人工智能学习笔记 实验五 python 实现 SVM 分类器的设计与应用
学习来源
【机器学习】基于SVM人脸识别算法的一些对比探究(先降维好还是先标准化好等对比分析)_○( ^皿^)っHiahiahia…的博客-CSDN博客
实验原理
有关svm原理 请移步该篇通俗易懂的博客 机器学习算法(一)SVM_yaoyz105-CSDN博客_svm
下图 或许可以简单概括svm功能与原理

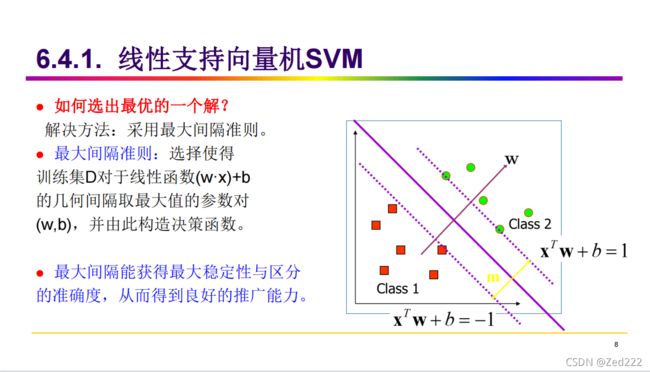
有关深究svm原理 请移步该篇通俗易懂的博客 机器学习算法(一)SVM_yaoyz105-CSDN博客_svm
或者评论我获取svm学习ppt
实验内容
1. 数据库的选择
可选取 ORL 人脸数据库作为实验样本,总共 40 个人,每人 10 幅图像,图像大小为
112*92 像素。图像本身已经经过处理,不需要进行归一化和校准等工作。实验样本分为训
练样本和测试样本。首先设置训练样本集,选择 40 个人前 5 张图片作为训练样本,进行训
练。然后设置测试样本集,将 40 个人后 5 张图片作为测试样本,进行选取识别。
2. 实验基本步骤
人脸识别算法步骤概述:
a) 读取训练数据集;
若 flag=0 ,表述读取原文件的前五幅图作为训练数据,若 flag=1 ,表述读取原文件
的后五幅图作为测试数据,数据存入 f_matrix 中,每一行为一个文件,每行为 112*92
列。参见: ReadFace.m
b) 主成分分析法降维并去除数据之间的相关性;参见: fastPCA.m
c) 数据规格化;参见 scaling.m
d) SVM 训练(选取径向基和函数)得到分类函数;参见: multiSVMtrain.m
e) 读取测试数据、降维、规格化;参见: multiSVM.m
f) 用步骤 d 产生的分类函数进行分类(多分类问题,采用一对一投票策略,归位得票
最多的一类);参见: main.m
g) 计算正确率。
以上只是matlib做法
而我会使用python做法
3. 实验要求
1 ) 分别使用 PCA 降维到 20,50,100,200 ,然后训练分类器,对比分类结果,画出对比曲 线;
2 ) 变换 SVM 的 kernel 函数,如分别使用径向基函数和多项式核函数训练分类器,对
比分类结果,画出对比曲线;
3 ) 使用交叉验证方法,变换训练集及测试集,分析分类结果。
实验步骤
一、分别使用 PCA 降维到 20,50,100,200,然后训练分类器,对比分类结果,画出对比曲线;
1.数据处理
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签2.数据标准化+PCA降维+自动
def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
#dimension=[3,5,10,20,50,100,200]
dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
#svm = SVC().fit(face_trainPca,face_target_train)
svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
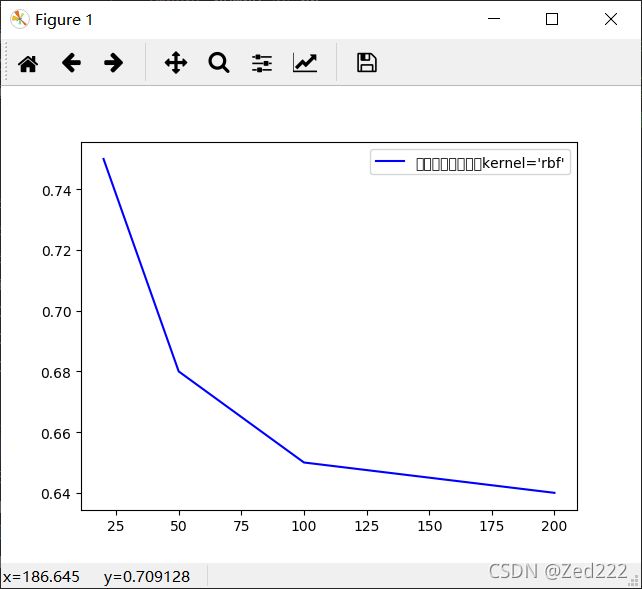
plt.plot(dimension,accuracy,"b-")
plt.legend(['默认径向基核函数kernel=\'rbf\'','多项式核函数kernel=\'poly\''])
plt.show()
#draw_chart1(dimension,accuracy)
3.总代码
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
import matplotlib.pyplot as plt #用于绘制图形
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
def draw_chart(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.plot(dimension,accuracy,"r-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('linear不同维度差异')
#plt.savefig("./tmp/采用默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")
plt.show()
def draw_chart1(dimension,accuracy):
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.plot(dimension,accuracy,"r-")
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('poly不同维度差异')
#plt.savefig("./tmp/采用默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")
plt.show()
def face_fuc(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
#dimension=[3,5,10,20,50,100,200]
dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
svm = SVC(kernel='linear').fit(face_trainPca,face_target_train)
#svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
draw_chart(dimension,accuracy)
def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test):
#2、数据标准化 标准差标准化
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
face_testStd = stdScaler.transform(face_data_test)
#dimension=[3,5,10,20,50,100,200]
dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
#3、PCA降维
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
face_testPca = pca.transform(face_testStd)
#4、建立SVM模型 默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'
#svm = SVC().fit(face_trainPca,face_target_train)
svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)
#5、预测训练集结果
face_target_pred = svm.predict(face_testPca)
#6、分析预测结果
true=0
for i in range(0,200):
if face_target_pred[i] == face_target_test[i]:
true+=1
accuracy.append(true/face_target_test.shape[0])
print(accuracy)
plt.plot(dimension,accuracy,"b-")
plt.legend(['默认径向基核函数kernel=\'rbf\'','多项式核函数kernel=\'poly\''])
plt.show()
#draw_chart1(dimension,accuracy)
if __name__ == '__main__':
#1、获取数据
face_data_train,face_target_train=get_data(1,6) #读取前五张图片为训练集
face_data_test,face_target_test=get_data(6,11) #读取后五张图片为测试集
face_target_test=face_target_test.values #将DataFrame类型转成ndarrayl类型
# face_fuc(face_data_train,face_target_train,face_data_test,face_target_test)
face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test)
4.处理结果
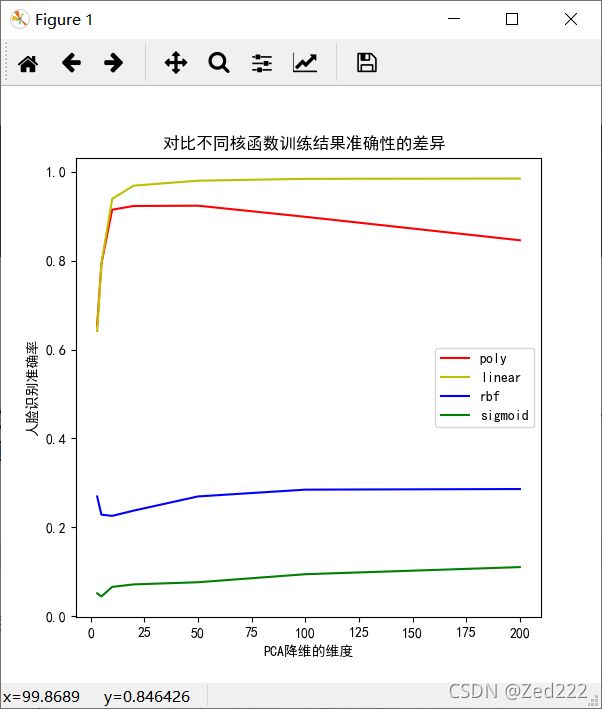
二、 变换 SVM 的 kernel 函数,如分别使用径向基函数和多项式核函数训练分类器,对比分类结果,画出对比曲线。对比四个核函数在不同降维情况下的准确度(采用交叉验证)
有关交叉验证用法来自此处
1.降维 选核函数 交叉验证 绘制图像
def face_fuc(face_data_train,face_target_train,k,c):
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
dimension=[3,5,10,20,50,100,200]
accuracy=[]
for i in dimension:
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
#默认为径向基核函数kernel='rbf' 多项式核函数'poly' 线性核函数'linear' sigmoid核函数
svm = SVC(kernel=k)
scores = cross_val_score(svm,face_trainPca,face_target_train,cv=3)
print(scores)
accuracy.append(scores.mean())
print(accuracy)
plt.plot(dimension,accuracy,c)2.总函数
import cv2 #opencv库,用于读取图片等操作
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler #标准差标准化
from sklearn.model_selection import cross_val_score #用于交叉验证
from sklearn.svm import SVC #svm包中SVC用于分类
from sklearn.decomposition import PCA #特征分解模块的PCA用于降维
import matplotlib.pyplot as plt #用于绘制图形
def get_data(x,y):
file_path='./ORL/' #设置文件路径(这里为当前目录下的ORL文件夹)
train_set = np.zeros(shape=[1,112*92]) #train_set用于获取的数据集
train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型
target=[] #标签列表
for i in range(1,41): #i用于遍历ORL文件夹中的40个文件夹
for j in range(x,y): #j用于遍历每个文件夹的对应的x到y-1的图片
target.append(i) #读入标签(图片文件夹中的人脸是同一个人的)
img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\
cv2.IMREAD_GRAYSCALE) #读取图片,第二个参数表示以灰度图像读入
img=img.reshape(1,img.shape[0]*img.shape[1]) #将读入的图片数据转换成一维
img=pd.DataFrame(img) #将一维的图片数据转成DataFrame类型
train_set=pd.concat([train_set,img],axis=0)#按行拼接DataFrame矩阵
train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的行索引
train_set.drop(labels=0,axis=0,inplace=True) #删除行索引为0的行(删除第一行)
target=pd.DataFrame(target) #将标签列表转成DataFrame类型
return train_set,target #返回数据集和标签
def face_fuc(face_data_train,face_target_train,k,c):
stdScaler = StandardScaler().fit(face_data_train)
face_trainStd = stdScaler.transform(face_data_train)
dimension=[3,5,10,20,50,100,200]
#dimension=[20,50,100,200]
'''
dimension=[]
for i in range(1,40):
dimension.append(i*5)
'''
accuracy=[]
for i in dimension:
pca = PCA(n_components=i).fit(face_trainStd)
face_trainPca = pca.transform(face_trainStd)
#默认为径向基核函数kernel='rbf' 多项式核函数'poly' 线性核函数'linear' sigmoid核函数
svm = SVC(kernel=k)
scores = cross_val_score(svm,face_trainPca,face_target_train,cv=3)
print(scores)
accuracy.append(scores.mean())
print(accuracy)
plt.plot(dimension,accuracy,c)
if __name__ == '__main__':
face_data_train,face_target_train=get_data(1,11) #读取所有图片
kernel= [ 'poly','linear', 'rbf', 'sigmoid' ]
color=['r','y','b','g']
plt.rcParams['font.sans-serif']='SimHei'
plt.figure(figsize=(6,6))
plt.xlabel('PCA降维的维度')
plt.ylabel('人脸识别准确率')
plt.title('对比不同核函数训练结果准确性的差异 ')
for i in range(0,4):
face_fuc(face_data_train,face_target_train,kernel[i],color[i])
plt.legend(['poly','linear', 'rbf', 'sigmoid'])
plt.show()
3.实现结果