【论文阅读笔记】Say As You Wish: Fine-grained Control of Image Caption Generation with Abstract Scene Graphs
Say As You Wish: Fine-grained Control of Image Caption Generation with Abstract Scene Graphs
2020-CVPR
Shizhe Chen1∗, Qin Jin1†, Peng Wang2, Qi Wu3
1Renmin University of China, 2Northwestern Polytechnical University 3Australian Centre for Robotic Vision, University of Adelaide
motivation:
人类能够按照自己的意愿描述从粗到细的图像内容。然而,大多数图像字幕模型只被动生成图像描述,并不关心用户对什么内容感兴趣,描述应该有多详细,也就是说,不能根据不同的用户意图自动生成不同的描述。
此前的工作都只能处理粗粒度的控制信号,很难在细粒度级别上实现用户所需的控制(在不同的细节级别上描述各种对象及其关系)。
contribute:
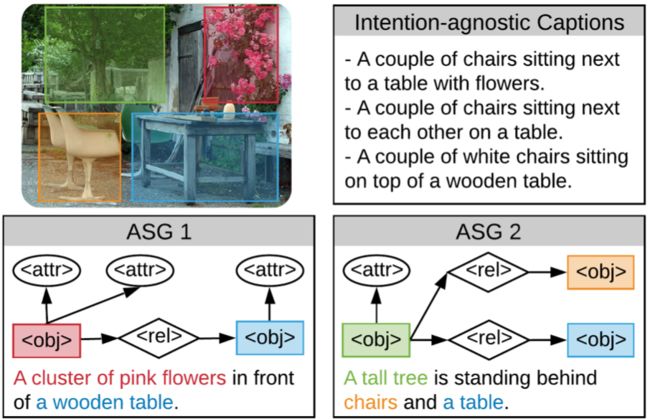
在本研究中,我们提出了抽象场景图(ASG)结构,在细粒度层次上表示用户意图,并控制所生成的描述内容和详细程度。
ASG是一个有向图,由三种类型的抽象节点(对象、属性、关系)组成,这些抽象节点根植于图像中,没有任何具体的语义标签,无论是手动还是自动获取都很容易。
基于ASG,我们提出了一种asg2caption模型,该模型能够识别图中的用户意图和语义,从而根据图的结构生成所需的标题。
方法:
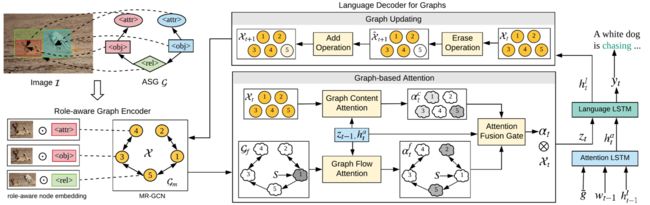
1.Overview
由于ASG只包含一个抽象的场景布局,没有任何语义标签,有必要在图中捕获意图和语义。因此,我们提出了一种role-aware graph encoder 来区分节点的细粒度意图,并用图上下文增强每个节点以改善语义表示。
其次,ASG不仅通过不同的节点控制要描述的内容,而且通过节点的连接方式隐式地决定描述顺序。因此,我们提出的解码器同时考虑关注节点的内容和结构,以图流顺序生成所需的内容。
最后,在ASG中完全覆盖信息而不遗漏或重复是很重要的。为此,我们的模型在解码过程中逐步更新图的表示,以保持对图访问状态的跟踪。
整个模型由role-aware graph encoder和language decoder for graphs (如图)。给定图像I和ASG G,编码器首先将每个节点初始化为角色感知嵌入,并使用多层MR-GCN对Gm中的图上下文进行编码。然后解码器动态地合并图内容和图流注意,用于生成ASG控制的字幕。生成一个词后,我们将图Xt−1更新为Xt来记录图的状态。
2.Abstract Scene Graph
图像I的ASG记为G = (V,E),其中V和E分别为节点和边的集合。节点按其意图角色可分为三类:对象节点o、属性节点a和关系节点r。注意ASG只是一个没有任何语义标签的图形布局,这意味着不依赖于外部训练的对象/属性/关系检测器。
3.The ASG2Caption Model
3.1Role-aware Graph Encoder
该编码器将ASG G编码为一组节点嵌入X = {x1,···,X |V|},包含两个组件:role-aware node embedding用于区分节点意图和multi-relational graph convolutional network (MR-GCN)用于上下文编码。
(1)role-aware node embedding
对于G中的第i个节点,首先将其初始化为相应的可视化特征vi。再进一步对每个节点进行角色嵌入,得到角色感知节点嵌入xi(0):
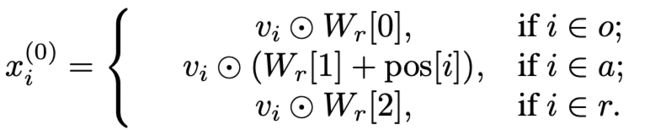
(2)MR-GCN
用不同的双向边扩展原来的ASG,从而得到一个多关系图gm ={V,E,R}用于上下文编码。使用MR-GCN来编码Gm中的图上下文,如下所示为第l层:
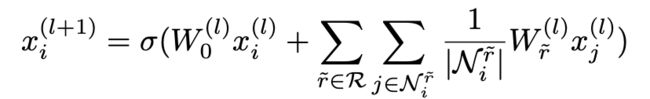
堆叠L层,最后一层的输出被用作我们的最终节点嵌入。我们也可以得到一个全局图,通过取xi的平均值 g ̄ = 1 xi 。我们将全局图嵌入与全局图像表示融合为全局编码特征 v ̄。
3.2Language Decoder for Graphs
解码器的目的是将编码后的G转换成图像标题。为了提高从图到句子的质量,我们提出了一种专门针对图的解码器language decoder for graphs ,该解码器包括一个基于图的注意机制,它同时考虑了图的语义和结构,以及一个图的更新机制,它记录了描述的内容和没有描述的内容。
(1)Overview of the Decoder
The attention LSTM:输入全局的编码嵌入v ̄,之前的词嵌入wt−1以及上一步的输出hlt−1,计算注意查询hat:
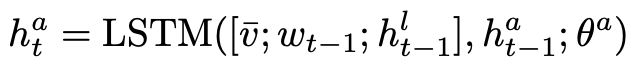
The language LSTM:输入hat和zt(基于图的注意机制从Xt中检索的上下文向量),按顺序生成word:
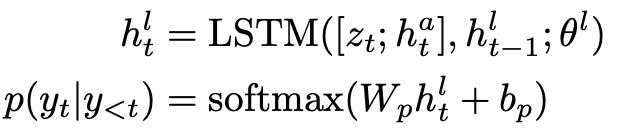
在生成单词yt后,我们通过所提出的图更新机制将节点嵌入Xt更新为Xt+1,以记录新的图状态。
(2)Graph-based Attention Mechanism
graph content attention:考虑节点嵌入Xt与hat之间的语义相关性,计算关注分数向量αc:
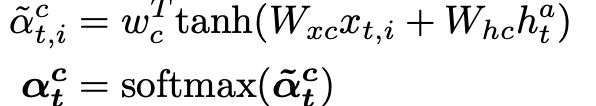
graph flow attention:捕获图结构,由动态门控制的三种流量分数的值:
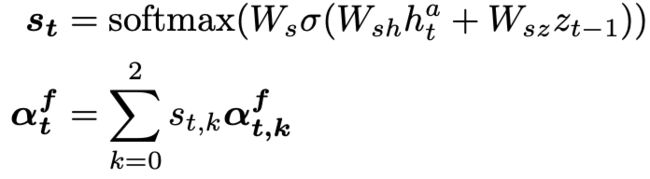
综合虑内容和结构:
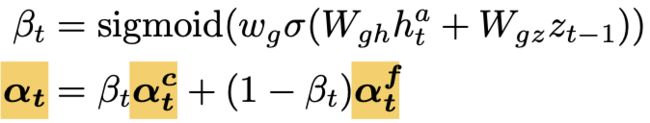
(3)Graph updating mechanism
在每个解码步骤中,我们更新图表示以保存不同节点的访问状态记录。注意分数αt表示每个节点的访问强度,高参与节点应该更新更多,为此,我们提出了一种adaptively modify the attention intensity:
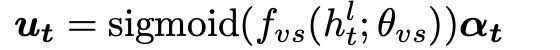
对于节点i,根据图节点表示xt,i的更新强度ut,i进行细粒度擦除:
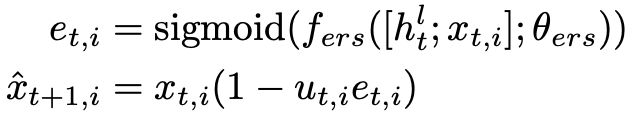
如果不再需要访问某个节点,则可以将该节点设置为0。
如果一个节点可能需要多次访问并跟踪其状态,再使用添加操作:
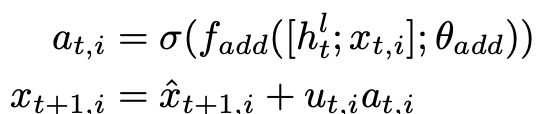
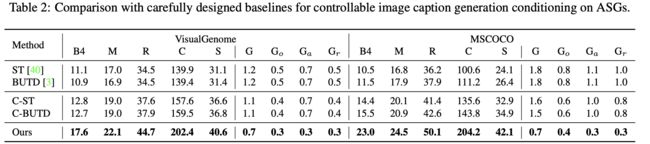
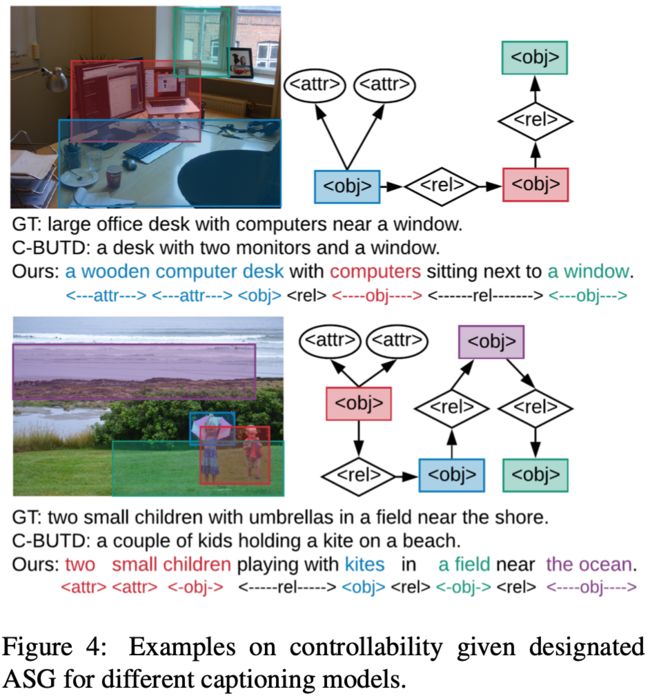
结果:
2022-12-29
by littleoo