PCL-点云处理(一)
PCL—点云处理(一)
- PCL—综述—三维图像处理
- 点云模型与三维信息
- 点云库对滤波算法的实现
- PCL—点云分割(RanSaC)-低
- 点云分割
- RanSaC算法
- PCL中基于RanSaC的点云分割方法
- PCL—点云分割(邻近信息)-低
- 1.确定领域的方法--kdTree&OcTree
- 2.区分邻里关系远近的方法---欧几里得与区域生长算法
PCL—综述—三维图像处理
点云模型与三维信息
三维图像是一种特殊的信息表达形式,其特征是表达的空间中三个维度的数据。和二维图像相比,三维图像借助第三个维度的信息,可以实现天然的物体-背景解耦。除此之外,对于视觉测量来说,物体的二维信息往往随射影方式而变化,但其三维特征对不同测量方式具有更好的统一性。与相片不同,三维图像是对一类信息的统称,信息还需要有具体的表现形式。其表现形式包括:深度图(以灰度表达物体与相机的距离),几何模型(由CAD软件建立),点云模型(所有逆向工程设备都将物体采样成点云)。可见,点云数据是最为常见也是最基础的三维模型。点云模型往往由测量直接得到,每个点对应一个测量点,未经过其他处理手段,故包含了最大的信息量。然而,这些信息隐藏在点云中需要以其他提取手段将其萃取出来,提取点云中信息的过程则为三维图像处理。## 点云处理的三个层次与图像处理类似,点云处理也存在不同层次的处理方式。或者说,根据任务的需求,需要组合不同的处理方式,而这些处理在过程上有先后之分。Marr将图像处理分为三个层次,低层次包括图像强化,滤波,边缘检测等基本操作。中层次包括连通域标记(label),图像分割等操作。高层次包括物体识别,场景分析等操作。工程中的任务往往需要用到多个层次的图像处理手段,在传统的图像处理方法中(传统就是不包括CNN神经网络和大数据集),图像处理的过程需要递增的使用不同层次图像处理来完成任务。PCL官网对点云处理方法给出了较为明晰的层次划分,如图所示。
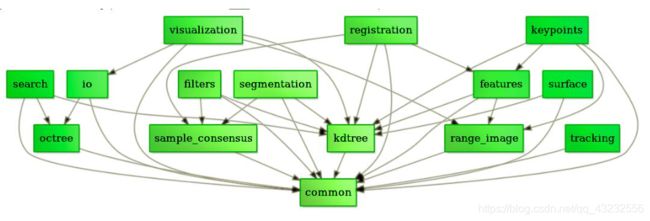
此处的common指的是点云数据的类型,包括XYZ,XYZC,XYZN,XYZG等很多类型点云,归根结底,最重要的信息还是包含在pointpcl::point::xyz中。可以看出,低层次的点云处理主要包括滤波(filters),关键点(keypoints),分割(segmention)。分别对应图像处理中的滤波,边缘检测,分割。显然,在图像处理中还是中层次的分割操作,由于点云的特性被简化到了低层次的水平,本质上与滤波和关键点提取难度相当了。点云的中层次处理则是特征描述(feature)。高层次处理包括配准(registration),识别(recognition)。可见,点云在分割的难易程度上比图像处理更有优势。准确的分割也为识别打好了基础。# PCL—点云滤波(初步处理)-低## 点云滤波的概念点云滤波是点云处理的基本步骤,也是进行 high level 三维图像处理之前必须要进行的预处理。其作用类似于信号处理中的滤波,但实现手段却和信号处理不一样。我认为原因有以下几个方面:
- 点云不是函数,对于复杂三维外形其x,y,z之间并非以某种规律或某种数值关系定义。所以点云无法建立横纵坐标之间的联系。
- 点云在空间中是离散的。和图像,信号不一样,并不定义在某个区域上,无法以某种模板的形式对其进行滤波。换言之,点云没有图像与信号那么明显的定义域。
- 点云在空间中分布很广泛。历整个点云中的每个点,并建立点与点之间相互位置关系成了最大难点。不像图像与信号,可以有迹可循。
- 点云滤波依赖于几何信息,而不是数值关系。
综上所述,点云滤波只在抽象意义上与信号,图像滤波类似。因为滤波的功能都是突出需要的信息。## 点云滤波的方法PCL常规滤波手段均进行了很好的封装。对点云的滤波通过调用各个滤波器对象来完成。主要的滤波器有直通滤波器,体素格滤波器,统计滤波器,半径滤波器 等。不同特性的滤波器构成了较为完整的点云前处理族,并组合使用完成任务。实际上,滤波手段的选择和采集方式是密不可分的。
-
如果使用线结构光扫描的方式采集点云,必然物体沿z向分布较广,但x,y向的分布处于有限范围内。此时可使用直通滤波器,确定点云在x或y方向上的范围,可较快剪除离群点,达到第一步粗处理的目的。
-
如果使用高分辨率相机等设备对点云进行采集,往往点云会较为密集。过多的点云数量会对后续分割工作带来困难。体素格滤波器可以达到向下采样同时不破坏点云本身几何结构的功能。点云几何结构不仅是宏观的几何外形,也包括
微观的排列方式,比如横向相似的尺寸,纵向相同的距离。随机下采样虽然效率比体素滤波器高,但会破坏点云微观结构。 -
统计滤波器用于去除明显离群点(离群点往往由测量噪声引入)。其特征是在空间中分布稀疏,可以理解为:每个点都表达一定信息量,某个区域点越密集则可能信息量越大。噪声信息属于无用信息,信息量较小。所以离群点表达的信息可以忽略不计。考虑到离群点的特征,则可以定义某处点云小于某个密度,既点云无效。计算每个点到其最近的k个点平均距离。则点云中所有点的距离应构成高斯分布。给定均值与方差,可剔除3∑之外的点。
-
半径滤波器与统计滤波器相比更加简单粗暴。以某点为中心画一个圆计算落在该圆中点的数量,当数量大于给定值时,则保留该点,数量小于给定值则剔除该点。此算法运行速度快,依序迭代留下的点一定是最密集的,但是圆的半径和圆内点的数目都需要人工指定。
实际上点云滤波的手段和传统的信号滤波与图像滤波在自动化程度,滤波效果上还有很大的差距。学者大多关注图像识别与配准算法在点云处理方面的移植,而对滤波算法关注较少。其实点云前处理对测量精度与识别速度都有很大影响。
点云库对滤波算法的实现
点云库中已经包含了上述所有滤波算法。PCL滤波算法的实现是通过滤波器类来完成的,需要实现滤波功能时则新建一个滤波器对象并设置参数。从而保证可以针对不同的滤波任务,使用不同参数的滤波器对点云进行处理。
直通滤波器:
// Create the filtering object
pcl::PassThrough pass;
pass.setInputCloud (cloud);
pass.setFilterFieldName ("z");
pass.setFilterLimits (0.0, 1.0);
//pass.setFilterLimitsNegative (true);
pass.filter (*cloud_filtered); 体素滤波器:
// Create the filtering object
pcl::VoxelGrid sor;
sor.setInputCloud (cloud);
sor.setLeafSize (0.01f, 0.01f, 0.01f);
sor.filter (*cloud_filtered); 统计滤波器:
// Create the filtering object
pcl::StatisticalOutlierRemoval sor;
sor.setInputCloud (cloud);
sor.setMeanK (50);
sor.setStddevMulThresh (1.0);
sor.filter (*cloud_filtered); 半径滤波器:
// build the filter
pcl::RadiusOutlierRemoval outrem;
outrem.setInputCloud(cloud);
outrem.setRadiusSearch(0.8);
outrem.setMinNeighborsInRadius (2);
// apply filter
outrem.filter (*cloud_filtered); PCL—点云分割(RanSaC)-低
点云分割
点云分割可谓点云处理的精髓,也是三维图像相对二维图像最大优势的体现。自Niloy J Mitra教授的Global contrast based salient region detection出现,最优分割到底鹿死谁手还不好说。
点云分割的目的提取点云中的不同物体,从而实现分而治之,突出重点,单独处理的目的。而在现实点云数据中,往往对场景中的物体有一定先验知识。比如:桌面墙面多半是大平面,桌上的罐子应该是圆柱体,长方体的盒子可能是牛奶盒…对于复杂场景中的物体,其几何外形可以归结于简单的几何形状。这为分割带来了巨大的便利,因为简单几何形状是可以用方程来描述的,或者说,可以用有限的参数来描述复杂的物体。而方程则代表的物体的拓扑抽象。于是,RanSaC算法可以很好的将此类物体分割出来。
RanSaC算法
随机抽样一致算法(RANdom SAmple Consensus,RANSAC),采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。RANSAC算法假设数据中包含正确数据和异常数据(或称为噪声)。正确数据记为内点(inliers),异常数据记为外点(outliers)。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。该算法核心思想就是随机性和假设性,随机性是根据正确数据出现概率去随机选取抽样数据,根据大数定律,随机性模拟可以近似得到正确结果。假设性是假设选取出的抽样数据都是正确数据,然后用这些正确数据通过问题满足的模型,去计算其他点,然后对这次结果进行一个评分。RANSAC算法被广泛应用在计算机视觉领域和数学领域,例如直线拟合、平面拟合、计算图像或点云间的变换矩阵、计算基础矩阵等方面,使用的非常多。
算法基本思想
(1)要得到一个直线模型,需要两个点唯一确定一个直线方程。所以第一步随机选择两个点。
(2)通过这两个点,可以计算出这两个点所表示的模型方程y=ax+b。
(3)将所有的数据点套到这个模型中计算误差。
(4)找到所有满足误差阈值的点。
(5)然后我们再重复(1)~(4)这个过程,直到达

如果用最小二乘法是无法得到这样的效果的,直线大约会在图中直线偏上一点。可以发现,虽然这个数据集中外点和内点的比例几乎相等,但是RANSAC算法还是能找到最合适的解。这个问题如果使用最小二乘法进行优化,由于噪声数据的干扰,我们得到的结果肯定是一个错误的结果,这是由于最小二乘法是一个将外点参与讨论的代价优化问题,而RANSAC是一个使用内点进行优化的问题。经实验验证,对于包含80%误差的数据集,RANSAC的效果远优于直接的最小二乘法。
实际上这个算法就是从一堆数据里挑出自己最心仪的数据。所谓心仪当然是有个标准(目标的形式:满足直线方程?满足圆方程?以及能容忍的误差e)。平面中确定一条直线需要2点,确定一个圆则需要3点。随机采样算法,其实就和小女生找男朋友差不多。
-
从人群中随便找个男生,看看他条件怎么样,然后和他谈恋爱,(平面中随机找两个点,拟合一条直线,并计算在容忍误差e中有多少点满足这条直线)
-
第二天,再重新找个男生,看看他条件怎么样,和男朋友比比,如果更好就换新的(重新随机选两点,拟合直线,看看这条直线是不是能容忍更多的点,如果是则记此直线为结果)
-
第三天,重复第二天的行为(循环迭代)
-
终于到了某个年龄,和现在的男朋友结婚(迭代结束,记录当前结果)
优点:是噪声可以分布的任意广,噪声可以远大于模型信息。
缺点:第一,必须先指定一个合适的容忍误差e。第二,必须指定迭代次数作为收敛条件。
综合以上特性,本算法非常适合从杂乱点云中检测某些具有特殊外形的物体。
PCL中基于RanSaC的点云分割方法
PCL支持了大量几何模型的RanSaC检测,可以非常方便的对点云进行分割。其调用方法如下:
//创建一个模型参数对象,用于记录结果
pcl::ModelCoefficients::Ptr coefficients (new pcl::ModelCoefficients);
//inliers表示误差能容忍的点 记录的是点云的序号
pcl::PointIndices::Ptr inliers (new pcl::PointIndices);
);
// 创建一个分割器
pcl::SACSegmentation seg;
// Optional
seg.setOptimizeCoefficients (true);
// Mandatory-设置目标几何形状
seg.setModelType (pcl::SACMODEL_PLANE);
//分割方法:随机采样法
seg.setMethodType (pcl::SAC_RANSAC);
//设置误差容忍范围
seg.setDistanceThreshold (0.01);
//输入点云
seg.setInputCloud (cloud);
//分割点云
seg.segment (*inliers, *coefficients); PCL几乎支持所有的几何形状。作为点云分割的基础算法,RanSaC很强大且必收敛,可以作为机器人抓取,识别等后续任务的前处理。
PCL—点云分割(邻近信息)-低
分割给人最直观的影响大概就是邻居和我不一样。比如某条界线这边是中华文明,界线那边是西方文,最简单的分割方式就是在边界上找些居民问:"小伙子,你到底能不能上油管啊?”。然后把能上油管的居民坐标连成一条线,自然就区分开了两个地区。也就是说,除了之前提到的基于采样一致的分割方式以外,应该还存在基于邻近搜索的分割方式。通过对比某点和其最近一点的某些特征,来实现点云的分割。图像所能提供的分割信息仅是灰度或RGB向量,而三维点云却能够提供更多的信息。故点云在分割上的优势是图像所无法比拟的(重要的事情要说三遍)。
1.确定领域的方法–kdTree&OcTree
由于分割工作需要对点云的邻近点进行操作,不断对比和访问某个点的邻居,所以决定点云的相邻关系是非常重要的。对于Scan来说,邻居关系是天然的。但对于很多杂乱点云,或者滤波,分割后的点云来说,邻居关系就已经被破坏了。确定一个点云之间的相邻关系可以通过“树”来完成,目前比较主流的方法包括:kdTree和OcTree,这两种方法各有特点。
1.1.kdTree—一种递归的邻近搜索策略
关于kdTree到底是怎么工作的https://en.wikipedia.org/wiki/K-d_tree这里有非常详细的说明,我不再赘述。但是kdTree实际上包括两个部分:1.建立kdTree,2.在kdTree中查找。建立kdTree实际上是一个不断划分的过程,首先选择最sparse的维度,然后找到该维度上的中间点,垂直该维度做第一次划分。此时k维超平面被一分为二,在两个子平面中再找最sparse的维度,依次类推知道最后一个点也被划分。那么就形了一个不断二分的树。如图所示。
显然,一般情况下一个点的邻近点只需要在其父节点和子节点中搜索即可,大大缩小了邻近点的搜索规模。并且kdtree可以有效的对插入点进行判断其最近点在哪个位置。对于低层次视觉来说kdTree算法是非常重要的。在很多情况下需要给出某个点,再查k临近点的编号,或者差某半径范围内的点。PCL已经实现了kdtree算法,其调用接口如下:
#include
#include
//创建kdtree 结构
pcl::KdTreeFLANN kdtree;
//传入点云
kdtree.setInputCloud (cloud);
//设置输入点
pcl::PointXYZ searchPoint;
//k邻近搜索
int K = 10;
//设置两个容器,第一个放点的标号,第二个点到SearchPoint的距离
std::vector pointIdxNKNSearch(K);
std::vector pointNKNSquaredDistance(K);
//进行搜索,注意,此函数有返回值>0为找到,<0则没找到
kdtree.nearestKSearch (searchPoint, K, pointIdxNKNSearch, pointNKNSquaredDistance)
// 基于距离的搜索 //
//两个未知大小的容器,作用同上
std::vector pointIdxRadiusSearch;
std::vector pointRadiusSquaredDistance;
// 搜索半径
float radius = 3;
//搜索,效果同上
kdtree.radiusSearch (searchPoint, radius, pointIdxRadiusSearch, pointRadiusSquaredDistance) 显然,我们还需要一个算法把Idx里的点云数据提取出来进行重新着色之类的工作,代码可以写作:
pcl::PointCloud::Ptr Npoints(new pcl::PointCloud);
Npoints->height=1;
Npoints->width=searchindice.size();
Npoints->resize (searchindice.size());
//注意此清空操作非常极其以及特别重要,否则Npoints中会有莫名奇妙的点。
Npoints->clear();
int PointNUM = 0;
for(int i=0;ipush_back(cloud->points[PointNUM]);
//cout<points[PointNUM].x<<" "<points[PointNUM].y<<" "<points[PointNUM].z<<" "< Npoints_color_handler (Npoints, 0, 255, 0);
viewer->addPointCloud(Npoints,Npoints_color_handler,"Npoints");
viewer->setPointCloudRenderingProperties (pcl::visualization::PCL_VISUALIZER_POINT_SIZE, 5, "Npoints");
1.2 OcTree
OcTree是一种更容易理解也更自然的思想。对于一个空间,如果某个角落里有个盒子我们却不知道在哪儿。但是"神"可以告诉我们这个盒子在或者不在某范围内,显而易见的方法就是把空间化成8个卦限,然后询问在哪个卦限内。再将存在的卦限继续化成8个。意思大概就是太极生两仪,两仪生四象,四象生八卦,就这么一直划分下去,最后一定会确定一个非常小的空间。对于点云而言,只要将点云的立方体凸包用octree生成很多很多小的卦限,那么在相邻卦限里的点则为相邻点。
显然,对于不同点云应该采取不同的搜索策略,如果点云是疏散的,分布很广泛,且没什么规律(如lidar测得的点云或双目视觉捕捉的点云)kdTree能更好的划分,而octree则很难决定最小立方体应该是多少。太大则一个立方体里可能有很多点云,太小则可能立方体之间连不起来。如果点云分布非常规整,是某个特定物体的点云模型,则应该使用ocTree,因为很容易求解凸包并且点与点之间相对距离无需再次比对父节点和子节点,更加明晰。典型的例子是斯坦福的兔子
2.区分邻里关系远近的方法—欧几里得与区域生长算法
基于欧式距离的分割和基于区域生长的分割本质上都是用区分邻里关系远近来完成的。由于点云数据提供了更高维度的数据,故有很多信息可以提取获得。欧几里得算法使用邻居之间距离作为判定标准,而区域生长算法则利用了法线,曲率,颜色等信息来判断点云是否应该聚成一类。
2.1.欧几里得算法
算法的原理在PCL相关的教程中已经说的比较清楚了,我不再给出伪代码。我想用一个故事来讲讲这个问题。从前有一个脑筋急转弯,说一个锅里有两粒豆子,如果不用手,要怎么把它们分开。当时的答案是豆子本来就是分开的,又没黏在一起,怎么不叫分开。OK,实际上欧几里德算法就是这个意思。两团点云就像是两粒豆子,只要找到某个合适的度量方式,就有办法把点云和点云分开。区分豆子我们用的方法可以归结于,两个豆子之间的距离小于分子距离,所以它们并没有连在一起。如果两团点云之间最近两点的距离小于单个点云内部点之间的距离,则可以由算法判断其分为两类。假设总点云集合为A,聚类所得点云团为Q
具体的实现方法大致是:
- 找到空间中某点p10,有kdTree找到离他最近的n个点,判断这n个点到p10的距离。将距离小于阈值r的点p12,p13,p14…放在类Q里
- 在 Q\p10 里找到一点p12,重复1
- 在 Q\p10,p12 找到找到一点,重复1,找到p22,p23,p24…全部放进Q里
- 当 Q 再也不能有新点加入了,则完成搜索了
算法作用:半径滤波删除离群点、采样一致找到桌面、抽掉桌面。。。。。
显然,一旦桌面被抽,桌上的物体就自然成了一个个的浮空点云团。就能够直接用欧几里德算法进行分割了。
PCL 对欧几里得算法封装
//被分割出来的点云团(标号队列)
std::vector cluster_indices;
//欧式分割器
pcl::EuclideanClusterExtraction ec;
ec.setClusterTolerance (0.02); // 2cm
ec.setMinClusterSize (100);
ec.setMaxClusterSize (25000);
//搜索策略树
ec.setSearchMethod (tree);
ec.setInputCloud (cloud_filtered);
ec.extract (cluster_indices); 2.2 区域生长算法
区域生长算法直观感觉上和欧几里德算法相差不大,都是从一个点出发,最终占领整个被分割区域。毛*席说:“星星之火,可以燎原” 就是这个意思。欧几里德算法是通过距离远近,来判断烧到哪儿。区域生长算法则不然,烧到哪儿靠燃料(点)的性质是否类似来决定。对于普通点云,其可由法线、曲率估计算法获得其法线和曲率值。通过法线和曲率来判断某点是否属于该类。其算法可以总结为:
- 种子周围的点和种子相比
- 法线方向是否足够相近
- 曲率是否足够小
- 如果满足1,2则该点可用做种子
- 如果只满足1,则归类而不做种
- 从某个种子出发,其“子种子”不再出现则一类聚集完成
- 类的规模既不能太大也不能太小
显然,上述算法是针对小曲率变化面设计的。尤其适合对连续阶梯平面进行分割:比如SLAM算法所获得的建筑走廊。
PCL对区域生长算法有如下封装:
//一个点云团队列,用于存放聚类结果
std::vector clusters;
//区域生长分割器
pcl::RegionGrowing reg;
//输入分割目标
reg.setSearchMethod (tree);
reg.setNumberOfNeighbours (30);
reg.setInputCloud (cloud);
//reg.setIndices (indices);
reg.setInputNormals (normals);
//设置限制条件及先验知识
reg.setMinClusterSize (50);
reg.setMaxClusterSize (1000000);
reg.setSmoothnessThreshold (3.0 / 180.0 * M_PI);
reg.setCurvatureThreshold (1.0);
reg.extract (clusters); 除了普通点云之外,还有一种特殊的点云,成为RGB点云。显而易见,这种点云除了结构信息之外,还存在颜色信息。将物体通过颜色分类,是人类在辨认果实的过程中进化出的能力,颜色信息可以很好的将复杂场景中的特殊物体分割出来。而颜色点云也并不那么遥不可及,Xbox Kinect就可以轻松的捕捉颜色点云。基于颜色的区域生长分割原理上和基于曲率,法线的分割方法是一致的。只不过比较目标换成了颜色,去掉了点云规模上限的限制。可以认为,同一个颜色且挨得近,是一类的可能性很大,不需要上限来限制。所以这种方式比较适合用于室内场景分割。尤其是复杂室内场景,颜色分割可以轻松的将连续的场景点云变成不同的物体。哪怕是高低不平的地面,没法用采样一致分割器抽掉,颜色分割算法同样能完成分割任务。

基于PCL的实现方式如下:
//用于存放点云团的容器
std::vector clusters;
//颜色分割器
pcl::RegionGrowingRGB reg;
reg.setInputCloud (cloud);
//点云经过了滤波器的预处理,提取了indices
reg.setIndices (indices);
reg.setSearchMethod (tree);
reg.setDistanceThreshold (10);
//点与点之间颜色容差
reg.setPointColorThreshold (6);
//苹果都是红的,哪怕离散的苹果也应该是一类
reg.setRegionColorThreshold (5);
reg.setMinClusterSize (600);
reg.extract (clusters);