【论文阅读】Get To The Point: Summarization with Pointer-Generator Networks
2017 ACL 指针生成网络
文章目录
-
- Abstract
- 1 Introduction
- 2 Our Models
-
- 2.1 Sequence-to-sequence attentional model
- 2.2 Pointer-generator network
- 2.3 Coverage mechanism
- 3 Related Work
- 4 Dataset
- 5 Experiments
- 6 Results
-
- 6.1 Preliminaries(准备工作)
- 6.2 Observations
- 7 Discussion
-
- 7.1 Comparison with extractive systems
- 7.2 How abstractive is our model?
- 8 Conclusion
Abstract
神经序列到序列模型为抽象文本摘要提供了一种可行的新方法(这意味着它们不局限于简单地从原始文本中选择和重新安排段落)。然而,这些模型有两个缺点:它们容易不准确地再现事实细节,而且它们倾向于重复自己。在这项工作中,我们提出了一个新的结构,以两种正交的方式增加标准的序列到序列的注意模型。首先,我们使用了一个混合的指针生成网络,它可以通过pointing从源文本中复制单词,这有助于准确地复制信息,同时保留了通过generator生成新单词的能力。其次,我们使用coverage来跟踪已经总结的内容,这就不鼓励重复。我们将我们的模型应用到CNN /每日邮报的总结任务中,比目前的抽象技术至少高出2个ROUGE点。
1 Introduction
摘要是将一段文本浓缩为包含原始文本主要信息的较短版本的任务。 摘要有两种广泛的方法:抽取式和抽象式。 抽取法只从直接从源文本中摘取的段落(通常是整句)中收集摘要,而抽象法可能会生成源文本中没有的新词和短语–就像人类编写的摘要通常所做的那样。 提取方法更容易,因为从源文档复制大块文本可以确保语法和准确性的基线水平。 另一方面,对于高质量摘要至关重要的复杂能力,如释义、概括或现实世界知识的结合,只有在抽象框架中才有可能(参见图5)。
由于抽象总结的困难,过去的绝大多数工作都抽取性的。 然而,最近序列到序列模型的成功使得抽象摘要变得可行。 尽管这些系统很有前途,但它们也表现出一些不良行为,如不准确地再现事实细节、无法处理词汇表外(OOV)单词以及重复(参见图1)。

在本文中,我们提出了一个在多句摘要的上下文中解决这三个问题的体系结构。 虽然最近的抽象工作集中在标题生成任务(将一两个句子简化为一个标题)上,但我们认为长文摘要更具挑战性(需要更高的抽象级别,同时避免重复),而且最终更有用。 因此,我们将我们的模型应用于最近引入的CNN/Daily Mail数据集,该数据集包含新闻文章(平均39句)和多句摘要,并表明我们比最先进的抽象系统的性能高出至少2个ROUGE点。
我们的混合指针-生成器网络通过指向方便了从源文本复制单词,这提高了OOV单词的准确性和处理,同时保留了生成新词的能力。 该网络可以被看作是抽取和抽象方法之间的平衡,类似于Gu et al.(2016)的CopyNet和Miao and Blunsom(2016)的强制注意句子压缩,它们被应用于短文本摘要。 我们从神经机器翻译中提出了一种coverage vector的新变体(Tu et al.,2016),我们使用它来跟踪和控制源文档的覆盖。 我们证明coverage 对消除重复是非常有效的。
2 Our Models
在本节中,我们将描述(1)我们的基线序列到序列模型,(2)我们的PointerGenerator模型,以及(3)我们的覆盖机制,可以添加到前两个模型中的任何一个。 我们模型的代码可以在线获得。www.github.com/abisee/pointer-generator
2.1 Sequence-to-sequence attentional model
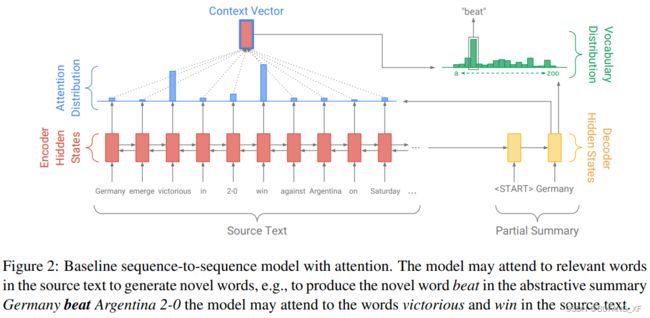
我们的基线模型与Nallapati等人的相似。 (2016),如图2所示。 文章中的令牌Wi被一个接一个地送入编码器(单层双向LSTM),产生编码器隐层状态hi序列。 在每个步骤t上,解码器(单层单向LSTM)接收前一个单词的单词嵌入(在训练时,这是参考摘要的前一个单词;在测试时,这是解码器发出的前一个单词),并具有解码器状态st。注意力分布at计算方法与Bahdanau等人相同。 (2015年):
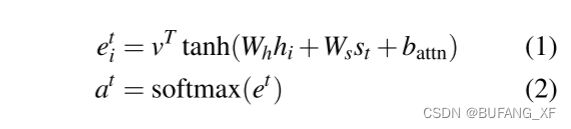
其中V、WH、WS和Battn是可学习参数。注意力分布可以看作是源词的概率分布,它告诉解码器在哪里寻找产生下一个词。 接下来,使用注意力分布来产生编码器隐藏状态的加权和,称为上下文向量h*t:
上下文向量可以看作是这一步从源读取的内容的FixedSize表示,它与解码器状态ST级联,并通过两个线性层馈送,以产生词汇分布PVOCAB:

PVOCAB是词汇表中所有单词的概率分布,它为我们提供了预测单词w的最终分布:

2.2 Pointer-generator network

我们的指针生成器网络是我们的基线和指针网络(Vinyals et al.,2015)之间的混合体,因为它既允许通过指向复制单词,也允许从固定词汇表生成单词。 在指针生成器模型(如图3所示)中,注意力分布AT和上下文向量HT如2.1节所示计算。 另外,时间步长T的生成概率Pgen∈[0,1],由上下文向量HT、解码器状态ST和解码器输入XT计算:

接着,PGEN被用作软开关,以选择是通过从PVOCAB中采样从词汇表中生成单词。还是通过从AT的关注分布中采样从输入序列中复制单词。 对于每个文档,让扩展词汇表表示这些词汇表和源文档中出现的所有单词的联合。 我们在扩展词汇表上得到以下概率分布:

注意,如果w是词汇表外(OOV)词,那么pvocab(w)为零; 类似地,如果w没有出现在源文档中,那么∑i:wi=wati为零。 产生OOV词的能力是指针生成器模型的主要优点之一; 相比之下,像我们的基线这样的模型被限制在它们预先设置的词汇表中。
损失函数如方程(6)和(7)所述,我们在方程(9)中给出的修正概率分布p(w)。
2.3 Coverage mechanism
重复是Sequenceto-Sequence模型的一个常见问题,在生成多句文本时尤其明显(见图1)。 我们改写了Tu等人的覆盖模型。 (2016年)解决问题。 在我们的覆盖模型中,我们维护一个覆盖向量CT,它是所有先前时间步骤解码器上的注意力分布的总和:

直观地说,CT是源文档单词上的一个(非规范化)分布,它代表了这些单词到目前为止从注意力机制中获得的覆盖程度。 请注意,C0是一个零向量,因为在第一个timestep中,没有一个源文档被覆盖。
覆盖向量被用作注意力机制的额外输入,将等式(1)改为:

这确保了注意机制当前的决定(选择下一次关注的点)被它以前的决定的提醒通知(summarized in ct )。 这将使注意力机制更容易避免重复关注相同的位置,从而避免产生重复的文本。
我们发现有必要(见第5节)另外定义coverage loss,以惩罚重复处理同一地点:

等式(12)不同于机器翻译中使用的覆盖损失。 在机器翻译中,我们假设应该有一个大致一对一的翻译比; 因此,如果最终覆盖向量大于或小于1,则对其进行惩罚。
我们的损失函数更加灵活:因为摘要不应该要求统一的覆盖,我们只惩罚每个注意力分布与迄今为止覆盖之间的重叠–防止重复注意。 最后,由一些超参数λ重新加权的复盖损失,被添加到主损失函数,以产生一个新的混合损失函数:
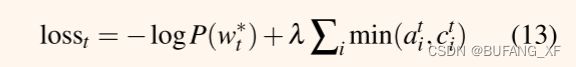
3 Related Work
Neural abstractive summarization..拉什等人。 (2015)是第一个将现代神经网络应用于抽象文本摘要的人,在DUC-2004和GigaWord这两个句子级摘要数据集上实现了最先进的性能。 他们的方法以注意力机制为中心,通过循环解码器(Chopra et al.,2016)、抽象意义表示(Takase et al.,2016)、分层网络(Nallapati et al.,2016)、变分自动编码器(Miao and Blunsom,2016)和直接优化性能度量(Ranzato et al.,2016),进一步提高了这些数据集的性能。
然而,用于较长文本摘要的大规模数据集很少。 纳拉帕蒂等人。 (2016)改编了DeepMind问答数据集(Hermann et al.,2015)进行总结,产生了CNN/Daily Mail数据集,并提供了第一个抽象基线。 同样的作者随后发表了一种神经提取方法(Nallapati et al.,2017),该方法使用分层RNN来选择句子,并发现相对于Rouge度量,它显著优于他们的抽象结果。 据我们所知,这是完整数据集上仅有的两个公布的结果。
在现代神经方法之前,抽象文摘比抽取文摘受到的关注少,但Jing(2000)探索切割句子中不重要的部分来创建文摘,Cheung和Penn(2014)探索使用依赖树进行句子融合。
Pointer-generator networks. 指针网络(Vinyals et al.,2015)是一个使用Bahdanau等人的软注意力分布的序列对序列模型。 (2015)产生由输入序列中的元素组成的输出序列。 指针网络已被用于为NMT(Gulcehre et al.,2016)、语言建模(Merity et al.,2016)和摘要创建混合方法 。
我们的方法接近Miao和Blunsom(2016)的强迫注意句子压缩模型和Gu et al.(2016)的CopyNet模型,但有一些小的差异:(i)我们计算了明确的切换概率pgen,而Gu et al.通过共享的softmax函数诱导竞争。(ii)我们回收注意力分布作为拷贝分布,但Gu等人使用两个单独的分布。(iii)当一个单词在源文本中多次出现时,我们将注意力分布的所有相应部分的概率质量相加,而Miao和Blunsom没有。我们的推理是:(i)计算一个明确的pgen有效地使我们能够同时提高或降低所有生成单词或所有复制单词的概率,而不是单独提高或降低概率,(ii)这两种分布具有类似的目的,我们发现我们更简单的方法就足够了,以及(iii)我们观察到,指针机制通常会复制一个单词,同时关注它在源文本中的多次出现。
我们的方法与Gulcehre等人的方法大不相同。 (2016)和Nallapati等人 (2016年)。 这些工作训练它们的指针组件只为词汇表外的单词或命名实体激活(而我们允许我们的模型自由地学习何时使用指针),它们不会混合来自副本分布和词汇表分布的概率。 我们认为这里描述的混合方法更适合于抽象文摘–在第6节中,我们表明复制机制对于准确复制稀有但在词汇表中的单词至关重要,在第7.2节中,我们观察到混合模型使语言模型和复制机制能够协同工作来执行抽象文摘。
Coverage. 覆盖源于统计机器翻译(Koehn,2009),由Tu等人修改为NMT。 (2016)和米等人。 (2016),他们都使用一个GRU来更新每一步的覆盖向量。 我们发现一种更简单的方法–对注意力分布求和以获得覆盖向量–就足够了。 在这方面,我们的方法类似于Xu等人。 (2015),他们将一种类似覆盖的方法应用于图像帽配比,以及Chen等人。 (2016),他们还将方程(11)中描述的覆盖机制(他们称之为“分心”)纳入对较长文本的神经摘要。
Temporal attention是一种相关技术,已应用于NMT(Sankaran et al.,2016)和摘要(Nallapati et al.,2016)。 在这种方法中,每一个注意力分配被前一个注意力分配的总和除以,有效地抑制了重复的注意力。 我们尝试了这种方法,但发现它的破坏性太大,扭曲了来自注意力机制的信号,降低了性能。 我们假设,像覆盖这样的早期干预方法比像时间注意这样的事后干预方法更好–通知注意机制以帮助它做出更好的决定比完全推翻它的决定更好。 这一理论得到了覆盖给我们的胭脂评分带来的巨大提升(见表1),而相同任务的时间关注给我们的提升较小(Nallapati et al.,2016)。
4 Dataset
我们使用CNN/Daily Mail数据集(Hermann et al.,2015;Nallapati et al.,2016),其中包含在线新闻文章(平均781个令牌)与多句摘要(平均3.75句或56个令牌)配对。 我们使用了Nallapati等人提供的脚本。 (2016)获得了相同版本的数据,其中有287,226个训练对、13,368个验证对和11,490个测试对。 这两个DataSet已发布的结果(Nallapati et al.,2016,2017)都使用了数据的匿名版本,该版本已经过预处理,以将每个命名实体(如联合国)替换为示例对的唯一标识符(如@Entity5)。 相比之下,我们直接对原始文本(或非匿名版本的数据)进行操作,2我们认为这是一个很好的解决问题,因为它不需要预处理。
5 Experiments
对于所有实验,我们的模型有256维的隐藏状态和128维的词嵌入。 对于指针生成器模型,我们对源和目标都使用50K单词的词汇表–注意,由于指针网络处理OOV单词的能力,我们可以使用比Nallapati et al.(2016)150K源词汇表和60K目标词汇表更小的词汇表。 对于基线模型,我们还尝试了150K的更大词汇量。
请注意,指针和覆盖机制为网络引入的额外参数很少:对于词汇表大小为50K的模型,基线模型有21,499,600个参数,指针生成器添加了1153个额外参数(公式8中的WH*、WS、WX和BPTR),覆盖机制添加了512个额外参数(公式11中的WC)。
不像Nallapati等人。 (2016),我们不预先训练单词嵌入–它们是在训练中从头学来的(白手起家 不用预训练参数)。 我们使用Adagrad(Duchi et al.,2011)进行训练,学习率为0.15,初始累加器值为0.1。 (这被发现是最有效的随机梯度下降,Adadelta,动量,Adam和RMSprop)。 我们使用最大梯度范数为2的梯度裁剪,但不使用任何形式的正则化。 我们在验证集上使用损失来实现早期停止。
在训练和测试时,我们将文章截断为400个令牌,并将摘要的长度限制为100个令牌用于训练,120个令牌用于测试。这样做是为了加快训练和测试,但我们也发现截断文章可以提高模型的性能(更多细节请参见7.1节)。 对于训练,我们发现从高度截断的序列开始,然后在收敛后提高最大长度是有效的。 我们在单个特斯拉K40M GPU上进行训练,批量大小为16个。 在测试时,我们的总结是使用波束大小为4的波束搜索产生的。
我们对我们的两个基线模型进行了大约60万次迭代(33个epochs))的训练–这与Nallapati等人(2016)的Best Model所要求的35个epochs)相似。 50K词汇量模型的训练时间为4天14小时,150K词汇量模型的训练时间为8天21小时。 我们发现指针生成器模型训练速度更快,需要不到23万次训练迭代(12.8个Epochs); 总共3天4小时。 特别是,指针生成器模型在训练的早期阶段取得了更快的进展。 为了获得最终的覆盖模型,我们添加了覆盖损失加权为λ=1的覆盖机制(如公式13所述),并训练了3000次迭代(约2小时)。 在这段时间里,覆盖损失收敛到约0.2,从约0.5的初始值下降。 我们还尝试了一个更积极的值λ=2; 这减少了覆盖损失,但增加了主损失函数,因此我们没有使用它。
我们尝试在没有损失函数的情况下训练覆盖模型,希望注意力机制可以自己学习不要重复注意同一位置,但我们发现这是无效的,重复没有明显的减少。 我们也尝试从第一次迭代开始进行覆盖训练,而不是作为一个单独的训练阶段,但发现在训练的早期阶段,覆盖目标干扰了主要目标,降低了整体性能。
6 Results

6.1 Preliminaries(准备工作)
我们的结果在表1中给出。 我们用标准的Rouge度量(Lin,2004b)评估我们的模型,报告Rouge1、Rouge-2和Rouge-L的F1分数(它们分别测量参考摘要和待评估摘要之间的单词重叠、Bigram-重叠和最长公共序列)。 4我们还使用Meteor度量(Denkowski and Lavie,2014)在精确匹配模式(只奖励单词之间的精确匹配)和完整模式(额外奖励匹配的词干、同义词和释义)下进行评估。5
除了我们自己的模型,我们还报告了Lead-3基线(它使用文章的前三句话作为总结),并在完整的数据集上与仅有的抽象化(Nallapati et al.,2016)和抽象化(Nallapati et al.,2017)模型进行了比较。 我们的模型的输出可以在线获得。6
鉴于t我们生成纯文本摘要,但是Nallapati等人。 (2016;2017)生成匿名摘要(见第4节),我们的ROUGE评分没有严格的可比性。 有证据表明,原始文本数据集可能会比匿名数据集导致更高的Rouge分数–前者的Lead-3基线高于后者。 一种可能的解释是,多词命名实体导致更高的n元重叠率。 不幸的是,ROUGE是唯一可用的手段与Nallapati等人的工作进行比较。 然而,鉴于Lead-3评分的差异分别为(+1.1Rouge-1、+2.0Rouge-2、+1.1Rougel)点,我们的最佳模型评分超过了Nallapati等人。 (2016)通过(+4.07Rouge1,+3.98Rouge-2,+3.73Rouge-L)点,我们可以估计我们至少比以前唯一的抽象系统的性能高出至少2个Rouge点。
6.2 Observations
我们发现我们的两个基线模型在Rouge和Meteor方面的表现都很差,事实上更大的词汇量(150K)似乎没有帮助。 即使是性能较好的基线(有50K词汇表)也会产生包含几个常见问题的摘要。 事实细节经常被错误地复制,经常用一个更常见的替代词代替一个不常见的(但在词汇表中)词。 例如,在图1中,基线模型似乎与罕见的单词thewart进行了斗争,产生了disabilize,这导致了捏造的disabilize尼日利亚经济。 更糟糕的是,总结有时会变成重复的废话,如图1中基线模型产生的第三句话。 此外,基线模型无法再现词汇表外的单词(如图1中的Muhammadu Buhari)。 补充材料中提供了所有这些问题的进一步例子。
我们的指针生成器模型实现了比基线更好的ROUGE和METEOR得分,尽管训练时间少得多。 摘要中的区别也很明显:词汇表外的词处理得很容易,事实细节几乎总是正确地复制,没有捏造(见图1)。 然而,重复现象仍然很普遍。

我们的带覆盖的指针生成器模型进一步提高了Rouge和Meteor的得分,令人信服地超过了Nallapati等人的最佳抽象模型。 (2016)被几个ROUGE点。 尽管覆盖训练阶段很短(约占总训练时间的1%),但重复问题几乎完全消除,这既可以定性地看到(图1),也可以定量地看到(图4)。 然而,我们的最佳模型并没有完全超过Lead-3基线的Rouge分数,也没有超过当前的最佳提取模型(Nallapati et al.,2017)。 我们在第7.1节讨论这个问题。
7 Discussion
7.1 Comparison with extractive systems
从表1可以清楚地看出,抽取系统往往比抽象系统获得更高的ROUGE分数,并且抽取式lead-3基线非常强(即使是最好的萃取系统也只比它略胜一筹)。 我们对这些观察提供了两种可能的解释。
首先,新闻文章往往以最重要的信息开头; 这部分解释了Lead-3基线的强度。 事实上,我们发现,只使用文章的前400个标记(大约20句话)比使用前800个标记产生的Rouge分数要高得多。
其次,任务的性质和Rouge度量使得提取方法和Lead3基线很难被击败。 参考摘要内容的选择是相当主观的–有时句子形成了一个自成一体的摘要; 其他时候,它们只是展示文章中一些有趣的细节。 鉴于文章平均包含39个句子,有许多同样有效的方法来选择这种风格的3或4个亮点。 抽象引入了更多的选项(措辞的选择),进一步降低了与参考摘要匹配的可能性。 例如,对于图5中的第一个示例,走私者从绝望的移民中获利是一个有效的替代抽象摘要,但它相对于参考摘要的得分为0胭脂。 Rouge的这种不灵活性因只有一个参考摘要而加剧,与多个参考摘要相比,这表明Rouge的可靠性较低(Lin,2004a)。

由于任务的主观性和有效摘要的多样性,Rouge似乎奖励安全的策略,如选择首次出现的内容,或保留原始的措辞。 虽然参考摘要有时确实偏离了这些技术,但这些偏差是不可预测的,以至于更安全的策略平均获得更高的Rouge分数。 这可能解释了为什么萃取系统往往比抽提系统获得更高的ROUGE分数,甚至萃取系统也不会显著超过LEAD-3基线。
为了进一步探讨这个问题,我们使用Meteor度量来评估我们的系统,它不仅奖励精确的单词匹配,还奖励匹配词干、同义词和释义(来自预定义列表)。 我们观察到,所有模型都通过包含词干、同义词和释义匹配获得了超过1个流星点的提升,这表明它们可能正在执行一些抽象。 然而,我们再次观察到,我们的模型没有超过Lead-3基线。 可能是新闻文章风格使得Lead3基线在任何指标方面都非常强。 我们认为,进一步调查这一问题是今后工作的一个重要方向。
7.2 How abstractive is our model?
我们已经表明,我们的指针机制使我们的抽象系统更加可靠,更经常地正确复制事实细节。 但是复制的方便性是否使我们的系统变得不那么抽象了呢?

图6显示,我们最终模型的摘要包含的新n-grams(即那些没有出现在文章中的)的比率比参考摘要低得多,这表明抽象程度较低。 请注意,基线模型更频繁地产生新的n-grams–然而,这个统计数据包括所有错误复制的单词、UNK tokens和捏造,以及良好的抽象实例。
特别是,图6显示我们的最终模型在35%的时间内复制了整个文章句子; 相比之下,参考摘要只有1.3%的时间是这样做的。 这是一个主要的改进领域,因为我们希望我们的模型超越简单的句子提取。 然而,我们观察到其他65%包含了一系列抽象技术。 文章句子被截断,形成语法正确的短版本,新句子是通过拼接片段组成的。 不必要的感叹词、从句和带括号的短语有时会从抄写的段落中省略。 图1展示了其中的一些能力,补充材料包含了更多的例子。

图7显示了两个更令人印象深刻的抽象示例–它们都具有相似的结构。 该数据集包含许多体育故事,这些故事的摘要遵循的是X beat Y score on day的模板,这可能解释了为什么我们的模型在这些例子上最有信心地抽象出来。 然而,一般说来,我们的模型并不像图7中那样常规地生成摘要,也不像图5中那样接近于生成摘要。
生成概率pgen的值也给出了模型抽象性的度量。在训练期间,pgen的值从大约0.30开始,然后增加,在训练结束时收敛到大约0.53。这表明模型首先学习大部分的复制,然后学习大约一半的时间生成。然而,在测试时,pgen严重偏向于复制,平均值为0.17。这种差异可能是由于在培训期间,模型以参考摘要的形式接受逐字监督,但在测试时却没有。尽管如此,即使模型正在复制,生成器模块也很有用。我们发现,在不确定的情况下,例如句子的开头、缝合在一起的片段之间的连接以及产生截断复制句子的句点时,pgen最高。我们的混合模型允许网络在同时参考语言模型的同时进行复制,从而使拼接和截断等操作具有语法性。无论如何,鼓励指针生成器模型更抽象地编写,同时保留指针模块的准确性优势,是未来工作的一个令人兴奋的方向。
8 Conclusion
在这项工作中,我们提出了一个带覆盖的混合PointerGenerator体系结构,并表明它减少了不准确和重复。 我们将我们的模型应用于一个新的、具有挑战性的LongText数据集,并显著优于抽象的最新结果。 我们的模型展示了许多抽象能力,但是获得更高的抽象级别仍然是一个开放的研究问题。