pytorch学习笔记(新)
pytorch学习笔记
- 原理篇
-
- 1、torch.nn.BatchNorm2d() 详解
-
- ①原理介绍
- ②代码实现
- ③参数详解
- 2、torch.autograd.functional.jacobian()
- 技巧篇
-
- 1、utils.save_image用法详解
- 1_1、torchvision.utils.make_grid() 将图片可视化
- 2、数据预处理
-
- 心得笔记
- 代码分析
-
- 需要用到的包
- 如何预处理自己的图片文件
-
- 其他读取数据集的方法
- 3、模型
-
- 3_1、模型的保存之torch.jit.save
- 3_2、模型的读取之torch.jit.load
原理篇
1、torch.nn.BatchNorm2d() 详解
①原理介绍
官网链接: https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
在四维输入上应用批量归一化
- input: (N,C,H,W) N: 批量batch大小,C:图片通道数,H&W: 2D图片
- Output: (N, C, H, W) 与输入的一样
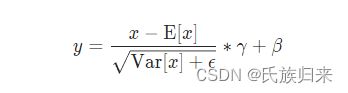
即,将原本的输入x,通过小批量的数据上的均值和标准差进行归一化。这里的均值和标准差是在N个数据上,对于每一个维度C进行计算的。
图解如下:
以下图片来自于:https://blog.csdn.net/qq_39777550/article/details/108038677
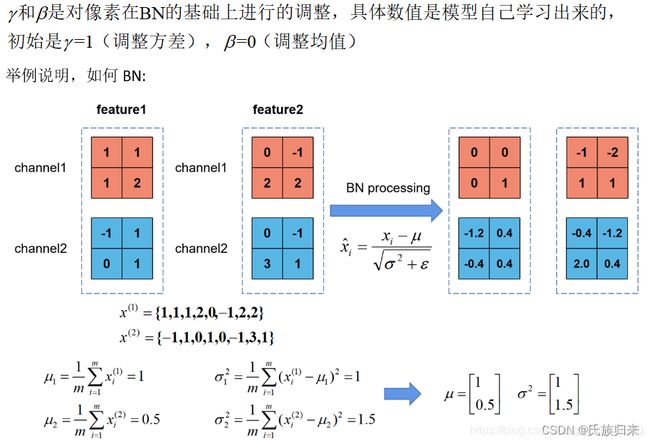
②代码实现
代码实现:
import torch
import torch.nn as nn
m = nn.BatchNorm2d(2)
input = torch.tensor([
[
[
[1,1],
[1,2]
],
[
[-1,1],
[0,1]
]
],
[
[
[0,-1],
[2,2]
],
[
[0,-1],
[3,1]
]
]
]).to(torch.float32)
output = m(input)
print(output)
输出:
tensor([[[[ 0.0000, 0.0000],
[ 0.0000, 1.0000]],
[[-1.2247, 0.4082],
[-0.4082, 0.4082]]],
[[[-1.0000, -2.0000],
[ 1.0000, 1.0000]],
[[-0.4082, -1.2247],
[ 2.0412, 0.4082]]]], grad_fn=)
③参数详解
num_features– C from an expected input of size (N, C, H, W)(N,C,H,W)eps– a value added to the denominator for numerical stability. Default: 1e-5,防止出现分母为0的情况。momentum– the value used for the running_mean and running_var computation. Can be set to None for cumulative moving average (i.e. simple average). Default: 0.1affine– a boolean value that when set to True, this module has learnable affine parameters. Default: True,决定是否更新BatchNorm2d()中的参数。track_running_stats– a boolean value that when set to True, this module tracks the running mean and variance, and when set to False, this module does not track such statistics, and initializes statistics buffers running_mean and running_var as None. When these buffers are None, this module always uses batch statistics. in both training and eval modes. Default: True,决定是否跟踪统计整个数据集的均值与方差。如果值为true,那么在test阶段,用的应该就是整个训练集的均值和方差(常用,更加稳定);反之,测试阶段就只用每个测试集中batch个数据的均值和方差,这回使得其波动大,一般不予推荐!
track_running_stats 参数的理解
1、training=True, track_running_stats=True, 这是常用的training时期待的行为,running_mean 和running_var会跟踪不同batch数据的mean和variance,但是仍然是用每个batch的mean和variance做normalization。
2、training=True, track_running_stats=False, 这时候running_mean 和running_var不跟踪跨batch数据的statistics了,但仍然用每个batch的mean和variance做normalization。
3、training=False, track_running_stats=True, 这是我们期待的test时候的行为,即使用training阶段估计的running_mean和running_var.
4、training=False, track_running_stats=False,同2(!!!).
作者:李韶华
链接:https://www.zhihu.com/question/282672547/answer/529154567
来源:知乎
2、torch.autograd.functional.jacobian()
这是pytorch中一个自动求雅可比矩阵工具。输入是函数,和函数的输入。
zeros_v = torch.randn([1, 512]).to(torch.float32).to(device)
generate_model = my_tools.get_styleGAN2_generate_model(device)
def my_gan(sample_latents):
w = generate_model.mapping(sample_latents, None, truncation_psi=1, truncation_cutoff=8)
img = generate_model.synthesis(w, noise_mode='const', force_fp32=True)
return img
# 自动计算雅可比
J = torch.autograd.functional.jacobian(my_gan, zeros_v)
u,s,v = torch.svd(J)
# SVD取前多少个百分比
SVD_threshold = 0.9
sum_i = 0
max_SVD_threshold_length = 0
sum_s = torch.sum(s)
for i in range(s.shape[0]):
sum_i += s[i]
print("前{}个特征向量的占比:{}".format(i+1, sum_i / sum_s))
if sum_i/sum_s >= SVD_threshold:
max_SVD_threshold_length = i + 1
break
-------------------------------------------------------
前1个特征向量的占比:0.15348199009895325
前2个特征向量的占比:0.2818334400653839
前3个特征向量的占比:0.40080156922340393
前4个特征向量的占比:0.48647621273994446
前5个特征向量的占比:0.547724723815918
前6个特征向量的占比:0.6026646494865417
前7个特征向量的占比:0.6460585594177246
前8个特征向量的占比:0.6786832213401794
前9个特征向量的占比:0.7062328457832336
前10个特征向量的占比:0.7287726402282715
前11个特征向量的占比:0.7488722801208496
前12个特征向量的占比:0.7658688426017761
前13个特征向量的占比:0.782359778881073
前14个特征向量的占比:0.7963537573814392
前15个特征向量的占比:0.8090671300888062
前16个特征向量的占比:0.8190773725509644
前17个特征向量的占比:0.8285030722618103
前18个特征向量的占比:0.8371889591217041
前19个特征向量的占比:0.8449500799179077
前20个特征向量的占比:0.8518429398536682
前21个特征向量的占比:0.8577028512954712
前22个特征向量的占比:0.8628340363502502
前23个特征向量的占比:0.8676300644874573
前24个特征向量的占比:0.8721526861190796
前25个特征向量的占比:0.8765588998794556
前26个特征向量的占比:0.8803938627243042
前27个特征向量的占比:0.8838895559310913
前28个特征向量的占比:0.8873368501663208
前29个特征向量的占比:0.890557587146759
前30个特征向量的占比:0.8937016725540161
前31个特征向量的占比:0.8965181708335876
前32个特征向量的占比:0.8991898894309998
前33个特征向量的占比:0.9017578363418579
技巧篇
1、utils.save_image用法详解
from torchvision import utils
images = []
gen_i, gen_j = 5, 5 #行与列
with torch.no_grad():
for _ in range(gen_i):
# generator这里指的的对抗神经网络中的生成器
images.append((generator(torch.randn(gen_j, 512).to(device), step=step, alpha=alpha).data.cpu() + 1) * 0.5)
utils.save_image(
torch.cat(images, 0),
f'./pic/{str(epoch + 1).zfill(6)}.png',
nrow=gen_i,
normalize=True,
range=(-1, 1),
)
用法详解:
torchvision.utils.save_image(
tensor(Tensor or list): 要保存的图像。如果给定的是一个小型批次的张量,通过调用make_grid将张量保存为图像的网格。
fp(string or file object): 保存图像的位置
format(Optional):如果省略了,保存的格式为文件的后缀名。
nrow (int, optional): 网格当中每一行显示的图片数
padding (int, optional):默认为2,每张图片之间的间隔像素
normalize (bool, optional):如果是True,将图像移到(0, 1)范围内,由value_range指定的最小和最大值。默认值。为False。
value_range (tuple, optional): 其中min和max是数字,那么这些数字被用来规范化图像。默认情况下,min和max是从张量中计算出来的。
)
1_1、torchvision.utils.make_grid() 将图片可视化
函数介绍:
torchvision.utils.make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0)
参数介绍:
tensor(Tensor 或 list)– 四维批(batch)Tensor或列表。如果是Tensor,其形状应是(B x C x H x W);如果是列表,元素应为相同大小的图片。nrow(int, 可选)– 最终展示的图片网格中每行摆放的图片数量。网格的长宽应该是(B / nrow, nrow)。默认是8。padding(int, 可选)– 扩展填充的像素宽度。默认是2。normalize(bool, 可选)– 如果设置为True,通过减去最小像素值然后除以最大像素值,把图片移到(0,1)的范围内。range(tuple, 可选)– 元组(min, max),min和max用于对图片进行标准化处理。默认的,min和max由输入的张量计算得到。scale_each(bool, 可选)– 如果设置为True,将批中的每张图片按照各自的最值分别缩放,否则使用当前批中所有图片的最值(min, max)进行统一缩放。pad_value(float, 可选)– 扩展填充的像素值。
————————————————
版权声明:本文为CSDN博主「从天而降小可爱」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_36411839/article/details/105484537
import torchvision
import matplotlib.pyplot as plt
import torch
import dnnlib
import torch_utils
import pickle
# 这个GAN是styleGAN2,可以跳过这一步直接使用
# img_dataloader = torch.utils.data.DataLoader(datasets.CIFAR10('./data/cifar10/', train=True, download=True, transform=transform), batch_size=32, shuffle=True)
# 链接:https://github.com/NVlabs/stylegan2-ada-pytorch
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
GAN_pkl = './model/style_GAN/cifar10u-cifar-ada-best-fid.pkl'
print('Loading GAN generator from "%s"...' % GAN_pkl)
with open(GAN_pkl, 'rb') as f:
generator = pickle.load(f)['G_ema'].to(device)
c = None
z = torch.randn([32, 512]).to(device)
w = generator.mapping(z, c, truncation_psi=1, truncation_cutoff=8)
img = generator.synthesis(w, noise_mode='const', force_fp32=True) #img.shape = torch.Size([32, 3, 32, 32])
# 使用make_grid函数
img_grid = torchvision.utils.make_grid(img) #img_grid.shape = torch.Size([3, 138, 274])
# 定义可视化函数
def imshow(imgs):
imgs = imgs / 2 + 0.5 # 逆归一化,像素值从[-1, 1]回到[0, 1]
imgs = imgs.cpu().numpy().transpose((1, 2, 0)) # 图像从(C, H, W)转回(H, W, C)的numpy矩阵
plt.axis("off") # 取消x,y坐标
plt.imshow(imgs)
plt.show() #如果要用plt.subplot(x,x,x)的话,这个先不用写,等所有的plt.imshow(imgs)都弄好了后,再plt.show()
# 展示结果
imshow(img_grid)

2、数据预处理
心得笔记
首先要理解一下pytorch中的神经网络的数据格式,通过print打印mnist数据的shape可以知道,输入pytorch中nn.model中的数据的shape格式如下:
[[batch_size, 1, 28, 28]]
其中,batch_size就是每次该网络同时处理的图片数,设置合理的baich_size可以加快训练的运行速度与模型的稳定性(亲测如此)。然后‘1’就是通道数,因为我打印的时mnist数据集的shape,它是灰度图片,所以通道数为1, 如果图片为彩色图片,其通道数为3。最后两个‘28’就是图片的像素大小了,可以通过该图片文件的属性中的详细属性看到。
代码分析
需要用到的包
import torch
from torchvision import datasets, tranforms
from torch.utils.data import DataLoader
如何预处理自己的图片文件
网上有很多关于mnist数据集的预处理方法,但当我们自己要处理自己的图片文件时,就显得有些不知所措,详细请看代码:
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
'''
定义一个转化函数,目的就是可以把我们常见的图片文件(jpg,png等)通过torchvision.transforms.ToTensor()函数
转化成tensor格式,然后再通过torchvision.transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
函数进行图片归一化,即将tensor中的值都限定在-1到1之间。
'''
transforms = torchvision.transforms.Compose([torchvision.transforms.ToTensor()],
torchvision.transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]))
'''
读取目录下的图片文件,你的文件夹格式应该为如下情况:
directory/
├── class_x
│ ├── xxx.jpg
│ ├── xxy.jpg
│ └── ...
│ └── xxz.jpg
└── class_y
├── 123.jpg
├── nsdf3.jpg
└── ...
└── asd932_.jpg
即,directory下面有各种各样的类别文件夹,然后在这个类别文件夹下才是你自己的图片文件,之所以需要这样
是因为,它这个torchvision.datasets.DatasetFolder函数能够根据你的class_x的名字来自动定义标签,
如上,class_x文件夹下的图片的标签就是0,class_y下的图片标签就是1,以此类推。
'''
imagenet_data = torchvision.datasets.DatasetFolder('path/to/directory/', transform=transforms )
'''
最后就是构造一个迭代器了,batch_size就是接下来要批量处理的数量,shffle标志是否给imagenet_data中的数据打乱,顺序随机一下。
'''
data_loader = torch.utils.data.DataLoader(imagenet_data,
batch_size=4,
shuffle=True)
'''
最后就是可以处理数据了,我们先假设我们已经构造好了模型为model, 损失函数为criterion,优化函数为optimizer
'''
model = ’自己的网络结构‘
optimizer = optim.Adam(model.parameters(), lr=0.0001) # 优化方法,学习率为lr的值
criterion = nn.MSELoss() # 损失函数,即计算模型的预测值和真实标签label的差异大小的函数
epoch = 200 # 将整个数据集训练200次
for i in range(epoch):
for data in data_loader:
imgs, labels = data #提出图片和该图片的标签
# ======前向传播=======
outputs = model(img)
loss = criterion(outputs, labels)
# ======反向传播=======
optimizer.zero_grad()
loss.backward()
optimizer.step()
其他读取数据集的方法
参考链接:https://blog.csdn.net/shizuguilai/article/details/128306786
3、模型
3_1、模型的保存之torch.jit.save
torch.jit.save(m, f, _extra_files=None) ——> 参考链接
核心代码示例:
import torch
import io
import sys
sys.path.append("./statick/data/z_model/CIFAR10/VAE") #将python_files目录添加到工作目录
import VAE
device = torch.device("cuda:1")
vae = VAE.VanillaVAE(in_features=512, hidden_dims = [128, 64, 32], latent_dim=2).to(device)
vae.load_state_dict(torch.load("/home/kuangjielong/my_idea/robustmap/我的开始/statick/data/z_model/CIFAR10/VAE/checkpoints/1_VAE_checkpoint/vae_checkpoint_1000.pt",map_location = device))
m = torch.jit.script(vae)
# Save to file
torch.jit.save(m, 'scriptmodule.pt')
# This line is equivalent to the previous
m.save("scriptmodule.pt")
# Save to io.BytesIO buffer
buffer = io.BytesIO()
torch.jit.save(m, buffer)
# Save with extra files
extra_files = {'foo.txt': b'bar'}
torch.jit.save(m, 'scriptmodule.pt', _extra_files=extra_files)
我的VAE代码
import torch
from base import BaseVAE # 因为可以直接from base import是因为在调用这个文件的是时候,将这个文件所在的目录加入了sys.path
#import BaseVAE
from torch import nn
from torch.nn import functional as F
from typing import List, Callable, Union, Any, TypeVar, Tuple
# from torch import tensor as Tensor
Tensor = TypeVar('torch.tensor')
class VanillaVAE(BaseVAE):
def __init__(self,
in_features: int,
latent_dim: int,
hidden_dims: List = None,
**kwargs) -> None:
super(VanillaVAE, self).__init__()
self.latent_dim = latent_dim
if hidden_dims is None:
# hidden_dims = [128, 64, 32] 1_VAE
# idden_dims = [64, 32] 2和3的vae
hidden_dims = [400]
out_feature = in_features
# Build Encoder
modules = []
for h_dim in hidden_dims:
modules.append(
nn.Sequential(
nn.Linear(in_features=in_features, out_features=h_dim),
nn.LeakyReLU())
)
in_features = h_dim
self.encoder = nn.Sequential(*modules)
self.fc_mu = nn.Linear(hidden_dims[-1], latent_dim)
self.fc_var = nn.Linear(hidden_dims[-1], latent_dim)
# Build Decoder
modules = []
self.decoder_input = nn.Linear(latent_dim, hidden_dims[-1])
hidden_dims.reverse() #数组反转
in_features = hidden_dims[0]
for h_dim in hidden_dims:
modules.append(
nn.Sequential(
nn.Linear(in_features=in_features, out_features=h_dim),
nn.LeakyReLU())
)
in_features = h_dim
self.decoder = nn.Sequential(*modules)
self.final_layer = nn.Sequential(
nn.Linear(in_features=hidden_dims[-1], out_features=out_feature),
nn.Tanh())
def encode(self, input: Tensor) -> List[Tensor]:
"""
Encodes the input by passing through the encoder network
and returns the latent codes.
:param input: (Tensor) Input tensor to encoder [N x C x H x W]
:return: (Tensor) List of latent codes
"""
result = self.encoder(input)
# Split the result into mu and var components
# of the latent Gaussian distribution
mu = self.fc_mu(result)
log_var = self.fc_var(result)
return [mu, log_var]
def decode(self, z: Tensor) -> Tensor:
"""
Maps the given latent codes
onto the image space.
:param z: (Tensor) [B x D]
:return: (Tensor) [B x C x H x W]
"""
result = self.decoder_input(z)
result = self.decoder(result)
result = self.final_layer(result)
return result
def reparameterize(self, mu: Tensor, logvar: Tensor) -> Tensor:
"""
Reparameterization trick to sample from N(mu, var) from
N(0,1).
:param mu: (Tensor) Mean of the latent Gaussian [B x D]
:param logvar: (Tensor) Standard deviation of the latent Gaussian [B x D]
:return: (Tensor) [B x D]
"""
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return eps * std + mu
def forward(self, input: Tensor) -> List[Tensor]:
mu, log_var = self.encode(input)
z = self.reparameterize(mu, log_var)
return [self.decode(z), input, mu, log_var]
def loss_function(self,
*args,
**kwargs) -> dict:
"""
Computes the VAE loss function.
KL(N(\mu, \sigma), N(0, 1)) = \log \frac{1}{\sigma} + \frac{\sigma^2 + \mu^2}{2} - \frac{1}{2}
:param args:
:param kwargs:
:return:
"""
recons = args[0]
input = args[1]
mu = args[2]
log_var = args[3]
kld_weight = kwargs['M_N'] # Account for the minibatch samples from the dataset
recons_loss =F.mse_loss(recons, input)
kld_loss = torch.mean(-0.5 * torch.sum(1 + log_var - mu ** 2 - log_var.exp(), dim = 1), dim = 0)
loss = recons_loss + kld_weight * kld_loss
return [loss, recons_loss, -kld_loss]
def sample(self,
num_samples:int,
current_device: int, **kwargs) -> Tensor:
"""
Samples from the latent space and return the corresponding
image space map.
:param num_samples: (Int) Number of samples
:param current_device: (Int) Device to run the model
:return: (Tensor)
"""
z = torch.randn(num_samples,
self.latent_dim)
z = z.to(current_device)
samples = self.decode(z)
return samples
def generate(self, x: Tensor, **kwargs) -> Tensor:
"""
Given an input image x, returns the reconstructed image
:param x: (Tensor) [B x C x H x W]
:return: (Tensor) [B x C x H x W]
"""
return self.forward(x)[0]
继承的父类
from typing import List, Callable, Union, Any, TypeVar, Tuple
# from torch import tensor as Tensor
Tensor = TypeVar('torch.tensor')
from torch import nn
from abc import abstractmethod
class BaseVAE(nn.Module):
def __init__(self) -> None:
super(BaseVAE, self).__init__()
def encode(self, input: Tensor) -> List[Tensor]:
raise NotImplementedError
def decode(self, input: Tensor) -> Any:
raise NotImplementedError
def sample(self, batch_size:int, current_device: int, **kwargs) -> Tensor:
raise RuntimeWarning()
def generate(self, x: Tensor, **kwargs) -> Tensor:
raise NotImplementedError
@abstractmethod
def forward(self, *inputs: Tensor) -> Tensor:
pass
@abstractmethod
def loss_function(self, *inputs: Any, **kwargs) -> Tensor:
pass
3_2、模型的读取之torch.jit.load
torch.jit.load(f, map_location=None, _extra_files=None)——>参考链接

import torch
import io
torch.jit.load('scriptmodule.pt')
# Load ScriptModule from io.BytesIO object
with open('scriptmodule.pt', 'rb') as f:
buffer = io.BytesIO(f.read())
# Load all tensors to the original device
vae = torch.jit.load(buffer)
# Load all tensors onto CPU, using a device
buffer.seek(0)
torch.jit.load(buffer, map_location=torch.device('cpu'))
# Load all tensors onto CPU, using a string
buffer.seek(0)
torch.jit.load(buffer, map_location='cpu')
# Load with extra files.
extra_files = {'foo.txt': ''} # values will be replaced with data
torch.jit.load('scriptmodule.pt', _extra_files=extra_files)
print(extra_files['foo.txt'])