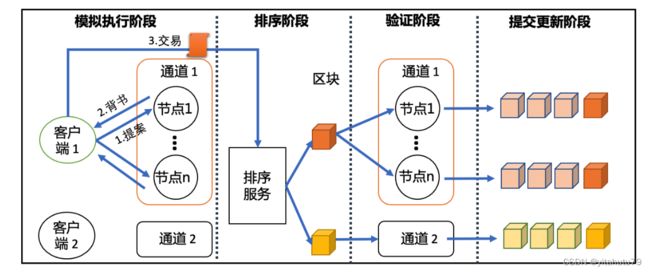
通道相当于某几个网络成员之间进行通信的私有“子网”,每个通道都维护着自己的账本数据.在模拟执行阶段,每个背书节点只接收和执行在其通道内有权限的客户端发起的交易提案.在排序阶段, 排序服务为每个通道创建单独的区块.在验证阶段,节点只接收在同一个通道上的区块进行验证.在提交更新阶 段,验证通过的区块只会追加到在同一个通道的节点的账本.可以发现,Hyperledger Fabric 的通道隔离模型类似 于其它区块链的分链模型,通道为交易处理的各个方面都带来固有的并行性
分区方法
分区方法被王嘉平等提出的 Monoxide 区块链采用.如图所示,系统会被分为多个区域(zones),每个分 区被称为一个异步共识区.每个异步共识区都拥有自己的区块链账本、状态数据库等,能够在各自的分区内完 成交易的处理和区块的共识.不同的合约交易会根据规则映射到某个分区进行处理,不同分区的合约交易因此 可以被并行执行,从而提高了整个区块链系统的吞吐率.分治并行执行模型都会存在因为算力稀释导致子链安 全性下降的问题. 这是因为每个子链只是由系统中的部分节点运行.对于区块链来说,越多的节点参与共识, 黑客聚集大于 51%算力的难度就越大,系统就越安全.与其它分治并行执行模型不同的是,王嘉平等提出了“连 弩挖矿”方法以应对算力稀释导致的安全性下降问题
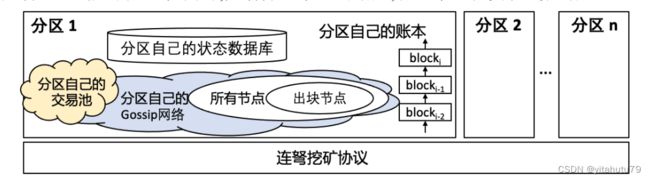
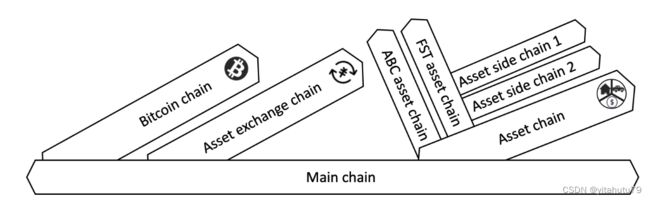
侧链方法
侧链方法同样被许多区块链采用以实现智能合约交易并行执行.aelf 是一个基于多级侧链的并行化区块 链框架,其主链负责统一规划和索引,侧链独立运行,每条侧链专门负责一项功能服务.不同功能服务的合约 交易可以在所属的侧链上并行执行,因此得以提高整个区块链系统的合约交易执行效率.同时,侧链可以通过主 链的验证以实现跨链交互.此外,每个子链中采用了资源互斥分组方法,交易集会根据冲突关系被划分为多个分 组,同组内的合约交易串行执行,不同组的合约交易并行执行.
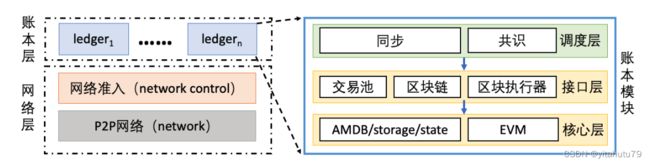
群组方法
群组方法被 FISCO BCOS用来实现其分治并行执行模型.每个区块链节点都可以根据实际业务关系,自 由组成多个群组.如图所示,每个群组拥有一个属于自己的独立账本,其交易处理、数据存储和区块共识都是 与其它群组相互隔离的.这种架构在保障隐私性的同时,允许不同群组间的交易合约可以被并行执行,从而提高了整个区块链系统的处理能力.
七、区块链并行处理应用实例
1. 基于DAG的并行交易执行引擎
区块链世界中,交易是组成事务的基本单元。交易吞吐量很大程度上能限制或拓宽区块链业务的适用场景,愈高的吞吐量,意味着区块链能够支持愈广的适用范围和愈大的用户规模。当前,反映交易吞吐量的TPS(Transaction per Second,每秒交易数量)是评估性能的热点指标。为了提高TPS,业界提出了层出不穷的优化方案,殊途同归,各种优化手段的最终聚焦点,均是尽可能提高交易的并行处理能力,降低交易全流程的处理时间。
在多核处理器架构已经成为主流的今天,利用并行化技术充分挖掘CPU潜力是行之有效的方案。FISCO BCOS 2.0 中设计了一种基于DAG模型的并行交易执行器(PTE,Parallel Transaction Executor)。
PTE能充分发挥多核处理器优势,使区块中的交易能够尽可能并行执行;同时对用户提供简单友好的编程接口,使用户不必关心繁琐的并行实现细节。基准测试程序的实验结果表明:相较于传统的串行交易执行方案,理想状况下4核处理器上运行的PTE能够实现约200%~300%的性能提升,且计算方面的提升跟核数成正比,核数越多性能越高。
PTE为助力FISCO BCOS性能腾飞奠定了坚实基础,本文将全面介绍PTE的设计思路及实现方案,主要包括以下内容:
背景:传统方案的性能瓶颈与DAG并行模型的介绍
设计思路:PTE应用到FISCO BCOS中时遇到的问题以及解决方案
架构设计:应用PTE后FISCO BCOS的架构及核心流程
核心算法:介绍主要用到的数据结构与主要算法
性能测评:分别给出PTE的性能与可扩展性测试结果
背景
FISCO BCOS交易处理模块可以被抽象为一个基于交易的状态机。在FISCO BCOS中,『状态』即是指区块链中所有账户的状态,而『基于交易』即是指FISCO BCOS将交易作为状态迁移函数,并根据交易内容从旧的状态更新为新的状态。FISCO BCOS从创世块状态开始,不断收集网络上发生的交易并打包为区块,并在所有参与共识的节点间执行区块中的交易。当一个区块内的交易在多个共识节点上执行完成且状态一致,则我们称在该块上达成了共识,并将该区块永久记录在区块链中。
从上述区块链的打包→共识→存储过程中可以看到,执行区块中的所有交易是区块上链的必经之路。传统交易执行方案是:执行单元从待共识的区块逐条读出交易,执行完每一笔交易后,状态机都会迁移至下一个状态,直到所有交易都被串行执行完成,如下图所示:
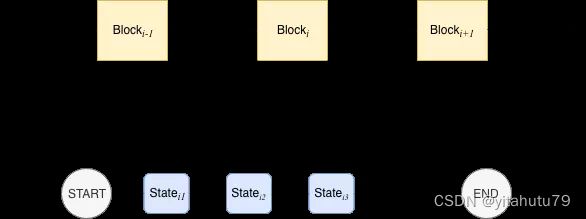
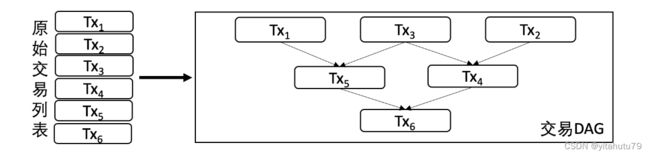
显而易见,这种交易执行方式对性能并不友好。即使两笔交易没有交集,也只能按照先后顺序依次执行。就交易间的关系而言,既然一维的『线』结构有这般痛点,那何不把目光投向二维的『图』结构呢?
在实际应用中,根据每笔交易执行时需要使用的互斥资源(互斥意味着对资源的排他性使用,比如在上述转账问题互斥资源中,指的就是各个账户的余额状态), 我们可以组织出一张交易依赖关系图,为防止交易依赖关系在图中成环,我们可以规定交易列表中牵涉到相同的互斥资源,且排序靠后的交易,必须等待靠前的交易完成后才被执行,由此得到的输出便是一张反映交易依赖关系的有向无环图,即交易DAG。
如下图所示,左侧的6笔转账交易可以组织为右侧的DAG形式:
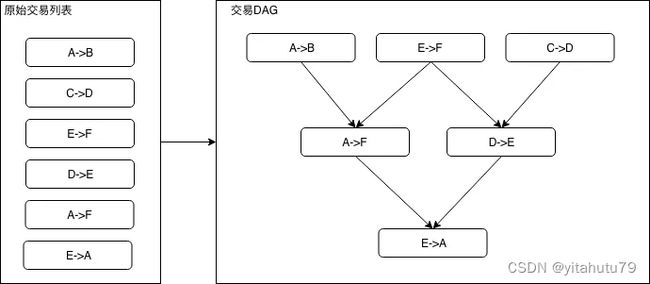
在交易DAG中,入度为0的交易是没有任何依赖项、可以被立即投入运行的就绪交易。当就绪交易的数量大于1时,就绪交易可以被分散至多个CPU核心上并行执行。当一笔交易执行完,依赖于该交易的所有交易的入度减1,随着交易不断被执行,就绪交易也源源不断被产生。在极限情况下,假如构造出的交易DAG层数为1 (即所有交易均是没有依赖项的独立交易),则交易整体执行速度的提升倍数将直接取决于处理器的核心数量n,此时若n大于区块内的交易数,则区块内所有交易的执行时间与单笔交易执行的时间相同。
理论上拥有如此让人无法拒绝的优美特性的交易DAG模型,该如何应用至FISCO BCOS中?
设计思路
要应用交易DAG模型,我们面临的首要问题便是:对于同一个区块,如何确保所有节点执行完后能够达到同一状态,这是一个关乎到区块链能否正常出块的关键问题。
FISCO BCOS采用验证(state root, transaction root, receipt root)三元组是否相等的方式,来判断状态是否达成一致。transaction root是根据区块内的所有交易算出的一个哈希值,只要所有共识节点处理的区块数据相同,则transaction root必定相同,这点比较容易保证,因此重点在于如何保证交易执行后生成的state和receipt root也相同。
众所周知,对于在不同CPU核心上并行执行的指令,指令间的执行顺序无法提前预测,并行执行的交易也存在同样情况。在传统的交易执行方案中,每执行一笔交易,state root便发生一次变迁,同时将变迁后的state root写入交易回执中,所有交易执行完后,最终的state root就代表了当前区块链的状态,同时再根据所有交易回执计算出一个receipt root。
可以看出,在传统的执行方案中,state root扮演着一个类似全局共享变量的角色。当交易被并行且乱序执行后,传统计算state root的方式显然不再适用,这是因为在不同的机器上,交易的执行顺序一般不同,此时无法保证最后的state root能够一致,同理,receipt root也无法保证一致。
在FISCO BCOS中,我们采用的解决方案是先执行交易,将每笔交易对状态的改变历史记录下来,待所有交易执行完后,再根据这些历史记录再算出一个state root,同时,交易回执中的state root,也全部变为所有交易执行完后最终的state root,由此就可以保证即使并行执行交易,最后共识节点仍然能够达成一致。
搞定状态问题后,下一个问题便是:如何判断两笔交易之间是否存在依赖关系?
若两笔交易本来无依赖关系但被判定为有,则会导致不必要的性能损失;反之,如果这两笔交易会改写同一个账户的状态却被并行执行了,则该账户最后的状态可能是不确定的。因此,依赖关系的判定是影响性能甚至能决定区块链能否正常工作的重要问题。
在简单的转账交易中,我们可以根据转账的发送者和接受者的地址,来判断两笔交易是否有依赖关系,比如如下3笔转账交易:A→B,C→D,D→E,可以很容易看出,交易D→E依赖于交易C→D的结果,但是交易A→B和其他两笔交易没有什么关系,因此可以并行执行。
这种分析在只支持简单转账的区块链中是正确的,但是一旦放到图灵完备、运行智能合约的区块链中,则可能不那么准确,因为我们无法准确知道用户编写的转账合约中到底有什么操作,可能出现的情况是:A->B的交易看似与C、D的账户状态无关,但是在用户的底层实现中,A是特殊账户,通过A账户每转出每一笔钱必须要先从C账户中扣除一定手续费。在这种场景下,3笔交易均有关联,则它们之间无法使用并行的方式执行,若还按照先前的依赖分析方法对交易进行划分,则必定会掉坑。
我们能否做到根据用户的合约内容自动推导出交易中实际存在哪些依赖项?答案是不太靠谱。我们很难去追踪用户合约中到底操作了什么数据,即使做到也需要花费不小的成本,这和我们优化性能的目标相去甚远。
综上,我们决定在FISCO BCOS中,将交易依赖关系的指定工作交给更熟悉合约内容的开发者。具体地说,交易依赖的互斥资源可以由一组字符串表示,FISCO BCOS暴露接口给到开发者,开发者以字符串形式定义交易依赖的资源,告知链上执行器,执行器则会根据开发者指定的交易依赖项,自动将区块中的所有交易排列为交易DAG。比如在简单转账合约中,开发者仅需指定每笔转账交易的依赖项是{发送者地址+接收者地址}。进一步地,如开发者在转账逻辑中引入了另一个第三方地址,那么依赖项就需要定义为{发送者地址+接受者地址+第三方地址}了。
这种方式实现起来较为直观简单,也比较通用,适用于所有智能合约,但也相应增加了开发者肩上的责任,开发者在指定交易依赖项时必须十分小心,如果依赖项没有写正确,后果无法预料。指定依赖项的相关接口会在后续文章中给出使用教程,本文暂且假定所有谈论到的交易依赖项都是明确无误的。
解决完上面两个比较重要的问题后,还剩下一些较为细节的工程问题:比如并行交易能否和非并行交易混合到一起执行?怎么保证资源字符串的全局唯一性?
答案也不复杂,前者可通过将非并行交易作为屏障(barrier)插入到交易DAG中——即我们认为,它即依赖于它的所有前序交易,同时又被它的所有后序交易依赖——来实现;后者可以通过在开发者指定的交易依赖项中,加入标识合约的特殊标志位解决。由于这些问题并不影响PTE的根本设计,本文暂不展开。
万事俱备,带着全新交易执行引擎PTE的FISCO BCOS已经呼之欲出。
架构设计
搭载PTE的FISCO BCOS架构图:
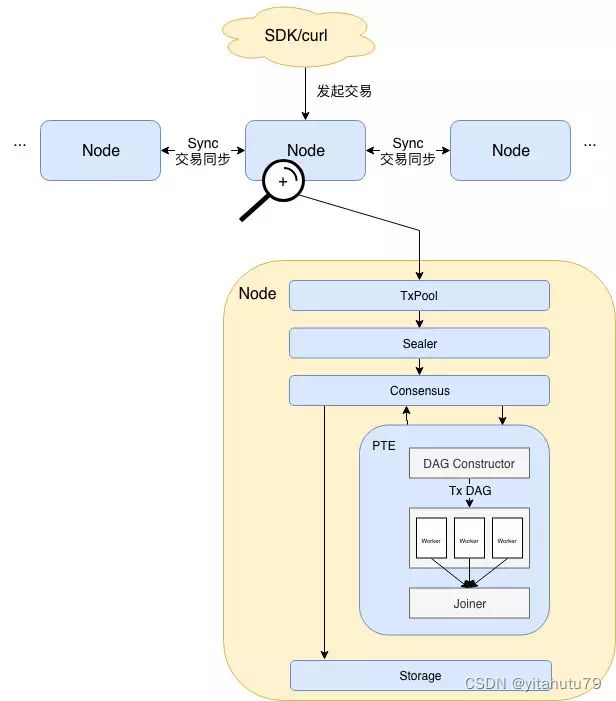
整个架构的核心流程如下:
用户通过SDK等客户端将交易发送至节点,此处的交易既可以是可并行执行的交易,也可以是不能并行执行的交易。随后交易在节点间同步,同时拥有打包权的节点调用打包器(Sealer),从交易池(Tx Pool)中取出一定量交易并将其打包成一个区块。此后,区块被发送至共识单元(Consensus)准备进行节点间共识。
共识前需要执行区块中的交易,此处便是PTE施展威力之处。从架构图中可以看到,PTE首先按序读取区块中的交易,并输入到DAG构造器(DAG Constructor)中,DAG构造器会根据每笔交易的依赖项,构造出一个包含所有交易的交易DAG,PTE随后唤醒工作线程池,使用多个线程并行执行交易DAG。汇合器(Joiner)负责挂起主线程,直到工作线程池中所有线程将DAG执行完毕,此时Joiner负责根据各个交易对状态的修改记录计算state root及receipt root,并将执行结果返回至上层调用者。
在交易执行完成后,若各个节点状态一致,则达成共识,区块随即写入底层存储(Storage),被永久记录于区块链上。
核心算法
交易DAG的数据结构
交易DAG的数据结构如下图所示:

Vertex类为最基础里的类型,在交易DAG中,每一个Vertex实例都表征一笔交易。Vertex类包含:
- inDegree:表示该顶点的入度
- outEdges:用于存储该节点的出边信息,即所有出边所连顶点的ID列表
DAG类用于对DAG的顶点与边关系进行封装,并提供操作DAG的接口,其包含:
- vtxs:Vertex数组
- topLevel:包含所有入度为0的顶点的队列,由于在执行过程中topLevel会动态变化且会被多个线程访问,因此其需要一个能够支持线程安全访问的容器
- void init(int32_t size)接口:根据传入的size初始化一个包含相应数量顶点的DAG结构
- addEdge(ID from, ID to)接口:用于在顶点from和顶点to之间建立边关系,具体地说,将顶点to的ID加入顶点from的outEdges中
- void generate()接口:当所有的边关系录入完毕后,调用该方法以初始化topLevel成员
- ID waitPop()接口:从topLevel中获取一个入度为0的顶点ID
TxDAG类是DAG类更上一层的封装,是DAG与交易之间建立联系的桥梁,其包含:
- dag:持有的DAG类实例
- exeCnt:已执行过的交易总数
- totalTxs:交易总数
- txs:区块中的交易列表
交易DAG的构造流程
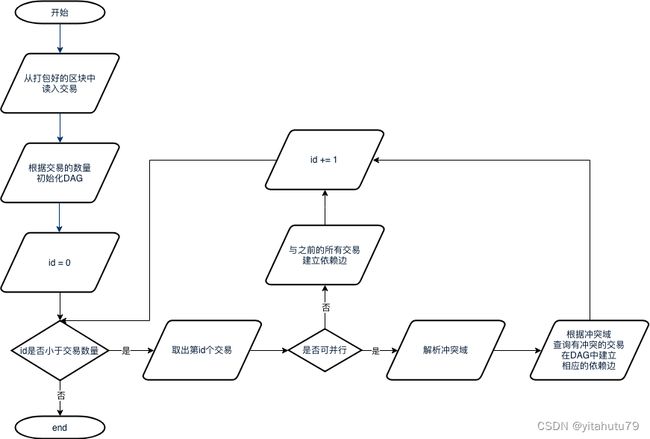
从打包好的区块从取出区块中的所有交易;
将交易数量作为最大顶点数量初始化一个DAG实例;
按序读出所有交易,如果一笔交易是可并行交易,则解析其冲突域,并检查是否有之前的交易与该交易冲突,如果有,则在相应交易间构造依赖边;
若该交易不可并行,则认为其必须在前序的所有交易都执行完后才能执行,因此在该交易与其所有前序交易间建立一条依赖边。
DAG构造器在构造交易DAG时,会首先将totalTxs成员的值设置为区块中的交易总数,并依据交易总数对dag对象进行初始化,dag会在vtxs中为每笔交易生成一个位置关系一一对应的顶点实例。随后,初始化一个空的资源映射表criticalFields,并按序逐个扫描每笔交易。
对于某笔交易tx,DAG构造器会在其解析出该交易的所有依赖项,对于每个依赖项均会去criticalFields中查询,如果对于某个依赖项d,有前序交易也依赖于该依赖项,则在这两笔交易间建边,并更新criticalFields中d的映射项为tx的ID。
交易DAG构造流程的伪代码如下所示:
criticalFields ← map<string, ID>();
totalTxs ← txs.size();
dag.init(txs.size());
for id ← 0 to txs.size() by 1 do
tx ← txs[id];
dependencies ← 解析出tx的依赖项;
for d in dependencies do
if d in criticalFields then
dag.addEdge(id, criticalFields[d]);
end
criticalFields[d] = id;
end
end
end
dag.generate();
Copy to clipboard
交易DAG的执行流程
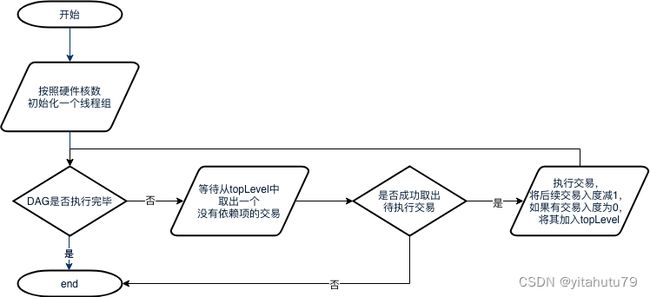
主线程会首先根据硬件核数初始化一个相应大小的线程组,若获取硬件核数失败,则不创建其他线程;
当DAG尚未执行完毕时,线程循环等待从DAG中pop出入度为0的交易。
若成功取出待执行的交易,则执行该交易,执行完后将后续的依赖任务的入度减1,若有交易入度被减至0,则将该交易加入topLevel中;
若失败,则表示DAG已经执行完毕,线程退出。
PTE在被创建时,会根据配置生成一个用于执行交易DAG的工作线程池,线程池的大小默认等于CPU的逻辑核心数,此线程池的生命周期与PTE的生命周期相同。工作线程会不断调用dag对象的waitPop方法以取出入度为0的就绪交易并执行,执行后该交易的所有后序依赖任务的入度减1,若有交易的入度被减至0,则将该交易加入到topLevel中。循环上述过程,直到交易DAG执行完毕。
交易DAG执行流程的伪代码如下所示:
while exeCnt < totalTxs do
id ← dag.waitPop();
tx ← txs[id];
执行tx;
exeCnt ← exeCnt + 1;
for txID in dag.vtxs[id].outEdges do
dag.vtxs[txID].inDegree ← dag.vtxs[txID].inDegree - 1;
if dag.vtxs[txID].inDegree == 0 then
dag.topLevel.push(txID)
end
end
end
Copy to clipboard
性能测评
我们选用了2个基准测试程序,用以测试PTE给FISCO BCOS的性能带来了怎样的变化,它们分别是基于预编译框架实现的转账合约和基于Solidity语言编写的转账合约,两份合约代码的路径分别为:
FISCO-BCOS/libprecompiled/extension/DagTransferPrecompiled.cpp
web3sdk/src/test/resources/contract/ParallelOk.sol
我们使用一条单节点链进行测试,因为我们主要关注PTE的交易处理性能,因此并不考虑网络、存储的延迟带来的影响。
测试环境的基本硬件信息如下表所示:

性能测试
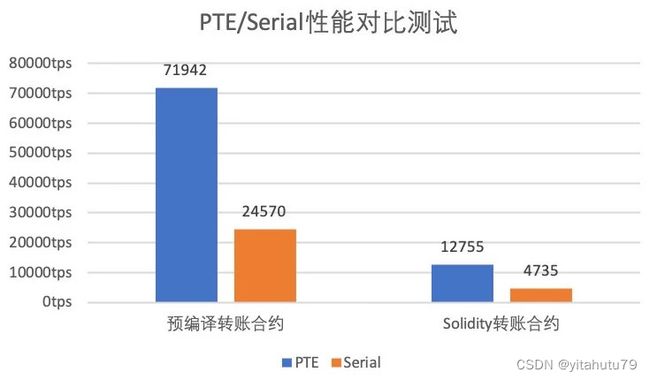
性能测试部分,我们主要测试PTE和串行交易执行方式(Serial)在各个测试程序下的交易处理能力。可以看到,相对于串行执行方式,PTE从左至右分别实现了2.91和2.69倍的加速比。无论是对于预编译合约还是Solidity合约,PTE均有着不俗的性能表现。
可扩展性测试
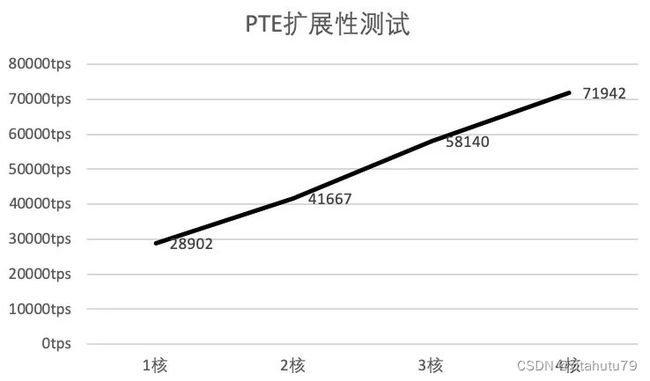
可扩展性测试部分,我们主要测试PTE在不同CPU核心数下的交易处理能力,使用的基准测试程序是基于预编译框架实现的转账合约。可以看到,随着核数增加,PTE的交易吞吐量呈近似线性递增。但是同时也能看到,随着核数在增加,性能增长的幅度在放缓,这是因为随着核数增加线程间调度及同步的开销也会增大。
瓶颈
对这个阶段性结果,我们并不满足,继续深入挖掘发现,FISCO BCOS 的整体 TPS 仍有较大提升空间。 用木桶打个比方:如果参与节点的交易处理所有模块构成木桶,交易执行只是组成整个木桶的一块木板,根据短板理论,一只木桶能盛多少水取决于桶壁上最矮的那块,同理,FISCO BCOS 的性能也由速度最慢的组件决定。
尽管 PTE 取得了理论上极高的性能容量,但是 FISCO BCOS 的整体性能仍然会被其他模块较慢的交易处理速度所掣肘。为了能够最大化利用计算资源以进一步提高交易处理能力,在 FISCO BCOS 中全面推进并行化改造势在必行。
数据分析
根据并行程序设计的『分析→分解→设计→验证』四步走原则,首先需定位出系统中仍存在的性能瓶颈的精确位置,才能更深入地对任务进行分解,并设计相应的并行化策略。使用自顶向下分析法,我们将交易处理流程分为四个模块进行性能分析,这四个模块分别是:
区块解码(decode):
区块在节点间共识或同步时需要从一个节点发送至另一个节点,这个过程中,区块以 RLP 编码的形式在网络间传输。节点收到区块编码后,需要先进行解码,将区块还原为内存中的二进制对象,然后才能做进一步处理。
交易验签(verify):
交易在发送之前由发送者进行签名,签名得到的数据可以分为 (v, r, s) 三部分,验签的主要工作便是在收到交易或交易执行前,从 (v, r, s) 数据中还原出交易发送者的公钥,以验证交易发送者的身份。
交易执行(execute):
执行区块中的所有交易,更新区块链状态。
数据落盘(commit):
区块执行完成后,需要将区块及相关数据写入磁盘中,进行持久化保存。
以包含 2500 笔预编译转账合约交易的区块为测试对象,在我们的测试环境中,各阶段的平均耗时分布如下图所示:
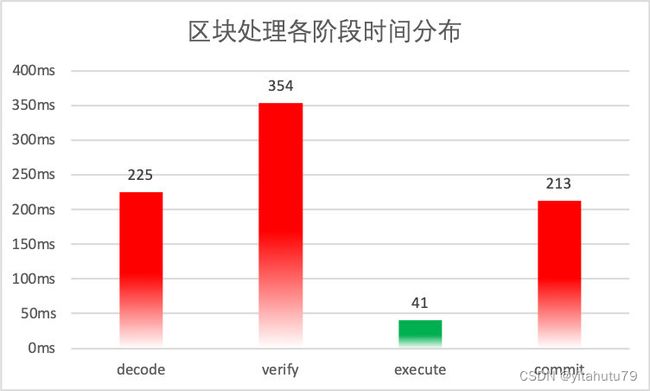
从图中可以看出,2500 笔交易的执行时间已经被缩短到了 50 毫秒以内,可以证明 PTE 对 FISCO BCOS 交易执行阶段的优化是行之有效的。但图中也暴露出了非常明显的问题:其他阶段的用时远远高于交易执行的用时,导致交易执行带来的性能优势被严重抵消,PTE 无法发挥出其应有的价值。
早在 1967 年,计算机体系结构领域的元老 Amdahl 提出的以他名字命名的定律,便已经向我们阐明了衡量处理器并行计算后效率提升能力的经验法则:

其中,SpeedUp 为加速比,Ws 是程序的串行分量,Wp 是程序中的并行分量,N 为 CPU 数量。可以看出,在工作总量恒定的情况下,可并行部分代码占比越多,系统的整体性能越高。我们需要把思维从线性模型中抽离出来,继续细分整个处理流程,找出执行时间最长的程序热点,对这些代码段进行并行化从而将所有瓶颈逐个击破,这才是使通过并行化获得最大性能提升的最好办法。
根因拆解
串行的区块解码
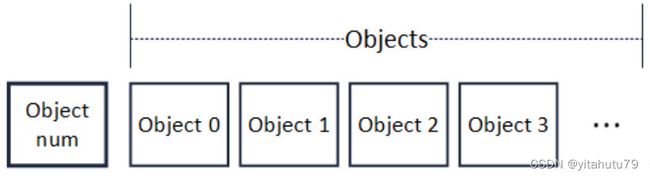
区块解码主要性能问题出在 RLP 编码方法本身。RLP 全称是递归的长度前缀编码,是一种用长度作为前缀标明编码对象中元素个数的编码方法。如下图所示,RLP 编码的开头即是此编码中的对象个数(Object num)。在个数后,是相应个数的对象(Object)。递归地,每个对象,也是 RLP 编码,其格式也与下图相同。
需要特别注意的是,在 RLP 编码中。每个 Object 的字节大小是不固定的,Object num 只表示 Object 的个数,不表示 Object 的字节长度。
RLP 通过一种长度前缀与递归结合的方式,理论上可编码任意个数的对象。下图是一个区块的 RLP 编码,在对区块进行编码时,先递归至最底层,对多个 sealer 进行编码,多个 sealer 被编码并加上长度前缀后,编码成为一串 RLP 编码(sealerList),此编码又作为一个对象,被编入上层的一串 RLP 编码(blockHeader)中。此后层层递归,最后编码成为区块的 RLP 编码。由于 RLP 编码是递归的,在编码前,无法获知编码后的长度。
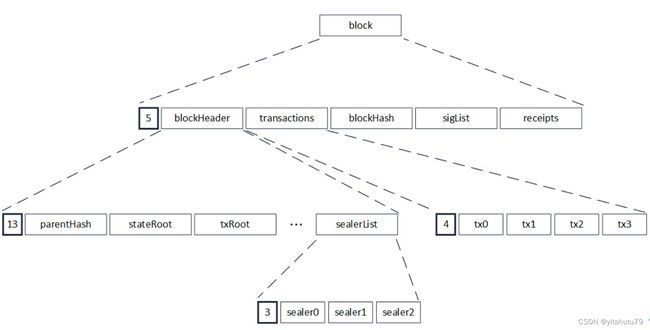
解码时,由于 RLP 编码中每个对象的长度不确定,且 RLP 编码只记录了对象的个数,没记录对象的字节长度,若要获取其中的一个编码对象,必须递归解码其前序的所有对象,在解码前序的对象后,才能访问到需要访问的编码对象的字节位置。例如在上图中,若需要访问区块中的第 0 笔交易,即 tx0,必须先将 blockHeader 解码,而 blockHeader 的解码,需要再次递归,把 parentHash,stateRoot 直至 sealerList 都解码出来。
解码区块最重要的目的是解码出包含在区块中的交易,而交易的编码都是互相独立的,但在 RLP 特殊的编码方式下,解码一笔交易的必要条件是解码出上一笔交易,交易的解码任务之间环环相扣,形成了一种链式的依赖关系。需要指出的是,这种解码方式并不是 RLP 的缺陷,RLP 的设计目标之一本就是尽量减少空间占用,充分利用好每一个字节,虽然编解码变得低效了些,但编码的紧凑度却是有目共睹,因此这种编码方式本质上还是一种时间换空间的权衡结果。
由于历史原因,FISCO BCOS 中使用了 RLP 编码作为多处信息交换协议,贸然换用其他并行化友好的序列化方案可能会带来较大的开发负担。基于这一考虑,我们决定在原有的 RLP 编解码方案稍作修改,通过为每个被编码的元素添加额外的位置偏移信息,便可以做到并行解码 RLP 的同时不会改动大量原有代码。
交易验签 & 数据落盘开销大
通过对交易验签和数据落盘部分的代码进行拆解,我们发现两者的主要功能都集中在一个耗时巨大的 for 循环。交易验签负责按序取出交易,然后从交易的签名数据中取出 (v, r, s) 数据,并从中还原出交易发送者的公钥,其中,还原公钥这一步,由于涉及密码学算法,因此耗时不少;数据落盘负责从缓存中逐个取出交易相关数据,将其编码为 JSON 字符串后写入磁盘,由于 JSON 编码过程本身效率比较低,因此也是性能损失的重灾区。
两者代码分别如下所示:
// 交易验签
for(int i = 0; i < transactions.size(); ++i)
{
tx = transactions[i];
v, r, s = tx.getSignature();
publicKey = recover(v, r, s); // 从 (v, r, s) 中复原出发送者公钥
...
}
复制代码
// 数据落盘
for(int i = 0; i < datas.size(); ++i)
{
data = datas[i];
jsonStr = jsonEncode(data); // 将数据编码为 JSON 字符串进行存储
db.commit(jsonStr);
...
}
两个过程共有的特点是,它们均是将同样的操作应用到数据结构中不同的部分,对于这种类型的问题,可以直接使用数据级并行进行改造。所谓数据级并行,即是将数据作为划分对象,通过将数据划分为大小近似相等的片段,通过在多个线程上对不同的数据片段上进行操作,达到并行处理数据集的目的。
数据级并行唯一的附加要求是任务之间彼此独立,毫无疑问,在 FISCO BCOS 的实现中,交易验签和数据落盘均满足这一要求。
优化实践
区块解码并行化
改造过程中,我们在系统中使用的普通 RLP 编码的基础上,加入了 offset 字段,用以索引每个 Object 的位置。如下图所示,改造后编码格式的开头,仍然是对象的个数(Object num),但是在个数字段后,是一个记录对象偏移量的数组(Offsets)。
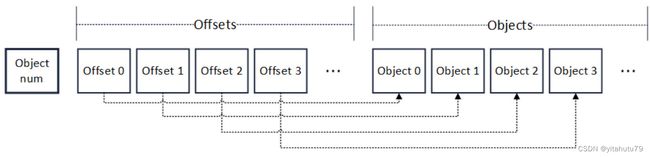
数组中的每个元素有着固定的长度。因此要读取某个 Offset 的值,只需向访问数组一样,根据 Offset 的序号直接索引便可以进行随机访问。在 Offsets 后,是与 RLP 编码相同的对象列表。相应序号的 Offset,指向相应序号的对象的 RLP 编码字节位置。因此,任意解码一个对象,只需要根据对象的序号,找到其偏移量,再根据偏移量,就可定位到相应对象的 RLP 编码字节位置。
编码流程也进行了重新设计。流程本身仍然基于递归的思路,对于输入的对象数组,首先将对象数组的大小编码在输出编码的开头处,若数组大小超过 1,则按序逐个取出待编码对象并缓存其递归编码,并在 Offsets 数组中记录该对象的偏移位置,待数组遍历完后,将缓存的对象编码第一次性取出并附加至输出编码末尾;若数组大小为 1,则递归对其编码并写入输出编码的末尾,结束递归。
编码流程的伪代码如下:
Rlps = RLP(); // Output,初始时为空
void encode(objs) //Input: objs = 待编码对象的数组
{
offset = 0;
codes = [];
objNum = objs.size()
Rlps.push(objNum)
if objNum > 1
{
for obj in objs
{
rlp = encode(obj); // 递归调用编码方法
Rlps.push(offset);
offset += rlp.size();
codes.add(rlp); // 缓存递归编码的结果
}
for x in codes
{
Rlps.push(x);
}
}
else
{
rlp = encode(objs[0]);
Rlps.push(rlp);
}
}
偏移量的引入使解码模块能够对元素编码进行随机访问。Offsets 的数组范围可以在多个线程间均摊,从而每个线程可以并行访问对象数组的不同部分,分别进行解码。由于是只读访问,这种并行方式是线程安全的,仅需最后再对输出进行汇总即可。
解码流程的伪代码如下:
Objs decode(RLP Rlps)
{
objNum = Rlps.objNum; // 获取对象个数
outputs = [] // 输出的对象数组
if objNum > 1
{
parallel for i = 0 to objNum
{
offset = Rlps.offsets[i];
code = Rlps.objs[offset];
x = decode(code);
outputs.add(x); // 有序插入 outputs
}
}
else
{
outputs.add(decode(Rlps.objs[0]));
}
return outputs;
}
交易验签 & 数据落盘并行化
对于数据级并行,业内已有多种成熟的多线程编程模型。虽然 Pthread 这类显式的多线程编程模型能够提供对线程进行更精细的控制,但是需要我们对线程通信、同步拥有娴熟的驾驭技巧。实现的复杂度越高,犯错的几率越大,日后代码维护的难度也相应增加。我们的主要目标仅仅对密集型循环进行并行化,因此在满足需求的前提下,Keep It Simple & Stupid 才是我们的编码原则,因此我们使用隐式的编程模型来达成我们的目的。
经过再三权衡,我们在市面上众多隐式多线程编程模型中,选择了来自 Intel 的线程构建块(Thread Building Blocks,TBB)开源库。在数据级并行方面,TBB 算是老手,TBB 运行时系统不仅屏蔽了底层工作线程的实现细节,还能够根据任务量自动在处理器间平衡工作负载,从而充分利用底层 CPU 资源。
使用 TBB 后,交易验签和数据落盘的代码如下所示:
// 并行交易验签
tbb::parallel_for(tbb::blocked_range<size_t>(0, transactions.size()),
&
{
for(int i = _range.begin(); i != _range.end(); ++i)
{
tx = transactions[i];
v, r, s = tx.getSignature();
publicKey = recover(v, r, s); // 从 (v, r, s) 中复原出发送者公钥
...
}
});
// 并行数据落盘
tbb::parallel_for(tbb::blocked_range<size_t>(0, transactions.size()),
&
{
for(int i = _range.begin(); i != _range.end(); ++i)
{
data = datas[i];
jsonStr = jsonEncode(data); // 将数据编码为 JSON 字符串进行存储
db.commit(jsonStr);
...
}
});
可以看到,除了使用 TBB 提供的 tbb::parallel_for 进行并行循环和 tbb::blocked_range 引用数据分片外,循环体内的代码几乎没有任何变化,接近 C++ 原生语法正是 TBB 的特点。TBB 提供了抽象层级较高的并行接口,如 parallel_for、parallel_for_each 这类泛型并行算法,从而使得改造能够较为容易地进行。同时,TBB 不依赖任何语言或编译器,只要有能支持 ISO C++ 标准的编译器,便有 TBB 的用武之地。
当然,使用 TBB 并不是完全没有额外负担,比如线程间安全还是需要开发人员的仔细分析来保证,但 TBB 考虑周到,提供了一套方便的工具来辅助我们解决线程间互斥的问题,如原子变量、线程局部存储和并行容器等,这些并行工具同样被广泛地应用在 FISCO BCOS 中,为 FISCO BCOS 的稳定运行保驾护航。
压力测试的结果表明,FISCO BCOS 的交易处理能力,相较于并行化改造之前,成功提升了 1.74 倍,基本达到了这个环节的预期效果。
但是我们也深深明白,性能优化之路漫漫,木桶最短的一板总是交替出现,并行之道在于,通过反复的分析、拆解、量化和优化,使得各模块互相配合齐头并进,整个系统达到优雅的平衡,而最优解总是在“跳一跳”才能够得着的地方。
2. 星云链并发执行模型
我们可以直观地感受到所有交易被提交到区块链上时,矿工打包的过程和它验证的过程可以理解为一个有限状态机,区块链可以理解为一个状态的集合。它有很多状态,所有交易到我们区块链公网上来之后,实际上我们状态的集合会发生迁移,它从某一个状态变到下一个状态。它就是一个有限状态机。
在传统的场景下面,这个状态机是什么样的呢?所有的交易被提交到公网上来了之后,他们对状态迁移的过程是一个交易执行的过程。一个交易执行完了之后,它迁移到下一个状态,我们再基于这个状态再接进来一个交易,再跳到下一个状态,所以,就变成了一个串行的确定有限状态机。
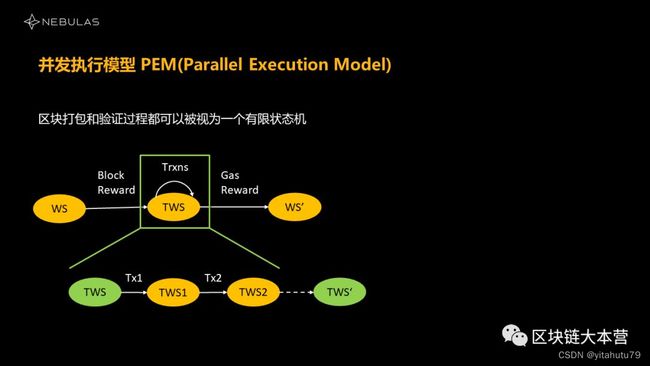
那么我们能不能把交易的执行过程,这个串行的状态机变成一个并行的——你提交上来10个交易,我能不能把这10个交易同时执行,最终合并到同一个状态集合里面去,这种情况能不能实现?
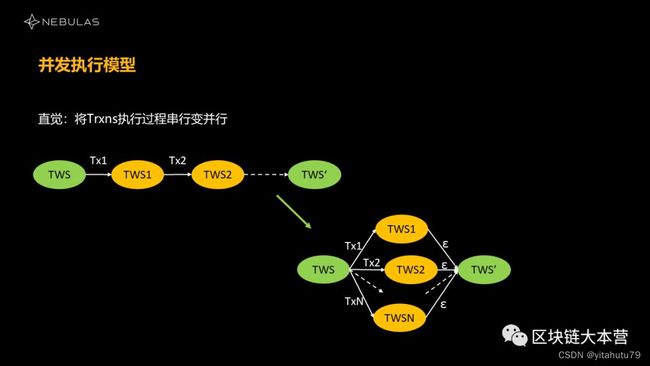
我们上来就遇到了这样三个问题。
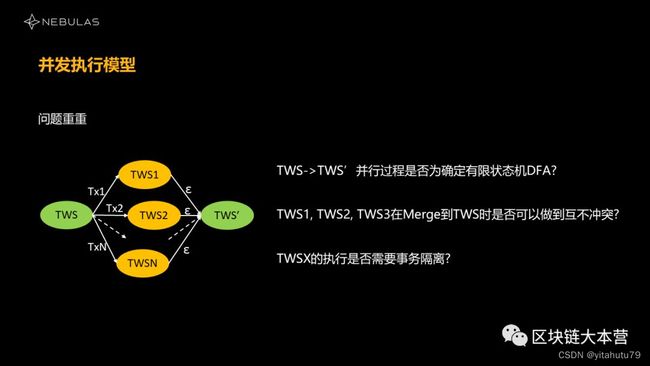
第一个问题:
当我们把状态的迁移过程从串行变成并行之后,会不会每次执行的结果不一样?这一过程是否为确定有限状态机?
第二个问题:
假设我们可以把所有的状态做成并行的。那么要将多个交易并行后得到的状态集合融合,这一过程中会不会产生冲突?产生冲突了怎么办?有没有办法互不冲突?
第三个问题:
在传统的MySQL里有个读写锁,只要读写不冲突就好了。但在我们并行执行过程中是否存在一个更强的逻辑?我们是否需要事务隔离?如果不需要,我们能否让它变成一个更加并行的状态?
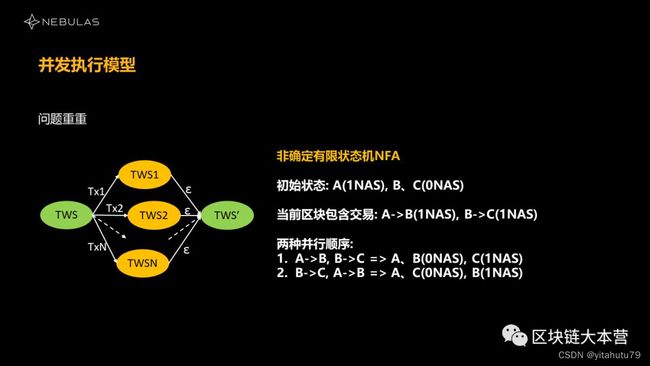
在第一个问题里,它变成并行化之后,还是不是确定的状态机呢?很不幸它不是。这个问题非常棘手,我们可以通过一个实际例子来说明。比如说我们在初始状态下,A和B有两个账户,A有1 NAS,B和C都没有NAS,那我们现在要挖一个区块,这个区块里面我们收到了2笔交易。
第一种情况是A到B转账执行完后,B到C再转账,这个时候的结果就是A和B都没有NAS了,C有一个NAS。
第二种情况是B和C可能先执行了,A和B再执行,但是B到C执行的过程中,它们之间转移一个NAS是不成功的,所以这一交易失败,A向B则会转移成功。最后的结果是A和C没有NAS,B有一个NAS。显然,我们把它并行化之后,如果这个顺序被打散了,最终的结果也就不一致了。
在第二个问题里,我们能不能让两个交易并发执行,在最终做状态合并的时候互不冲突?这其实也很难做到。我们有一个很直观的感觉,比如说A到B我们收到了一个区块,里面有三个交易,A到B、B到C和D到E。
这样看来,感觉“A到B”和“B到C”是相互关联的,因为它们共享了一个地址B,而D到E似乎跟这两个交易没有太多的关系,是两波不一样的人。
那我们能不能由此把它分成两个部分,让A到B,B到C串行执行,D到E跟他们并行执行呢?这个想象很美好,但是实际上不是这样子的。比特币上可以这样干,但是所有基于以太的、通用的智能合约结构,这样都做不了。
A到B这一笔交易,它有可能不是一个普遍的转账,并不只是单纯的NAS转移。B可能是一个合约——这又是一个致命的问题:A到B转账可能会调用某一个合约,在这个合约的逻辑里,可能其中的某一条指令要从合约把一笔钱转到另一个账户上去,那个账户有可能是D,有可能是E。
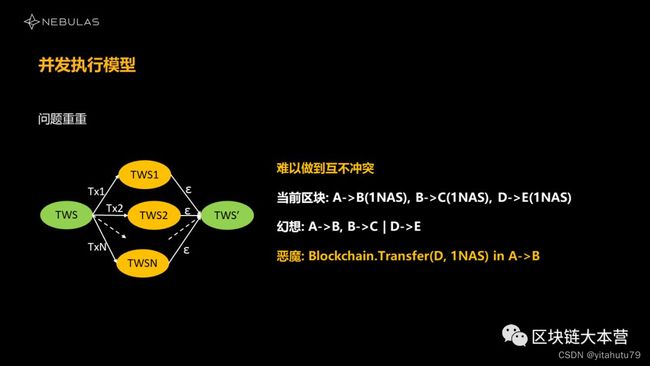
我们根本不知道用户会在他的合约里面存什么样的地址,结果我们想当然地把AB、BC、DE做分割,但是可能就踩到雷了,A到B实际上是影响D到E的,这些事情在早期其实是没有办法预判的。所以说,我们想做到互不冲突也非常困难。
第三个问题,我们是否需要做事务隔离?
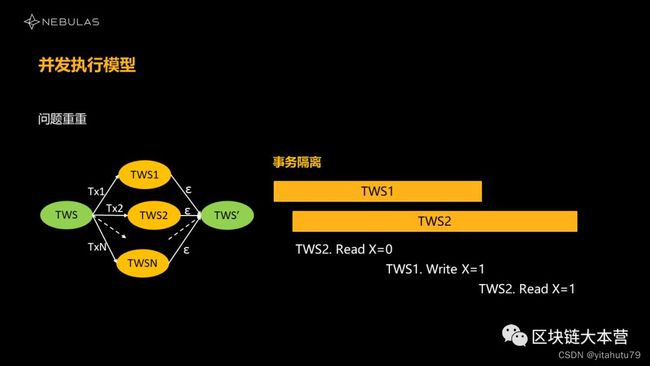
显然,我们不能允许1、2两个中间,互相操作相同的数据,如果操作相同数据——我举个例子,比如在2里面它先读了X=0,在2执行的过程中,1执行结束了,它把X设为了1,那2还在同一个交易里面再去读X的时候,又变成了1,实际上这个场景是不可能出现的。2在执行过程中,要么X全程都是1,要么X全都是0,不可能出现先读到0,再读到1。
所以,场景里面一定要做事务隔离。
解决思路
那么要解决这三个问题,我们能干些什么?
关于第一个问题,我们从一个确定的状态变成一个非确定的,我们需要去关注交易和交易之间的依赖关系。存在依赖关系的交易,是一定存在先后执行顺序的,比如我们常说的拓扑排序结构。所以,除了打包过程要记录它的依赖关系以外,我们在验证的时候,还要根据所记录的依赖关系做最终验证。
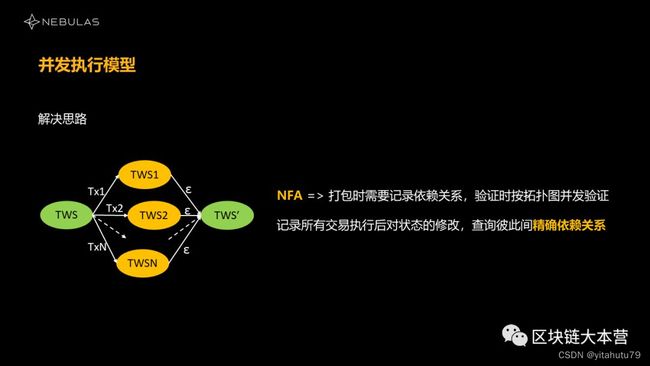
这里我们需要做两个事情。如果我们要记录依赖关系的话,相当于有两个交易,第一个交易做完,它所有状态修改的集合,我们是需要保存的,不然再做第二个交易的时候,都不知道它改过什么,也没办法去判断依赖关系。也就是说,我们就需要保存所有的交易执行之后的状态集合。另外,我们要提供机制,能够查询两个修改后的集合之间的精确依赖关系,这个存储其实也是要很大开销的。
第二个问题,我们能不能做到互不冲突?极难做到,因为我们完全不知道用户在他的合约里面放了什么数据,也极难追踪。我们只能尽量使两个交易互不冲突,因为我们有一个基础的预判,from和to只要互不重叠,冲突的概率就会相对小一点。
我们有一个调动模型,但最终还要有一个东西来保证它们真的互不冲突。所以两个修改后的状态集合产生了之后,我们要去看这个集合里面都修改过什么?增删查改4个操作他们都做过什么?对同一个数据做的增删查改,哪种场景下是冲突的,哪种是不冲突的?我们需要定义这个冲突模式。
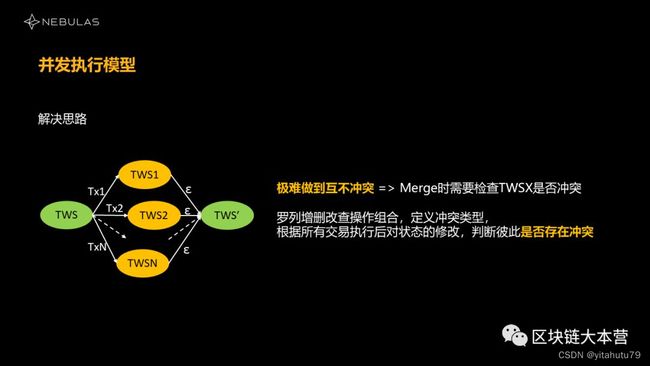
与此同时,我们也需要保存所有修改后集合的状态,因为我们最终需要去判断两个集合是否相互冲突,和第一个问题一样,我们需要一大笔存储的开销。
到了第三个问题,我们要做事务隔离。比如交易1执行之前的状态是0,交易2在执行之前状态也是0,1和2可能并行执行。这一过程中,可能都会对0那个状态的数据做修改,但他们一旦修改做了重叠之后影响了其他交易的执行,这就不是事务隔离。所以我们还要保证一点:1和2在做执行的过程中,他们所依赖的前提的状态都是0,相当于把0的状态拷贝两份,给他们各自一份作为初始条件。
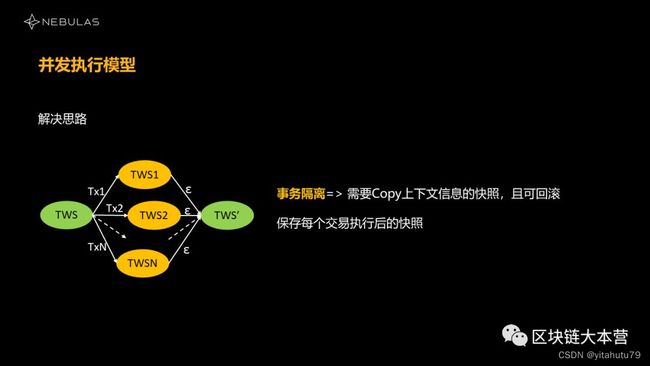
除了要把所有交易的修改集合保存以外,我们还要把所有的交易最开始依赖的初始条件保存,这样看的话,又是一大堆东西要存,而且这个场景是事务隔离,这个交易可能会失败,需要让它回滚。所以算法复杂度也提高了,我的存储复杂度也提高了。
解决方案
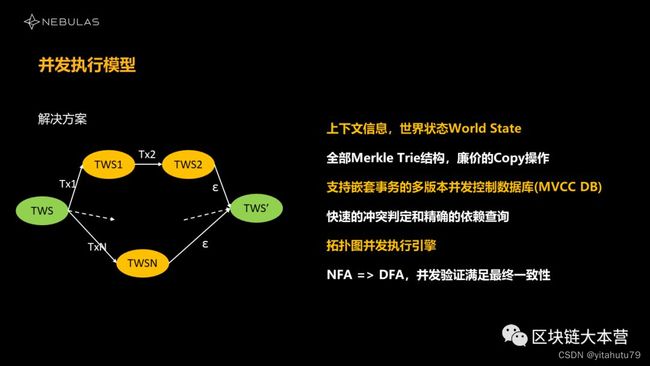
为了解决这几个问题,我们做了三个事情:
第一,我们把所有的状态统一到一起。原来的状态是分散的,我们不知道如何判断不同状态之间的冲突关系和依赖关系。所以我们在这边做了一个叫World State的工具,把所有的状态都统计、管理起来。你在增删查改任何东西之前,可以通过它来判断冲突、查看状态。
World State只是一个管理工具,那数据存在哪呢?我们还要存所有的交易修改之后的状态、和所有交易执行前的状态。而且在这个过程中,我们还得去判断它的依赖关系、冲突关系,实际上是要把每一份都拷贝一份,这个事情非常好解决。但实际上是不可行的,比如说TPS要上万,相当于是一秒钟以内要复制1万份;要上百万,就要复制上百万份…相当于是TPS越高,要的存储就越高,哪几台机器能够扛得住这么大的存储呢?
所以第二件事是,我们设计了一个结构来简化这个存储,这个名字叫做“支持嵌套事务的多版本控制并发数据库(MVCC DB)”,这个结构在我们的代码里面已经开源了,大家如果感兴趣可以看一下里面更多的细节。
第三个,我们刚刚说它变成一个非确定性状态机,要根据依赖关系来构建结构。它实际上是个拓扑图,会随着网络传播到下一个验证者那里,那个验证者会根据它的拓扑排序结构做一个调度,哪些交易可并行执行,哪些交易必须等到上一个交易执行完之后才能做,这里就要有一个拓扑图的执行引擎,来保障我们最终完成的一致性。
3. XuperChain并行执行区块链结构
架构概述
XuperChain 事务执行架构主要由三个部分组成,分别为VM层、Bridge层和Model层。 VM层主要用于解释用户执行合同的字节码,目前主要支持的有wasm、naTIve。Bridge 层用于隔离用户态和内核态,为用户提供系统调用的接口,如get、put、迭代器等。Model层用于数据的提交、回滚和查询,其内置的smart cache机制能支持事务的并发执行。
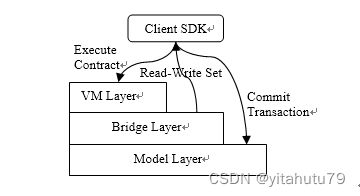
整个处理过程是这个样子的。一阶段:首先,客户端触发智能合约的预执行,智能合约的字节码被虚拟机解析并执行,并且像Get,Set这样的系统调用在执行过程中被桥接层截获,桥接层记录下执行过程中的读写集,最后将它们返回客户端。二阶段:用户将读写集与交易组合起来,附上TA的签名,然后将它们提交给模型层。模型层会验证读取集中的变量是否与本地状态匹配,最后将写入集中的变量值更新到状态数据库中。
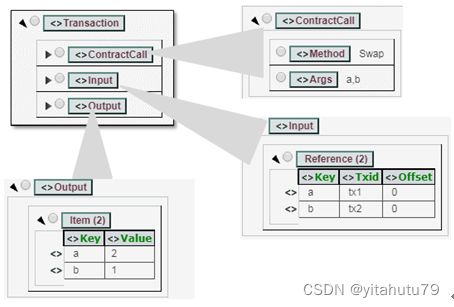
XuperModel
为了描述读写集,我们需要定义一种叫做XuperModel的新交易模式。这种模式是比特币UTXO模式的升级。在比特币UTXO模式里,每一笔交易的输入都需要参照之前一笔交易的输出来证明资金的来源。相似的,在XuperModel中,每一笔交易读取的数据需要参照上一笔交易写入的数据。在XuperModel中,一笔交易的输入就是智能合约执行中使用的数据,它来自另一笔交易的输出。一笔交易的输出会被记录到交易数据库中,等待被未来交易的智能合约引用。
我们来进一步解释一下:如果存在这样两笔交易,tx1和tx2,tx1将变量a赋值为1,tx2将变量b赋值为2。然后存在一个tx3,tx3能够调用一个智能合约交换两个变量的值,最后输出结果为a=2,b=1。所以tx3的输入将会指向tx1和tx2,因为a,b之前的值是被tx1和tx2指定的。
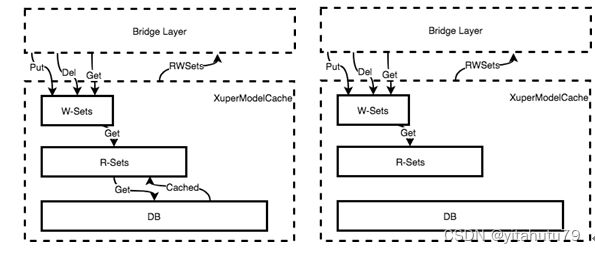
XuperModel的智能缓存
为了在运行期间为合约获取读写集,每个合约在预执行时都会被提供一个智能缓存。这个缓存对状态数据库来说是只读的,它还能生成读写集和智能合约预执行的结果。同时,它也能被用作合约验证。这个缓存由四部分组成,一个写入集实例,一个读取集实例,一个状态数据库引用和一个渗透标记(penetration flag)用以确定查询是否可以渗透到数据库中。
当预执行合约时,渗透标记被设为true,桥接器会根据状态数据库中可被读取的数据生成一个缓存,桥接器将查询的数据存储到缓存中的读取集中。合约也能写入数据,被写入的数据会存放在缓存的写入集中。预执行之后,读写集能够被一同取得然后返回到客户端。
当验证合约时,渗透标志被设为false,验证节点会根据交易的读写集初始化一个新缓存实例。这个节点将会再次执行合约,但是合约只能在准备好的读取集中读取数据。相似的,写入数据只能在缓存实例的写入集中起作用。
我们来进一步解释一下,以一个调用合约为例。Xuperchain用发起一个交易的方式调用合约。当合约预执行时,智能缓存是以三层存储对象的形式被生成的。假设合约调用一个Get方法,获取变量的名字叫parameter,缓存首先会在它的写入集中读取相关数据,如果没有找到,就在读取集中寻找,如果还是没有找到,最后在数据库中寻找并且在读取集中记录下变量的名称和版本。当验证合约时,缓存以双层存储对象的形式生成。假设验证的合约调用一个Get方法,缓存会首先读取写入集中最新的数据,如果没有找到,就在读取集中寻找。
交易冲突处理
像我们之前提到的,智能缓存能够提取智能合约预执行时生成的读写集,这是交易信息的很重要的一部分。在XuperChain中,一个读写集由读取集和写入集组成。读取集是由tuples:{variable,data version}组成,它反映了合同运行时读取的变量状态;写入集是 tuples: {variable name, data value},它代表了合约执行之后状态数据库的改变。
数据版本是tuple: {RefTxid, RefOffset},它记录了上一个修改变量的交易的ID和交易输出的偏移量。交易的ID是该交易所有字段的sha256摘要。在Hyperledger Fabric中数据版本也是一个tuple,但是它的结构是{BlockHeight,TxNumber},所以Fabric不支持未确认交易输出的立即可见。
当一个节点接收到交易后,它首先根据交易附带的读写集创建一个临时的缓存,用它来验证智能合约执行结果是否正确。通过检查后,它会验证读写集中变量的版本是否与本地状态数据库中的记录一致,如果不一致,它会拒绝这笔交易。值得注意的是,XuperChain需要为所有写入集中的变量在读取集中对应地赋予版本数据。如果变量之前没有数值,版本的位置需要留空。此外,如果本地未确认交易的读写集与区块中已确认的交易产生冲突,未确认的交易将会回滚。回滚操作会将写入集中的变量恢复回以前版本的读取集中的值。
智能合约的并行预执行
由于XuperModel上面提到的特性——智能缓存和标记版本的数据,我们能够并行地执行智能合约。桥接层会为每个合约生成一个新的内容,包括一个标准缓存的实例,这个实例只在预执行期间是合法的。在预执行期间的读写操作只会对这个缓存产生影响,所以(智能合约)的预执行都是彼此独立的。因为智能合约的预执行是一个彼此互不影响的过程,所以合约能够被并行执行。
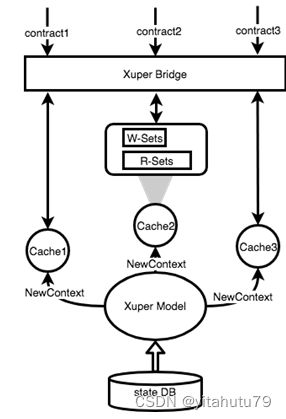
上图解释了合约是如何并行执行的。假设合约1,合约2和合约3是同时被执行的。通过XuperBridge三个缓存实例被初始化。缓存在合约执行期间记录读写集并将其返回给用户。
智能合约的并行验证
当合约预执行时,客户端的用户会从XuperChain节点那里得到读写集。用户可以在本地将带有读写集的完整交易与签名组装起来然后提交给XuperChain。XuperChain节点会验证合约。验证过程如下图所示。
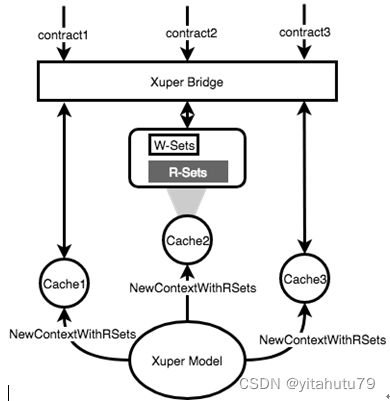
合约验证主要包括一下三步:
步骤一:XuperBridge会初始化一个新的上下文(context),然后根据交易提交的读写集生成上下文中的缓存。如果一个在读取集中特定版本的数据没有在本地状态数据库中找到,这表明数据已经被其他合约优先修改了,缓存的初始化会失败,合约也会失败。
步骤二:节点会再次执行合约以验证写入集是否与交易中的写入集一致。
步骤三:如果一致,这笔交易会被确认,否则返回失败。
冲突的合约会在步骤一失效。因为每个合约的验证过程是分别发生在各自的缓存中的,不同合约的验证过程是彼此独立的,所以步骤二中合约的验证能够并行。在步骤三中,我们需要再次检查读取集中变量的版本是否合法。
局限
通过上面提到的XuperModel,我们的系统能够让合约并行执行,并且未确认合约的输出也能立即可见。但是,这个模式仍然存在一些局限。首先,在合约执行期间对状态数据库的每一访问都会记录在读取集中,所以如果一个用户在合约调用期间访问了太多数据,会导致读取集过大。更重要的是,该模型对存储的要求很高,需要进一步优化。
参考文章
- 区块链共识与执行的并行处理方法
- 区块链的并行发展路线
- 区块链性能腾飞:基于DAG的并行交易执行引擎
- 区块链全方位的并行处理
- 区块链性能突破(五):全方位的并行处理
- 区块链交易的并发执行
- 基于XuperChain提出的一种智能合约并行执行区块链结构解析
- 区块链必修课:DAG区块链
- 百度开源的区块链项目:XuperChain,一个支持智能合约并行执行的系统
- 区块链智能合约并行执行模型综述