技术分享 | Presto性能对比测试:Kubernetes部署 VS 物理机部署
目录
一、引言
Presto系统架构
传统方式部署Presto存在的问题
二、使用Kubernetes部署Presto
Kubernetes部署方案的优点
Kubernetes部署方案的问题
三、对比测试评估
测试介绍
TPC-DS
集群配置
四、测试结果
五、结论
六、问题排查
节点分配不均
资源利用率过低
Presto性能如何调优
七、参考

一、引言
Presto是开源分布式SQL查询引擎,可以对从GB到PB级大小的数据源进行交互式分析查询。Presto支持Hive、Cassandra、关系型数据库甚至专有数据存储等多种数据源,允许跨源查询。(详见参考[1] )
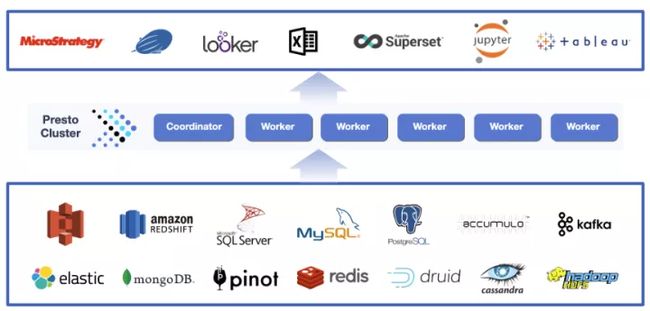 图1 Presto层次架构图(图源Presto官网)
图1 Presto层次架构图(图源Presto官网)
无处不在的Presto
当今大规模的互联网公司都在使用Presto。
Uber将Presto用于SQL数据湖,每周有超过7000名活跃用户,每天在超过50PB 的HDFS(Hadoop Distributed File System)数据上运行50万次查询。
字节跳动对Presto 进行了广泛的应用,例如数据仓库、BI 工具、广告等。字节跳动的 Presto 集群拥有上万个计算核心,每天处理约 100 万次查询,涵盖 90% 以上的交互式查询。这极大地减少了查询延迟并节省了大量计算资源。
Meta公司(Facebook)使用 Presto 对多个内部数据存储进行交互式查询,包括300PB 数据湖。每天有超过 1,000 名 Facebook 员工使用 Presto 运行 30,000 多个查询,平均每个查询扫描超过 1 PB。
腾讯将Presto 应用于内部的不同业务场景,包括微信支付、QQ、游戏等关键业务。日均处理数据量 PB 级,P90 查询耗时为 50s,全面提升各业务数据实时分析性能,有效助力业务增长。
阿里数据湖分析集成了Presto的联合查询引擎能力,不仅让阿里云众多用户体验了大规模的 Serverless 云服务,也积累了许多成功的业务用例,比如日志数据分析和基因数据分析等,这些案例表明了Presto应用广泛,分析能力强大。
 图2 各大互联网公司Presto性能展示数据部分来源Presto官网
图2 各大互联网公司Presto性能展示数据部分来源Presto官网
Presto系统架构
Presto 集群由一个Coordinator和一个或多个Worker组成。Coordinator负责接纳、解析、规划和优化查询以及查询编排,Worker负责查询处理。Presto通过Connector适应底层不同类型的数据源,以便访问各种数据源中的数据。如图3显示了 Presto 架构的简化视图(详见参考[2] )。
 图3 Presto 架构图
图3 Presto 架构图
传统方式部署Presto存在的问题
作为一个分布式架构的系统,Presto为数据查询和处理提供了高效便捷的方法。随着数据量增大,为了保证数据查询处理的效率,Presto集群规模也要扩大。例如上文提到的Uber、字节跳动和Meta等公司每天查询的数据量是PB级别,一个Presto集群的节点数量已经上千。当数据量远超单机处理能力时,分布式架构相比于集中式架构的优势就体现出来了,但是对于一个规模庞大的分布式集群,持续高效地处理数据,将会面临一系列的问题:
- 对于一个规模庞大、节点数量上千的Presto集群,如果没有自动化部署工具,采用传统方式一个一个部署Presto节点,耗费的时间是难以想象的。此外对于部署好的Presto集群根据业务进行调优,需要不断修改Presto节点的配置信息,按照传统方式逐个修改配置信息,耗费的人力和时间成本也是难以忍受的。
- 传统部署Presto集群,当其中某个节点发生故障时,无法做到自动重启或者动态加入新的节点以维持集群数量,此时如果正好发生故障的是Coordinator节点,则整个集群将陷入瘫痪,导致服务不可用。
- Presto主要应用场景是即席查询,比如Uber和滴滴等网约车公司,查询业务高峰时段主要在白天,晚上基本没有查询。如果晚上闲置的资源不能加以回收利用,将会产生很大的资源浪费。此外,当业务高峰期的查询负载超过当前集群的承载能力时,如果不对集群立刻按需扩容,也会对业务产生很大的影响。
使用Kubernetes部署Presto集群,将云原生与Presto相结合,借助Kubernetes便捷部署、自动化运维和弹性伸缩等优点,解决上述提到的一系列问题。
二、使用Kubernetes部署Presto
Kubernetes,也被称为K8s,是一个用于自动化部署、扩展和管理容器化应用程序的开源系统,目前已被业界广泛接受并得到了大规模的应用。Kubernetes集群由控制平面和node组成。其中node上运行由Kubernetes所管理的容器化应用,也就是Pod。控制平面管理集群中的node和Pod,为集群提供故障转移和高可用性,而集群也会跨多个主机运行(详见参考[3] )。
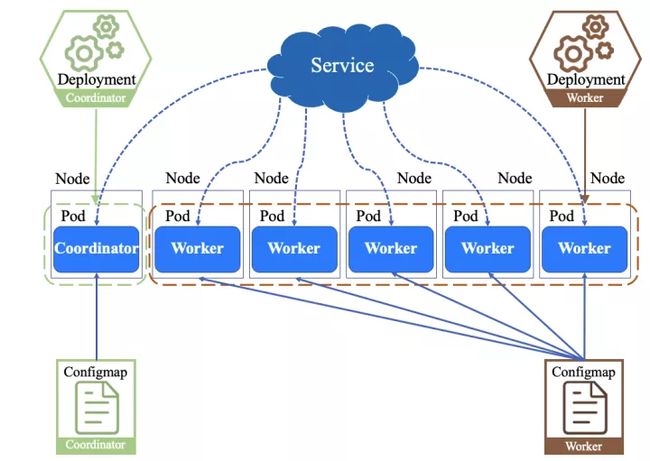 图4 Kubernetes部署Presto集群方案
图4 Kubernetes部署Presto集群方案
如图4所示为本次测试所部署方案,Deployment负责创建、更新、维护其所管理的所有Pods。Presto Coordinator和Worker进程分别运行在Pod中,针对Presto集群内Coordinator和Worker分别配置不同类型的Deployment来进行管理。Deployment可以保证集群内可用Pod的数量,实现弹性伸缩,维持集群可用性和稳定性。
Configmap用来存储配置文件,Coordinator和Worker的配置信息分别通过Configmap进行存储,每次进行配置更改,只需要修改Configmap里面的配置信息,Coordinator和Worker就会更新相应的配置信息。
Service会对同一个服务的多个Pod进行聚合,向集群提供一个统一的入口地址,通过访问Service的入口地址就能访问到后面的Pod服务,实现负载均衡和服务发现。在Kubernetes部署的Presto集群中,Coordinator将自己的地址注册到Service,Worker通过Service中的域名地址与Coordinator连接,从而实现Presto集群的服务注册与发现。
在Kubernetes部署Presto方案中,Deployment负责创建和管理Pods,Configmap负责存储配置信息,Service负责服务注册与发现。Deployment、Configmap和Service三类资源相互配合,保证了Presto集群持续高效工作。
Kubernetes部署方案的优点
通过合理设置Deployment、Configmap和Service等资源对象,使用Kubernetes部署Presto集群,将Kubernetes的运营优势与Presto技术优势相结合:
√ 便捷部署:在Deployment中设置Coordinator和Worker的副本数量,Configmap设置配置信息,Service设置Presto集群提供服务的入口地址。将上述三类资源对象提交到Kubernetes中即可完成Presto集群配置,比如设置Worker副本数量为1000,提交之后即可创建1000个Worker Pod,每一个节点的配置信息从Configmap文件中读取。只需要编写好资源对象文件,提交到Kubernetes,即可创建Presto集群,后续可以通过修改Configmap文件更新各个节点的配置信息。通过Kubernetes部署Presto集群减轻了配置、部署、管理和监控容器化Presto应用程序的负担和复杂性。
√ 自动化运维:可以更方便地和Prometheus结合,通过Prometheus可以实现对整个集群的监控数据采集、存储、分析以及可视化。有效监控Presto集群,当发生故障时可以针对性修复,从而维持集群稳定,保证高可用性。
√ 弹性伸缩:当业务量激增,自动扩容Presto Worker节点,满足业务需求;当业务量处于低谷,自动缩容Presto Worker节点,节省运行成本。
Kubernetes部署方案的问题
传统方式部署Presto集群是以物理机的方式运行,相比之下,在Kubernetes上部署Presto集群是以容器的方式运行。尽管Kubernetes部署方式带来了很多优点,但是容器方式和物理机方式的性能差异仍然未知,下面的测试将重点对比分析两种不同部署方式的性能差异。
三、对比测试评估
测试介绍
基准测试的目的是比较物理机的 Presto 集群和部署在 Kubernetes 的 Presto 集群的性能差异。因此,测试方案分为物理机方案和Kubernetes方案。Presto 物理机集群的结构是1个Coordinator和5个Worker;Kubernetes集群是在6个node之间分配了1个Coordinator和5个Worker。在物理机集群中,用户直接通过Presto客户端向Coordinator发起查询请求,Coordinator将任务分配给Worker;如图5所示,在Kubernetes集群中,首先利用6个node部署Presto集群,Presto客户端向Kubernetes中的Coordinator发起SQL查询,Coordinator将任务分配给Worker。
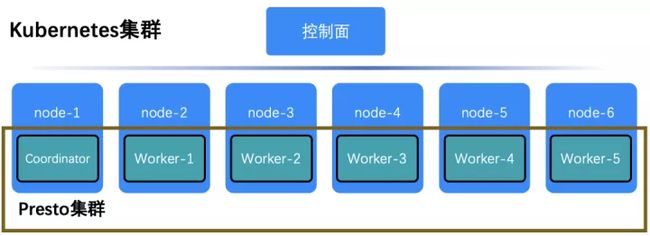 图5 基准测试系统架构图
图5 基准测试系统架构图
TPC-DS
沿用目前业内的普遍测评方法,本次测试采用TPC-DS 作为benchmark,它在多个普遍适用的商业场景基础上进行了建模,包括查询和数据维护等场景(详见参考[4] ),同时提供了一系列能够代表系统性能的评估指标。简单来说,TPC-DS使用了一个真实的商品零售业务场景来测试系统性能。它构建了一个大型跨国零售公司的业务模型,模型里不仅包含了多家专卖店,同时还包含了线上销售业务,以及库存管理系统和促销系统(详见参考[5] )。由于TPC-DS是以真实场景为原型,在业内能够起到比较好的测评效果,从而成为了当前SQL引擎测试最常用的benchmark(详见参考[6] )。
集群配置
| Linux系统版本 | Ubuntu20.04 |
| Kubernetes版本 | 1.22.3 |
| Docker版本 | 20.10 |
| Kubernetes集群 | 6 node,56vCPU,224G内存 |
| Presto集群 | 1 Coordinator/5 Worker,48vCPU,192G内存 |
四、测试结果
为了保证本次测试的结果具有更加广泛的意义,分别选取了TPC-DS不同的查询类型进行测试,包括即席查询、报告查询和迭代OLAP查询三种类型:
即席查询:这类查询主要的应用场景是通过查询来回答即时和特定的业务问题。即席查询和报告查询之间的主要区别在于系统管理员在规划即席查询时可用的预知程度有限。图表中为q19, q42, q52, q55, q63, q68, q73, q98。
报告查询:定期执行的查询,这类查询主要是定期获取到有关企业财务和运营状况。图表中为q3, q7, q27, q43, q53, q89。
迭代OLAP查询:OLAP 查询通常用于探索和分析业务数据以发现新的和有意义的关联关系和趋势。图表中为q34, q46, q59, q79, q96, q48。
 图6 Kubernetes VS 物理机查询时间对比图
图6 Kubernetes VS 物理机查询时间对比图
如图6所示,纵坐标为查询时间,单位是毫秒;横坐标为查询任务分类,图表中所显示的每个查询任务的时间实际为4次查询时间的平均值。可以看出,在不同的查询分类中,Kubernetes部署的Presto集群的平均查询时间稍微短于物理机部署,两者时间差基本保持在几秒之间,考虑到本次测试环境部署在云服务器上,不同时段使用云服务器,性能会有不同程度的偏差,几秒之间的性能波动是可以容忍的。排除本次测试使用的云服务器产生的波动,可以说明Kubernetes部署与物理机部署在性能和效率上几乎相差无几。所以针对不同类型的查询,Kubernetes部署的Presto集群相比物理机部署在查询速度上并没有损耗,性能与效率几乎没有损失。
五、结论
Kubernetes部署Presto集群的方案减轻了配置、部署、管理和监控容器化Presto应用程序的负担和复杂性。实现了Presto集群的自动配置以及工作节点自动扩展,保证了Presto Coordinator的高可用,通过与Prometheus集成可以更好地实现集群监控。在Kubernetes上部署Presto集群将这两种技术的架构优势和运维优势结合在一起,相比于传统方案,在没有性能损耗的情况下,实现了对Presto集群的动态扩展、便捷部署管理和稳定维护。
六、问题排查
在性能对比测试的过程中,并非一帆风顺,前期测试中出现了一些问题,导致Kubernetes部署的Presto集群性能无法完全释放,与物理机部署的Presto集群性能相差很多。现将测试过程中遇到的一系列问题以及相应的解决方法单开一节进行总结,方便读者在实际部署过程中遇到类似问题时可以得到借鉴与参考。
节点分配不均
Kubernetes 部署 Presto Pod(Master 或 Worker)时,如果使用了Deployment而非DaemonSet进行部署,会集中在几台物理机上(多个 Presto Pod 会同时运行在一台物理机上),有些物理机没有 Pod 运行。
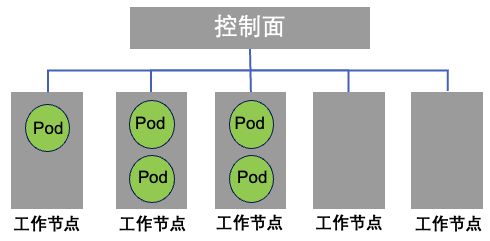 图7 Presto Pod 分布情况
图7 Presto Pod 分布情况
解决方法:出现这种现象的原因是 Presto Pod 所需的 CPU 和内存远远小于主机的上限,因此可以在一台物理机上运行多个 Presto Pod。造成的影响包括同一主机中的Pod互相抢占资源,导致效率下降,以及部分主机(没有Presto Pod)闲置,造成资源浪费。解决方案是可以通过resources requests 和 limits 合理设置 Presto Pod 运行所需的资源,使其均匀分布到各个主机上。
资源利用率过低
与物理机相比,Kubernetes 部署的 Presto 无法使用所有 CPU,只使用一个 CPU 核,每个节点的吞吐量有限,导致查询时间明显变慢。
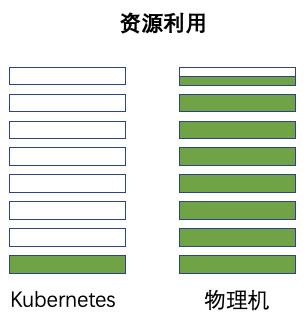 图8 Kubernetes vs 物理机资源利用情况
图8 Kubernetes vs 物理机资源利用情况
解决方法:出现这种现象的原因是没有设置Presto Pod调用主机资源的最大限制。最大限制可能是默认值,无法达到主机的理想资源配额。影响是 Presto Pod 使用的资源严重受限,导致查询任务执行效率低下。解决的办法是合理设置 Presto Pod 可以调用的宿主机的最大资源限制。
针对上述两个问题,在Kubernetes中采用requests和limits两种限制类型来对资源进行容器粒度的分配。这 2 个参数是通过每个容器 containerSpec 的 resources 字段进行设置的。requests定义了对应容器需要的最小资源量。limits定义了这个容器最大可以消耗的资源上限,防止过量消耗资源导致资源短缺甚至宕机。设置为 0 表示对使用的资源不做限制。如下图所示,设置request的cpu为3,memory为6Gi,这样保证一个pod运行在一个节点上,解决了Pod在节点上分配不均的问题;设置limit的cpu为8,memory为8Gi,为节点的最大资源配置,解决了性能受限的问题,同时也避免了使用资源超过节点最大资源引起的Pod崩溃重启问题。
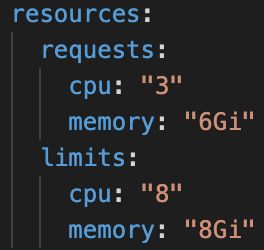 图9 资源配置
图9 资源配置
Presto性能如何调优
解决方法:对于Kubernetes部署集群,需要设置CpuCoreRequests、CpuCoreLimits、MemoryRequests和MemoryLimits。CpuCoreLimits 和 MemoryLimits 需要设置为宿主机配置的最大值,这样在执行任务时就不会受到限制。在此基础上,在Presto应用层面还需要设置一个合理的 query.max-memory-per-node。query.max-memory-per-node:查询可以在任何一台机器上使用的最大用户内存量,如果不进行设置,默认值为jvm * 0.1。在本次测试中,如果单个查询在节点上的使用内存最大值过小,会导致查询无法完成,建议将内存值设置足够大,以避免查询失败的情况。
七、参考
[1] https://prestodb.io/
[2] R. Sethi et al., "Presto: SQL on Everything," 2019 IEEE 35th International Conference on Data Engineering (ICDE), 2019, pp. 1802-1813, doi: 10.1109/ICDE.2019.00196.
[3] https://kubernetes.io/
[4] https://www.tpc.org/tpcds/
[5] TPC和TPC-DS的介绍 - 知乎
[6] https://bbs.huaweicloud.com/blogs/198087
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请关注 [Alluxio智库]: 