目标跟踪:Model Uncertainty Guides Visual Object Tracking(AAAI2021)
论文地址:Model Uncertainty Guides Visual Object Tracking
1.Motivation
目标跟踪模型很大程度上依赖从潜在的不同样本帧中在线学习辨别分类器。但是,噪声或样本量不足会降低分类器的性能,导致跟踪器漂移;遮挡和模糊等变化会导致目标丢失。
2.Contribution
第一,提出在线学习采样方法,有效地选择有代表性的样本来满足跟踪器的分类分支,同时去除噪声样本。
第二,提出数据增强方法和一个特定的改进的骨干网络结构。
第三,以上改进都集合在一个模型中,称为UATracker。
3.Method
该模型建立在DIMP跟踪器的基础上,其中包括一个目标分类分支和一个目标定位分支。分类分支是在线学习的一个分支,用于识别粗糙位置。再将这些粗定位信息反馈给目标定位分支,估计出目标的精确位置,如图1所示。这里没有显示目标定位分支,详情请参阅ATOM。
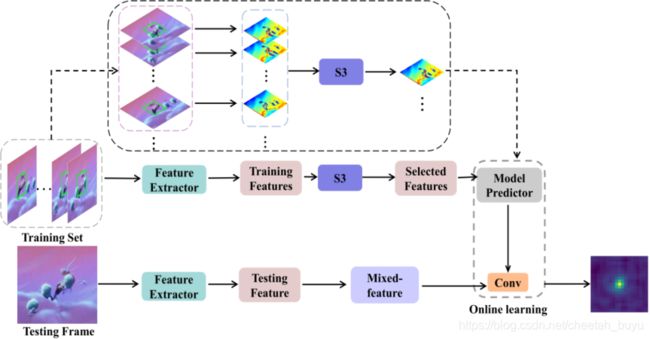
跟踪器的分类分支由两个分支组成,如图1所示。中间分支以一个参考帧和指示目标位置的边界框作为输入,并输出目标外观的特征表示。底部分支以单个测试帧作为输入。将模型的底部分支得到的测试帧的最终特征表示与滤波器ω进行卷积,得到目标在测试帧某一区域的概率的得分图,使用训练帧的标签通过在线学习训练滤波器ω。
Online Learning Loss
跟踪器通过使用之前的采样帧作为训练样本来训练分类分支,并将跟踪响应与以边框标签中心为中心的高斯先验c之间的差异最小化。训练样本表示为 x m x_m xm。当加入新的样本帧时,通过最小化以下函数来更新分类分支的参数: L ( ω ) = 1 M ∑ m = 1 M ∥ r ( x m ∗ ω , c m ) ∥ 2 + λ ∥ ω ∥ 1 , ( 1 ) L(\omega)=\frac{1}{M} \sum_{m=1}^{M}\left\|r\left(x_{m} * \omega, c_{m}\right)\right\|^{2}+\lambda\|\omega\|^{1},(1) L(ω)=M1m=1∑M∥r(xm∗ω,cm)∥2+λ∥ω∥1,(1)
样本 { 1 , 2 , . . . , M } \left\{1,2,...,M\right\} {1,2,...,M}的选择策略是S3, c m c_m cm是目标位置的高斯先验,*表示多通道卷积, x m ∗ ω x_m*\omega xm∗ω是卷积得到的跟踪响应,r是像素点损失函数, λ \lambda λ是超参数。通过优化等式1,预测目标响应图以估计目标粗略位置。
在线学习分支的性能很大程度上依赖于样本的质量,样本选择又依赖于模型的上一次迭代,这可能会出现错误。所以作者将不确定性估计之间嵌入到模型回归分支的损失中,并将其作为权重,对每个区间的样本进行平均,找到最可靠的样本。具体方法如下:
Uncertainty-sensitive Online Learning
这个跟踪器包含一个回归分支,该分支估计目标的形状,并通过训练来计算目标和任意提议框的 Intersection Over Union (IOU)。作者用联合不确定性预测(joint uncertainty prediction)来增强这个分支,并进一步使用这种不确定性的度量来决定在测试时向在线学习分支提供哪些帧。
在What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision? 中,通过联合预测不确定性和输出来对异方差数据进行线性回归。作者从中得到灵感,将这些方法融入深度学习环境中。
该回归分支将一个提议边框(proposal bounding box)作为输入,然后输出目标和提议边框之间的IOU,同时使用不确定性度量(uncertainty measure) σ \sigma σ增强该分支,回归分支输出如下: ( y , σ ) = I O U θ ( B ) , ( 2 ) \left(y,\sigma \right)=IOU_\theta \left(B\right),(2) (y,σ)=IOUθ(B),(2)其中, θ \theta θ表示神经网络的权重, σ \sigma σ是神经网络返回的IOU预测值y的不确定性估计。
使用如下损失函数对回归分支进行训练: L ( θ ) = ∑ i [ 1 2 exp ( − σ i ) ∥ y i − y ^ i ∥ 2 + 1 2 σ i ] , ( 3 ) L(\theta)=\sum_{i}\left[\frac{1}{2} \exp \left(-\sigma_{i}\right)\left\|y_{i}-\hat{y}_{i}\right\|^{2}+\frac{1}{2} \sigma_{i}\right],(3) L(θ)=i∑[21exp(−σi)∥yi−y^i∥2+21σi],(3)这个损失函数中,不确定性 σ \sigma σ不需要明确的标签。也就是说,当 ∣ ∣ y i − y ^ i ∣ ∣ ||y_i-\hat y_i|| ∣∣yi−y^i∣∣值较大时, σ \sigma σ直接采用一个大的值。因此,结合预测结果 y i y_i yi和这个特殊的损失函数, σ \sigma σ可以估计输入数据的噪声,从而过滤掉提供给在线学习分支的训练集中的不可靠样本。
作者提出S3(Significant Sample Selection)策略来获取高质量的代表性样本。
将当前帧之前的帧划分为多个区间,考虑到每个样本输出的不确定性,从每个区间中选择一个具有代表性的帧。对于每个区间 J,作者根据公式2计算的不确定性为每个样本分配一个权重,然后计算平均值,来选择一个代表性样本。 x ~ = 1 ∑ j ∈ J exp ( − σ j ) ∑ j ∈ J exp ( − σ j ) x j , ( 4 ) \tilde{x}=\frac{1}{\sum_{j \in J} \exp \left(-\sigma_{j}\right)} \sum_{j \in J} \exp \left(-\sigma_{j}\right) x_{j},(4) x~=∑j∈Jexp(−σj)1j∈J∑exp(−σj)xj,(4)其中, x j x_j xj是每个区间 J 中的样本帧 j 的特征表示,最小化 ∣ x j − x ~ ∣ |x_j-\tilde x| ∣xj−x~∣作为初步选择的样本。如果 x j x_j xj返回的分数高于预先设定的阈值,则保留将该样本作为区间的代表性样本,否则选择下一个最近的样本。只有已知包含目标高置信度信息的样本才能成为模板训练集的一部分,这样确保模板不会被污染。
Two Effective Ways to Improve the Model
如果训练数据缺乏多样性,训练好的模型的泛化能力就会很差。为了进一步提高跟踪器的泛化性能,作者提出了两种方法:(1)用更多样化的人工样本来扩充数据;(2)提高模型架构的鲁棒性。
Mixed-feature Method for the Training
混合特征:训练分类分支时采用“混合特征”这种数据增强策略。作者用特征空间中另一个样本 x j x_j xj干扰样本帧 x i x_i xi,并保留第一个样本的标签。由于CNN特征图保留了类似图像的外观,因此可以将这种干扰看作遮挡或模糊的类似。
生成虚拟样本:SGD每次迭代时,随机选择两个样本 ( x i , y i ) \left(x_i,y_i\right) (xi,yi)和 ( x j , y j ) \left(x_j,y_j\right) (xj,yj),y 表示标签,并在 β \beta β分布 β ( 0.1 , 0.1 ) \beta(0.1,0.1) β(0.1,0.1) 随机选择参数 λ \lambda λ(鼓励选择接近0或1的值)。 x ˉ = λ x j + ( 1 − λ ) x i , ( 5 a ) y ˉ = y i 1 λ < 0.5 + y j 1 λ ≥ 0.5 , ( 5 b ) \begin{array}{l} \bar{x}=\lambda x_{j}+(1-\lambda) x_{i} ,(5a)\\ \bar{y}=y_{i} 1_{\lambda<0.5}+y_{j} 1_{\lambda \geq 0.5},(5b) \end{array} xˉ=λxj+(1−λ)xi,(5a)yˉ=yi1λ<0.5+yj1λ≥0.5,(5b)其中,1表示指示函数。如果, λ < 0.5 \lambda<0.5 λ<0.5( x ˉ \bar x xˉ更接近 x i x_i xi),则将标签设置为 y i y_i yi,否则将标签设置为 y j y_j yj。将这个虚拟样本 ( x ˉ , y ˉ ) \left(\bar x,\bar y \right) (xˉ,yˉ)提供给离线的目标分类分支。
Deformable Convolutions for the Backbone
可变性卷积:传统CNN的卷积核大小限制对几何变形等进行建模的能力。作者采用可变性卷积替换了骨干网络Resnet50的layer2-layer4中所有的3*3卷积层。
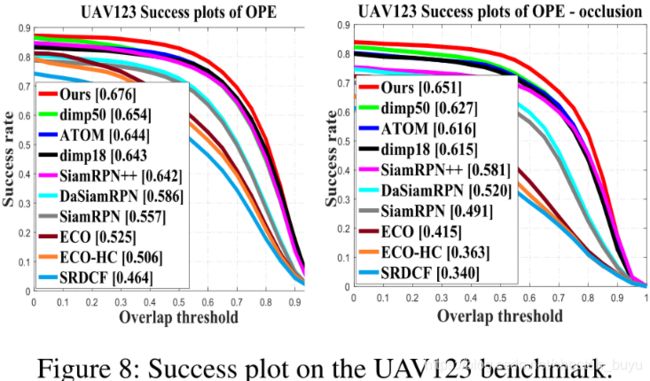
4.Experiments