AlexNet —— Part 2:论文精读
文章目录
-
-
- 摘要
- 论文小标题
- AlexNet 网络结构
-
- 3.1 ReLU
- 3.2 Training on Multiple GPUs
- 3.3 Local Response Normalization(局部响应标准化)
- 3.4 Overlapping Pooling
- Reducing Overfitting
- 实验结果与分析
- 论文总结
-
在AlexNet —— Part 1:论文导读中,主要介绍了 AlexNet 的研究背景以及成果,下面我主要通过下面四个方面来对这篇论文进行精读。
- AlexNet 网络结构及参数计算
- AlexNet 网络特色及训练技巧
- 实验设置及结果分析
- 论文总结
我们再来回顾一下论文结构:

下面,我们首先来看看摘要。
摘要

我们可以将摘要总结如下:
- 在 ILSVRC-2010 的120万图片上训练深度卷积神经网络,获得最优结果,top-1 和 top-5 error 分别为 37.5% 和 17%。
- 在 Alexnet 中,一共有6千万个参数和65万个神经元,包括5个卷积层和3个全连接层。
- 为了训练的更快,Alexnet 使用了非饱和激活函数——ReLU,采用GPU进行训练
- 为了防止过拟合,在全连接层采取了 “dropout” 的方法。
- 基于以上技巧,在 ILSVRC-2012 以超出第二名10.9个百分点成绩夺冠。
论文小标题
看完了摘要,我们应该将这篇论文的小标题列举出来,通过观察这些小标题,我们大致就可以看出这篇论文的大致框架是怎样的。

可以看出,我们应该重点关注第3部分,它的子标题也是最多的。我们可以看到 3.5 是一个总览框架,所以我们阅读时可以先看 3.5,再去看 3.1-3.4。
下面我们就从 AlexNet 网络结构出发(3.5)。
AlexNet 网络结构
我们先看 3.5 的总体框架。

可以从上面两段文字总结如下:
- 这个网络包括8个带权重的层,5个卷积层和3个全连接层。
- 第2,4,5层只和相同 GPU 上的前一层相连接。
- 第3层和第2层中所有 GPU 上的前一层相连。
- 在第1层和第2层后有 LRN 层。
- 最大池化层会在第1,2,5层之后。
- ReLU函数会在所有的卷积层和全连接层。
接下来我们看看对图的描述。
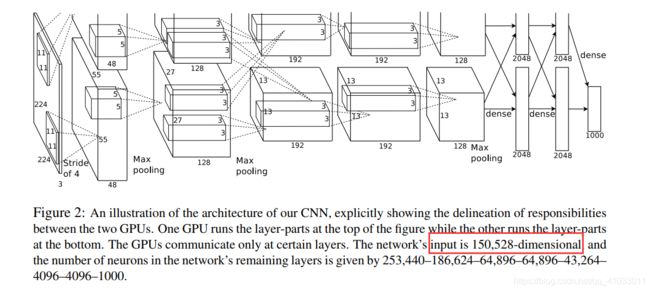
在文字中,神经网络的输入是 150,528 维度的,从图中就可以看出,输入是 224x224x3 = 150528。然后每层的神经元个数如下:

我们按照之前的文字描述将原神经网络给描述得更清晰一些:
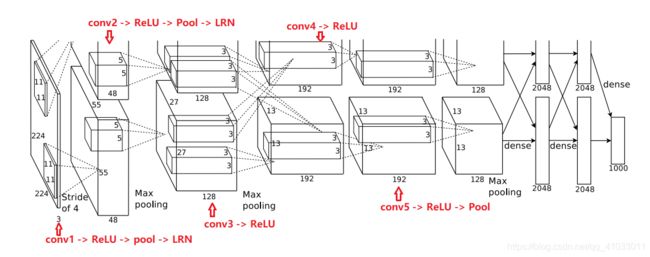
如果你还是不太明白,那么就看下面这张图:
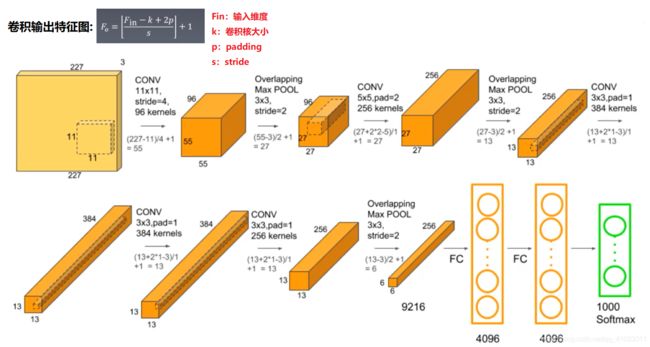
但是你看到第一层,你就可能会有一个疑问,输入层不是 224x224 吗,怎么变成了 227x227,那是因为如果将 224x224 代入 F o F_o Fo 公式计算会出现不能整除的情况,所以为了避免这种情况,应该将此处的 padding 设为 2,代入 F o F_o Fo 公式可得到输出后的大小为 55*55。
接下来,我们就来计算一下,这个网络怎么得到的 6000 万个参数。
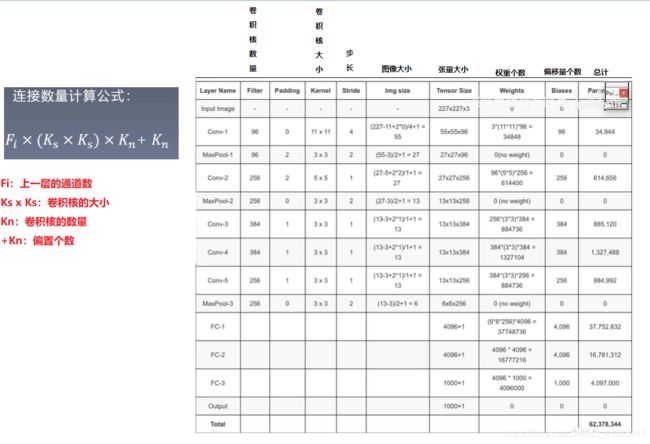
我们通过上面的公式计算一下第一层的连接数量:3 * 11 * 11 * 96 + 96 = 34944,第二层的连接数为:96 * 5 * 5 * 256 + 256 = 614656,以此类推。但是我们观察到 FC1 层的连接数量为 37,752,832 个,占了整个连接数量的一半,所以全连接层是非常消耗内存的。
我们现在已经整体的把握了 AlexNet 的网络结构,我们再倒回去看 3.1-3.4 的部分,来看看该网络到底是怎么实现的。

根据上面一段话可知,3.1-3.4 是按照重要程度依次递减排列的。那么我们将 3.1-3.4 的小标题再列出来:
3.1 ReLU Nonlinearity(the most important)
3.2 Training on Multiple GPUs
3.3 Local Response Normalization(局部相应标准化)
3.4 Overlapping Pooling
3.1 ReLU
下面,我们就来看看 3.1。

上面一段话表明,通常我们模型的激活函数会选择 tanh 或者 sigmoid 函数,但是它们都是属于饱和函数,在这个模型中,采用的是非饱和非线性的激活函数 —— ReLU 函数。因为就梯度下降的训练时间而言,饱和函数要比非饱和函数慢得多。可以从下图中观察得知:
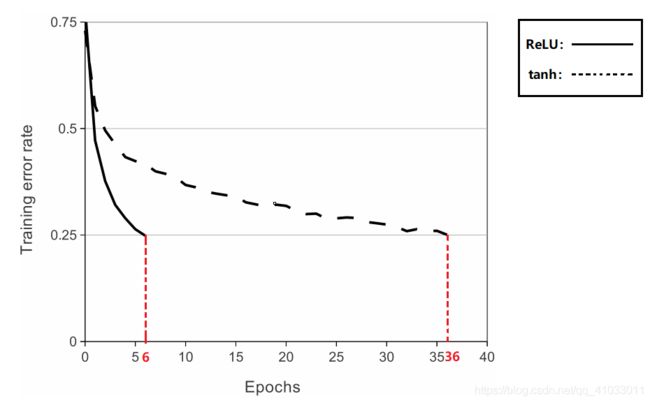
从上图可以得知,当 Training error rate 下降到 0.25 时,ReLU 函数需要训练大概 6 个 epoch,而 tanh 要训练 36 个 epoch,两个函数差了 6 倍之多,可见该网络模型的成功离不开 ReLU 函数。
那么 ReLU 还有哪些优点呢?
- 使网络训练更快
- 防止梯度消失
- 使网络具有稀疏性
下面就来看一下 ReLU 函数和 Sigmoid 函数曲线的对比:
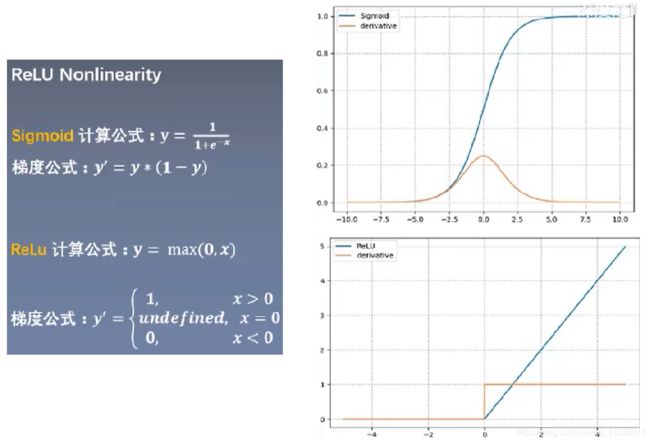
补充:饱和函数

3.2 Training on Multiple GPUs
该模型主要使用了2个GPU,在模型总览那里我们已经了解了怎么使用多 GPU,这里就不再赘述了。
3.3 Local Response Normalization(局部响应标准化)
局部响应标准化:有助于 AlexNet 泛化能力的提升,受真实神经元侧抑制(lateral inhibition)启发。
侧抑制:细胞分化变为不同时,它会对周围细胞产生抑制信号,阻止它们向相同方向分化,最终表现为细胞命运的不同。
在论文中提到了一个公式,下面我们就来解释一下这个公式:

- b x , y i b_{x,y}^i bx,yi:表示神经元局部响应标准化后的值, i i i 表示通道, x , y x, y x,y 像素的位置
- a x , y i a_{x,y}^i ax,yi:表示神经元局部响应标准化前的值
- k k k:超参数,由原型中的 bias 指定
- α α α:超参数,由原型中的 α α α
- N N N:每个特征图里面最内层向量的列数
- β β β:超参数,由原型中的 β β β 指定
- 其中, k = 2 , n = 5 , α = 1 e − 4 , β = 0.75 k=2, n=5, α=1e-4, β=0.75 k=2,n=5,α=1e−4,β=0.75
式子中的 max(0, i-n/2) 和 min(N-1, i+n/2) 是为了边界溢出的问题。我们真正需要关心的是 i-n/2 和 i+n/2。假设我们当前通道为 i i i,我们会往左考虑 n/2 个通道,向右考虑 n/2 个通道,这就对应了侧抑制概念中当细胞分化不同时,它会对周围细胞产生抑制信号。而左右 n/2 对应周围细胞。其实这个公式就是看分母,如果分母越大,那么最后得出的值相对就会比较小,就表现出抑制的作用。
3.4 Overlapping Pooling
我们先来看一下我们常见的池化方式是怎样的?
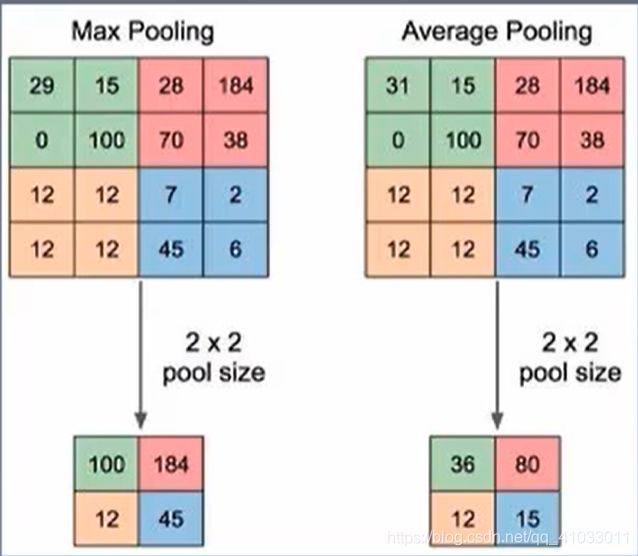
上图中输入特征图是 44 的,它的滑动窗口大小是 22 的,那么它会进行4次池化,而且每次池化的部分是不重叠的(每一部分用不同颜色区分)。通常,我们就会将移动的步长 s 设置为滑动窗口大小,即 s = 2。但是该模型中使用的是有重叠的池化,即 s < 滑动窗口大小。

以上就是神经网络大致结构。下面我们就来看看网络的训练技巧,这就是第 4 小节的内容了,Reducing Overfitting。
Reducing Overfitting
这篇论文主要使用的减少过拟合的技巧有两个:Data Augmentation 和 Dropout。
下面我们先来看看 4.1 Data Augmentation 主要使用了哪些方法。

(1):在训练阶段,从大小为 256256 的图片中随机截取出 224224 的图片,然后再经过水平翻转,我们可以得到 2048 张图片。
(2):2048 = (256-224)^2 * 2 平方表示宽和高两方面,2 表示水平翻转
(3):在测试阶段采取的方法是从一张 256256 的图片截取 5 张 224*224 的图片,分别从左上角,右上角,左下角,右下角,中心截取5张,然后分别进行水平翻转获得10张图片。
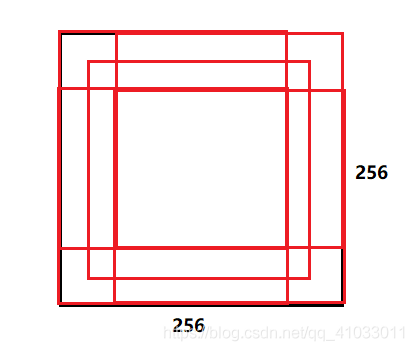
可见第一种方法使用的是裁剪和翻转来使数据量扩增。下面我们来看看第二种方法。

主要说的就是对图像颜色的扰动。
下面我们总结一下针对 Data Augmentation 采取的两种方法:

说完了 Data Augmentation。再来看看 Dropout(随即失失活)。

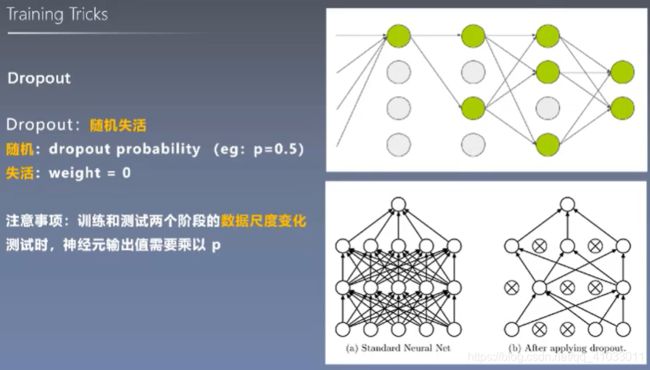
实验结果与分析
我们主要分析三个部分:

下面先来看看第一部分,在 ILSVRC-2012 挑战赛中的成果。下表表示了 AlexNet 在 Top-1 和 Top-5 这两个指标上的变化情况,它采用了四种不同的方式来获取这些指标。我们要去学习网络不断改进的思路和方法。

接下来我们看 Qualitative Evaluations。


从上图的有右图可以得出特征的相似性:相似图片的第二个全连接层输出特征向量的欧氏距离相近。
启发:可用 AlexNet 提取高级特征进行图像检索、图像聚类、图像编码。
论文总结
在研究完每篇论文之后,我们都需要做一个总结。主要从三方面进行总结:关键点、创新点和启发点。
那么我们先来看一下这篇论文的总结是什么?

第一段其实主要想讲关于模型的网络结构之间的相关联是非常重要的,例如,我们移除了某一个神经网络的卷积层,这个模型的性能会下降大概2%。同样的,我们在使用网络的时候,也不要随意增加网络的层数。
第二段主要是想讲未来的研究方向,这也是大部分论文在论文结尾都会点出来的,自己的不足或者未来可以去发展的方向。这里它提到未来可以用视频的数据来训练一个更大的卷积神经网络。因为这里提到一些时序上的信息的缺失,AlexNet 都是基于 2D 的图片,是缺少时间这个维度的,而视频数据恰恰补充了这个信息,所以这里提出来了未来可以研究的方向就是基于视频信息来训练一个更大的卷积神经网络。
下面就来进行自我总结。
关键点
- 大量带标签的数据 —— ImageNet(算料)
- 高性能计算资源 —— GPU(算力)
- 合理算法模型 —— 深度卷积神经网络(算法)
创新点
- 采用 ReLU 加快大型神经网络训练
- 采用 LRN 提升大型网络泛化能力
- 采用 Overlapping Pooling 提升指标
- 采用随机裁剪翻转及色彩扰动增加数据多样性(重点)
- 采用 Dropout 减轻过拟合(FC层)
启发点
- 深度与宽度可决定网络能力
Their capacity can be controlled by varying their depth and breadth. (1 Introduction p2) - 更强大的GPU及更多数据可进一步提高模型性能
All of our experiments suggest that our results
can be improved simply by waiting for faster GPUs and bigger datasets to become available. - 图片缩放细节,对短边先缩放
Given a
rectangular image, we first rescaled the image such that the shorter side was of length 256, and then
cropped out the central 256×256 patch from the resulting image.(2 Dataset p3) - ReLU 不需要对输入进行标准化来防止饱和现象,即说明 sigmoid/tanh 激活函数有必要对输入进行标准化
ReLUs have the desirable property that they do not require input normalization to prevent them
from saturating. (3.3 LRN p1)
复现代码见 AlexNet