R-C3D—基于区域卷积3D网络的时序行为检测
R-C3D: Region Convolutional 3D Network for Temporal Activity Detection
论文地址:https://arxiv.org/pdf/1703.07814.pdf
行为检测是行为识别的一个分支,个人认为其目的为了提高行为识别的准度。行为检测处理的对象大部分是视频数据。它完成检测任务大致可以分为两个阶段,第一个阶段为从视频中提取相关行为空间和时间特征,第二个阶段是基于这些特征准确的定位具体行为在视频中的开始和结束时间。在R-C3D之前,处理该问题最好的方法主要通过滑动窗形式生成的时间段,之后对这些时间段进行分类,或者通过额外区域推荐机制来产生时间段。上述这些方式中有些是基于手工设计的特征或者通过在特定图像或视频数据集上训练好的网络来提取特征,通常都对数据集建立了很强的假设,大部分采用非端到端的训练,检测精度相对不是很好,训练时间相对较长。R-C3D提出对前面存在的问题进行了很好的解决。
R-C3D(RegionConvolutional3DNetworkforTemporalActivityDetection),2017发表在ICCV上的一篇文章,作者主要是以C3D网络为基础,并借鉴了Faster RCNN的思路。R-C3D用3D全卷积网络对视频流编码,生成可能包含行为的时间范围proposal,然后对proposal进行分类和微调,如图1。该模型与现有方法相比,在速度和精度上有了大幅度提高。R-C3D三个主要的贡献:(1)可以针对任意长度视频、任意长度行为进行端到端的检测;(2)参数共享,速度很快(是目前网络的5倍)如图11;(3)具有很好的通用性,作者测试了3个不同的数据集,效果都很好。

图1. R-C3D数据流处理过程
R-C3D网络有三部分组成,3D ConvNet,Proposal Subnet和Classification Subnet。3D ConvNet(如图2),特征提取网络,以视频帧作为输入,通过卷积计算features。其features被后面的Proposal Subnet和Classification Subnet两个子网络所共享。
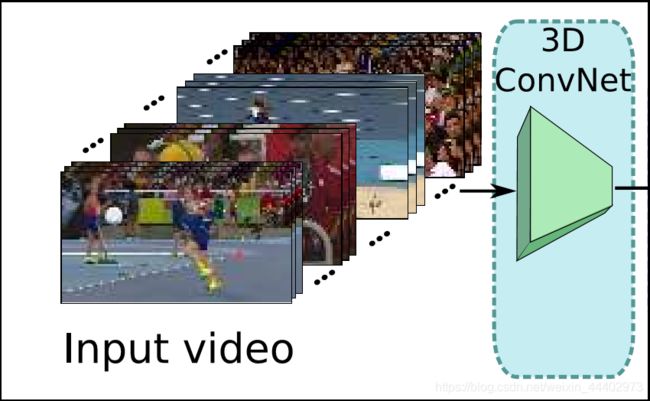
图2. 3D ConvNet
Proposal Subnet(如图3),以features作为输入,生成不同长度的proposals以及相应的confidence scores。Classification Subnet(如图4),对proposals 进行过滤,通过3D ROI Pooling池将3D ConvNet输出的feature map和NMS之后的不同长度的anchor segments转换为成固定长度的features map,然后进行行为类别分类并预测出精修后的行为边界。
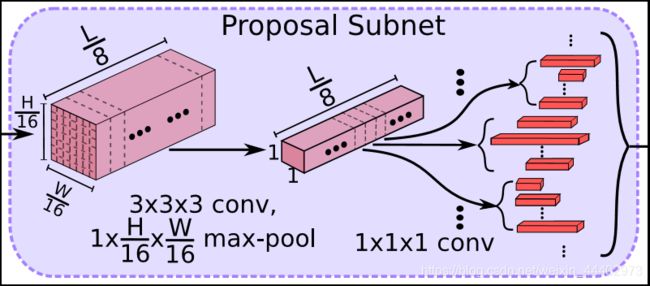
图3. Proposal Subnet子网络
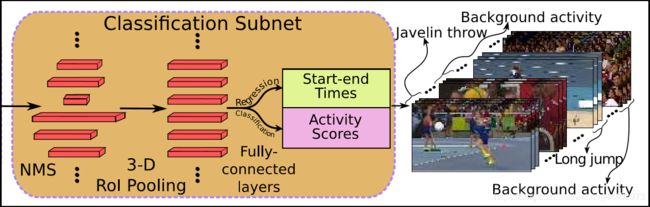
图4. Classification Subnet子网络
接下来,我想对于网络各个部分小组件的作用进行阐述。首先对于特征提取层,作者采用C3D的卷积层(conv1a到conv5b),其产生特征映射Conv5b的输出为512×L/8×H/16×W/16(512是层conv5b的通道数量;L使输入时间帧数;H,W分辨代表图像的高度和宽度)。C3D卷积网络的输入帧的高度(H)和宽度(W)分别为112,帧的数目可以是任意的(文章说明只是收到GPU memory的影响)。其次是Proposal Subnet结构,该网络类似于Faster R-CNN的RPN网络,用来生成Candidate Proposal Segments。这里使用了anchor机制,作者假设anchor均匀分布在L/8的时间域上,也就是有L/8个anchors,每个anchors生成K个不同scale的候选时序。很重要的一点,其实相对于网络开始输入帧的时间维度L,经过池化降采样了1/8,也就是一个anchor对应于原始输入中的8帧图片,我们对这8帧图片使用K个scale的anchor段作为候选段(我们假设视频帧率为25fps,那么每个scale换算到对应视频时间长度为8*scale/25),这就是anchors的生成规则。3D Pooling对特征图使用一个3X3X3的卷积核,这样做的目的是想进一步集中特征信息,之后使用一个核大小为1 x H/16 x W/16的3D max-pooling层在空间维度上进行下采样,产生只含有时序信息的特征图(512 x L/8 x 1 x 1)。对下采样后的特征图中,每个时序位置处的512维特征向量用来预测每个anchor的相对的中心位置和长度{![]() } ,同时预测每个proposal是行为还是背景事件的二分类分数,具体Proposal的坐标和分数通过在3D max-pooling层后面添加两个1x1x1的卷积层进行预测。最后是Classification Subnet,其由三部分组成,首先是NMS,对Proposal Subnet生成的候选proposals进行选择,来去除一些高度重叠和低置信度的候选框,文章中NMS阈值设定为0.7;接着是3D ROI pooling,其输入为3D ConvNet输出和NMS输出的候选框特征,遍历每个候选框(长度为lp),将其时间维度坐标缩小8倍,变为lp/8*7*7的sub-volume映射到L/8*7*7上一个确定的区域,之后将这个sub-volume分成m*n*s个大小相同的min-sub-volumes,之后在每个min-sub-volume中进行池化操作,最终生成m*n*s固定大小的volume(shape:m*n*s*512),最后输出volume个数等于NMS之后proposals segments个数。经过3D RoI pooling layer之后,batch_size=NMS之后proposals segments个数,feature map维度:m*n*s*512分别输入到softmax层和位置回归层对每个检测框进行分类和位置回归。
} ,同时预测每个proposal是行为还是背景事件的二分类分数,具体Proposal的坐标和分数通过在3D max-pooling层后面添加两个1x1x1的卷积层进行预测。最后是Classification Subnet,其由三部分组成,首先是NMS,对Proposal Subnet生成的候选proposals进行选择,来去除一些高度重叠和低置信度的候选框,文章中NMS阈值设定为0.7;接着是3D ROI pooling,其输入为3D ConvNet输出和NMS输出的候选框特征,遍历每个候选框(长度为lp),将其时间维度坐标缩小8倍,变为lp/8*7*7的sub-volume映射到L/8*7*7上一个确定的区域,之后将这个sub-volume分成m*n*s个大小相同的min-sub-volumes,之后在每个min-sub-volume中进行池化操作,最终生成m*n*s固定大小的volume(shape:m*n*s*512),最后输出volume个数等于NMS之后proposals segments个数。经过3D RoI pooling layer之后,batch_size=NMS之后proposals segments个数,feature map维度:m*n*s*512分别输入到softmax层和位置回归层对每个检测框进行分类和位置回归。
接下来,我想阐述一下网络的优化。正如图5所示,网络包括两部分,第一部分为区域推荐网络,该网络结束时候会对每个anchor的K个scale形成的候选框进行过滤,总共形成的候选区域个数为L/8*K,若候选框与我们的GT标注框IOU超过0.7时或与我们GT有最高的IOU,则标注这些框为前景,否则为背景。对于区域回归具体计算如图6。ci:表示候选框的中心位置,li:表示候选框的长度,而c*i:表示GT框的中心位置,l*i:GT框的长度。而δci,δli是候选框相对与每一个GT值的中心位置和长度相对位置。图7

图5. 网络结构图
为损失函数,其中lamada为平衡因子,i为候选区在batch中索引,对于推荐网络,回归损失函数使用smooth L1损失,用来优化候选框和GT框相对位置偏移;分类损失用来调整网络参数使网络可以准确对背景和前景很好分类。接下来,我想对分类网络优化问题进行讲解,该网络中分类会对每个候选框分成具体的类别,而位置回归则使GT位置值和候选框位置值之间误差进行优化。

图6. 位置计算
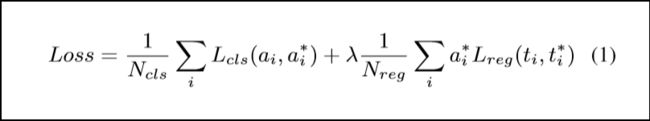
图7. 损失函数
最后我阐述一下预测和实验阶段。R-C3D中的预测包括两个步骤。首先,RPN网络生成候选区域,并预测每个候选区的开始-结束时间偏移量和置信度。然后通过阈值为0.7的NMS对候选区域进行过滤。NMS之后,所选候选区被送入分类网络,分类为特定的活动类别,候选框的活动边界由回归层进一步重新确定。RPN网络和分类子网的边界预测均采用中心点相对位移和分段长度的形式。为了得到预测的活动的在视频中开始时间和结束时间,需对图6进行反换。对于实验阶段主要对R-C3D进行评估,使用数据集为THUMOS’1,Charade,ActivityNet。对于每个推荐段计算时间公式8*scale/帧率。
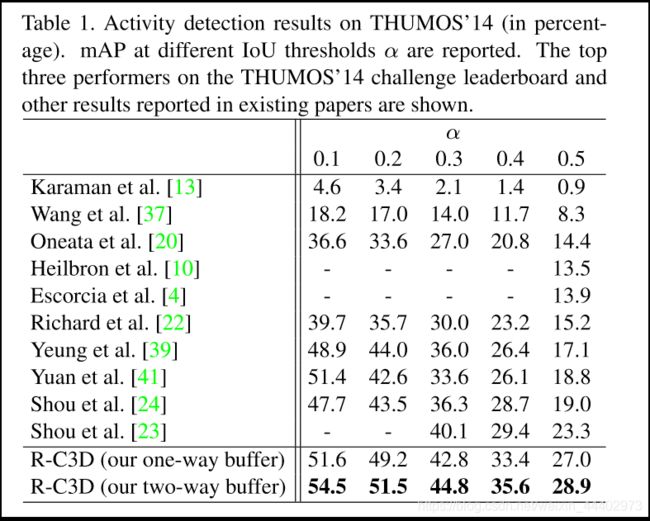
图8. THUMOS’1(at different IoU thresholdsαare reported)评估结果
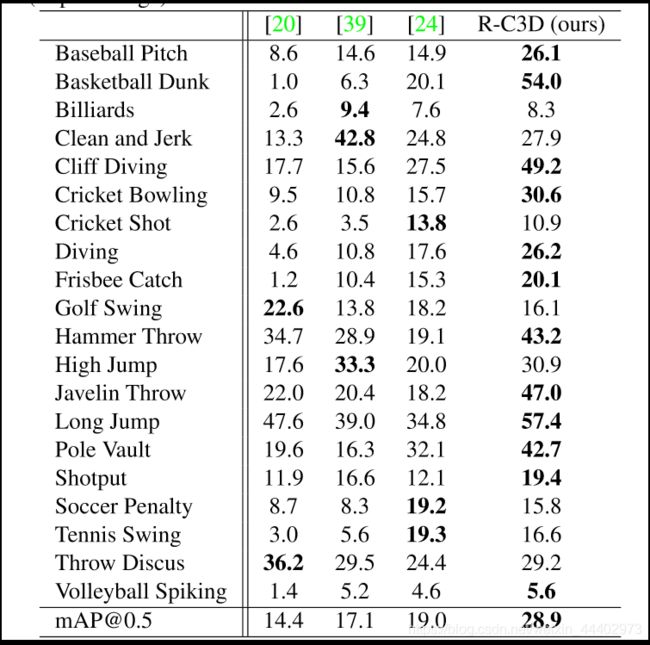
图8. Per-class AP at THUMOS’1(IoU thresholdα= 0.5 )评估结果
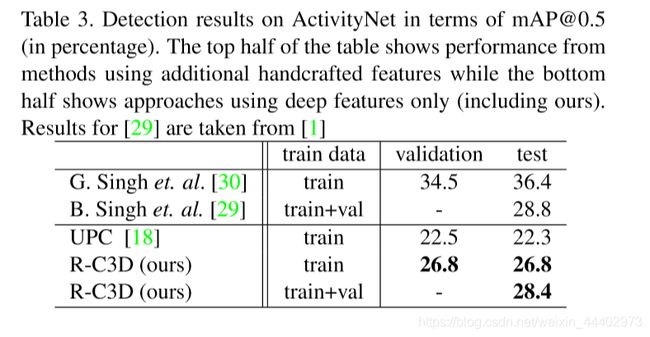
图9. Detection results on ActivityNet in terms of mAP
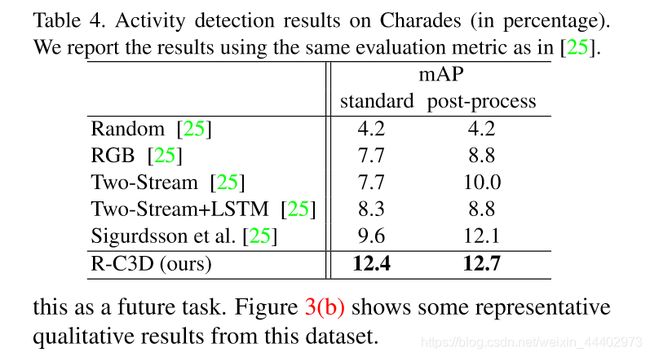
图10. Activity detection results on Charades

图11. Activity detection speed during inference
总结,读给论文我最大感受有些细节不太清楚,存在如下问题:1)为什么1*1*1的卷积可以实现对推荐网络每个候选框的分类?2)第一部分网络中分类损失如何优化(GT值是什么)?3)ROI pooling层修图原理是什么?我想遇到这些问题, 我们应该多读几遍,把文章中的一个关键字圈出来。同时结合其代码,我想会慢慢读懂的。