读论文---Scalable Diffusion Models with Transformers

Figure 1. Diffusion models with transformer backbones achieve state-of-the-art image quality. We show selected samples from two of our class-conditional DiT-XL/2 models trained on ImageNet at 512×512 and 256×256 resolution, respectively.
图1。带有变压器主干的扩散模型可实现最先进的图像质量。我们展示了从我们的两个类条件DiT-XL/2模型中选择的样本,分别在ImageNet上以512×512和256×256分辨率训练。
摘要
We explore a new class of diffusion models based on the transformer architecture.
We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches.
We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops.
We find that DiTs with higher Gflops—through in- creased transformer depth/width or increased number of in- put tokens—consistently have lower FID.
n addition to pos- sessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class- conditional ImageNet 512×512 and 256×256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.
我们探索了一类新的基于变压器结构的扩散模型。
我们训练图像的潜在扩散模型,用一个对latent patches操作的变压器取代常用的U-Net骨干网。
我们通过Gflops测量的前向传递复杂性来分析扩散变压器(dit)的可伸缩性。
我们发现,具有较高gflop的dit(通过增加变压器深度/宽度或增加插入令牌数量)始终具有较低的FID。
除了拥有良好的可扩展性属性,我们最大的DiT-XL/2模型在类条件ImageNet 512×512和256×256基准上优于所有先前的扩散模型,在后者上实现了2.27的最先进的FID。
Intordcution
Machine learning is experiencing a renaissance powered by transformers.
Over the past five years, neural architectures for natural language processing [8, 39], vision [10] and several other domains have largely been subsumed by transformers [57].
Many classes of image-level generative models remain holdouts to the trend, though—while transformers see widespread use in autoregressive models [3,6,40,44], they have seen less adoption in other generative modeling frameworks.
For example, diffusion models have been at the forefront of recent advances in image-level generative models [9,43];
yet, they all adopt a convolutional U-Net architecture as the defacto choice of backbone.
在变压器的推动下,机器学习正在经历复兴。
在过去的五年中,用于自然语言处理[8,39]、视觉[10]和其他几个领域的神经架构在很大程度上已经被变压器[57]所包含。
许多图像级生成模型仍然不受这一趋势的影响,尽管变形金刚在自回归模型中得到了广泛的应用[3,6,40,44],但它们在其他生成建模框架中应用较少。
例如,扩散模型一直处于图像级生成模型最新进展的前沿[9,43];
然而,它们都采用卷积U-Net架构作为骨干网的实际选择。
The seminal work of Ho et al. [19] first introduced the U-Net backbone for diffusion models. The design choice was inherited from PixelCNN++ [49, 55], an autoregressive generative model, with a few architectural changes. The model is convolutional, comprised primarily of ResNet [15] blocks.
In contrast to the standard U-Net [46], additional spatial self-attention blocks, which are essential components in transformers, are interspersed at lower resolutions.
Dhariwal and Nichol [9] ablated several architecture choices for the U-Net, such as the use of adaptive normalization layers [37] to inject conditional information and channel counts for convolutional layers.
However, the high-level design of the U-Net from Ho et al. has largely remained intact.
Ho等人[19]的开创性工作首次为扩散模型引入了U-Net骨干网。
设计选择继承自pixelcnn++[49, 55],一个自回归生成模型,有一些架构上的变化。该模型是卷积的,主要由ResNet[15]块组成。
与标准U-Net[46]相比,附加的空间自注意块是变压器中的基本组件,以较低的分辨率散布。
Dhariwal和Nichol[9]消除了U-Net的几种架构选择,例如使用自适应非屏蔽层[37]为卷积层注入条件信息和通道计数。
然而,Ho等人的U-Net的高级设计基本保持不变。
With this work, we aim to demystify the significance of architectural choices in diffusion models and offer empirical baselines for future generative modeling research.
We show that the U-Net inductive bias is not crucial to the performance of diffusion models, and they can be readily replaced with standard designs such as transformers.
As a result, diffusion models are well-poised to benefit from the recent trend of architecture unification—e.g., by inheriting best practices and training recipes from other domains, as well as retaining favorable properties like scalability, ro- bustness and efficiency.
A standardized architecture would also open up new possibilities for cross-domain research.
通过这项工作,我们旨在揭示扩散模型中建筑选择的重要性,并为未来的生成建模研究提供经验基线。
我们表明,U-Net inductive bias对扩散模型的性能不是至关重要的,并且它们可以很容易地用标准设计(如变压器)代替。
因此,扩散模型很好地准备从架构统一的最近趋势中获益。通过继承来自其他领域的最佳实践和培训配方,以及保留诸如可伸缩性、抗破坏性和效率等有利属性。
标准化的体系结构也将为跨领域研究开辟新的可能性。
In this paper, we focus on a new class of diffusion models based on transformers.
We call them Diffusion Transformers, or DiTs for short.
DiTs adhere to the best practices of Vision Transformers (ViTs) [10], which have been shown to scale more effectively for visual recognition than traditional convolutional networks (e.g., ResNet [15]).
本文讨论了一类新的基于变压器的扩散模型。
我们称之为扩散变压器,简称dit。
dit坚持视觉变形金刚(ViTs)[10]的最佳实践,它已被证明比传统的卷积网络(例如ResNet[15])更有效地扩展视觉识别。
More specifically, we study the scaling behavior of transformers with respect to network complexity vs. sample quality. We show that by constructing and benchmarking the DiT design space under the Latent Diffusion Models (LDMs) [45] framework, where diffusion models are trained within a VAE’s latent space, we can successfully replace the U-Net backbone with a transformer.
We further show that DiTs are scalable architectures for diffusion models: there is a strong correlation between the network complexity (measured by Gflops) vs. sample quality (measured by FID).
By simply scaling-up DiT and training an LDM with a high-capacity backbone (118.6 Gflops), we are able to achieve a state-of-the-art result of 2.27 FID on the class- conditional 256 × 256 ImageNet generation benchmark.
更具体地说,我们研究了变压器的标度行为与网络复杂度和样本质量的关系。我们表明,通过在潜扩散模型(ldm)[45]框架下构建和对标DiT设计空间,其中扩散模型在VAE的潜空间内训练,我们可以成功地用变压器取代U-Net骨干。
我们进一步表明dit是扩散模型的可扩展架构:网络复杂性(由Gflops测量)与样本质量(由FID测量)之间存在很强的相关性。
通过简单地扩展DiT并训练具有高容量主干(118.6 Gflops)的LDM,我们能够在类别条件256 × 256 ImageNet生成基准上实现2.27 FID的最先进结果。
相关工作related work
略过
...
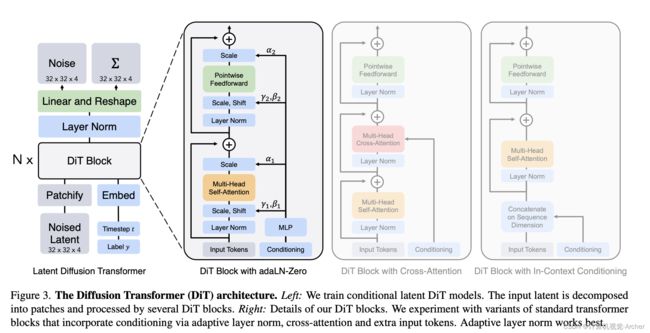
Figure 3. The Diffusion Transformer (DiT) architecture.
Left: We train conditional latent DiT models.
The input latent is decomposed into patches and processed by several DiT blocks.
Right: Details of our DiT blocks. We experiment with variants of standard transformer blocks that incorporate conditioning via adaptive layer norm, cross-attention and extra input tokens. Adaptive layer norm works best.
扩散变压器(DiT)架构。左:我们训练条件潜在DiT模型。
将输入潜伏期分解成小块,由多个DiT块进行处理。
右:DiT块的细节。
我们对标准变压器块的变体进行了实验,这些变体通过自适应层范数、交叉注意和额外的输入令牌结合了条件调节。自适应层范数效果最好